一种基于双控节点的Ceph写性能优化方法*
2022-11-15黄遵祥朱磊基熊勇
黄遵祥,朱磊基,熊勇
(中国科学院上海微系统与信息技术研究所 中国科学院无线传感网与通信重点实验室, 上海 201800; 中国科学院大学, 北京 100049)
如今,越来越多的商业公司使用分布式存储系统解决PB级数据存储问题[1]。而分布式存储系统Ceph作为软件定义存储的代表,被设计为可在众多主流商用硬件上运行,因此具有部署成本低、扩展性高等优点[2-3],从而得到广泛应用。
与目前其他一些热门的分布式存储系统相比,当需要对小文件进行频繁修改时,Ceph比Hadoop表现更为出色[4];相比较GlusterFS(gluster file system),Ceph在系统扩容、缩容时对整个集群的数据服务影响更小[5];与Sheepdog支持单一的存储接口相比,Ceph同时提供主流的3种存储接口等[6-7]。虽然与其他热门的分布式存储系统相比Ceph具有上述的很多优势,但其本身依然存在不足,以Intel为代表的商用硬件供应商对Ceph读写性能的测试结果表明[8]:单线程下Ceph写入速度只有原生磁盘的3.6%,在多线程条件下也只能达到原生磁盘的10%。究其写性能不理想的主要原因是Ceph的多副本强一致性写入机制[3],即主副本要在本地写入完成后,还要等待其余从副本写入完成,当所有副本都写入完成,才会向客户端返回最终的写入完成。这种多副本强一致性写入机制虽然保证了数据的安全性和可靠性,但也严重影响了集群的写性能,同时由于各副本写入速度的不尽相同,并且如遇到如网络拥塞、从副本所在的OSD出现故障等问题,会导致整个集群的写延迟出现剧烈波动,从而影响集群的稳定性和鲁棒性。
针对Ceph写性能不理想的问题,文献[8]优化了Ceph后端存储引擎FileStore,实现的nojournal-block模型用于提高系统的IO性能。从Jewel版本开始,Ceph引入BlueStore取代传统存储引擎FileStore,用于缓解写放大问题,并针对SSD进行优化,目前社区已经推荐在生产环境中使用BlueStore。
文献[9]提出一种根据不同的读写操作比例,决定最终副本同步与异步更新比例的方法。首先统计在一定时间内读写操作的数量,通过不同数量的对比,决定当前同步执行写操作的副本数量,从而实现写操作占IO操作数比例越多,写延迟越小的特性。
文献[10]提出当主副本OSD完成数据的日志盘和数据盘写入后,向客户端返回写完成的改进方法,即主副本在完成本地事务的写入数据盘操作后,才向客户端返回写完成。在该方法中如遇到数据盘写入失败也可以从日志盘进行恢复并重新写入,所以日志盘成功写入即可保证数据最终一定会写入数据盘。
文献[11]提出一种基于分布式哈希环的多副本弱一致性模型。该方法在一定程度上降低了写延迟,但在复杂的应用场景下该方法提高Ceph写入速度的效果并不明显,同时Ceph以对存储数据的高可用著称,但该多副本弱一致性模型可能会影响数据安全性和高可靠性。
文献[12]研究了网络配置对Ceph读写性能的影响,底层使用SSD的存储集群则推荐使用至少能提供10Gbps的网络配置,才能发挥最佳系统性能;文献[13]分析了Ceph的CRUSH(controlled replication under scalable hashing)算法中各项参数对集群读写性能的影响;文献[14]通过引入多流水线算法,每条流水线中包含一个生产者进程和一个消费者进程,利用多核CPU实现大文件IO性能的提升;文献[15]通过设计SFPS (small file process system)框架,包括消除重复数据中的副本、合并相似小文件和引入数据缓存,提高CephFS的IO性能。
上述研究虽然在一定程度上提高了Ceph集群的写性能,但同时也引入了很多新的问题,比如读写机制还有优化空间、写机制改进后破坏了Ceph对数据安全性和高可靠性保证、在实际部署中优化效果不明显等问题。因此本文对基于双控节点的Ceph进行研究,通过改进多副本强一致性写入机制,提高集群写入性能。同时为保证数据依然具有安全性和高可靠性,集群使用双控制器双存储阵列节点,确保集群内部不需要通过数据迁移来实现多副本的存储需求,降低节点间数据传输流量和副本磁盘读写流量,实现数据服务的不间断和集群状态的快速恢复。
1 Ceph基本架构
本文在Ceph基本架构基础上提出改进算法,可将Ceph中的节点按照不同功能分成3类:
1)Monitor节点(MON),负责收集、整理和分发集群的各类映射表。从Luminous版本开始,Ceph增加了全新的Manager节点(MGR),负责实时追踪集群状态和集群各类参数的统计[1]。
2)Object Storage Device节点(OSD),负责数据的最终存储,同时还提供数据复制、恢复和再平衡等功能[16]。
3)MetaData Sever节点(MDS),主要用于在CephFS(Ceph file storage)中对元数据进行管理[3]。
以上只是从功能角度对节点进行分类,可在同一台物理服务器上运行多个服务进程实现上述的多种功能,从而对外提供不同的服务。
同时Ceph通过引入池(Pool)的概念,Pool中存放若干归置组(placement group,PG)。Ceph通过执行2次映射实现数据寻址:第1次静态映射,输入是任意类型的数据,按照默认4 M大小进行切割、编号,通过伪随机哈希函数生成对应的PGID[2];第2次实现PG与OSD的相互映射,除了PGID,输入还需要集群拓扑和相应的CRUSH规则作为哈希函数的输入[4],最终得到一组OSD列表,即该数据对象的所有副本存储位置。
Ceph可采用多副本或纠删码方式维护数据的安全性[17],本文以多副本存储方式为例,当客户端发起一个写请求时,Ceph的数据写入流程如图1所示。由于采用的是多副本强一致性写入机制[3],客户端首先通过上述数据寻址过程,得到该数据对象最终存储的OSD列表,然后与列表中第一个OSD,即主副本OSD,发起写请求;主副本OSD收到后分别向其余从副本OSD发起相应事务,并开始本地写,当主副本OSD收到其余从副本OSD的写入日志盘完成,并且本地也完成后,向客户端返回写入日志盘完成;当主副本OSD收到其余从副本OSD的写入数据盘完成应答,并且本地也完成后,最终向客户端返回写入数据盘完成应答。

图1 Ceph数据写入流程
(1)
各副本写延迟如公式1所示,式中:TOSD1、TOSD2和TOSD3分别代表主副本OSD1、从副本OSD2和从副本OSD3的写延迟,三者在时间轴上是并列关系;trp代表Request preprocessing,请求预处理阶段;ttd代表Transaction dispatch,各从副本事务分发阶段;twj代表Write journal,写入日志盘阶段;twd代表Write disk,写入数据盘阶段;tcs代表Completion status collection,各副本事务完成情况收集及各类回调操作阶段。
因此可以发现,只有当所有副本都写入完成才向客户端返回,同时由于各副本写入速度的不尽相同,并且如遇到网络拥塞、从副本所在的OSD出现故障等问题,无法确保从副本OSD及时完成相应事务。因此,本文主要研究在保证数据安全性和高可靠性的基础上,对上述的Ceph数据写入机制进行优化。
2 基于双控节点的Ceph写性能优化
为保证写入机制优化后,Ceph数据存储依然具有安全性和高可靠性,同时为避免存储节点控制器出现故障时,集群需要通过数据迁移实现多副本存储需求,集群使用双控制器双存储阵列节点,双控作为2个不同的OSD为集群提供数据存储服务。采用双控节点的分布式集群架构如图2所示。
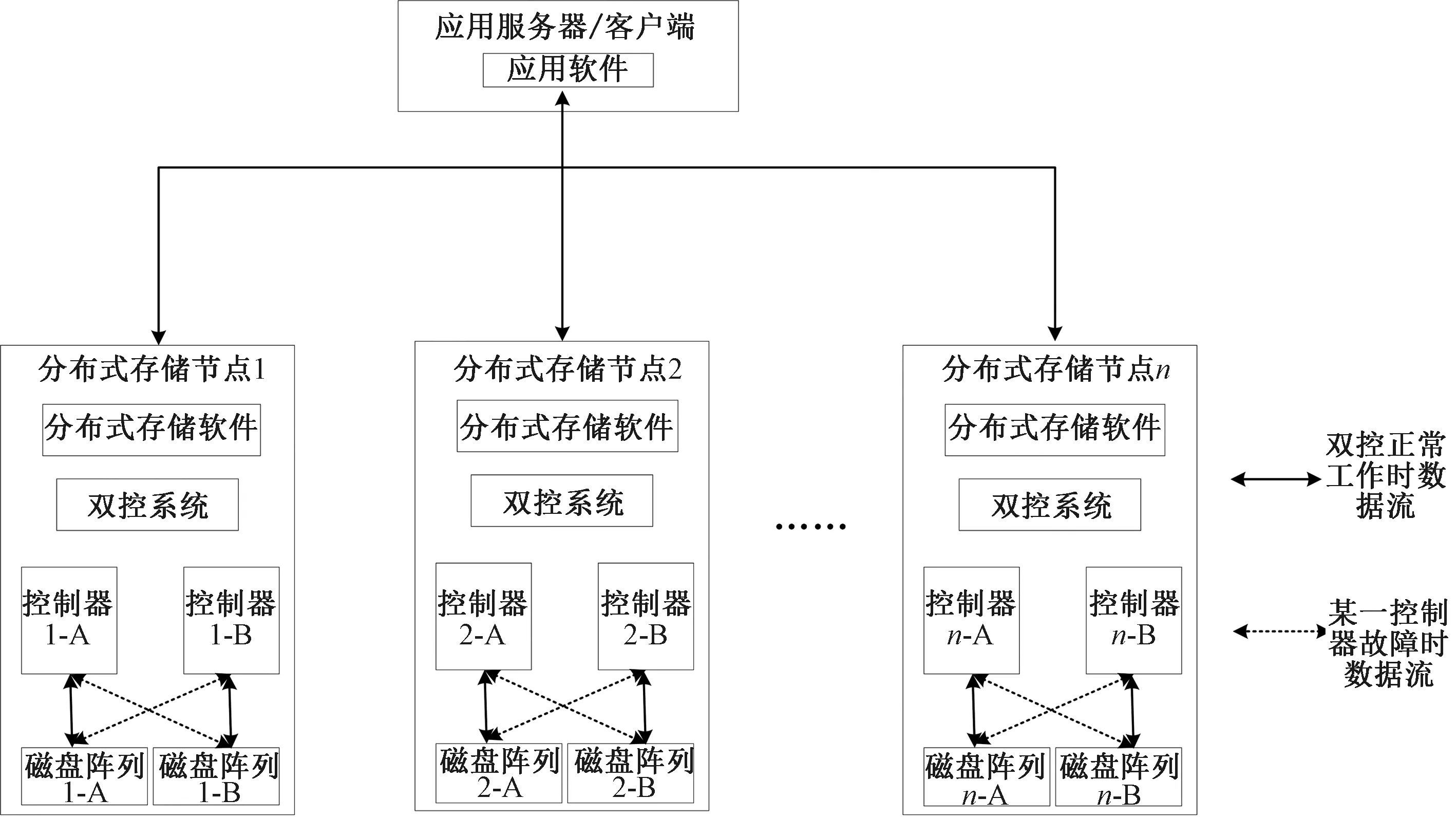
图2 双控节点分布式集群架构
2.1 双控存储节点的实现
节点正常工作时,双控分别控制着各自的存储阵列,并作为2个不同的OSD为集群提供数据存储服务,当双控中一个控制器出现故障时,该节点另一个伙伴控制器创建新的OSD进程并快速接管故障控制器的存储阵列,此时2个OSD进程运行在同一控制器上。为实现上述操作,首先需要区分出现的故障类型,节点故障分为临时性故障和永久性故障[12]:前者包括主机重启等,后者包括控制器损坏、磁盘损坏等。由于OSD之间通过周期性的心跳检测,监控彼此的状态,当超过一定时间阈值没有收到双控中另一个伙伴OSD的心跳消息,则向Monitor上报该OSD的失联信息,同时,该控制器开始尝试接管故障控制器的存储阵列。在集群配置时,需要设置mon_osd_down_out_ subtree_limit配置项,用来限制当集群在出现故障时,集群进行自动数据迁移的粒度。因为如果发生的是永久性故障中的控制器故障,底层磁盘上的数据都是完好的,可以通过双控中另一个伙伴控制器启动新的OSD进程,接管故障控制器的存储阵列实现集群数据的快速恢复,从而避免通过数据迁移实现多副本存储。
因此双控节点接管故障控制器存储阵列的操作主要步骤如下:
步骤1:确定同节点另一个控制器故障,通过OSD间周期性的心跳检测,监控彼此的状态,当超过一定时间阈值没有收到双控中另一个伙伴OSD的心跳消息就执行步骤2;
步骤2:开始尝试接管故障控制器的存储阵列,首先读取存储阵列中的引导数据(bootstrap)用于身份验证,具体引导数据如表1所示。接着创建tmpfs文件系统,并挂载到当前控制器OS中的OSD directory中,通过使用ceph_bluestore_ tool获取启动故障OSD需要的元数据信息(这些元数据存储在label中),并写入工作目录中,接下来创建设备文件软链接并变更设备的所有者和所有组,最后通过systemctl注册系统服务,故障控制器存储阵列对应的OSD进程即可创建成功,并在同节点的伙伴控制器上开始执行;

表1 通过读取的OSD引导数据
步骤3:对重新启动的OSD上存储的所有PG进行数据一致性检查,从而确保各副本数据的完全相同。
2.2 Ceph的写性能优化
在双控节点存储架构基础上,将Ceph写入机制优化为主副本OSD在本地写入日志盘后,就向客户端返回写完成。之后主副本OSD本地写入数据盘的完成情况、其余从副本OSD写入日志盘完成应答(applied)和从副本OSD写入数据盘完成应答(committed)则由主副本OSD在后台继续收集并完成后续各类回调操作。优化后的写入机制如图3所示。
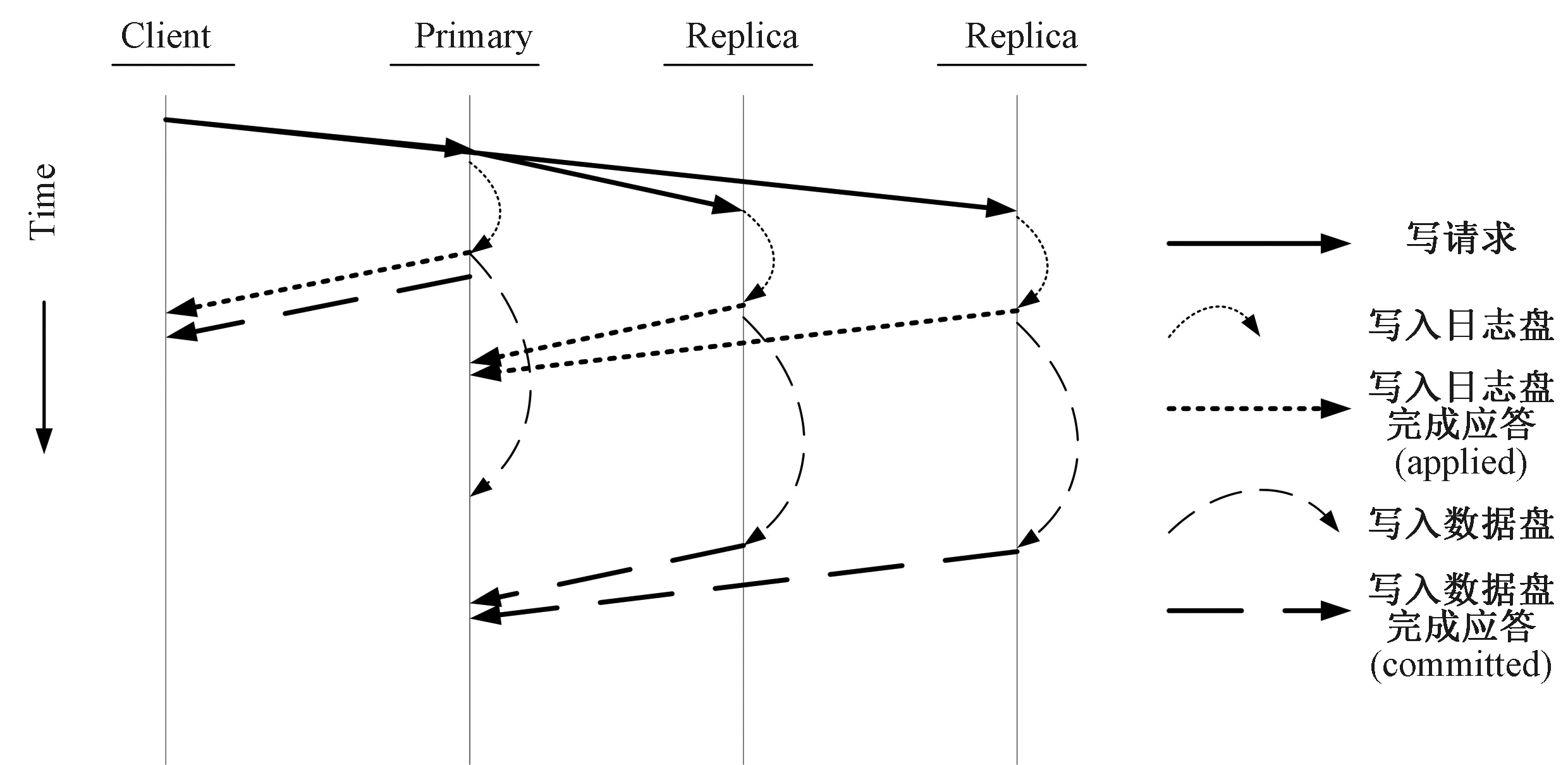
图3 优化后的写入机制
T=trp+ttd+twj.
(2)
优化后写延迟如公式2所示,式中:T代表从主副本OSD收到客户端发送的写请求到向客户端返回最终写完成的时延;其余符号含义如公式1所示。
优化后写入机制具体步骤如下:
步骤1:客户端首先对需要操作的数据计算出32位哈希值作为对象标识,并作为输入通过ceph_stable_mod计算出Pool中承载该对象的PG,然后通过CRUSH算法,得到该操作对象存放的主副本OSD,最终通过send_message向该OSD发送写请求;
步骤2:主副本OSD收到客户端发送的写请求后,首先将message封装成一个op,根据其中的PGID信息插入到对应的op_shardedwq队列,最终由osd_op_tp线程池中的线程开始步骤3的处理;
步骤3:该op首先通过do_request和do_op完成一系列检查,前者完成PG层的检查,后者完成包括初始化其中各种标志位、op合法性校验和最重要的获取操作对象上下文(ObjectContext),并创建OpContext用于承接客户端对op的所有操作,并对该op后续执行情况进行追踪;
步骤4:通过execute_ctx执行步骤3中生成的OpContext。步骤4~步骤6都是在execute_ctx中执行,首先需要进行PG Transaction准备,PG Transaction中封装了一系列对原始对象的处理步骤,并和日志共同保证数据存储的一致性。PG Transaction准备阶段包括:将op中的每个处理步骤转化为PG Transaction中的操作,接着判断是否需要对原始对象进行快照,最后生成日志并更新操作对象的OI(Object Info)和SS(Snap Set)属性;
步骤5:接着将PG Transaction转化为各个副本的本地事务(ObjectStore Transaction),从而保证各副本的本地一致性,接着由issue_repop执行副本间Transaction分发,同时将其加入waiting_for_applied和waiting_for_commit两个队列中;
步骤6:当主副本OSD调用本地存储引擎后端写入日志盘后,主副本OSD回调执行先前在OpContext中注册的on_applied和on_committed回调函数,即向客户端返回写完成;
步骤7:各从副本OSD收到主副本OSD发送的写请求对应的本地事务(ObjectStore transaction)后,调用本地存储引擎后端分别执行写入日志盘和数据盘,对应操作完成后向主副本OSD返回相应完成应答;
步骤8:主副本OSD收到从副本OSD返回的写入日志盘完成应答(applied)或写入数据盘完成应答(committed)后,通过eval_repop,在waiting_for_applied或waiting_for_commit队列上删除对应事务,并不断检查waiting_for_applied和waiting_for_commit是否为空,重点检查waiting_for_commit队列,如果发生waiting_for_ commit为空,而waiting_for_applied不为空的情况,那么就直接清空waiting_for_applied中未完成的OSD,并执行其余回调函数,最终清理和释放OpContext。
通过上述优化后的写入机制,数据成功写入主副本OSD的日志盘(journal)后,就向客户端返回写完成,消除了公式1中TOSD1的twd+tcs、TOSD2和TOSD3的写入延迟,从而降低非必要写操作对集群写性能的影响。
2.3 优化后数据可用性分析
优化后的Ceph数据可用性主要体现在以下3个方面:节点控制器故障时数据可用性保证、存储阵列或磁盘故障时数据可用性保证、节点电源或网卡故障时数据可用性保证。下面分别进行阐述:
1)节点控制器故障时数据可用性保证:对于OSD在执行数据写入过程中,若控制器发生故障,可通过节点双控双存储阵列模式,有效确保数据的安全性和高可靠性。具体情况分析及相应处理机制如下:
①如果当主副本OSD写入日志盘前,发生主副本OSD控制器故障,则会由同节点双控中另一个伙伴控制器重新拉起该OSD进程,并接管故障控制器存储阵列后通知Monitor,客户端通过Monitor获取最新的OSDMap后,会重新发起本次写请求,并重复上述优化后写入机制的所有步骤。
②如果当从副本OSD写入日志盘前,发生从副本OSD控制器故障,则会由同节点双控中另一个伙伴控制器重新拉起该OSD进程,并接管故障控制器存储阵列后通知Monitor,主副本OSD通过Monitor获取最新的OSDMap后,重新发送对应副本的本地事务(ObjectStore Transaction),从副本OSD收到后,重新调用后端存储引擎执行写入操作。
③如果当主副本OSD写入日志盘后,并且在写入数据盘完成前,主副本OSD控制器发生故障,则会由同节点双控中另一个伙伴控制器重新拉起该OSD进程,并接管故障控制器存储阵列后,将日志盘中数据重新写入数据盘,由于重新接管后造成其余从副本OSD上写操作完成状态丢失,因此还需要对操作对象进行一致性检查。当发现从副本OSD中相应数据与主副本OSD不一致时,则将主副本OSD中的数据作为权威副本,恢复从副本OSD中未成功写入的数据,从而保证各副本数据最终一致性。
④如果当从副本OSD写入日志盘后,并且在写入数据盘完成前,从副本OSD控制器发生故障,则会由同节点双控中另一个伙伴控制器重新拉起该OSD进程,并接管故障控制器存储阵列后,将其日志盘中数据重新写入数据盘,最后还需要向主副本OSD发送该事务的写入数据盘完成应答(committed)。
通过上述4种情景分析,双控节点在其中一个控制器故障的情况下,进行控制器切换确保了集群内部不需要通过数据迁移实现多副本的存储需求,降低了节点间数据传输流量和副本磁盘读写流量,从而确保数据服务的不间断和集群状态的快速恢复。
2)存储阵列或磁盘故障时数据可用性保证:对存储阵列故障进行分类,具体情景分析及相应处理机制如下:
①如果只是存储阵列或磁盘由于某种原因导致的本次写入失败,存储阵列或磁盘本身并未损坏的情况下,如果是数据盘写入失败,则由日志盘(journal)中的对应数据进行恢复;如果是日志盘写入失败,则由日志log恢复针对该数据对象的操作步骤,从而实现对日志盘的重新写入。
②如果是由于存储阵列或磁盘损坏,导致的数据写入失败,那么此时该节点将通过心跳信号通知Monitor节点对应存储阵列或磁盘失联,Monitor节点间将通过Paxos算法实现对该OSD节点状态一致性确认。若最终判定该OSD节点失联时,Monitor会重新选择OSD用于放置故障存储阵列或磁盘数据,数据恢复过程如下:若主副本OSD的数据盘损坏,则从日志盘进行数据恢复;若主副本OSD的日志盘损坏,则先检测数据盘有没有写入成功,若数据盘没有写入成功,则先从日志log恢复针对该数据对象的操作步骤,从而实现对数据盘的重新写入;若从副本OSD上的存储阵列或磁盘出现损坏,则处理为:当Monitor重新分配了新的OSD用于恢复故障存储阵列或磁盘数据后,首先更新集群Map,当主副本OSD收到最新的集群Map后,将重新发起未完成的从副本写入操作,直到新的从副本OSD返回写入完成应答。
3)节点电源或网卡故障时数据可用性保证:该故障在实际项目部署中一方面对服务器双电源连接不同容灾域的供电端口,和对服务器双网卡连接不同网络进行规避;另一方面当某一节点出现电源或网卡故障时,即该节点与外界失联,与故障节点建立了心跳连接的节点会通过未周期性收到心跳包而最先感知,之后该节点会将失联节点通知Monitor。若最终Monitor判定该节点失联则会将其下线,之后重新分配新的OSD,并更新集群map,在执行数据恢复过程中会出现以下两种情况:
①若正在执行写入操作数据对象的从副本OSD出现节点电源或网卡故障:当主副本OSD收到更新后的集群map后,将会由主副本OSD发起针对新的从副本OSD数据Backfill机制,直到从副本OSD上数据符合系统要求的副本数;
②若正在执行写入操作数据对象的主副本OSD出现节点电源或网卡故障:当从副本OSD收到更新后的集群map后,由于从副本OSD无法确定出现故障的主副本OSD上是否有未完成的三副本数据对象的写操作,因此从副本OSD首先与另一个从副本OSD就该PG上的数据达成一致,即确定该PG上数据对象的权威副本,然后根据权威副本恢复新的主副本OSD上的数据,直到主副本OSD上的数据符合系统要求的副本数。
3 实验结果与分析
该部分通过VMware创建虚拟机,搭建Ceph集群的方式,对基于双控节点的Ceph写性能优化方法进行实验,测试分为验证优化后方法的数据高可用和评估优化后方法的写性能提升效果。
3.1 实验环境
实验使用8台虚拟机(node0~node7)搭建Ceph分布式存储集群,每台虚拟机都运行OSD进程作为OSD节点使用,同时前3台虚拟机还分别运行Monitor和Manager进程,作为MON节点和MGR节点使用[18],还需任选一台虚拟机作为客户端节点。将集群数据副本数设定为3,所有虚拟机的系统环境均为CentOS-7系统。测试环境的集群拓扑如图4所示,测试软件为Fio,其中IO引擎为libaio。
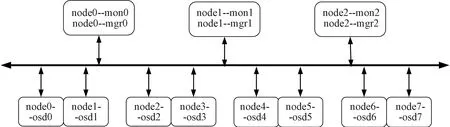
图4 实验集群拓扑图
3.2 数据可用性测试
在虚拟机搭建的Ceph集群中,通过修改CEUSH map的方式(包括修改Cluster map和Placement rule),将node0与node1、node2与node3、node4与node5、node6与node7分别绑定为伙伴控制器,从而模拟实际中的双控制器双存储阵列节点。数据可用性测试主要验证控制器、硬盘、电源和网卡出现故障时,整个集群的数据读写是否正常,即客户端此时进行任何数据读写是否不受故障影响,测试结果如表2所示。

表2 数据可用性测试
3.3 写性能测试
优化后方法的写性能测试主要从写延迟、吞吐量和IOPS等3个方面,对本文提出的基于双控节点的Ceph写性能优化方法和Ceph原生多副本强一致性写入机制进行测试比较,并在数据大小分别为4 K、8 K、16 K、64 K、128 K、1 M、2 M和4 M情况下对测试结果进行统计和分析。
如图5(a)、5(b)所示的是写延迟测试结果图,本组Fio测试的direct参数设置为1,iodepth参数设置为1。可以看出,通过本文提出的基于双控节点的Ceph写性能优化方法,在不同数据大小的情况下,无论顺序写还是随机写,写延迟与Ceph原生机制相比普遍降低了一半左右,并且随着写入数据块的增大,对1 M以上大数据块写延迟降低越明显,因为在Ceph原生的多副本强一致性写入机制中,主副本OSD需要通过网络为每个从副本传输事务,当操作对象越大时,网络传输造成的延迟也越大,因此本文提出优化方法运行在经常进行大文件读写的存储系统中,集群的写延迟表现会更加出色。
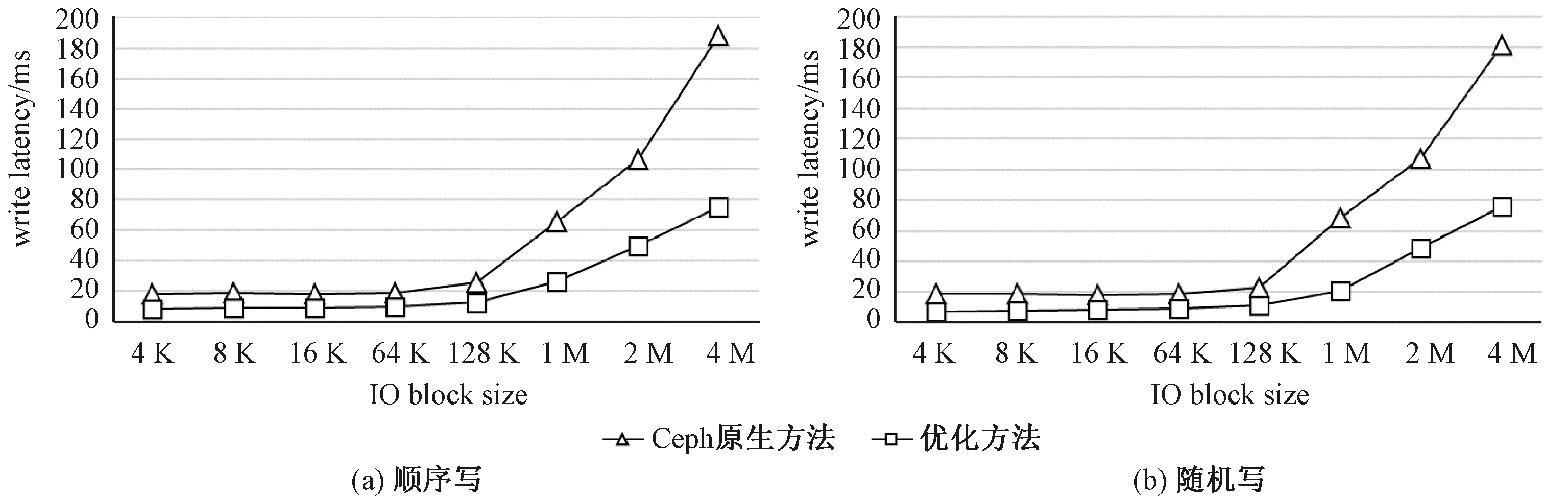
图5 不同数据大小情况下写延迟的比较
如图6(a)、6(b)所示的是吞吐量测试结果图,本组Fio测试的direct参数设置为1,iodepth参数设置为64。可以看出,通过本文提出的基于双控节点的Ceph写性能优化方法,在操作16 K以下的小数据块时,顺序写和随机写都有1.5倍性能提升,在数据块大小为64 K和128 K时,随机写的吞吐量性能提升了2倍以上,但在顺序写时,对1 M以上的大数据块操作效果没有小数据块明显,主要因为无论是本文提出的优化方案还是Ceph原生写入机制,最终结果各副本数据都需要写入数据盘中,在本文提出的优化方案中,如果某一副本本次写操作还未最终写入数据盘,下一个针对同一对象的写请求就已经到达,那么此时只有将最新的写请求插入等待队列中,等待上一次针对同一对象的写请求最终写入数据盘后,才能从队列中取出继续执行,而这种情况的发生概率在频繁顺序写入较大数据块时会增大,因此本文优化方案吞吐量的表现与系统对数据的操作特性有较大关系,如果系统需要频繁顺序操作大数据块,使用本文提出的优化方法,在吞吐量上的提升没有频繁操作小数据块效果明显。
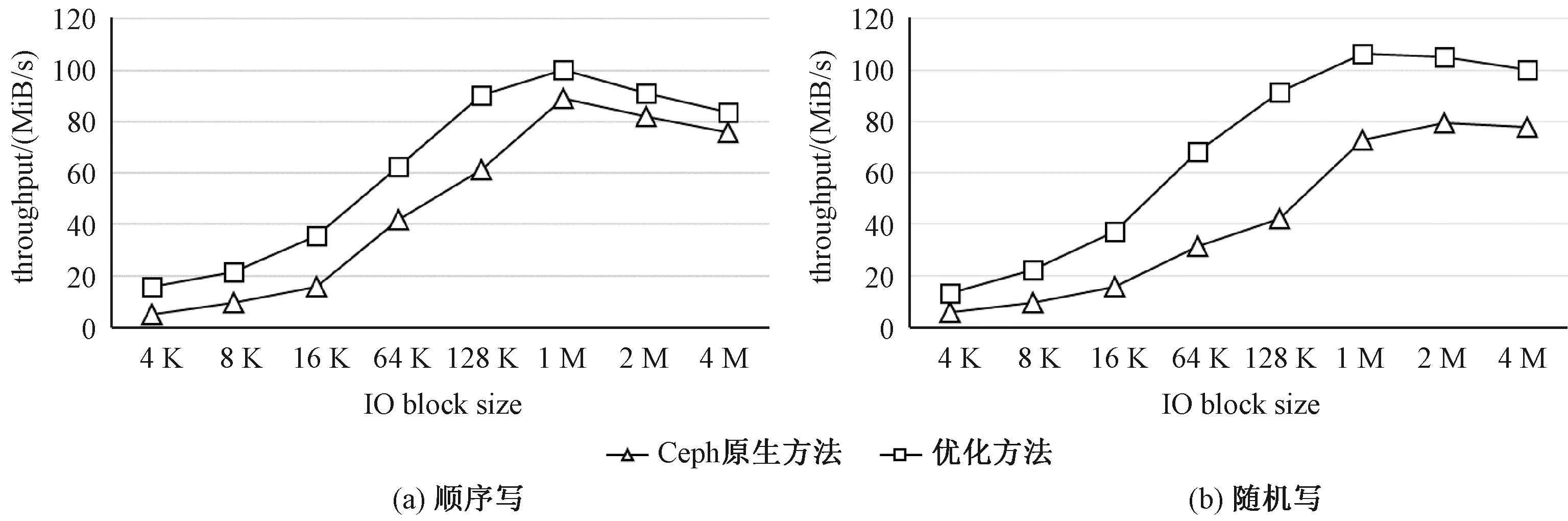
图6 不同数据大小情况下吞吐量的比较
如图7(a)、7(b)所示的是IOPS测试结果图,本组Fio测试的direct参数设置为1,iodepth参数设置为128。可以看出,通过本文提出的基于双控节点的Ceph写性能优化方法,在操作16 K以下小数据块时,顺序写性能提升了1.5倍左右,操作128 K以上的大数据块性能提升2倍左右。在随机写中IOPS性能提升效果更加明显,其中操作64 K以上的大数据块性能提升3倍左右,因为在本文提出的优化方案中,对于IO操作的完成不需要等待所有副本都完成才向客户端返回,当主副本OSD写入本地日志盘后,即可向客户端返回写完成,之后主副本OSD本地写入数据盘完成情况、其余从副本OSD写入日志盘完成应答(applied)和从副本OSD写入数据盘完成应答(committed)则由主副本OSD在后台继续收集并完成后续各类回调操作,从而消除了公式(1)中TOSD1的twd+tcs、TOSD2和TOSD3写入延迟,避免非必要写对集群IOPS的影响,从而提高单位时间内写操作的完成次数。
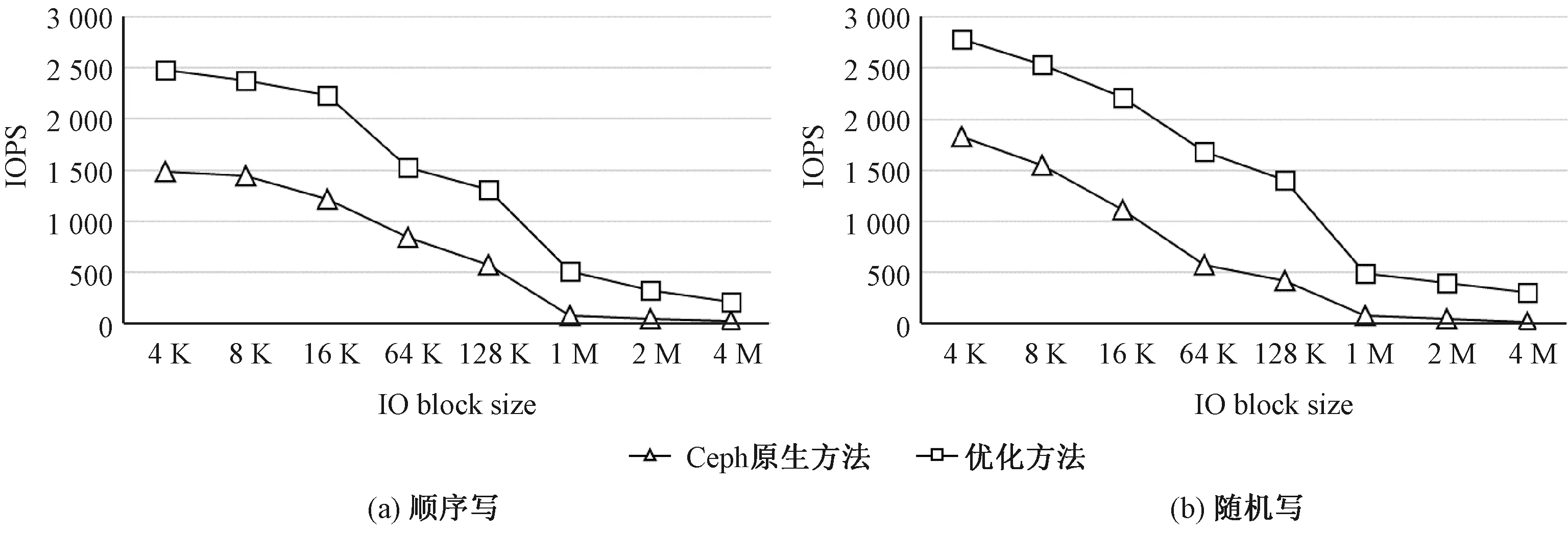
图7 不同数据大小情况下IOPS的比较
4 结语
本文针对分布式系统Ceph的多副本强一致性写入机制造成的写性能不理想问题,提出一种基于双控节点的Ceph写性能优化方法,提高写性能的同时,保证数据的安全性和高可靠性。通过对实验测试结果的进一步分析,保证了数据的高可用,并验证本文提出的优化方法对写性能提升的效果。虽然该优化方法对集群中的节点提出了一定的要求,要求具备双控双存储阵列能力,但却带来了对数据安全性和高可靠性的严格保证,对Ceph的商业化应用,特别是在国产平台上搭建Ceph具有一定的参考意义。
