高校图书馆个性化推荐系统设计与实现
2022-11-16何芳
何芳
(德州职业技术学院 山东省德州市 253000)
现代社会快速发展的今天,加快了高校智慧图书馆的建设步伐,大大增加了图书馆的书籍量,这样不仅为高校师生知识的扩展提供了支持,同时还师生资料的查找带来一定难度。所以,为了使得智慧图书馆为师生提供更加便利的服务,必须要加强对个性化推荐系统进行应用,针对教师与学生的实际需求,自动向其推荐合理的书籍,以提升师生获取有效书籍的效率,使智慧图书馆体现出最大的价值。
1 需求分析
近年来,随着我国高校图书馆规模的不断扩大,使得图书馆内部书籍的种类与数量逐渐增加,学生或教师想要查询到自己所需要的书籍时,将要投入大量时间,严重影响师生阅读图书的质量与效率。针对这一问题,科研领域利用各种数学算法,研发出了多种类型的检索推荐系统,通过这些系统的应用,快速为教师或学生推荐相关书籍,在一定程度上提升了师生阅读图书的质量与效率。但对现有推荐系统深入研究后可以发现,其中依然存在诸多缺陷,如大部分系统以协同过滤算法为主,因而需要通过用户对图书的评价进行推荐[1]。但实际当中,很多学生或教师并不会对书籍作出评价,导致系统推荐的并不是很准确。所以,为了进一步提升高校图书馆图书推荐效果,必须采用更加良好的推荐系统,该系统中应具备下述几个方面功能:
(1)新书推荐功能。图书馆内增加新书籍后,可立即将这一情况传输给校园内部所有师生用户,使师生对新增加的书籍具有一定了解。
(2)热门书籍推荐功能。师生首次进入到图书馆时,由于系统内部无该用户的喜好资料,无法向其推荐最佳的书籍,这时,则应向师生用户推荐图书馆在一段时间内的热门书籍,如临近考试阶段的各种复习资料等,以此为师生寻找书籍阅读提供一定指导[2]。
(3)图书推荐功能,为整个系统中的核心部分,主要是针对师生用户的喜好需求,自动推荐相应的书籍。
2 高校图书馆个性化推荐系统设计
2.1 结构设计
2.1.1 整体框架设计
本系统设计时,选择了JSP Mode12 框架,即JSP+servlet+JavaBean 框架。其中,jsp 为视图层,用于对书籍列表、书籍内容等的展示。Servlet 为控制成,主要对前端传输的指令予以处理[3]。JavaBean 为模型层,其中加载了相应的实体对象。具体来说,本系统共由六大结构模块构成,分别为:
(1)接口模块。主要用于用户与系统间数据的传输,包含录入接口与导出接口两部分。
(2)本题库。用于信息与文档关联性的评判。用户向系统内录入检索信息后,通过对关键词与文档关联性的评估,初步筛选出符合用户需求的书籍。
(3)语义推理机。在语义信息整理、分析过程中,可通过这一模块提供相应的帮助。其中,可以将其划分成两部分,一个是内部推理,即对本体库内是否存在冲突进行推理,以提取出无语义冲突的本体。另一个是外部推理,即使用推理标准按照本体之中元素的关联性,分析出其中所包含的隐性知识。本系统设计与开发时,以外部推理为主。
(4)检索请求扩展模块。用于对用户录入指令予以检索,并对检索指令进行适当处理。本系统设计时,主要是对深度为1 的子类扩展予以计算,以提取出指令内含有的隐性知识。
(5)检索处理模块,在其他模块配合下,寻找出对应的书籍资源,之后利用路由算法转发对应检索指令。
(6)结构匹配模块。提取出相似度较高的文本,并与预设阈值予以对比,若超过阈值,表示该文本符合监所要求,反之则表示不符合检索要求。
2.1.2 详细结构设计
本文对图书馆个性化推荐系统设计时,主要采用了协同过滤算法,这是从下述几个方面考虑的:
(1)高校是一个半开放式的场所,每年均有一批学生离开,又会进入一批新的学生,使得图书馆内的借阅数据不断增加,在这些借阅数据的支持下,加强我们对系统运行的了解情况。
(2)在我国高校图书馆当中,图书规模非常庞大,涉及各个领域的书籍。但对于学生与教师来说,通常处于不同的专业,仅需要某一类书籍阅读的需求,很少阅读与自身专业无关的书籍。所以需要图书馆能够详细将书籍名称、作者、主要内容等相关信息展示出来,为用户快速的查找提供支持[4]。
(3)在用户评价方面,不用显示出用户的具体信息,与常规商务平台的评价系统存在明显区别,无需对现有图书馆系统进行优化,也不会增加系统操作烦琐性。
(4)从本质上来说,用户借阅行为为“隐式反馈”,但具有一定专业素养的用户在借阅书籍时,通常会进行大量的思考,以得出最终的决策。而这一过程即可记录在系统日志当中,通过日志的分析,可准确评价用户的需求情况。
以协同过滤算法对系统结构进行构建,可得到4 层结构网络,分别为:网络层,处于系统的最上端,内部包含大量关联节点,以形成完成的覆盖网络,促进网络间信息传输效率与质量;消息层,一方面获取网络层传输的信息,另一方面向网络层发布指令,以此驱动服务层的运行;服务层,用于资源的检索与浏览,以寻找出相应节点;应用层,对消息进行集成,同时赋予特定功能[5]。具体如图1 所示。
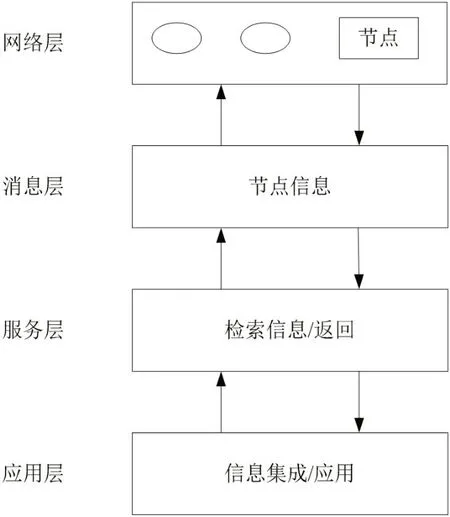
图1:高校图书馆个性化推荐系统结构图
2.1.3 交互结构设计
在系统交互结构方面,共包括5 大模块,分别为:
(1)热门推荐。即向教师或学生推荐一些近段时间中其他师生借阅率较高的书籍。用户之前为使用过系统情况下,系统无法掌握该用户的喜好情况,这种情况下,则针对学生专业、年龄的基本信息,向他们推荐其他类似学生喜欢的书籍,如临近英语等级考试时,以四六级复习资料为主等。若用户使用过系统,则根据以往的所搜信息,提供一些相关的热门书籍,以尽量缩短用户查找书籍的时间。
(2)书籍搜索。为该系统的辅助功能。用户想要获得某书籍时,无需退出该通,即可利用相应的关键词,对图书馆进行全面检索,判断图书馆中是否存在此类书籍,并将检索的书籍名称、基本内容展示出来。与此同时,系统还会自动记录该词汇,下次想要再次搜索与该词汇相关的书籍时,直接点击“历史记录”中的词汇即可。这一功能利用cookie实现的,通过cookie 对词汇进行存储,每次检索新的词汇后,cooik 均会自动对内部信息予以调整,以确保该词汇处于“历史记录”的最上方[6]。
(3)书籍推荐。即针对用户录入的关键词,向用户推荐相应的书籍,具体在下文介绍。
(4)历史借阅。用户借阅数据中获取归还时间字段不为空值(null)的图书记录,可展示出用户历史借阅情况与书籍归还时间。
(5)当前借阅。用户借阅数据中获取归还时间字段为空值(null)的图书记录,可展示出用户现有书籍借阅情况。
2.1.4 系统功能设计
该系统功能设计时,以用户需求为基础完成的。根据用户权限的不同,可将其划分成两类,一类为管理员,涉及登录设置、数据传输、算法选择等功能;另一类为普通用户,涉及账号登录及书籍查询、浏览等功能。
从管理员角度来说,应以云平台为基础,对各类基础数据予以分析。这一过程当中,数据不可随意更改,这是因为随着系统的不断应用,会逐渐增添更多新用户。所以,应在该系统当中,对管理员登录权限进行认证。
数据上传:即向系统内传入初始数据,同时将数据导入至hdfs 文件内,之后以此为基础,利用基于mahout 的协同过滤算法为主要工具,将hadoop 构架激活,对数据进行计算,并将结果存储下来,以此作为向用户推荐的书籍。对于该操作来说,属于管理员的权限[7]。
在普通用户方面,推荐算法的调用由4 个环节构成,具体为:
(1)前期准备。通过历史数据的分析,确定出两组基础数据,一个为热门书籍,另一个为前一管理员通过调用mahout 的协同过滤算法,针对各用户的基本情况,如专业、年龄等,分析出各用户最佳的推荐书籍。
(2)导入新用户的检索信息。
(3)激活推荐算法,将新用户与原有信息整理到一起,以得到全新的用户数据集。
(4)分析推荐结果,并传输给前台,以将最终结果展示出来。
2.2 功能模块设计
2.2.1 模块设计
针对上述模块与功能设计分析,可构建出如图2 所示功能模块结构图。
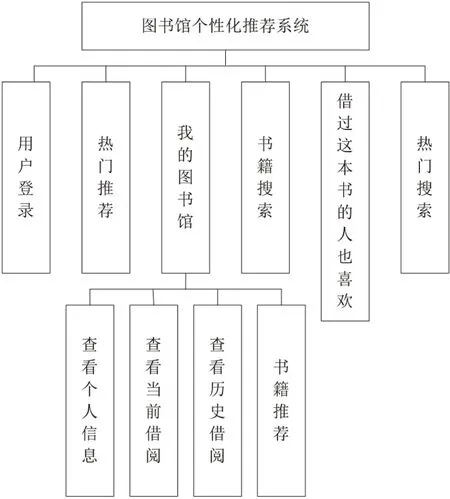
图2:图书馆个性化功能模块结构图
由图2 可知,在本系统当中,共由6 大功能模块构成,分别为用户登录模块、热门推荐模块、我的图书馆模块、书籍搜索模块、协同推荐模块及热门搜索模块。其中,我的图书馆模块内,又分成查看个人信息、查看当前借阅、查看历史借阅、书籍推荐等部分。这些模块运行过程中,依靠的均是协同过滤算法。具体运行流程为:
(1)录入数据表示:提取并分析用户的历史动作,以此当做用户的爱好情况,并通过x*y 的矩阵W 进行表示;
(2)相似社会群体的构建。用于分析出个体间的类似程度,以此作为推荐的依据;
(3)利用得到的依据进行分析,以得到最优的推荐集合。
2.2.2 数据库设计
本系统当中,主要包含三种数据库,具体如表1 ~表3所示。
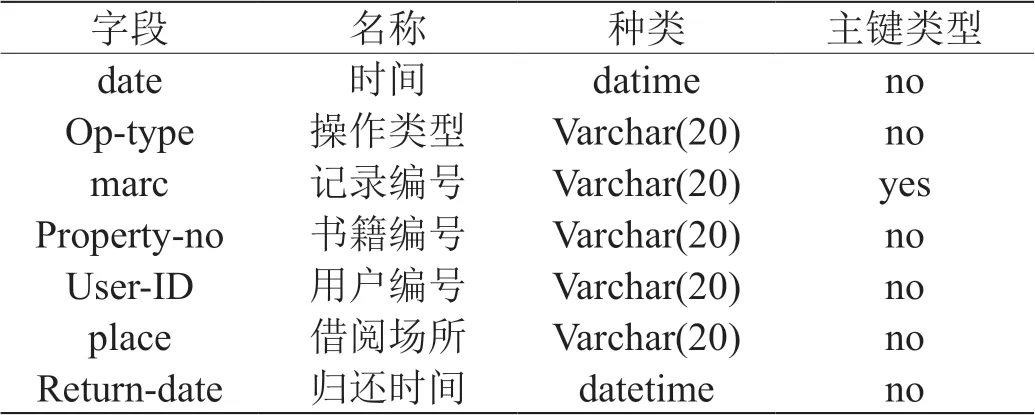
表1:借阅信息数据表
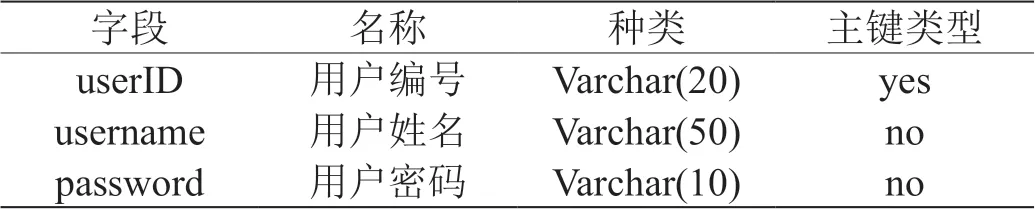
表2:用户数据表
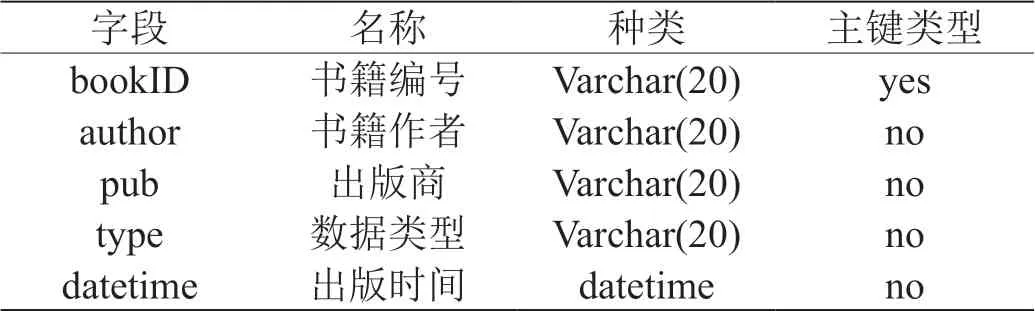
表3:书籍数据表
3 高校图书馆个性化推荐系统的实现
3.1 mahout算法概述
3.1.1 基于用户的相似度算法
现代计算机领域,存在多种不同的mahout 算法,基于用户的算法是其中较为常见的一种。在mahout 算法当中,可将用户数据封装,并对数据予以转换,使其变成DataModel 格式,以符合mahout 算法的计算要求,之后推导出相似度,以此为基础,确定出最终的书籍推荐结果。该算法的特点为:易于理解,且操作用户不是很多时,系统运行速率很快。从本质上来说,该算法是以类似成都非评价标准,对用户行为予以衡量,无需在多个用户间建立联系,也不用设置其他用户参数,即可得到较为精确的运算结果[8]。
3.1.2 基于item 的相似度算法
该算法运行时,是以项目(tiem)相似程度为基础的,具体存在两个特点,首先,由于以item 为基础的,当item不是很多时,会在较短的时间内得到分析结果;其次,在item 实际情况为基础,逐渐将概念进行融合时,能够得到易于理解的结果。现代电子商务系统等软件开发时,均采用了该算法,能够自动分析用户的需求,并向他们推荐相应的产品,以提升消费者的购买意愿。采用该算法时,首先做出相应假设:用户喜欢的商品与历史购买商品具备很高的相似性,以此为基础,即可推导出用户喜好items。从本质上来说,该算法与上述算法的原理基本相同,但分析角度存在一定的差异。利用相应的衡量方法,推导出两产品存在的向量距离,以此为基础,根据类似度的具体情况,确定用户的使用数据,进而绘制出用户喜好或需求清单,并将其传输给用户。这一运算流程中,虽未引用任意属性元素,但其中均存在各种各样的相似性,如处于同一地区,处于同一年龄段等[9]。由此表明,相对于上述算法来说,该算法更简单,无需增添邻居信息等。
3.1.3 基于语义的相似度算法
除了上述两种相似度算法外,还可从语义的角度出发进行计算。具体来说,可从四个方面着手。
(1)语义距离。假设:在本体层次书内,存在概念A与B,两点间的最短距离,即称之为予以距离,计算公式为:
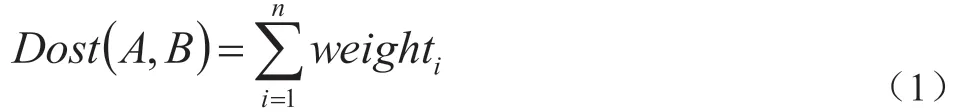
式中,weighti 为A、B 两点间,最短路径的权重。该指标与相似度呈方向关系,就其数值越大,表示相似度越低;反之,其数值越小,相似度则越高。
得到予以相似度后,用予以进行转化,以得到概念予以相似度,公式为:

(2)节点深度。在概念节点与最底部之间,最短路径具备的变数。对于下层节点来说,均为对上层节点的细化,节点越靠下,表明其含义越详细。从节点深度角度来说,其与予以相似度间的关联性可通过下式表达:
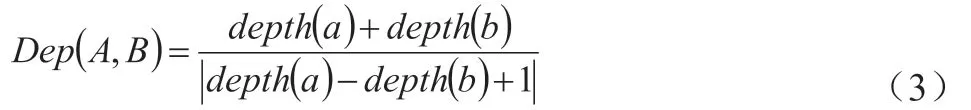
(3)节点密度。在系统层级结构当中,上部最粗与最大,越向下则逐渐变细与变小,分类得越详细。通常情况下,在某节点当中,其中包含的因子越多,密度越高,则解释得越详细,表明相似度越高,反之相似度则较低。从节点密度角度来说,其与予以相似度间的关联性可通过下式表达:

(4)有向边类型。在本体树当中,共包含三种关系类型,由于每种类型关系特点的不同,使其与相似度间存在的关系也具有一定差异,需要针对关系类型的具体情况,确定出最佳的相似度运算公式,具体为:

3.2 系统实现
3.2.1 构建平台
对系统平台构建时,主要流程为:
(1)构建hadoop 平台。本系统开发时,主要选择的是hadoop 框架,其属于分布式平台,其中由很多节点构成,本系统开发时,共选择了三个节点,分别为:node1、node2 与node3,内存都是2g。Hadoop 构建后,在终端处,录入下述指令:“bin/hadoop jar hadoop‐examples‐1.0.4.jar wordcount intput/test out/test‐output”,以此展示出系统的运行情况。
(2)加载mahout。Mahout 加载时,可采用两种形式:下载源码后,通过maven 直接予以编译;下载完成保后,通过解压缩的方式予以处理。本研究中,选择了第二种方法。
(3)测试。将测试数据导入到hadoop 平台内,通过平台内的Canppy 算法予以测试,测试指令为:
“Bin/hadoop jar $mahout_home/mahout examples‐0.7‐job.jar org.apche.machout.clustering. syntheticcontrol.canopy.job”
之后在终端界面内,即可展示出系统的运行情况。最后,于本地文件模块内,依次点击“/hom/test/mahout/test”选项,则能够浏览所有数据信息。
3.2.2 系统登录
该模块共有两部分构成,一个是注册功能,用户根据自己的学号、姓名等信息,注册出系统登录账号与密码;另一个是登录功能,即将前期注册的账号密度录入到登录界面框内,系统中的jsp会对这些信息予以书籍,并以servlet为媒介,对javabean 数据库予以检索,以判断用户是否符合登录要求,若判定用户符合要求,则可正式进入到系统内;反之,则禁止用户进入。
3.2.3 数据传输
在数据传输功能方面,共包括两部分:一是由客户端上传至服务端。由structs2 含有的上传功能实现的。这一操作当中,主要采用interceptor 拦截器。数据上传时,在interceptor 的作用下,对数据予以流化处理,同时传输至action 的文件属性栏内。之后,通过execute 法。将文件信息录入到磁盘内。二是服务端上传至HDFS 文件夹。这一操作通常与上述操作同步进行。该环节的主要代码为:

3.2.4 推荐分析
数据上传后,则应通过mahout 的协同过滤算法进行推荐。在系统内录入相应数据后,点击“提交”选项,以发出激活算法指令。Stuct2 获取该指令后,则会将数据传输至recommenderaction 内,以此对数据予以处理,并对用户身份予以验证。若判定用户符合登录要求,自动跳转至recommender‐success.jsp 界面。在该界面内,对标示予以分析,若标示为假,则向transformaction 发布请求指令,后者获取这一信息后,即可得到job 信息,同时传输至界面。在算法结束后,在传回job 信息同时,还可显示“停止刷新”的信息。最后,将hdfs 下载至本地,传输至mysql 数据库内。该操作的主要代码为:

4 总结
综上所述,本文以mahout 算法为依托,设计出一款高校图书馆个性化推荐系统,该系统主要包括热门推荐、我的图书馆、书籍搜索、协同推荐、热门搜索模块,及数据库模块,在各模块共同作用下,为用户提供良好的书籍推荐服务,以提升用户阅读效率与质量。
