基于NLP的政企类文本智能分类的实现与应用
2022-11-16胡文烨郭文涛李振业许鸿奎
胡文烨 郭文涛 李振业 许鸿奎
(山东建筑大学信息与电气工程学院 山东省济南市 250000)
1 引言
近年来,随着计算机技术的发展,各行业信息化建设水平也随之提高,政务部门出于对数据安全性以及政务处理智能化的考虑,对于政府的信息化建设也越来越重视。显然,政府的信息化建设必须借助于电子信息及数字网络技术,作为政府信息化建设中的关键一环,电子政务业务的实现并不是简单的将传统的政府管理事务及相关数据由纸面迁移到互联网上,而是要利用互联网技术给予它们第二次的生命。政府相关管理事务需要在互联网上进行组织结构的重组以及业务流程的再造,简单来说是需要以信息化的方式重塑业务;而政府在管理运行中产生的数据,也需要在重新整合存储的基础上进行更加智能化的分析和利用。
2016 年国家首次在政府工作报告中提到了“互联网+政务服务”的概念,将互联网、大数据等信息技术与政府工作紧密连接起来[1]。实现“互联网+政务服务”的核心是政务大数据的互通共享,而政务大数据则要依赖信息化、智能化的系统。信息化、智能化的系统可以帮助政务部门提升工作效率及准确性,并同步留存关键性的操作数据。在政府及中大型企业中,目前存在并持续产生的信息形式以文本信息为主,而如何整理文本信息本身就是一个复杂又消耗时间的过程,因此如何在大量且复杂的文本信息中获取到对使用者来说有价值的信息是文本挖掘领域的核心目标。文本挖掘是一个涵盖多种技术的新兴领域,它可以实现利用计算机处理技术从文本数据中抽取有价值的信息和知识,同时利用抽取到的知识来更好的组织信息,以便进行下一步的利用。这个过程类似于人类学习知识又加以应用的过程。它的实现技术包括了数据挖掘技术[2]、信息检索[3],机器学习[4]、自然语言处理(natural language processing,NLP)[5]、计算语言学[6]、线性几何[7]、概率理论[8]等。表达文本数据最直接的方式就是语言,任何事物都可以通过语言来表达意图,政企类文本数据作为自然语言的一种表达形式,从这个角度上来说,自然语言处理是实现政企类文本数据与计算机之间通信的最合适手段。
文本分类作为文本挖掘领域最基础且最重要的应用,在政企类文本信息的挖掘中有着举足轻重的作用,它能够很好的解决大数据时代数据量大且难以梳理的问题。以政务部门接线12345 市民热线电话[9]业务为例,业务员在接到电话后需要根据群众提供的信息首先在新工单中将其整合为事件描述,然后需要根据个人业务经验选择事件处理的部门,由被派单的部门在确认后处理,否则工单将被退回重新指派。实际上,接线员的个人经验参差不齐,派单时更多依赖个人想法,且每天接线数量巨大,给整体的派单准确率和处理效率都带来了很大影响,从而影响政府服务的群众满意度。而政企类文本的数据来源不仅限于此,社会治理中网格员的事件上报、政府公开网站中群众反映渠道、各镇街搜集民意反馈的信息等,来源广泛、格式风格不同的数据源成了文本分类中首先要解决的问题。
人们对于文本分类这一文本挖掘应用的研究始于上世纪的50 年代[10]。在此之前一直采用手工分类的方法,直到Luhn 提出的词匹配法开始走进人们的视野[11],但这种方法由于其简单机械的特点无法取得好的分类结果。60 年代以后,Maron 发表了有关自动分类的第一篇文章,把文本分类技术发展向前推进了一个台阶。此后一直到2010 年前后,在文本分类领域占据主流地位的一直是基于浅层学习的模型,例如朴素贝叶斯方法(Nave Bayes,NB)[12],K 近邻(K‐Nearest Neighbor,KNN)[13]和支持向量机(Support Vector Machine,SVM)[14]等。
随着人们对深度学习的不断深入挖掘,自然语言处理领域的难题也得到了不断突破,通过自然语言处理可以实现人与机器之间的交流。在文本分析领域,NLP 做了很大的贡献,而通过结合NLP 与文本分析,可以帮助政府和企业在政企类文本大数据中获取更多重要的信息,从而产生巨大的数据价值。2005 年,柳炳祥、章义来等人将关联规则和决策树两种数据挖掘技术应用到电子政务数据分析中[15],并进行了相关研究,为电子政务数据分析提出了一种新的研究思路。2021 年,李铭鑫等人从自然语言处理的角度对政务留言文本的分类问题进行了研究[16],将机器学习中的逻辑回归算法、朴素贝叶斯算法以及深度学习中的TextCNN 及TextRNN 算法做对比,得出文本一级分类时TextCNN 效果优于其他算法。在市民服务热线接线分析场景,杨欢提出了Word2vec‐TLSTM‐Attention 的融合神经网络模型进行分类[17],同单一网络神经模型相比,取得了更好的效果。
上述的研究主要应用于语义的简单分类,例如语句的情感分析或大意理解。然而,随着业务需求不断提高,对于语句具体含义的理解以及语义与宏观对象的映射关系的分析这类复杂的现实任务,上述研究所提出的模型并准确率低且泛化性差,极易出现过拟合问题。而在中文的政企类文本智能分类任务中,其文本内容具有文本较长、信息冗余、映射关系复杂、文本质量不一等特点,对于数据处理方法与模型的性能提出了极高的要求。目前,对于中文政企类文本自然语言处理方法的研究大多停留对于简单模型的应用研究,不能满足实际应用需要,工程落地困难,因此,亟待研究一种拟合能力强,泛化性能好的政企类文本智能分类方法。
本文用于训练及学习的数据集来自于社会治理脱敏数据,包含了市民热线、网格员上报、市民信箱、微信公众号等渠道,数据来源比较复杂。基于NLP 领域目前的相关研究成果以及前辈老师们的处理经验,在文本预处理阶段,本文采用了jieba 分词、去停用词、LDA 主题模型过滤、Word2vec 词向量转化等自然语言处理手段;在文本分类研究中对比了DNN、CNN、LSTM、GRU、BERT 等模型的分类效果,在使用经典的BERT 预训练模型的基础上,对其中的部分参数和训练方法进行调整,最终得到的模型及参数得到了81.47%的分类准确率,相较于其他算法具有明显的提升。同时,BERT 作为一种无监督预训练模型,通过已经训练好的编码器具备的中文阅读理解能力,可以应用于不同的业务场景。此外,本文从模型及技术实际应用的角度,分析了其在实际工程生产中的应用价值。
2 文本预处理
在实际的中文文本分类研究中,原始的中文文本数据经常会存在许多影响最终分类效果的内容,这部分数据或文本如果不加处理,直接交给模型去学习,会导致模型无法准确获得文本数据的特征和语义重点,从而会导致模型准确率低。因此文本预处理的步骤是帮助文本数据更加符合模型的输入要求而产生的,所有待学习的文本数据都需要在进入文本分类模型之前就被清洗干净,科学的文本预处理环节可以起到有效指导选择、提升模型效果的作用。文本预处理过程包含的主要环节有数据清洗(包含缺失值处理、去重处理、噪声处理、特殊文字处理等)、文本处理(包含分词、词性标注、命名实体识别等)、文本张量表示(包含文本编码、词向量表示等)、文本语料数据分析(包含长度、特征、词频等的统计分析)、文本特征处理(包含特征增强、长度规范等)以及数据增强等。
文本数据进行预处理前,首先对数据情况进行分析,以方便确定数据处理方法。每一次文本预处理都应该先明确最终你希望把原本的文本数据处理成什么格式或者样例。本文研究的数据为政企类文本数据,数据信息具有复杂性和多变性,且根据分类目标来看,分类数量多,原始可用数据量约12.3 万条,文本分类的类型数量约为90。因此本实验对于文本数据在预处理阶段能够达到的处理效果有更多的期待,也需要采用更多的方法和途径来提升文本数据与分类模型之间的匹配度。因而在本实验中,从数据的处理前分析、数据去重、文本过滤、文本主题挖掘、文本词向量表示等环节都采用了多种方法进行效果比较,最终以最优的方法进行组合,完成文本数据的预处理过程。
2.1 数据去重处理
政企类文本数据的特点是内容多,文本的固定位置具有重复现象。针对某些政企类文本数据来说,数据的开头和结尾分别有表示数据来源的信息以及固定的需求表达,或具有某种特定规律。对于文本数据的分析过程来说,这些对类别特征区分没有贡献的文本都是干扰因素,将会影响模型的分析效果,因此首先应当做去重处理,提取对文本智能分类的分类依据有实际贡献的文本信息。比如在本次实验数据中,来源于12345 市民热线的文本数据,由于数据是经过接线业务员转述进行重新组合而成的,因而在数据结构上显得较为标准。
以某条文本数据为例:张先生来电,某某小区门口某某路上下水井盖松动,有安全隐患,请派人维修。处理后请回复。
在以上文本数据中,“张先生来电,”和“处理后请回复。”在所有文本中较为标准,位置固定且内容重复,因此可以认为,其存在对于模型特征的学习并没有贡献,需要进行数据去重处理。
2.2 文本过滤
文本过滤是在对文本数据进行去重处理后进行的,主要是对数据去重后留下的文本信息主体进行模型可用信息的过滤提取。常见的处理方法有去停用词[18]、词性标注、命名实体识别等。经过对于文本数据特点的分析,在单条文本描述中,经常涉及身份证号、手机号等数字字符以及楼牌号等字母字符,以及部分固定的表述方式。这些具有干扰性的文字描述,可通过去停用词环节进行处理,即选取合适的中文停用词表(stop word),再根据业务场景增加部分特有的停用词,形成具有针对性的专用停用词表。然后对全量的政企类文本数据进行文本过滤。而词性标注及命名实体识别的使用,往往在需要筛查分析不同信息时进行使用,对于文本过滤也有很大的意义。例如在文本数据描述中出现地名及姓名等,这些都是模型学习分类特征不需要的信息,可以通过对于单条文本数据词性的认定以及命名实体识别来筛查去除固定词性及命名实体,从而达到文本过滤的效果。
2.3 文本主题挖掘
在文本数据描述较长,通过数据去重及文本过滤又没有达到很好的清洗效果时,可以针对性的进行文本主题挖掘的处理。即利用文本分析模型进行文本特征学习时,将文本数据中挖掘到的主题描述结果,作为输入的文本特征用于模型训练,其实际效果可根据模型学习及分类效果进行验证。将过滤后的文本利用中文分词和文本编码进行处理,在此基础上,采用文本主题挖掘模型提取文本主题关键词组,形成文本主干;或采用中文词法分析进行文本词性标注并针对性的去除某些词性的词语,得到文本关键词组。文本主题挖掘的过程包括词干的提取、停用词的去除、同类词或语义相近的词条间的合并、主题排序等。通过文本主题挖掘后得到的主题应是彼此间含义不同的一组词语,且文本信息中较为核心的主题词汇将排列在前,而用户有权在主题挖掘后根据需要选择生成主题词的数量。
文本主题挖掘可采用TF‐IDF 算法[19]、TextRank 算法以及LDA 主题模型等,在TF‐IDF 算法中,其计算过程如式(1)(2):
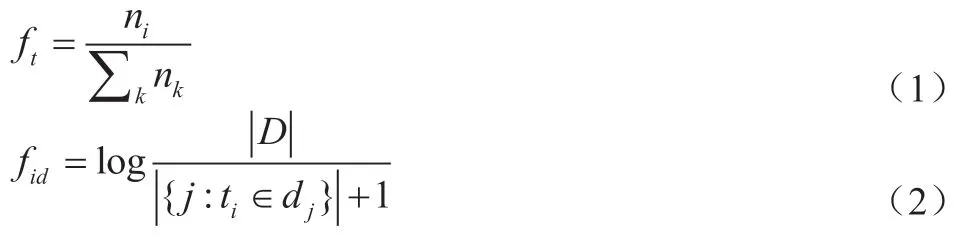
其中,ft为词频,ni,j表示某个词在该文本中出现的次数,表示该文本中包含的总词数;fid为逆向文件频率,|D|为语料库中所有文档总数,为包含词语ti的文档数,分母可能出现等于0 的情况,因此使用
在面对某些场景时,可使用改进后的词频计算公式如式(3):

其中,maxk(nk,j)表示该文本中出现次数最多的词的出现次数
最后计算TF‐IDF,只需要将计算的tf 值与idf 值累乘就得到了某个词在当前文本中的权重值,经过所有词权重的排序,就能根据词的重要程度保留文本主题。但TF‐IDF 的计算过程决定了它对于长文本数据的主题抽取效果较好,对于简短的文本数据结果则不尽如人意,况且其精准度很大程度上依赖算法使用的词表是否合适。
TextRank 算法是一种无监督的主题抽取算法,它不依赖于其他语料,可以直接从文本中挖掘主题词。它的弊端和TF‐IDF 算法类似,在长文本数据中表现较好,而且它需要进行迭代计算,所以效率会随着迭代次数的增加而降低。采用TextRank 算法进行关键词提取,主要步骤如下:
将文本T 按照一个句子进行分割,得到T=[S1,S2,...,Sn];
(2)根据保留的关键词构建有向有权图G=(V,E),其中V 为点集合,E 为边集合,图中任意两点Vi,Vj间的边权重为Wji。
(3)设窗口大小为K,根据以式(4)计算词语得分:
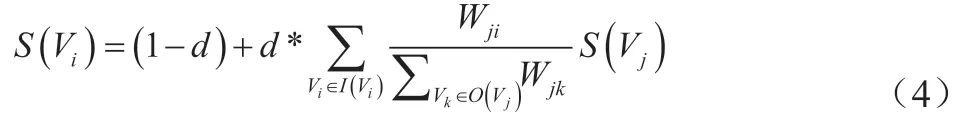
其中,S(Vi)为词语得分,I(Vi)为指向Vi点的点集合,O(Vj)为Vj点指向的点集合。根据公式进行迭代传播,对各节点得分进行排序,得到文本T 的关键词。
LDA 主题模型方法是一种基于贝叶斯模型诞生的无监督的方法,可以自由选择需要计算的主题词语数量,在使用LDA 模型进行主题挖掘前,需根据要处理的文本数据训练出LDA 模型,模型将自主学习文本数据中的词语重要性,政企类文本数据较为规范,特征比较密集,因此在采用LDA 模型时能得到较好的效果。
2.4 文本向量化表示
文本向量化是将文本表示成众多能够表达文本语义的向量。文本向量化模块实现对文本集合的数值向量化表示,向量化后的文本集合可以被文本分类模型识别和计算。词语是表达文本信息的最基本处理单元。当前对文本向量化大部分研究都是通过词向量化实现的,但也有doc2vec 和str2vec方法将文本和句子作为基本处理单元。为了更好的挖掘句中包含的词语含义,区分多类特征,本文采用词袋模型处理词向量化的方法进行文本向量化表示。
以词语为处理单元的方法为word2vec 方法[20]。word2vec 方法是基于样本数据中出现的词语构建词典作为索引,通过统计每个词语出现的词频构成向量。word2vec本质上是一种简单的神经网络,它分为CBOW 和Skip‐gram两种训练模型。CBOW 和Skip‐gram 模型在进行处理时目标不同,CBOW 模型是根据周围的单词预测中心单词,而Skip‐gram 模型则相反。其原理分别如图1 和图2 所示。
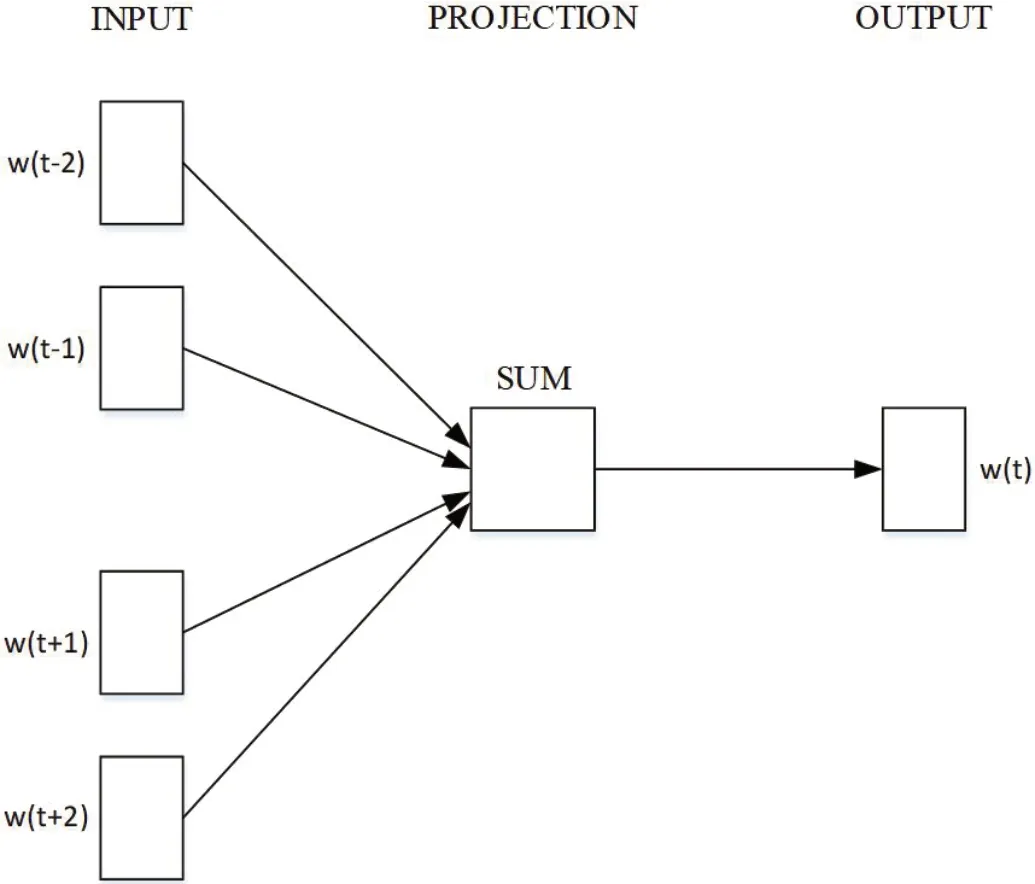
图1:CBOW 模型训练原理图
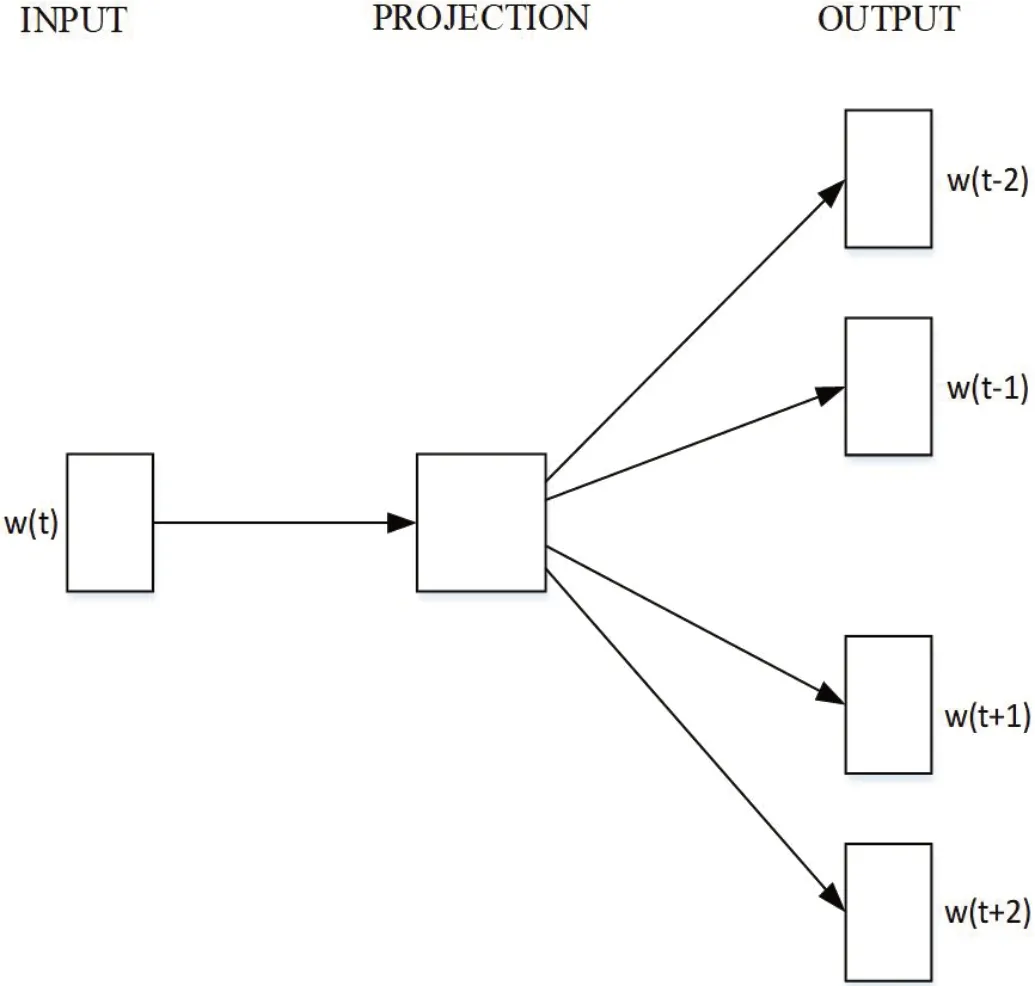
图2:Skip-gram 模型训练原理图
采用gensim 工具包中的word2vec 模型可快速得到文本向量化训练结果。
3 文本智能分类
文本分类作为一种信息组织和管理的有效方法,在诸多方面有着重要的应用,如情感分析、垃圾邮件识别、推荐系统、文档分类等。将原始数据进行去重处理、文本过滤、文本主题挖掘等文本预处理过程后,得到处理后的数据集。再根据分类模型对数据集进行处理准备工作。在分析了各种市场主流的文本分类模型后,拟使用比较的分类模型有深度神经网络、卷积神经网络、反馈神经网络等。
DNN 模型是基本的深度学习网络,拥有全连接的神经元结构,包含输入层、隐藏层、输出层三部分,使用场景比较广泛。卷积神经网络例如CNN,它最初在图像领域取得了巨大成功,其核心点在于可以捕捉局部相关性,TextCNN是基于CNN 模型,针对文本领域创造的卷积模型,做文本的特征表达工作。循环神经网络RNN 是NLP 领域常用的模型,它允许信息的持久化,但RNN 容易出现梯度消失或者梯度爆炸的问题,LSTM 和GRU 是改进后的两种算法模型。LSTM 是一种特殊的RNN 模型,是为了解决长序列训练过程中的梯度消失问题而产生的,由4 个全连接层进行计算,与原始的RNN 相比,LSTM 增加了一个细胞状态,模型的核心结构如图3。
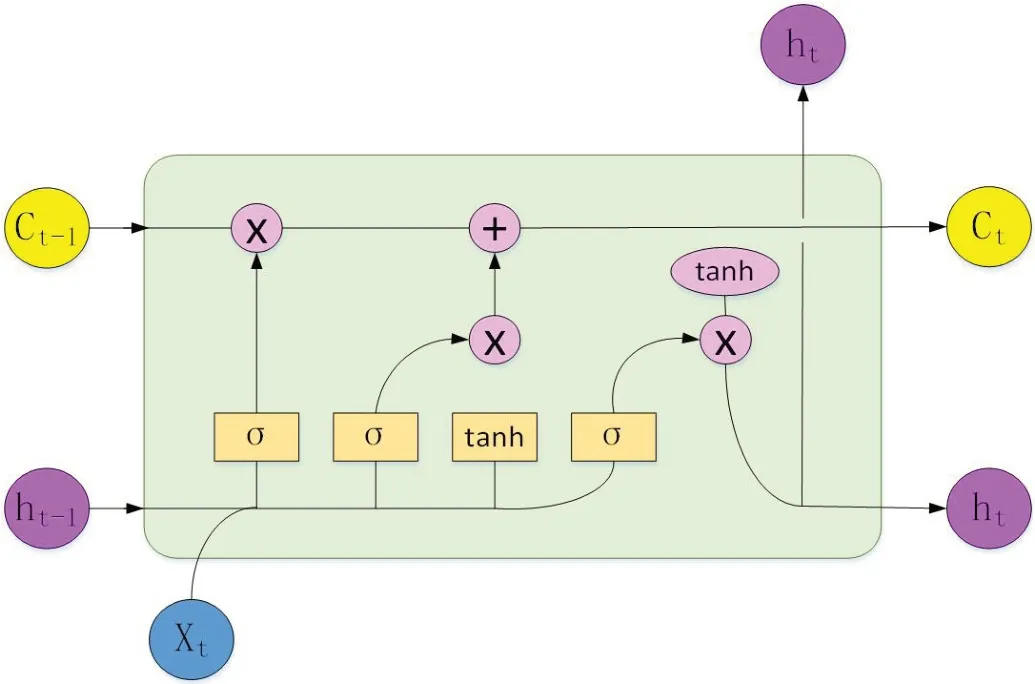
图3:LSTM 模型核心结构图
其中,模型输入有三部分,即Ct‐1为细胞状态信息,ht‐1为隐层状态信息,Xt为t 时刻输入向量,输出有两部分,分别是:细胞状态信息Ct,隐层状态信息ht。细胞状态信息和隐层状态信息按照不同的线路进行传递,它们之间的交互叫做“门”结构。在“门”结构中,σ 表示sigmoid 函数,它的输出在0 到1 之间,tanh是双曲正切函数,它的输出在‐1到1 之间。GRU 则是LSTM 网络的一种效果很好的变体,相比于LSTM,它的计算更简单,计算量也比较低,GRU和LSTM 都是通过各种门函数来将重要特征保留下来,二者实际效果的优劣需针对不同场景来看。
对于语言分析领域,谷歌提出了基于双向Transformer特征提取器的BERT 模型[21],相较于原来的RNN、LSTM 等,它可以在多个不同层次同时提取词在句子中的关系特征,从而能更全面的反映句子意思。BERT 模型的架构图如图4。
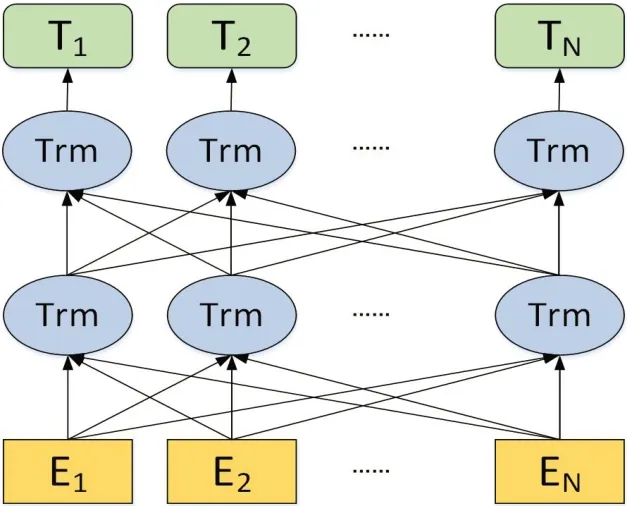
图4:BERT 模型内部架构图
从模型架构图中很明显可以看出,BERT 模型采用的是双向编码,是一个基于双向transformer 的模型,它可以共同调节left‐to‐right 的transformer 和right‐to‐left 的transformer。此外,它将预训练模型和下游任务模型结合在一起,它更注重于识别句子中单词与单词之间的关系或者是句子与句子之间的关系,它采用一个半监督学习和语言来表示模型。在预训练阶段,BERT 使用无监督的预测任务执行预训练,该任务包括下文遮蔽的语言模型MLM(Masked Language Model,MLM)[22],在执行完预训练后,BERT 模型会针对下游任务进行fine‐tune 来微调模型参数,以达到最适应的效果。
4 实验与分析
本实验的原始数据量约12.3 万条,文本分类的类型数量约为90。原始数据采用随机划分的方式,以8:1:1 的比例划分为训练集、验证集、测试集,使用训练集训练模型,选取在验证集中表现最好的模型,在测试集中测试模型分类准确率,以测试集的准确率作为实验的评价指标。
划分数据集后,将每个数据集进行一定的文本预处理。为适应各类模型的输入要求,实验中采用的文本预处理方法包括根据文档中文字出现频率训练编码器,文本去重、过滤并编码,文本去重、过滤、提取主题并编码,BertTokenizer编码器,文本去重、过滤、提取主题、BertTokenizer 编码器等。
将处理后的输入量输入分类模型,进行文本智能分类训练,并在训练过程中调整各训练参数以寻求更优结果。在实验结果分析中,发现在文本预处理过程中将文本处理的越详细,模型获取到的特征越清晰;在模型的互相比较中,BERT 模型在经过参数调优后取得的效果明显优于其他模型,因此着重对BERT 模型的实验过程进行介绍。
首先使用transformers 中的BertTokenizer 编码器对文本进行编码,其次对编码数据进行预处理:
通过分析,添加特殊编码[CLS]、[SEP]、[UNK]等标志以帮助执行分类任务。
构建输入矩阵:输入矩阵存放编码结果;辅助矩阵使用全零矩阵;注意力掩码矩阵用于记录输入文字长度;标签矩阵存放类别标签。
在模型微调环节,使用预训练模型,对模型进行fine‐tune 微调。具体过程为:
(1)获取模型:获取预训练模型结构与参数;
(2)分类模型构建:在预训练模型后添加MLP 分类器,采用激活函数softmax;
(3)模型优化:优化器使用Adam 优化器,设置参数solver 为’adam’,损失函数为稀疏分类交叉熵;
(4)模型训练。
在完成全部模型的训练及测试后,得到最终测试集准确率,多次实验后各模型及不同编码方式的分类效果对比如表1 所示。
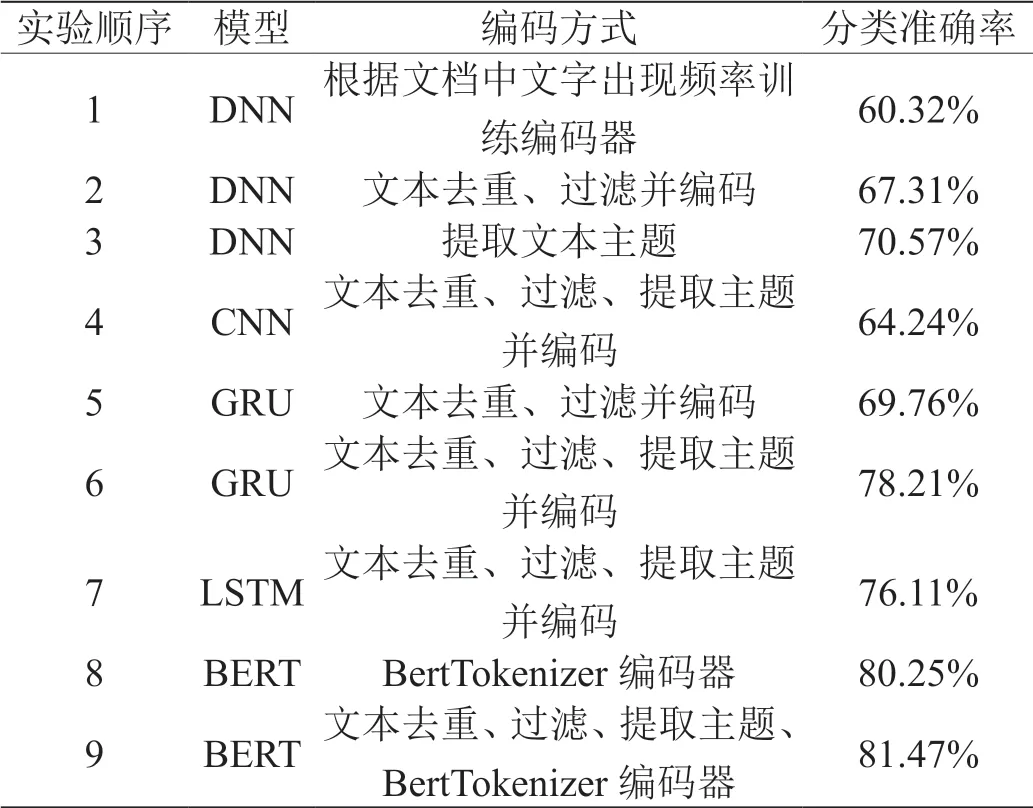
表1:各模型及不同编码方式的分类效果对比
在对各类模型进行参数优化以及编码方式的不同效果对比后,可以看出,DNN 作为最基础的深度学习算法,在模型未加改进以及优化的前提下准确率较低,而作为后续出现的CNN 以及GRU、LSTM 等算法都针对文本智能分类工作表现出了各自的优势,其中BERT 作为建立在双向transformer 上的语言处理模型,以其强大的中文文本理解能力以及模型参数微调的能力取得了相对较好的结果,面对分类种类多、原始数据有倾斜的样本现状,也有较好的表现,完成了预期实现的目标。而在编码方式上,通过数据对比可以得知,提取文本主题作为模型输入的方式能够使模型更好的学习样本特征,在不同的模型中均有准确率提升的效果。
5 实验结果分析及应用
5.1 实验结果分析
本实验针对数据原始特征及特性,从各个实验环节提高了实验效果。对于样本类别不均衡导致的部分类别特征少,很难从中提取规律的情况,在具体分析模型效果后,采用了BERT 预训练模型,使得模型获得足够优秀的中文阅读理解能力,再使用fine‐tune 的微调方法实现文本分类任务的需求,降低了对于样本数据的依赖。对于传统分类模型带来的严重过拟合现象,采用了MLM 对双向的Transformers 进行预训练,以生成深层的双向语言表征,有效的提升了模型的特征提取能力。同时,通过迁移学习的方法有效的解决了模型过拟合问题。在通过对实验模型的组合和改进后,最终获得了81.47%的效果,优化了传统方法和数据本身特点带来的弊端,唯一值得注意的是,整个训练过程往往需要强大的算力来支撑。
5.2 实验结果应用
实际工程项目中的政企类文本数据来源广、数据质量不一,用于分析的数据量收到实际情况的限制,因而在解决政企类文本分析相关问题上仍然是一个需要研究的课题。通过以及训练好的模型具备的中文阅读理解能力,可以应对实际工程中超过80%以上的识别需求。
近年来,智慧城市的建设渐渐成为数字化政府建设的重点需求,而社会治理作为政务服务管理中的重要环节,对于民情事件的智能化流转和迅速响应是核心需求。基于NLP的政企类文本智能分类,可以以民情事件的责任部门作为分类目标,为部门设定分类标签,设置业务流程,以文本智能分类手段替代常规人工业务流转,从而实现系统的事件智能分派功能,节省人工成本、提高处理效率的同时,为城市建设赋予更多的智能化元素。
此外,政务服务部门作为工作量较大、民众需求比较集中的部门,为更快更好的解决民众实际问题,也需要以智能机器人的形式辅助政务服务工作。在保证民众满意度的情况下,面对各式各样的群众需求,政企类文本智能分类的实现备受关注,因而通过分析文本智能分类工作可以大大提升群众满意度和政务工作的积极性。政务工作的业务需求也是推进NLP 领域迅速发展的主要因素。
