基于Bi-LSTM模型的自媒体文本情感分类方法
2022-11-16张伟娟董蕾王蒙
张伟娟 董蕾 王蒙
(山东电子职业技术学院 计算机与软件工程系 山东省济南市 250200)
自媒体文本情感分析是主要对文本数据进行情感倾向分类,获取人们的观点、看法、态度、立场等[1]。网络舆情具有自由、开放、隐蔽等特点,数量庞大且受众群体多样,因此能够在互联网中快速传播。通过自媒体热点话题可以分析用户的观点以及立场,在舆情发酵扩散之前,掌握并预测用户情感倾向,可帮助决策者进行提前处理[2]。
1 相关工作
早期文本情感分析研究主要基于词频特征、情感规则、情感词典等进行统计分析[3]。近年来,情感分析主要是采用机器学习、深度学习的方法构建分类器[4][5]。常用的机器学习方法有朴素贝叶斯、支持向量机、K 近邻、随机森林、决策树等。目前国内外有一些相关的自媒体文本情感分析产品。Global Pulse,是由联合国新发起的行动计划,所研发产品能够对全球情感波动情况进行监测[6]。在采集主流自媒体平台的舆论数据后,研究者们以此来分析公众情感并预测其变化趋势,给政务管理、金融、新闻传媒等诸多领域带来重大作用和影响[7]。各大社交网络平台,具有庞大用户基数且拥有海量数据,为文本情感分析提供了数据源[8]。
本文构建基于Bi‐LSTM 模型[9]的文本情感分类器,在该模型的Embedding 层利用Word2vec 模型[10]训练该层参数,通过标注好的带有情感标签的训练数据集对分类器进行训练,对实时采集到的自媒体文本数据进行情感分类预测,并为用户提供可视化的话题舆情监测。
2 数据集
本文选择2 个公开的训练数据集进行情感分析。
(1)数据集1:开源数据集weibo_senti_100k,涵盖共119988 条新浪微博及其对应情感标注,正向情感标签为1,负向标签为0。数据集1 情感分布详情如图1 所示。
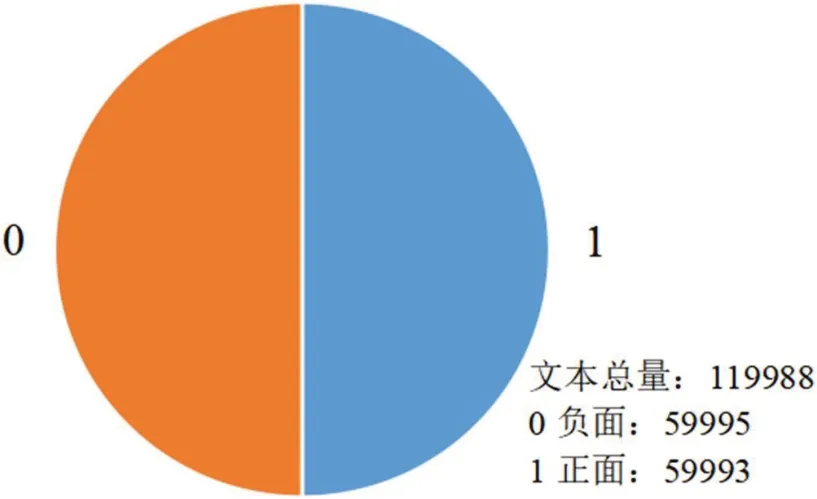
图1:数据集1 数据分布情况
(2)数据集2:开源数据集simplifyweibo_4_moods,共有361744 条新浪微博文本及其对应情感标注,包含的情感类别共有四种:喜悦、愤怒、厌恶和低落。与数据集1 相比,该数据集的标签分类更为详细。数据集2 情感分布如图2 所示。
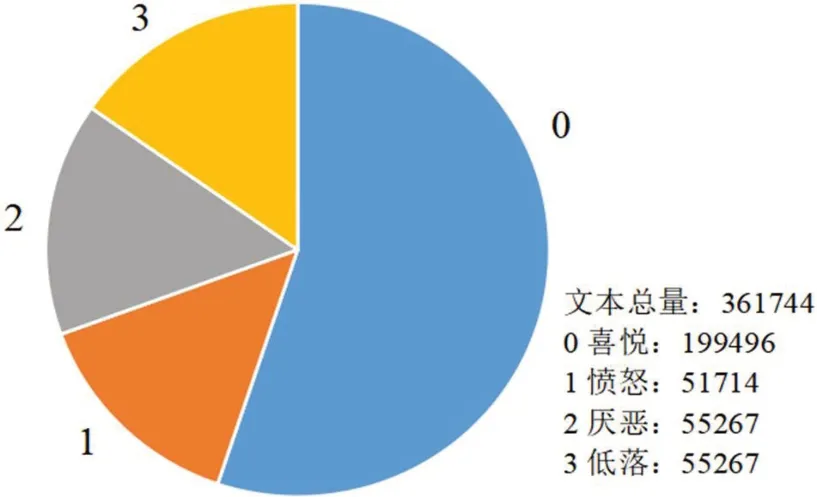
图2:数据集2 数据分布情况
3 数据预处理
3.1 去噪
本文对自媒体文本进行情感分析,首先需要去除文本中的噪声数据,包括HTML 标签、无关URL、表情符号、字母和数字等。使用正则表达式删除文本中的噪声数据。Python 主要代码如下:


3.2 分词
文本分词是将句子分割成一系列有实际意义的词汇序列。本文采用开源jieba 分词工具,采取精确模式将句子分割成规范的词序列,支持繁体分词,支持自定义词典,利用动态规划方法,获得句子在词语频数基础上的最大切分组合。示例句子经分词操作后获得词序列结果如表1 所示。

表1:分词示例
3.3 去停用词
在词典中,停用词是指对文本表意无实质性含义和作用的词语。过滤掉停用词可以节约存储空间、提升分类器效果。本文提出二次方法删除停用词。
(1)删除使用现频次高且无情感意义的停用词。例如“我”、“你”、“的”、“了”等词语,这些词语往往在很多文本中都会出现,对于文本内容表达并没有实质性的意义,无法为分类器提供有效文本特征,影响模型分类的准确度。采用开源的中文停用词表cn_stopwords 来过滤此类停用词。
(2)二次删除停用词。为了提高模型分类结果的准确性,在删除停用词后,对过滤后的文本进行词频统计。针对高频出现的词汇,人工判断是否需要将其加入停用词表,对数据集进行第二次过滤。数据集1 词频统计结果对比如表2 所示。
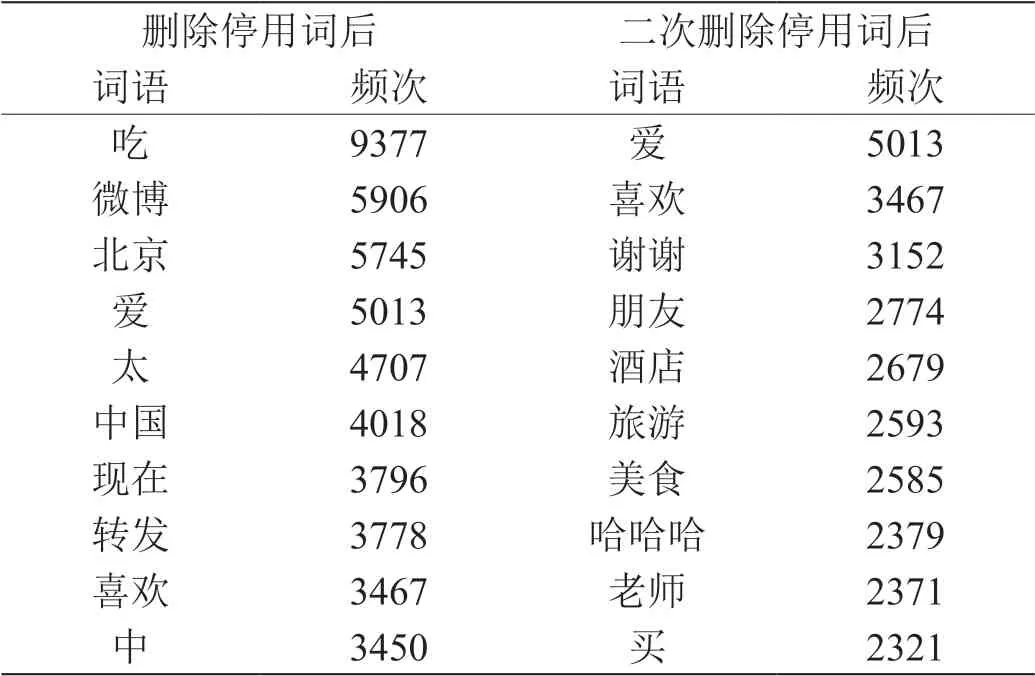
表2:数据集1 词频统计情况(最高频次的10 个词语)
4 数据情感分析
自媒体文本情感分析问题,从本质上来说是一个分类问题。本文构建基于Bi‐LSTM 模型的文本情感分析分类器,建模上下文信息,包括Embedding、Bidirectional 和Dense 3层结构。其中,Embedding 层使用Word2vec 模型训练该层参数,使用维基百科语料库训练词向量。
4.1 Embedding层
序列化分词后的文本,利用Tokenizer 对象的fit_on_texts 函数对文本中的每个词进行编号,词频频数高的词汇设定小的编号。然后,调用Tokenizer 对象的texts_to_sequences 方法进行特征提取,将文本数据转换为数字特征。
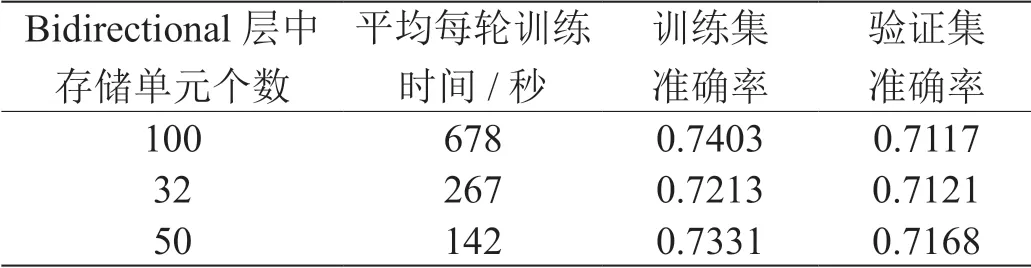
表3:不同存储单元数下的模型结果(数据集1)
4.2 Bidirectional层
在该层中定义一个LSTM 隐藏层,经过实验测试与验证,设置50 个存储单元。同时,在这一层中添加两个dropout,避免对单个节点的强依赖,使得本层模型各个参数可以更加平均地获得反向传播的修正值,减缓过拟合。输入和隐藏层的dropout 设置为0.2,隐藏层和隐藏层之间的recurrent_dropout 设置为0.2。
4.3 Dense层
本层给出了输出的维度以及激活函数。针对数据集1 的二分类问题,选用Sigmoid 函数来激活;针对数据集2 的四分类问题,选择Softmax 函数来激活。使用激活函数可以增加非线性因素,提高模型的表达能力。
5 实验结果
5.1 实验环境
操作系统:Windows 10;编程语言:Python 3.7。主要涉及的pip 库:pandas 1.3.5、numpy 1.21、jieba 0.42、keras 2.8、gensim 4.1、matplotlib 3.5 等。
5.2 实验数据
选择数据集1 和2 作为实验数据。以数据集1 为例,对数据集进行去噪和删除停用词,绘制文本长度直方图,以确定Embedding 层的各项参数,如图3。在数据集1 中,标签为0 和标签为1 的文本各抽取50000 条组成模型新的数据集并打乱。在总量为100000 条数据的数据集中,以7:1:2 的比例切割得到训练、验证和测试集。最终获得70000 条训练数据、10000 条验证数据以及20000 条测试数据。
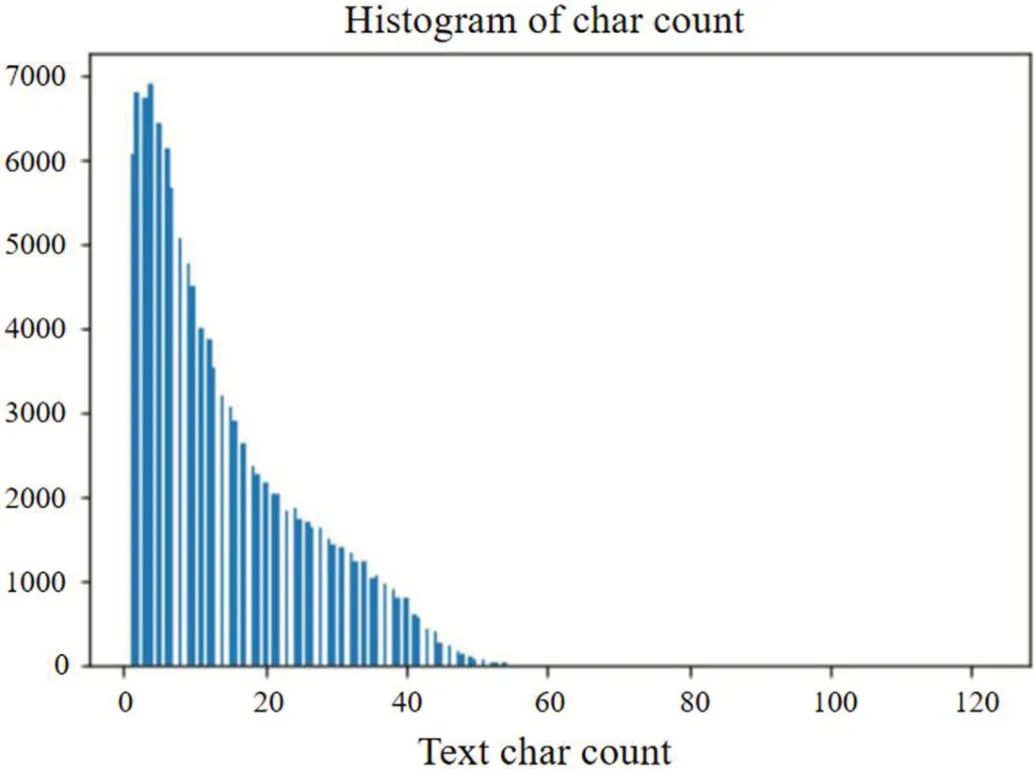
图3:数据集1 文本长度直方图
5.3 实验结果分析
利用binary_crossentropy 来计算损失,adam 作为优化器,batch_size 设置为64,训练20 epoch。加入EarlyStopping 机制,防止模型过拟合。
使用准确率、召回率、F1‐score 进一步评估数据集1 的实验结。在该数据集中抽取了20000 条作为测试集。在测试集上的混淆矩阵如表4 所示,准确率、召回率、F1‐score 如表5 所示。

表4:混淆矩阵

表5:实验结果
由表6 中的模型训练结果数据可知,该模型在weibo_senti_100k 数据集上得到较好的结果,最终在测试集上的准确率可达到0.7 以上。而在simplifyweibo_4_moods 数据集上表现较差,过拟合问题严重且难以解决。分析可能招致该问题的原因有下面两点:

表6:模型训练结果
(1)simplifyweibo_4_moods 数据集质量较差,通过人工比对该数据集中的文本及其对应标签,可以发现很多文本标注标签是不够准确的。
例如,“大盘啊,你就折腾吧,卖软件的,你就天花乱坠吧,‐‐‐‐‐‐‐‐我自岿然不动!”在数据集中被标注为0,即喜悦,“對說:羽姐啊你有删围脖吗?我怎么找不到那个杯子了”在数据集中被标注为2,即愤怒。诸如此类的错误标注数据非常多,导致模型无法准确提取特征,进行进一步学习和分类。
(2)该数据集共分为四类文本数据:喜悦、厌恶、愤怒和低落。而后三种情绪非常相似,且很多文本往往包含这其中的多种情绪,因此模型很难单独区分出文本从属于哪一类。
5.4 情感分析可视化展示
利用训练好的Bi‐LSTM 模型对采集到的话题下的自媒体文本进行情感分类,并输出每条文本对应的分类标签结果。将情感分类结果统计直方图、折线图以及填充气泡图置于同一个仪表盘界面中,帮助用户监测话题的主流情感态度以及舆情变化趋势。仪表盘布局如图4 所示。
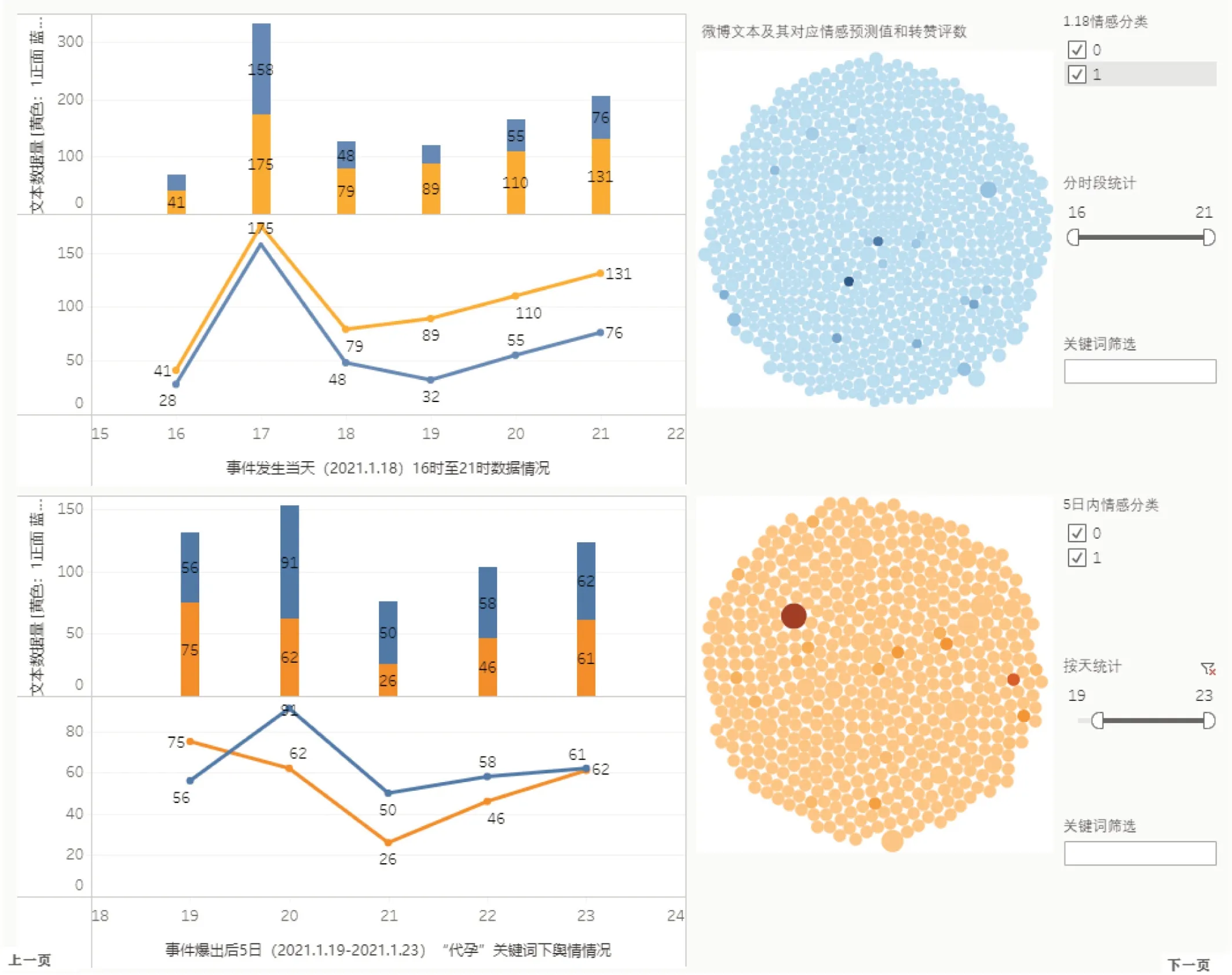
图4:话题情感分类及统计模块
为使用户能够更个性化地查看话题情感分类结果,该模块中设置3 个筛选器:根据情感分类结果显示、分时段统计以及根据文本所含关键词筛选。
当用户选择某一情感类别时,该仪表盘中各图表仅显示该情感类别下的各时段自媒体文本统计情况,供用户单独观察与分析该类情感的文本数量变化情况与趋势。
该模块中设置了按时段统计的筛选器,用户可以拉动时间段,筛选显示左侧图表中指定时间段内的情感类别统计情况,由此用户可以单独分析指定时间段内的舆情走势。
该模块设置按关键词筛选,可在填充气泡图中筛选出全部含有用户输入的指定关键词的全部自媒体文本,由此用户可以设定自定义的文本内容范围,观察该关键词下的舆情情况。
以上三种筛选器还可组合使用,例如图5 所示,仪表盘中显示了指定时间段内所有分类标签为0,即负面情感类文本,且带有“封杀”这一关键词的文本统计信息。组合使用以上三种筛选器可以提升数据统计展示的个性化程度,用户可进一步自定义筛选条件,细化数据范围,能够更细致地了解话题舆情情况。
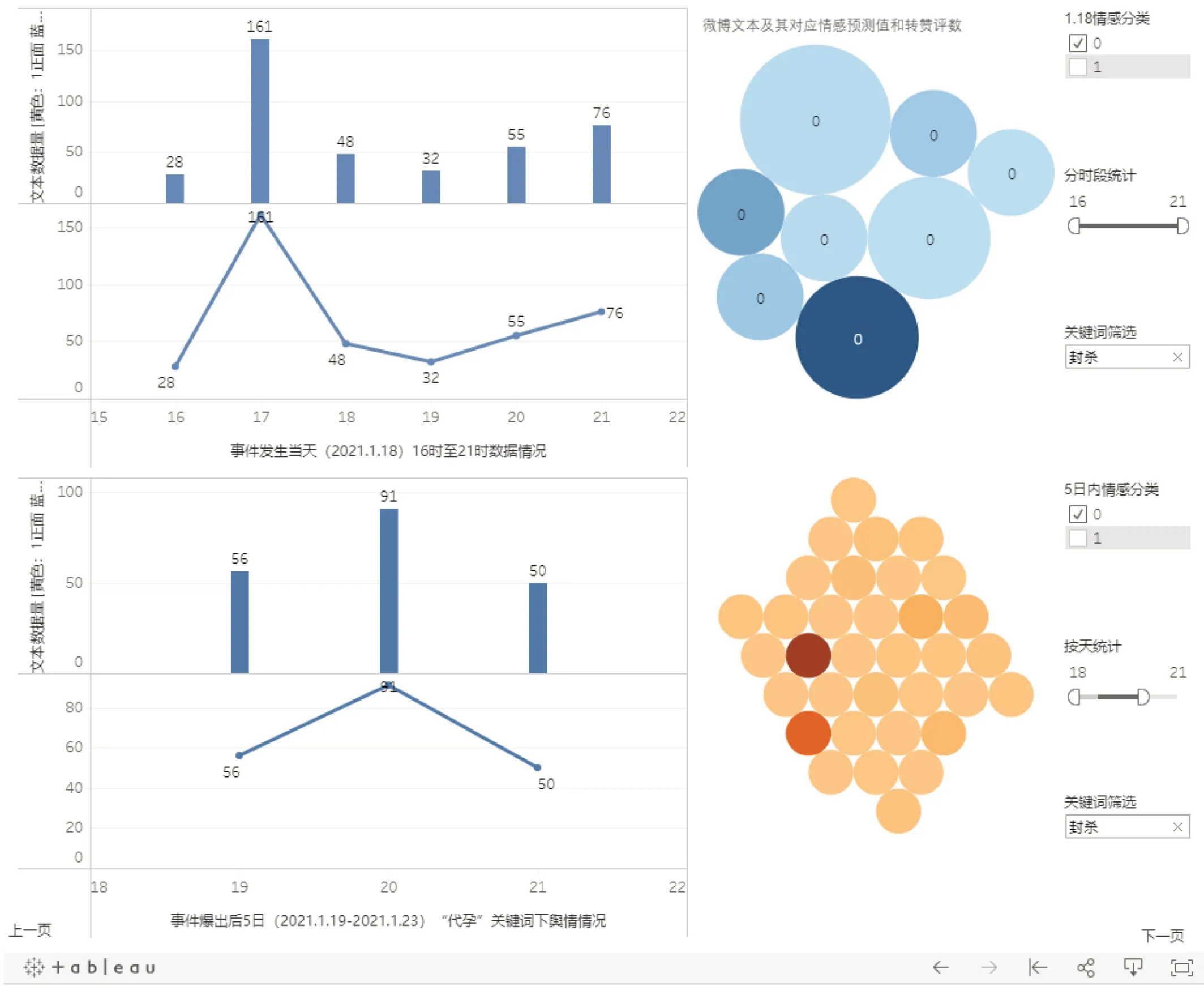
图5:可视化筛选器
6 结束语
本文构建基于Bi‐LSTM 模型的文本情感分类器,对热点话题下的自媒体文本的情感进行分析,为用户提供可视化的话题舆情监测。本文提供的方案可以有效分析海量自媒体数据中的情感信息,分析热点话题的舆论态势,客观反映话题舆论导向或预测舆情发展趋势,提升决策者应对突发事件的处置能力。
