改进的基于Transformer的双向编码器的对话文本识别
2022-11-16张杨帆丁锰
张杨帆, 丁锰,2*
(1. 中国人民公安大学侦查学院, 北京 100038; 2. 中国人民公安大学公共安全行为科学实验室, 北京 100038)
随着互联网技术的迅猛发展和移动终端的广泛普及,移动终端每天都会产生大量的数据。在公安实践中,为了在海量的数据中提取出与案件有关的数据,民警常常需要花费大量的时间进行分析和取证。因此如何在海量的数据中快速、准确提取与案件有关的信息,是当前公安技术工作的一大课题。在电子数据取证中,文本分析又面临着一些难题,例如犯罪嫌疑人交流中使用方言、隐语、代号或黑话。针对对话文本进行识别,旨在将与案件有关的对话文本和无关的对话文本区分开,达到对嫌疑人关系网的快速描绘以及聊天数据的快速取证。
基于对话文本的主题分类本质上属于文本分类的范畴。文本分类的方法早期是以传统机器学习为主,具有代表性的是朴素贝叶斯和支持向量机,在此基础上有不少学者进行了改进并将其应用于电子取证中。初冲[1]提出了一种不依靠词频的特征词权重计算方法并应用于中文短文本分类。易军凯等[2]在传统词频-逆文本频率指数(term frequency-inverse document frequency,TF-IDF)算法的基础上提出了基于类别区分度的改进算法并应用于电子证据取证的证据获取阶段,同时将文本分类原理应用于文件类型识别,即使用N-gram方法对文件字节流进行“分词”。叶明[3]通过引入正向类别和反向类别概率对特征权值算法进行改进,取得了一定的效果。程新航[4]提出了一种基于信息熵的改进TF-IDF文本分类算法并应用于电子取证中。虽然基于机器学习的文本分类模型取得了一定的成就,但其忽略了词与词之间以及句子和句子之间的关系,因而特征表征能力有限。基于深度学习的文本分类模型拥有更强大的特征提取和表征能力,因此随着深度学习的发展,基于机器学习的文本分类方法逐渐被基于深度学习的文本方法所替代。深度学习在文本分类领域有多种不同的模型,基于词嵌入向量化的文本分类模型(word2vec、CBOW、Skip-gram、FastText[5]、TextCNN[6])、基于上下文机制的文本分类模型(RCNN[7])、基于记忆存储机制的文本分类模型(RNN、LSTM、GRU)、基于注意力机制的文本分类模型(HAN)、基于语言模型的文本分类模型(Glove、ELMO[8]、ENRIE、BERT[9])。很多学者在以上模型的基础上进行改进使其适用于各种下游任务,如陈可嘉等[10]提出了一种基于单词表示的全局向量模型和隐含狄利克雷分布主题模型的文本表示改进方法用于解决文本分类中文本数据表示存在稀疏性、维度灾难、语义丢失的问题。郑承宇等[11]提出了一种多基模型框架(Stacking-BERT)的中文短文本分类方法用于解决静态词向量表示方法无法完整表示文本语义的问题。Wang等[12]提出了一种融合声调的双通道注意力双向长短期记忆(bidirectional long short time memory,Bi-LSTM)模型用于分析现代诗歌情感,提高了情感分析的准确率。王艳等[13]提出了一种融合拼音字符特征、汉字字符特征、词级别语义特征和词性特征的文本分类方法,提升了模型的语义表征能力。Zhu等[14]提出了融合多分类损失函数结合层级化多分类模型,实现二分类到多分类的对话文本的情感多分类,提高模型的泛化能力。李超凡等[15]提出一种基于注意力机制结合CNN-BiLSTM模型的病例文本分类模型,解决了中文电子病历文本分类的高维稀疏性、算法模型收敛速度较慢、分类效果不佳等问题。李忠等[16]提出了基于精简版BERT(A Lite BERT,ALBERT)和双向门控循环单元(gated recurrent unit,GRU)的文本多标签分类模型用于解决灾害求助信息辨识不准确、响应能力不足的问题。以上改进的模型都有其独特的优势,但不适用于电子取证。针对电子取证分析算法老旧准确率不高的问题,现提出基于预训练语言模型BERT的BERT-CNN-SE模型,充分利用预训练语言模型能够减轻过拟合的优势并提高BERT模型的分类能力。
1 对话文本识别模型
1.1 BERT模型
基于Transformer的双向编码器(bidirectional encoder representation from transformers,BERT)是由Devlin等[9]于2018年提出的基于深层Transformer的预训练语言模型。
BERT模型如图1所示。文本序列首先通过embedding层,然后通过12个(BERT-base)双向编码的BERT层,即Transformer的Encoder,其中每层输出的隐藏状态既作为下一层的输入也可以作为输出。
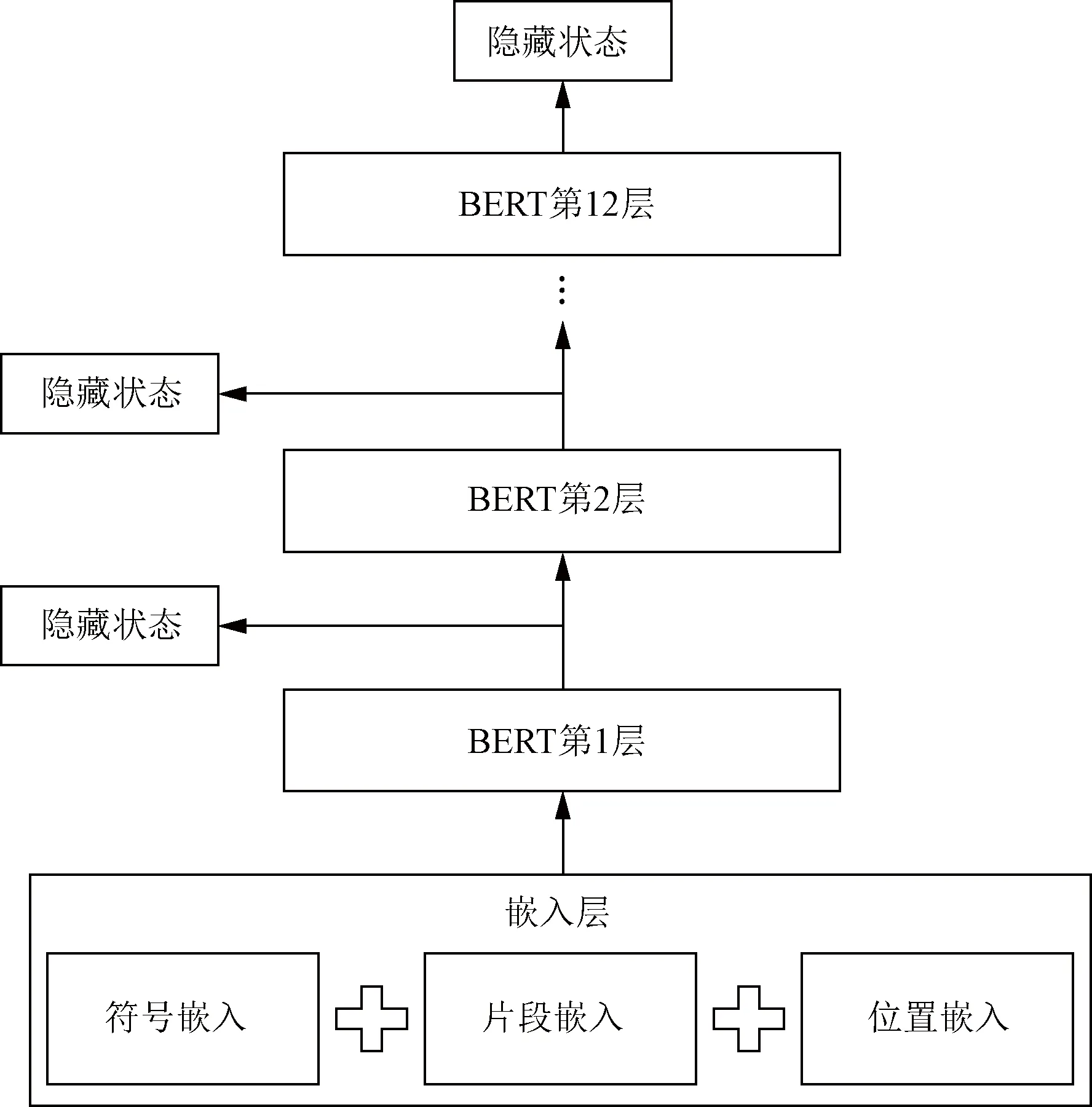
图1 BERT模型
1.1.1 BERT输入表示
BERT的输入表示是由词向量(token embedding)、块向量(segment embedding)和位置向量(position embedding)之和组成的。假设最大序列长度为L,词表大小为V,块数量为S,词向量维度为e,v∈RL×e表输入向量,vt∈RL×e代表词向量,vs∈RL×e代表块向量,vp∈RL×e代表位置向量,et∈RL×V为输入序列的词向量独热编码,es∈RL×S为输入序列的块编码,ep∈RL×L为输入序列的位置独热编码,wt∈RV×e为可训练的词向量矩阵,ws∈RS×e为可训练的块向量矩阵,wp∈RL×e为可训练的位置向量矩阵,公式如下。
v=vt+vs+vp
(1)
vt=etwt
(2)
vs=esws
(3)
vp=epwp
(4)
1.1.2 BERT的预训练方法
BERT模型的主要创新点在预训练方法上,即使用了掩码语言模型(masked language model, MLM)和下一个句子预测(next sentence prediction, NSP)两种方法分别捕捉词语和句子级别的文本语义信息。在预训练阶段通过对大量无标签的文本进行无监督学习得到丰富的语义信息,在进行下游任务的时候只需要进行微调就可以获得非常好的效果[17]。
BERT采用了类似完型填空的做法来进行MLM任务实现了真正的双向性,MLM任务将一个序列中15%的子词进行掩码,被掩码的词有80%的概率替换为[MASK]标记、10%的概率替换为词表中的其他词、10%的概率保持原词不变。BERT通过NSP任务来学习两段文本之间的差异,NSP任务要求输入是句子对,即(句子A,句子B),将来自同一个输入的句子A和句子B视为正样本,如果将句子B替换为语料库中的其他句子则视为负样本,通过对正负样本的预测,NSP任务可以学习到句子层面的语义信息。
1.1.3 注意力机制
注意力机制的提出是受到了认知神经科学领域的启发。Bahdanau等[18]首次将注意力机制引入NLP领域中后注意力机制就被广泛应用于NLP领域中。2017年Vaswani等[19]大量使用了自注意力机制,从此基于自注意力机制的模型大放异彩。注意力机制是Transformer和BERT的基础。它是Transformer的Encoder中最重要的部分,Transformer Encoder的结构如图2所示。
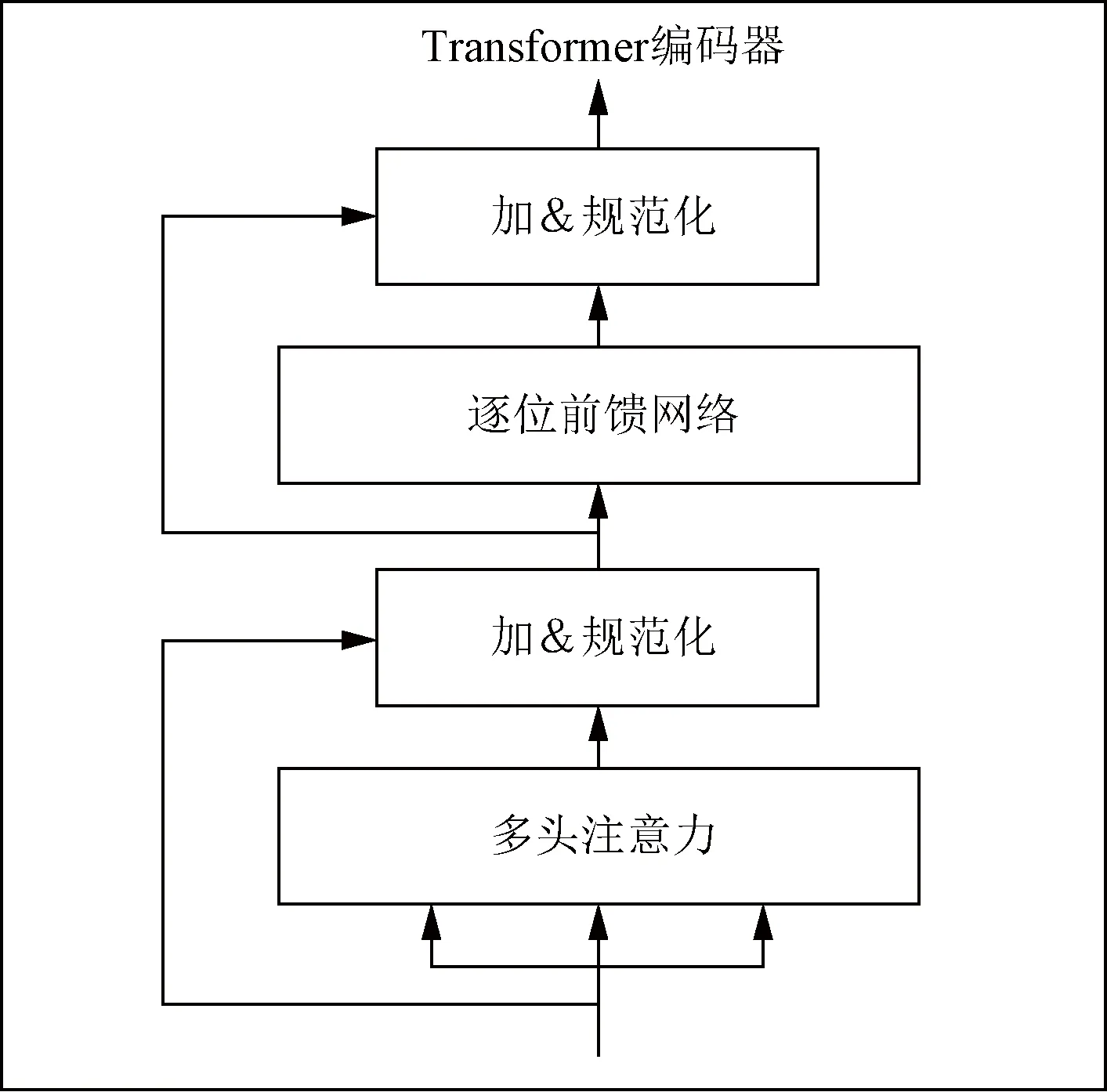
图2 transformer编码器结构
注意力机制通过注意力汇聚将查询(query,自主性提示)和键(keys,非自主性提示)结合在一起,实现对值(values,感官输入)的选择倾向。具体来说就是使用注意力评分函数来对keys和query的关系进行建模,将得到的输出输入到softmax中运算得到注意力权重(概率分布),values和注意力权重相乘得到output。注意力机制的结构图如图3所示。
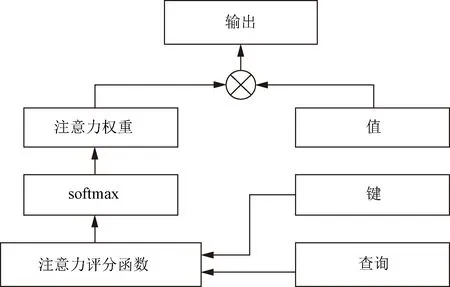
图3 注意力机制
注意力汇聚函数公式如下。
f[q,(k1,v1),(k2,v2),…,(km,vm)]=
(5)
b(q,ki)=softmax[a(q,ki)]
(6)
式(6)中:q∈Rq,q为查询;ki∈Rk,k为键;vi∈Rv,v为值;b(q,ki)为注意力权重;a为注意力评分函数;m为键值对个数。
常用的注意力评分函数是缩放点积注意力函数,公式为
(7)
式(7)中:d为查询和键的长度。
设Q∈Rn×d,K∈Rm×d,V∈Rm×v,n为查询的个数,d为查询和键的长度,v为值的长度,则缩放点积注意力可表示为
(8)
1.2 改进的BERT模型
使用微调BERT进行分类任务一般是取最后一层隐藏状态的第一个隐藏单元[CLS]作为句向量直接输入到全连接层中做分类,这可能会丢失一部分隐藏状态的语义信息,为了能最大化地利用最后一层的隐藏状态的语义信息,设计将BERT最后一层隐藏状态当作卷积层的输入,给输入添加一个大小为1的通道维度,然后分别使用几个大小不同的滤波器(卷积核)捕捉BERT输出序列的高级语义信息,然后将得到的输出依次通过同一个SE模块[20](squeeze-and-excitation),对通道进行加权。由于使用的同一个SE模块,SE模块参数共享在一定程度上减少了参数量,增强了模型的泛化能力。将通道加权后的输出输入最大池化层,最后将几种(卷积核的种类数)输出连接(concat)起来输入到全连接层中进行分类。改进BERT的模型图,如图4所示。
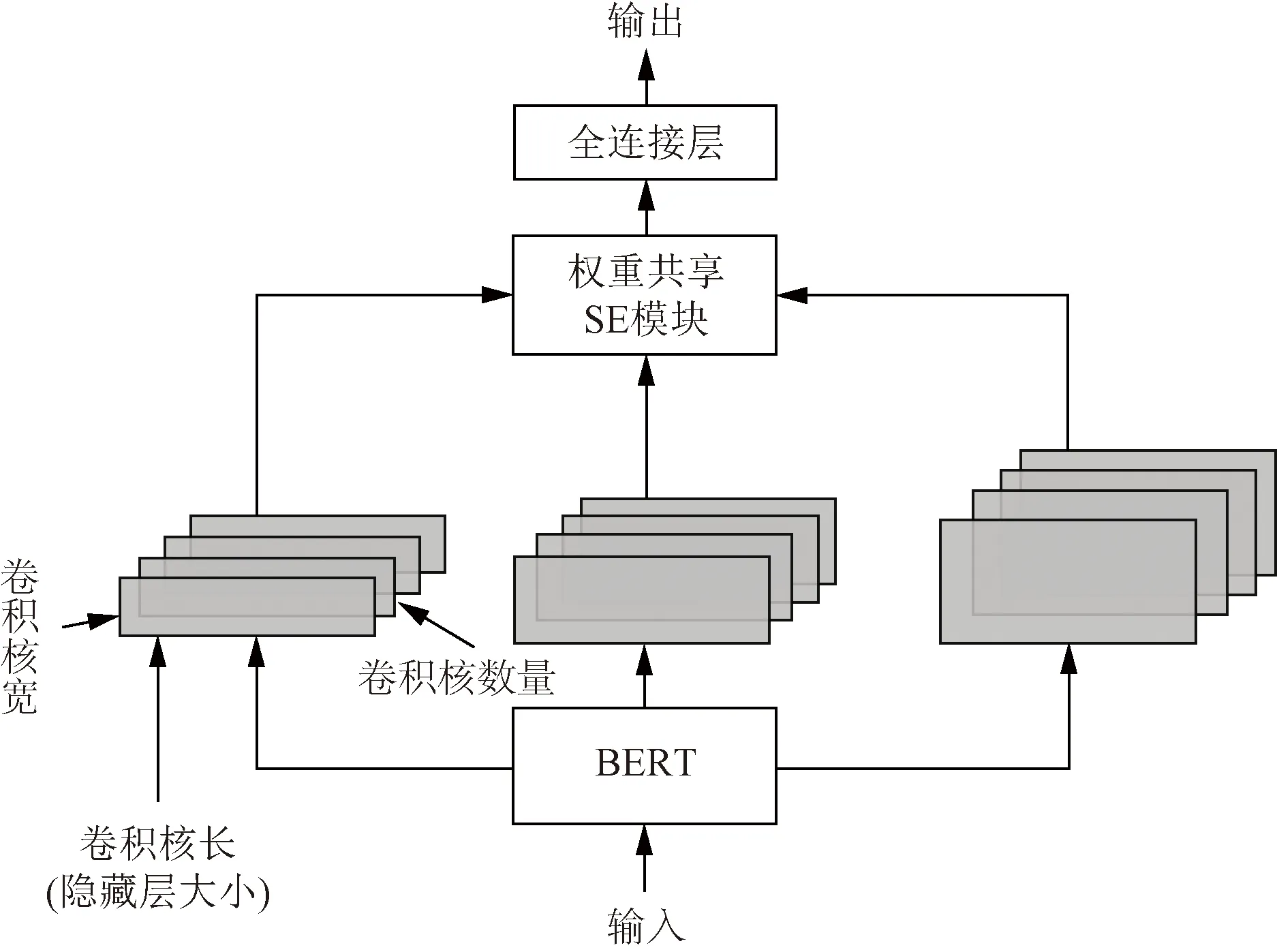
图4 改进BERT模型
1.2.1 SE模块
挤压和激励网络(squeeze-and-excitation networks,SENet)是Hu等[20]在CVPR2017上提出的网络。SENet通过建立特征通道之间的相互依赖关系,达到对通道的加权。具体来说就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。设C为通道数,L为序列长度,H为隐藏大小(经过卷积后变为1),r为减小比率,SE模块图如图5所示。
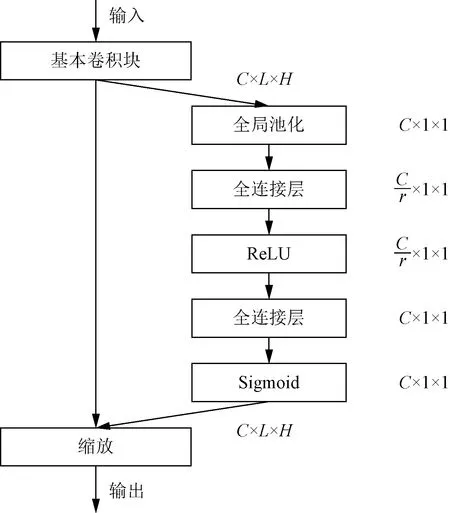
图5 SE模块
SE模块实现通道加权的具体过程如下。
(1)挤压(squeeze)。沿着特征维度(在改进BERT中为序列维度和隐藏维度)进行特征压缩,使用自适应平均池化(adaptive average pooling)将特征图使用变成一个实数,这个实数在一定意义上具有全局的感受野,它代表着在特征通道上响应的全局分布,因而使得靠近输入的层也可以获得全局的感受野,一定程度上弥补了卷积层过于关注局部特征的缺点。squeeze的公式为
(9)
式(9)中:zc为c通道特征图的平均值;Uc为c通道的特征图;H为隐藏大小;L为序列长度。
(2)激励(excitation)。激励操作可以学习各个通道之间的依赖关系,具体实现就是使用了全连接层-激活-全连接层-激活,利用全连接层和激活层的非线性来对通道之间的依赖关系进行描述。整数r为减小比率,可以限制模型复杂性减少参数量。excitation的公式为
S=Fex(z,W)=σ[g(z,W)]
=σ[W2δ(W1z)]
(10)
式(10)中:S为门控单元;z为全局统计向量;W1、W2为两个全连接层的权值矩阵;σ为sigmoid激活函数;δ为ReLU激活函数。
(3)加权(reweight)。将激励后的输出的权重视为每个通道的重要性,然后通过乘法沿着通道加权到先前的特征图上,完成在通道维度上的对原始特征的重标定。reweight的公式为
(11)
1.2.2 模型复杂度分析
BERT模型参数主要由嵌入层和Transformer块两部分组成,设词表大小为V,隐藏大小为H,层数为L,则参数量为VH+12(4H2+8H2)。BERT-base的H为768,L为12,假设词表大小为30 000,则总参数量为107 974 656≈108×106。
改进后的BERT模型增加了卷积层和SE模块,设卷积核的个数为n,卷积核高的组合为(a1,a2,…),卷积核的宽为H,通道数为C(C=n),减小比率为r,则增加的参数量为n(a1+a2+…)H+2CC/r。如果卷积核高的组合为(2,3,4),卷积核的宽即隐藏大小为768,卷积核个数为256,减小比率为16,则增加的参数量为1 777 664≈1.8×106。
改进BERT的参数量约为109.8×106,相比于BERT增加了1.67%。实验发现BERT-base的参数文件大小为426 MB,改进后的BERT参数文件大小为433 MB,与理论计算的文件大小一致。
2 实验与分析
2.1 实验环境
实验环境描述如表1所示。

表1 实验环境
2.2 实验数据集
2.2.1 原始数据集的获取
实验需要的犯罪类型会话文本由于法律规定的制约不能公开获取,为获得与研究最贴切的文本数据集,从字幕库网站(http://zmk.pw/)节选了《犯罪心理》中的一部分字幕。首先将字幕的SRT文件转化为TXT文件,然后将文本按对话时间进行切分并生成单独的TXT文档分类存储在名为“犯罪”和“日常”的文件夹中,一共制作了犯罪对话文本9 923条,平均轮数为3.3轮,日常对话文本15 596条,平均轮数为2.8轮。
2.2.2 实验数据集的处理
由于特殊符号不存在实际意义,因此用正则提取将特殊符号删除,由于在实际工作中可能遇到用数字谐音来指代的情况[21],例如“17 666”就是“一起溜溜溜(吸毒)”的意思,因此将数字替换为对应的汉字,之后通过融合拼音字符特征便能够将数字谐音识别出来。将“ ”替换为“/”可将对话文本置于一行便于观察且不丢失segment信息,“/”表示对话角色的切换(不替换而直接删除的话会将对话连成一句话而带来错误的语义信息,准确率会低约2%),最后将数据按照4∶1切分为训练集和测试集,生成train.csv、和test.csv文件,部分数据如表2所示。

表2 部分数据展示
读取数据集的时候使用jieba分词工具进行分词,将序列切分为独立的词并生成一个含有这些词的列表,然后使用预训练的分词器(Tokenizer)将这些切分好的词通过预训练词表的映射变成词在词表中的索引,通过这些索引就可以直接查询word embedding词典中对应的向量,具体过程示例如图6所示。
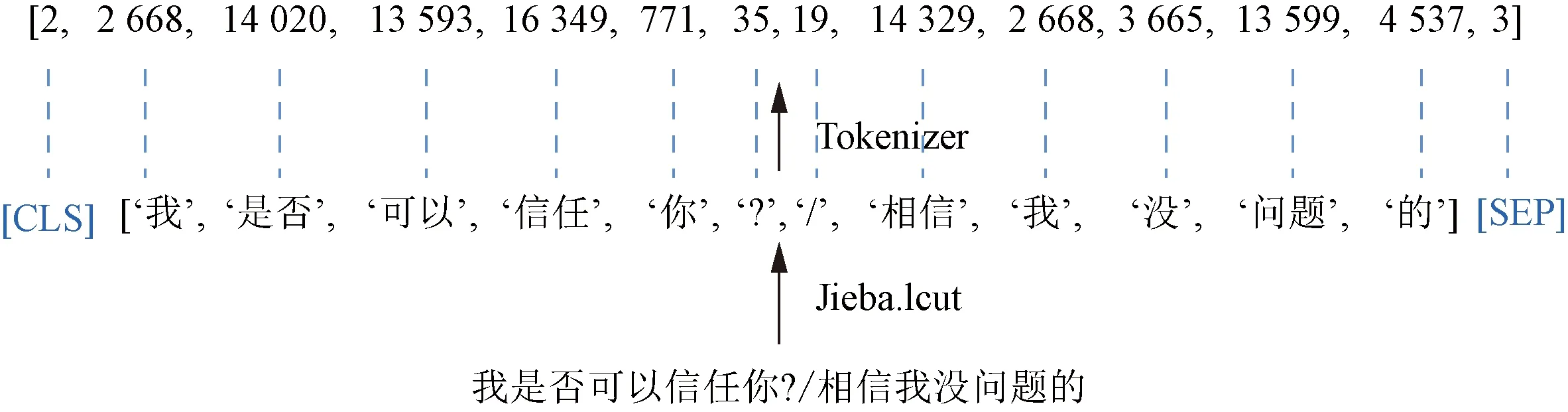
[CLS]为特殊类别词元,作为输入序列的起始符参与训练;[SEP]为特殊分隔词元,作为多文本序列的分隔符参与训练
2.3 实验过程
2.3.1 模型训练参数及配置
由于参数的选择对实验有着一定的影响,因此在显存允许范围内、尽可能提高训练速度、尽可能获得最佳准确率的情况下,就BERT基线模型进行调参,经过大量对比实验得出最佳超参数,如表3所示。
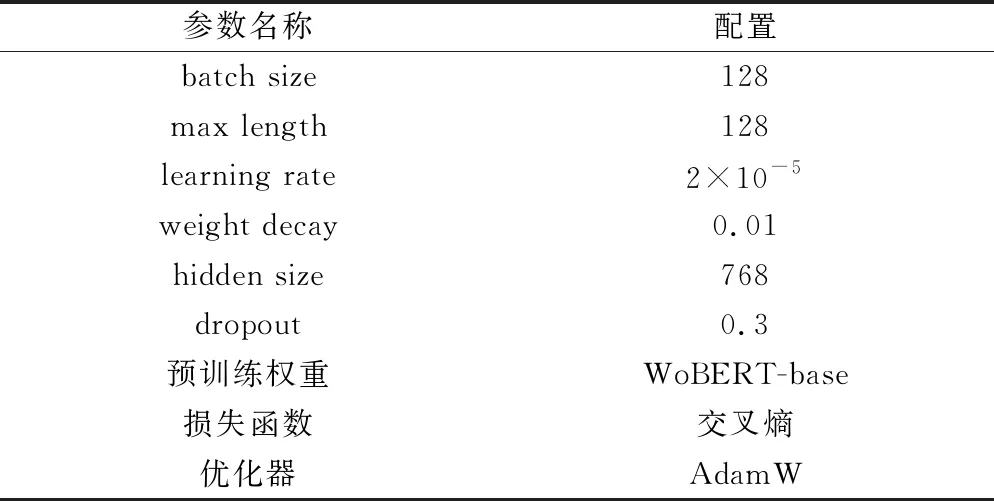
表3 参数及配置
2.3.2 输出层的选择
Jawahar等[22]通过一系列的实验证明BERT学习到了一些结构化的语言信息,比如BERT的低层网络就学习到了短语级别的信息表征,BERT的中层网络就学习到了丰富的语言学特征,而BERT的高层网络则学习到了丰富的语义信息特征。
由于BERT不同层学习到的特征不同,因此不同语义分布的数据在BERT不同层的输出进行分类准确率不同。为了探究数据在语义上的分布、输出层的选择以及输出方式的选择,设计了3种实验方案。
方案1:分别将每一层隐藏状态的第一个隐藏单元作为语义信息直接输入到全连接层进行分类,比较不同层第一个隐藏单元对语义的理解。
方案2:分别将每一层的隐藏状态按序列维度取均值作为语义信息输入到全连接层中进行分类。
方案3:将BERT每层隐层状态分别作为卷积层的输入,卷积核的高取2、3、4,宽为768(hidden size),卷积核个数为256,然后将经过了不同卷积核的输出使用SE模块进行通道加权,最后将3种输出连接起来输入到全连接层进行分类,比较不同层隐藏状态作为卷积层输入的结果。表4~表6是3种实验方案的结果,图7为表4~表6的对比图。
通过以上的对比实验可以发现,3组实验的每100次迭代的时长随层数上升而增加,因此层数越低,反向传播路径越短,计算图越小,训练时间越短。表4中负样本召回率最高的是第3层,为92.85%;表5中负样本召回率最高的是第4层,为92.31%;表6中负样本召回率最高的也是第4层,为91.06%。这说明低层对负样本的识别率最高,说明日常类里的短语级别的信息表征多,语言学特征少,语义信息少。表4中正样本召回率最高的是第8层,为86.80%;表5中正样本召回率最高的是第10层,为87.30%;表6中正样本召回率最高的是第10层,为87.86%。这说明高层对正样本的识别率最高,说明犯罪类里的短语级别的信息表征少,语言学特征多,语义信息少。 图7中平均值分层除第1层、第10层和第11层的正确率低于[CLS]分层外,其余均高于后者,计算得平均值分层的均值比[CLS]分层的均值高0.135%,因此使用隐藏状态在序列维度的均值进行分类比使用第一个隐藏单元进行分类效果要好。这一点已经被前人所证实, Reimers等[23]在SNLI和NLI数据集上验证了在使用BERT进行分类任务时使用计算均值的池化策略优于使用取[CLS]和取最大值的池化策略。根据图7中BERT+CNN+SE均处于[CLS]分层之上,计算得BERT+CNN+SE的均值比[CLS]分层的均值高0.747%。因此将BERT每层隐藏状态作为卷积层的输入,准确率均高于仅使用首个隐藏单元或隐藏状态的均值,说明使用CNN+SE后的模型对隐藏状态的语义理解更好。
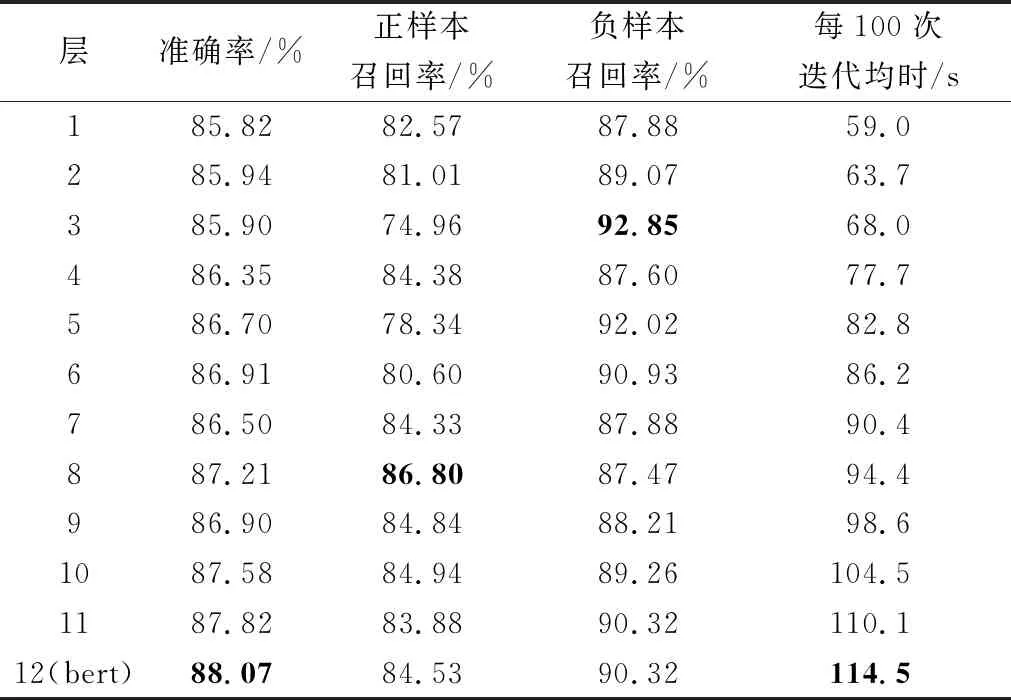
表4 使用每层的[CLS]进行分类
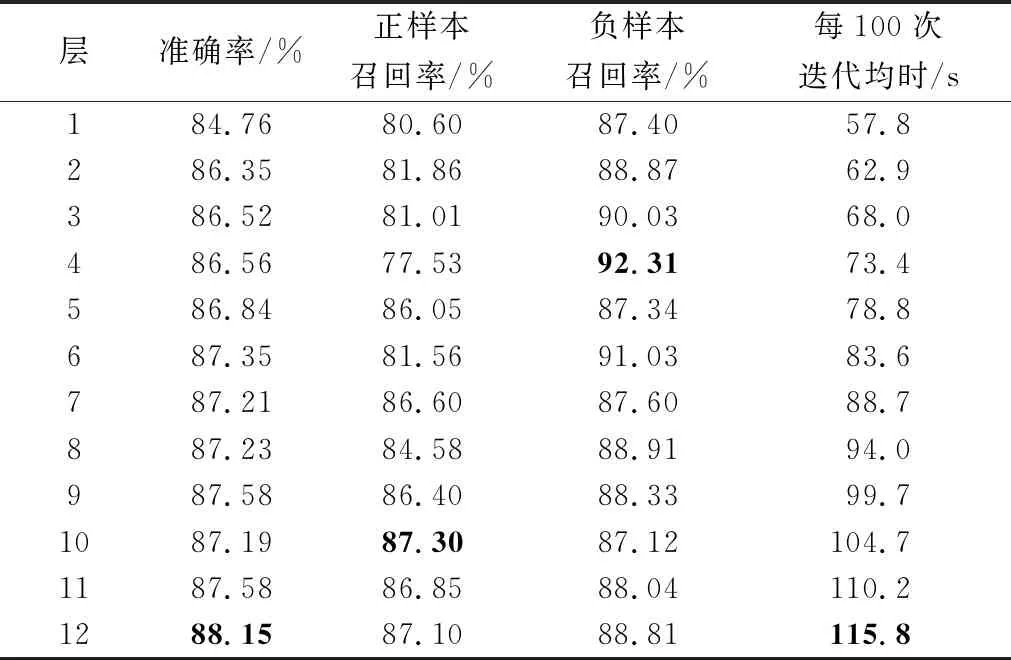
表5 使用每层的均值进行分类
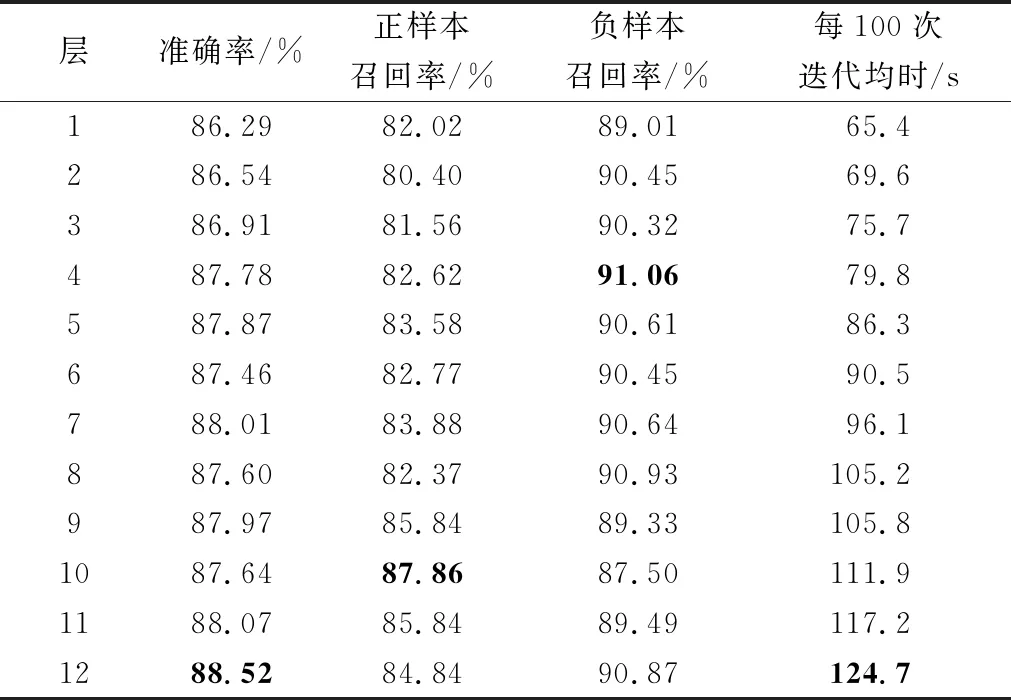
表6 使用每层隐藏状态+CNN+共享SE进行分类
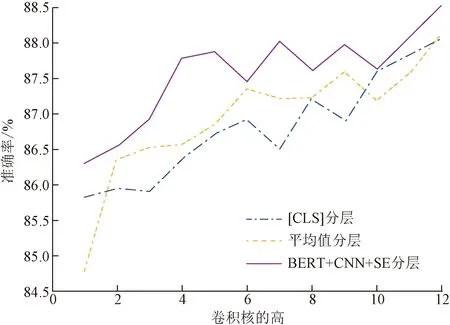
图7 不同层和分类方式对准确率的影响
2.3.3 SE模块和卷积核大小的选择
由于卷积核形状的不同会学习到不同词粒度的语义信息,从而给准确率带来影响,且SE模块一定程度上可以弥补卷积层过于关注局部特征的缺点。因此为了探究卷积核形状对准确率的影响以及卷积层后面的SE模块的作用,设计了两组对比实验。
(1)对比分别使用TextCNN模型和TextCNN+SE模型经过充分训练后在测试集上的最高准确率。以下为使用TextCNN经过多次训练得出的最佳参数:词表大小为50 000,隐藏大小为300,卷积核个数为256,学习率为0.001,随机失活率为0.3。以卷积核大小为自变量、准确率为因变量作曲线,结果如图8所示。
(2)对比BERT、BERT+CNN、BERT+CNN+SE的准确率,以卷积核的高的组合为变量,如(2,3)代表两种卷积核,大小分别为2×76和3×768,经过实验发现如果每种卷积核使用独立的SE模块,模型过拟合比较严重,因此采取了多种卷积核共用一个SE模块的方式。实验结果如图9所示。
通过图8和图9的对比实验可以发现,图8中TextCNN+SE始终位于TextCNN上方,计算得TextCNN+SE的均值比TextCNN的均值高0.56%,因此在TextCNN的卷积层后加SE模块可以提高模型准确率,说明通道加权对于扩大感受野具有一定的意义,在一定程度上可以缓解CNN过于关注局部特征的缺点。TextCNN在卷积核高为6的时候准确率最高,为86.93%;TextCNN+SE在卷积核高为8的时候准确率最高,为87.74%。 图9中,BERT+CNN+SE除(3,6)一种卷积核组合外,均高于BERT+CNN,计算得BERT+CNN+SE的均值比BERT基线高0.257%,比BERT+CNN高0.367%,说明在BERT+CNN模型的卷积层后加SE也起到了非常明显的作用,大幅提高了模型的准确率。BERT+CNN在卷积核组合为(3,6)时准确率最高,为88.33%。BERT+CNN+SE在卷积核组合为(2,6)时准确率最高,为88.58%。在BERT模型后单独加CNN进行高级语义特征提取效果并不好,受卷积核的组合影响较大,15种组合中只有6种组合超越了BERT基线模型,这些组合为(2,4)、(2,5)、(3,5)、(3,6)、(3,7)、(6,7),说明只使用CNN提取隐藏状态的高级语义信息不稳定。而BERT+CNN+SE的准确率一直高于BERT基线,说明使用共享SE模块后特征提取更加稳定。
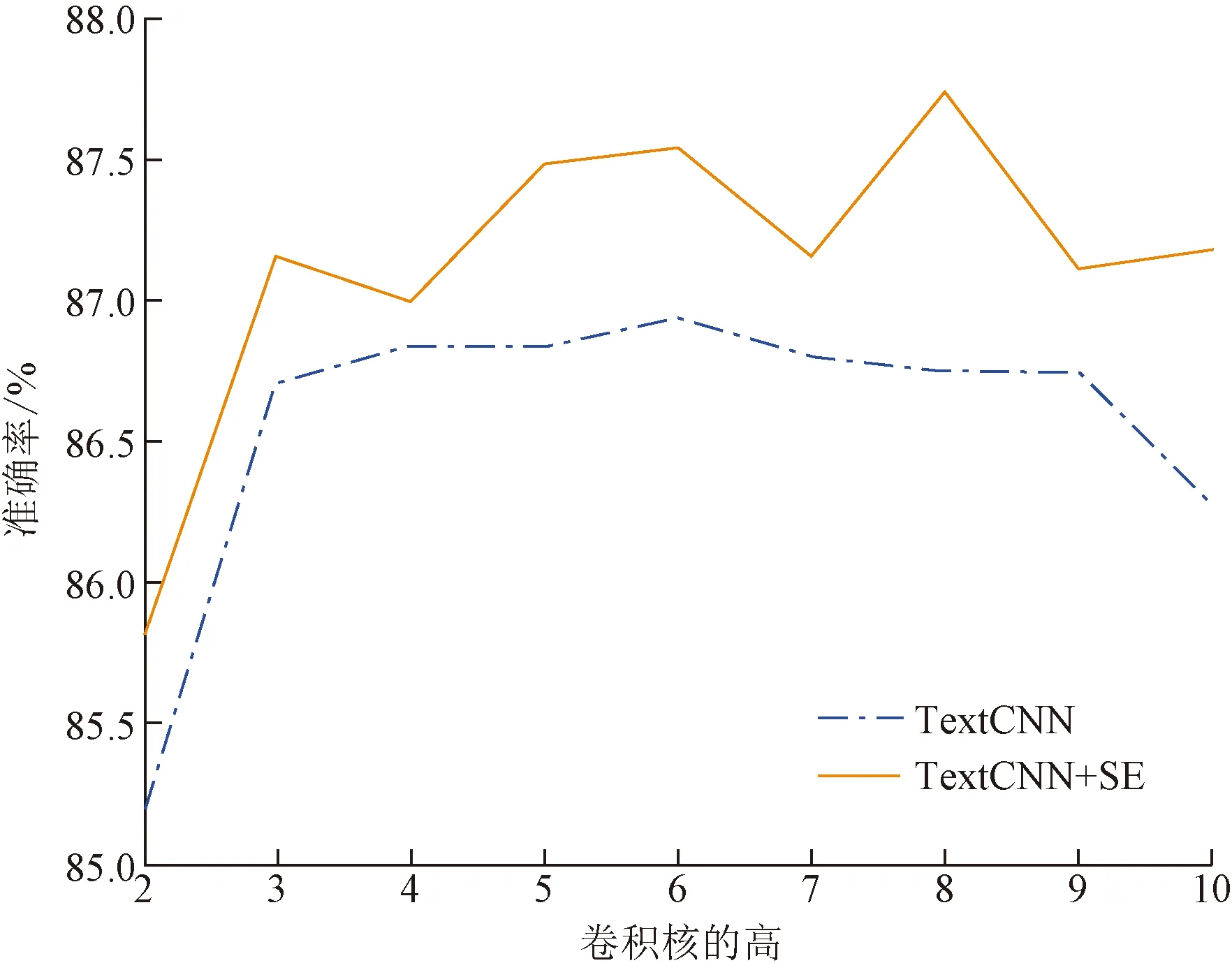
图8 TextCNN中SE、卷积核大小对准确率的影响
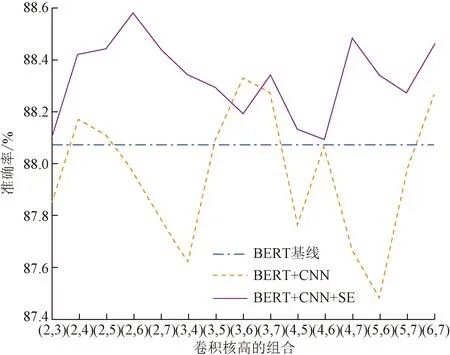
图9 BERT中SE、卷积核大小对准确率的影响
2.4 实验结果与分析
在实践中相比于日常文本的召回率,犯罪文本的召回率(正样本召回率)更值得关注,因此将涉案文本的召回率作为一项指标,根据2.3.2和2.3.3的实验结果,选择第12层隐藏状态作为卷积层的输入,选择卷积核大小组合为(2,6),卷积核数量为256,使用权重共享的SE模块。与BiRNN、BiLSTM、BiGRU、TextCNN以及BERT基线模型进行对比,实验结果如表7所示,其中加粗数据为该列最大值。
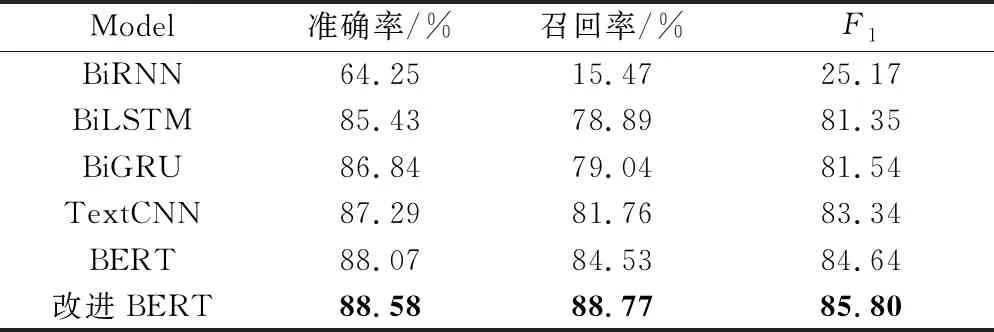
表7 不同模型的实验结果对比
实验表明,改进后的BERT模型准确率比BERT基线模型高0.51%,召回率高4.24%,F1高1.16%,相比于其他模型,改进后的BERT及基线BERT模型准确率都更高。不管是直接使用[CLS]位对应的隐含层作为句向量还是使用隐藏状态在序列维度的均值作为句向量,本质上都是池化操作,使用CNN+SE对隐藏单元的语义信息进行提取然后再进行最大池化也是一种池化操作,而后者在池化前进行了特征抽取,因而提取到的句向量更具有价值,因此使用后者提取到的句向量进行分类拥有更好的效果。
为了验证模型的有效性,在公开数据集THUCNews上进行了消融实验,THUCNews一共有14类,按类别比例随机抽取约48万条数据,每类样本数量如表8所示。
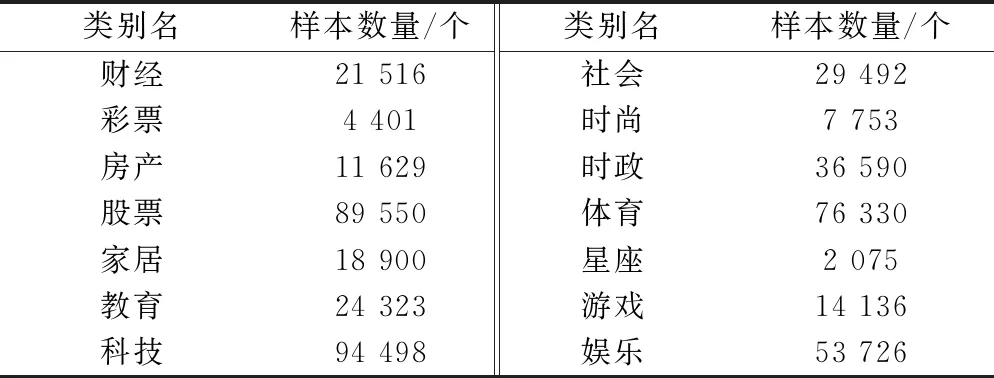
表8 THUCNews数据集的样本分布
将数据集按照5∶1切分为训练集和验证集,BERT和改进BERT模型都使用预训练权重“wonezha_L-12_H-768_A-12”,除预训练权重外其他训练条件均与2.3.1节一致,训练参数如下:训练轮数为100,批量大小为128,学习率为2×10-5,权重衰减率为0.01,隐藏大小为768,随机失活率为0.3。卷积核有4种尺寸,分别是(2,3,6,7)×768,每种256个,这是根据TextCNN-SE的大量实验得出的最佳尺寸组合,这种尺寸组合兼顾了粗细两种词粒度并在词粒度单一的情况下也有较好的表现。由于是多分类问题,且每类样本的数量比较不均衡,因此采用准确率和宏平均F1作为衡量标准,比较结果如表9所示,其中加粗数据为该列最大值。
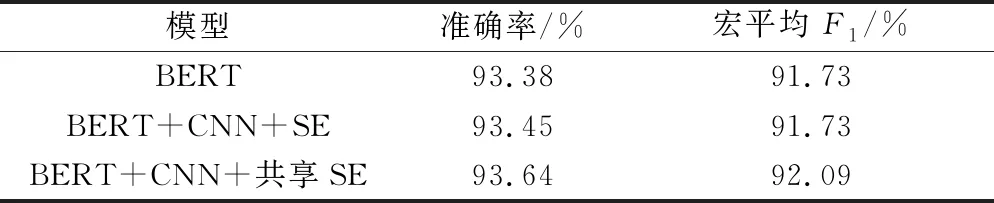
表9 在公开数据集上的消融实验结果
可以看出,使用了权重共享的SE具有更强的泛化能力,在准确率和宏平均F1上都超过了BERT基线模型,结果表明使用了CNN+SE对BERT最后一层隐藏状态进行提取以后再进行分类的效果优于直接使用[CLS]进行分类的效果,说明添加CNN+SE能够更加充分地理解高级语义信息,证明了改进模型的有效性。
3 结论
针对涉案文本取证的问题,提出了一种改进基于BERT模型的对话文本识别方法,实验表明改进BERT的准确率相比于BERT基线模型提升了0.51%,召回率提升了4.24%,F1提升了1.16%,同时,还与其他模型进行了对比实验,无论是准确率、召回率还是宏平均F1都比其他深度学习的基线模型要高,证明了改进BERT模型的有效性。同时还在公开数据集THUCNews上进行了验证,结果表明改进BERT的准确率相比于基线BERT提升了0.26%,说明改进BERT模型能够更好地提取BERT的隐藏状态的高级语义信息,在一定程度上提高了BERT模型的分类能力。
