基于卷积注意力和胶囊网络的SAR少样本目标识别方法*
2022-11-15霍鑫怡李焱磊陈龙永张福博孙巍
霍鑫怡,李焱磊,陈龙永†,张福博,孙巍
(1 中国科学院空天信息创新研究院 微波成像技术国家重点实验室, 北京 100094; 2 中国科学院大学, 北京 100049)
合成孔径雷达(synthetic aperture radar ,SAR)作为一种对地观测微波传感器,具有全天时、全天候的特点,广泛应用在军事侦查、地形勘测等多方面。SAR目标识别技术可以帮助我们自动判定目标型号,应用场景广泛[1]。传统SAR目标识别方法需要人工提取目标特征,算法准确率较低,普适性较差[2]。深度学习方法自动提取目标高维特征,准确率有很大提高[3-5]。然而,该类方法依赖于大量训练数据,由于SAR平台依赖性高,获取数据的成本高,对于非合作目标,不可能获得大量数据。样本量不足制约了深度学习在SAR目标识别领域的发展[6]。
研究者们取MSTAR训练集的10%~30%的数据进行研究,希望利用更少的数据,获得更高的准确率。目前,少样本目标识别问题主要分为以下几个方向:数据扩充[7-8]、迁移学习[9-11]、度量学习[12]、半监督学习[13]等。这些方法均利用卷积神经网络提取特征,存在以下问题:卷积神经网络中的池化层对特征图下采样(如图1所示),降低了特征图的空间分辨率,损失细节信息,不适用于SAR少样本数据集;二是卷积神经网络只判断图像中是否存在局部特征,忽略了不同特征之间的空间位置关系。雷达图像的散射系数随角度变化十分明显,不同角度下的图片差异较大[14],卷积神经网络并不具备识别这些变化的能力。在MSTAR数据集上,当训练集样本数目减少为278张时,卷积神经网络的准确率下降到70%左右[15]。可见,卷积神经网络在SAR少样本目标识别问题中存在准确率低的问题。
图1 由CNN中的池化层引起的空间分辨率的下降
自Sabour等[16]提出胶囊网络以来,多位学者将胶囊网络应用在目标识别问题上。Paoletti等[17]提出结合胶囊网络高光谱图像分类模型,通过高光谱胶囊提高网络的信息提取能力,提高对高光谱图像的准确率。Guo等[18]提出Capsules-Unet模型,提取出高维度信息,在遥感数据集中验证模型的有效性。张盼盼等[19]利用改进的胶囊网络对MSTAR数据进行分类,获得了98.85%的准确率。冯伟业等[20]对CapsuleNet 结构进行轻量化设计,在MSTAR数据集上验证了算法的有效性。
在少样本SAR目标识别问题中,样本有用信息少,胶囊网络不能选择性关注目标重要特征,学习效率较低。借鉴人类视觉的注意力机制系统,在神经网络快速扫描一幅图像后,注意力机制引导神经网络重点关注目标细节特征,提高了图像解译的效率[21]。学者们分别在空间域[22]、通道域[23]、混合域[24]、时间域[25]等不同域提出了注意力机制。李红艳等[26]在Faster-RCNN中引入注意力机制,提高了遥感图像的检测精度。Wang等[27]提出基于卷积注意力机制的SAR图像变化检测模型,在实测SAR数据上获得了良好的效果。周龙等[28]将注意力机制引入细粒度车辆模型分类中,在Compcars和Stanford Cars数据集上获得了良好性能。
为了充分利用少样本SAR图像的信息,进一步提高算法的准确率,本文提出结合卷积注意力机制和胶囊网络的SAR少样本目标识别模型CBAM-CapsNet(convolutional block attention module-capsule network)。分为2个模块。第1个模块:特征提取模块,在卷积层提取输入图像的初级特征后,加入注意力机制,在通道和空间2个维度分别对初级特征进行加权融合,引导神经网络重点关注SAR初级特征图中对分类结果贡献大的特征,忽略无用特征,从而提高了神经网络的学习效率。第2个模块:实体特征提取和分类模块,用胶囊网络代替卷积神经网络,卷积神经网络每次用单个神经元提取目标特征,而胶囊网络同时利用多个神经元提取目标的实体特征,具有表示更多信息的能力。实验表明,CBAM-CapsNet在少样本SAR数据集的情况下,准确率优于卷积神经网络。
1 CBAM-CapsNet网络模型
1.1 数据
本文采用了2个数据集:MSTAR数据集和实测车辆目标数据集。MSTAR数据集是由美国国防高等研究计划署公布的实测SAR地面静止目标数据,包含10类目标,系统分辨率为0.3 m×0.3 m,工作在X波段,采用HH极化。本文采用标准工作条件 (SOC) 下采集的数据集进行实验。
实测车辆目标数据集是由中国科学院空天信息研究院微波成像技术国家重点实验室获得的SAR图像,采集该数据集的传感器为mini SAR设备,系统分辨率为0.2 m×0.2 m,工作在Ku波段,极化方式为HH、VV、HV等3种。包含5类不同的车辆目标,分别是:消防车、救护车、油罐车、相撞的2辆小汽车和追尾的2辆小汽车,不同类别目标的光学图像如图2所示,每一类目标有66张图像,由于实测车辆目标数据集的数量有限,数据集划分准则是:每次实验中,没有参与训练的图片,全部划分为测试集。

图2 实测车辆数据集SAR图像和对应的光学图像
在实验前,对所有的训练集做了如下的预处理:首先将原始图片以中心为基准,裁剪为110×110大小的图片,再将图片随机裁剪成92×92大小的图片。对测试集的预处理为:从中心裁剪为92×92大小的图片。这样做的好处有2点:一是随机裁剪使得每一个目标不一定在图片的中心位置,体现了图像的平移不变性;二是92×92大小的图片足够包含整个目标,图像的尺寸变小后,减小了神经网络的参数,也减少了模型过拟合的风险。
1.2 胶囊网络结构和动态路由算法
胶囊网络和卷积网络的结构对比如图3所示。相比于卷积层每次只用一组卷积核提取特征,胶囊网络中的初级胶囊层利用C1组卷积核对特征图进行卷积运算,得到H×W×C×C1的高维特征图。将对应位置组合,得到H×W×C个向量,每一个向量的大小为1×C1,称为一个胶囊。胶囊的长度代表实体存在的概率,方向代表所提取出的目标实体,如:目标的纹理、特征的空间位置、特征的旋转角度等。利用多维神经元提取特征,具有表示更多信息的能力。
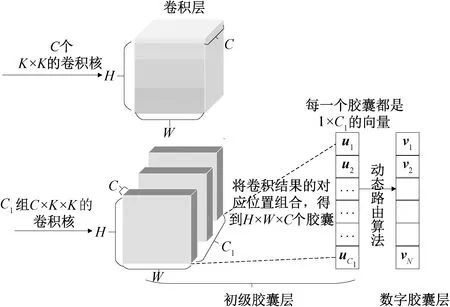
图3 胶囊结构和卷积结构对比
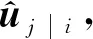
ci=softmax(bi),
(1)
再重复上述步骤K次,通过下式
(2)
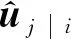
1.3 CBAM-CapsNet模型结构
本文提出的基于卷积注意力机制的胶囊网络SAR分类模型的结构如图4所示,图中的数字代表该层的特征维度,每一层的参数在名字的下方标注。为了防止神经网络对少样本数据集的过拟合,网络不宜过深,参数量不宜过大。在胶囊网络前设计了2层卷积神经网络,卷积层1提取目标的初级特征,卷积层2提取目标的高级特征。因此,卷积层1选取的卷积核较大,为9×9,卷积层2选取的卷积核较小,为5×5。
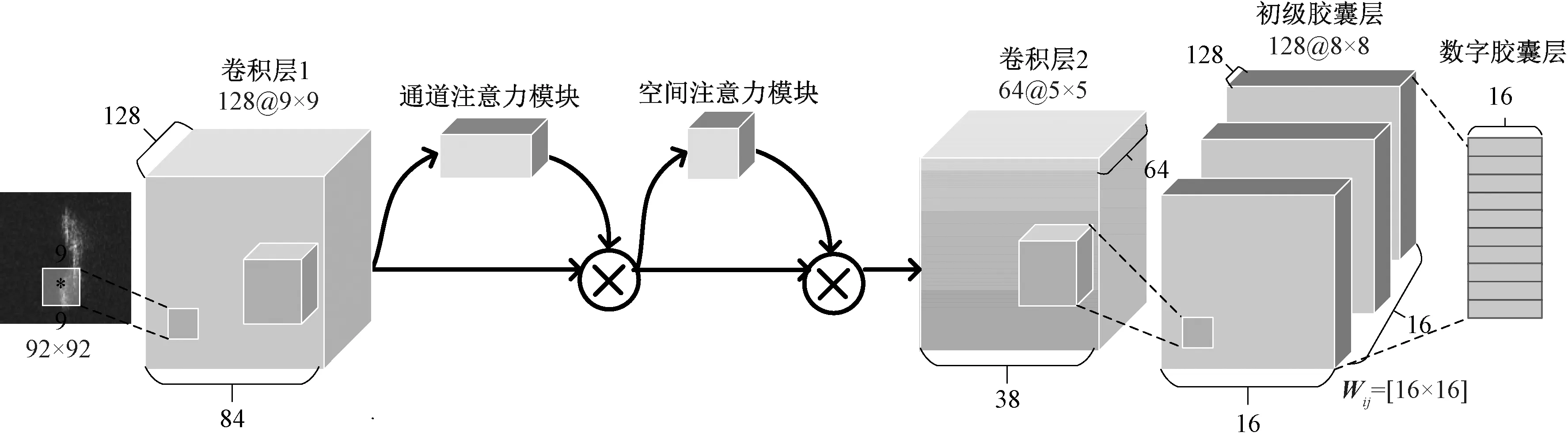
图4 CBAM-CapsNet结构
输入图像经过卷积层提取特征,注意力机制层对特征进行加权,提高有用信息的权重,抑制无用信息的权重,胶囊层提取目标高维实体特征,最后求取输出胶囊的长度,得到目标属于不同类别的概率。下面分别叙述每一层的细节。
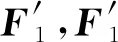
F1=max_pool(σ(W1(X))),
(3)
其中:W1表示卷积层1的权重参数,σ表示ReLU激活函数,max_pool表示最大池化。
第2层是注意力机制层,由通道注意力层和空间注意力层串联而成,对初级特征进行加权融合。在神经网络的学习过程中,卷积注意力层分别在通道和空间维度上学习到不同特征对分类结果的贡献程度。在通道维度得到一个1×C的注意力向量图,指导神经网络哪些维度的特征需要重点关注;在空间维度得到一个H×W的注意力向量图,指导神经网络图像中哪些区域需要重点关注。训练时,随机初始化一个权重,以不断减小损失值为目标,根据梯度下降算法更新权重,最终给出合适大小的权重。将注意力向量图和初级特征F1相乘,便可根据特征的重要程度对特征进行加权,自适应地引导后面的神经网络在学习过程中重点关注对结果贡献较大的特征,弱化无关特征,从而提高神经网络的学习效率。
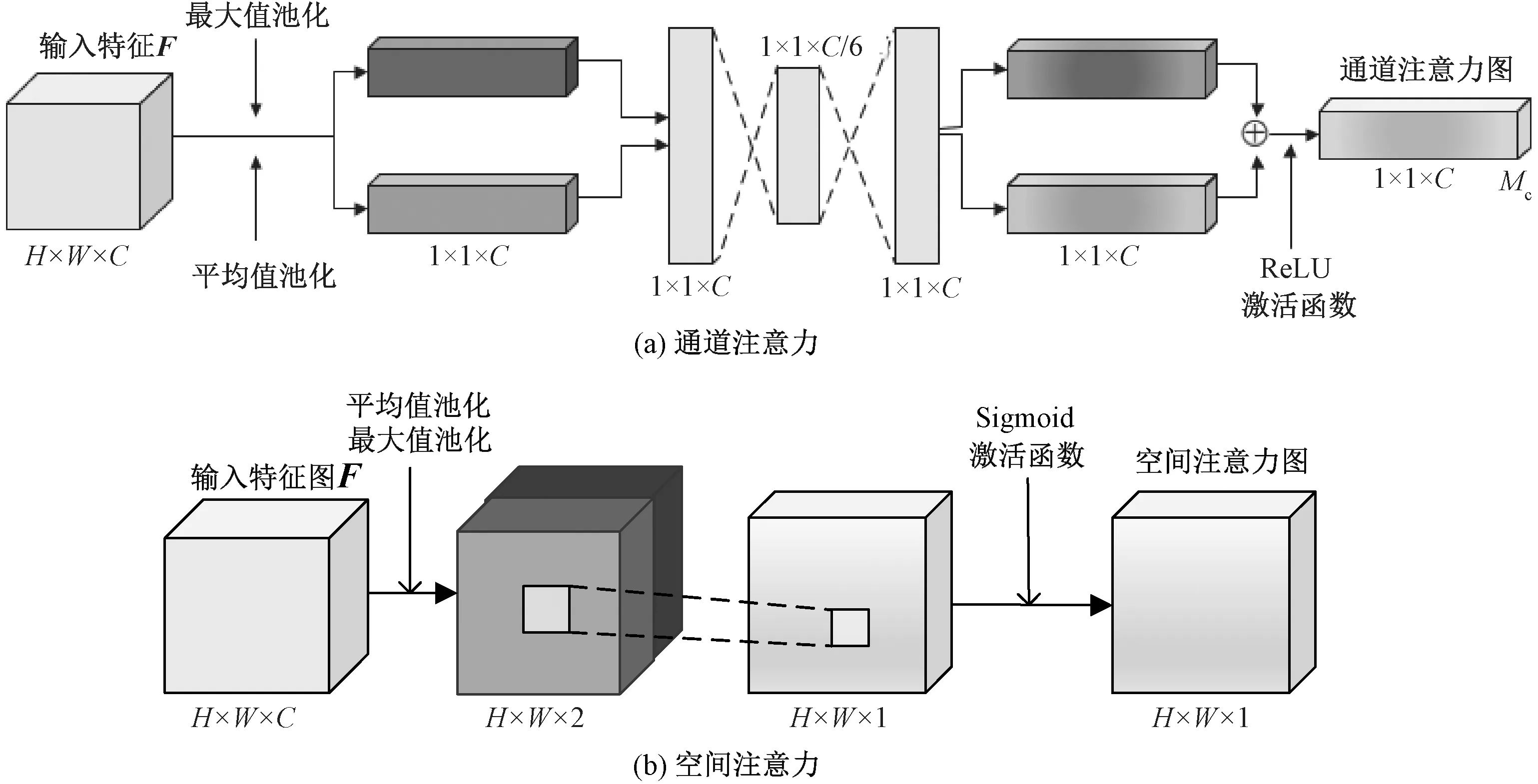
图5 注意力机制结构图
(4)
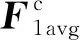
(5)
其中:符号“⊗”代表对应元素逐个相乘,即每一维度的特征乘以对应维度的加权系数。
(6)
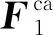
(7)
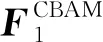
(8)
其中:W2表示卷积层2的参数,σ表示ReLU激活函数。
第4层为初级胶囊层(PrimaryCaps),提取目标的实体。由128个8×8的卷积核提取特征,每一个卷积核得到一组大小为1×C1的量神经向元,记为胶囊,最终得到若干个表示目标特征的初级SAR胶囊
ui=[u1,u2,…,uN1]=Squash(W3(F2)),
(9)
其中:W3表示初级胶囊层卷积核权重参数,N1代表初级胶囊层输出的胶囊数目,Q表示初级胶囊层的卷积核数目,C1取16。由于每一个胶囊由一组向量神经元组成,具有表示物体更多特征信息的能力。
第5层为数字胶囊层(DigitCaps),对初级SAR胶囊加权融合,最终得到N组胶囊,每一个胶囊的长度代表目标属于不同类别的概率。输入为初级实体胶囊ui,输出为N个胶囊,N代表数据集的类别数目。每个胶囊用vj表示,如下所示
vj=[v1,v2,…,vN],j=1,2,…,N,
(10)
计算过程如下
(11)
其中:cij是根据动态路由算法[16]确定的耦合系数。
为保证训练的收敛性,CBAM-CapsNet网络采用边缘损失函数[16]训练网络
Lk=Tkmax(0,m+-‖vk‖)2+
λ(1-Tk)max(0,‖vk‖-m-)2,
(12)
其中:m+、m-和λ为超参数。当k类别存在时,Tk为1;当k类别不存在时,Tk为0。
2 实验设计与结果分析
2.1 实验设计与评价指标
为验证本文所提算法在SAR少样本数据集上的有效性,分别在2种数据集上进行不同数据量下的实验。对于MSTAR数据集,分别随机选278张(占总训练集数目的10%,下同)、556张(20%)、827张(30%)、1 930张(70%)的数据进行实验,其中,除SN-132、SN-C71这2种样本在10%、20%、30%数据量情况下样本数目分别是27、55、82张外,其他类别的样本在不同数据量下的样本数目分别是28、56、83和193张。
对于实测车辆数据集,分别选取50、100、150、175张的图片作为训练集,在每次实验时,没有参与模型训练的图片作为测试集。其中,训练集中,不同类别的数据量是均衡的。在不同数据量下,分别对比了CBMA-CapsNet和其他算法的准确率和加入不同注意力机制下的准确率。
采用准确率和混淆矩阵评价算法的性能。由于本文中所有实验都是在数据类别均衡的情况下实现的,所以准确率可以客观评价算法性能。混淆矩阵中的每一个元素代表每一种类别被识别的数目或概率,更加直观地展示模型对不同类别目标的识别能力。
2.2 参数设置
设置Adam优化器的学习率为0.000 1,batch_size为8。为提高模型的稳定性,加快收敛,设置学习率衰减方式为指数衰减,衰减率为0.99。胶囊网络边缘损失函数的超参数λ=0.5,m-=0.1,m+=0.9。所用的服务器系统为Ubuntu18.04,显卡型号为GeForce GTX1080ti,显存为11 GB。
2.3 实验结果与分析
本文在不同训练集样本数目的情况下,对比了CBAM-CapsNet算法与其他经典算法(DCNN[7]、A-ConvNet[15]和CapsNet算法)的准确率。对比结果如表1所示。
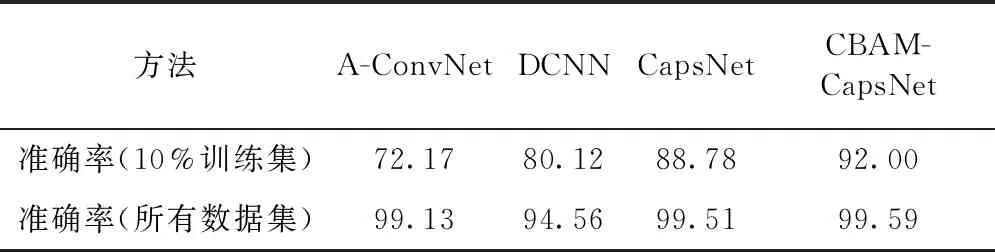
表1 MSTAR数据集不同方法准确率对比
在10%训练集的情况下,与前2种方法对比,CBAM-CapsNet对少样本数据的准确率分别提高19.83和11.88个百分点,与胶囊网络(CapsNet)相比,CBAM-CapsNet算法对少样本数据的准确率提高3.22个百分点;在所有数据集的情况下,CBAM-CapsNet算法与其他算法相比,准确率也有一定的提高。可见,相比于传统的卷积神经网络,胶囊网络的胶囊可以学习到更丰富的目标特征,在胶囊网络中引入注意力机制,可以使得神经网络重点学习对分类结果贡献大的特征,忽略无关特征,从而优化神经网络的准确率。本文算法在少样本数据集的情况下优势更加明显。
为验证注意力机制在模型中的作用,设计了不同数据量下,加入不同注意力机制的对比实验:分别对比了CBAM-CapsNet与卷积神经网络模型(CNN)、胶囊网络分类模型(CapsNet)、引入空间注意力机制的胶囊网络分类模型(SA-CapsNet)、引入通道注意力机制的胶囊网络分类模型(CA-CapsNet)、卷积注意力机制加在第2层卷积层后面的胶囊网络分类模型(CBAM2-CapsNet)对不同数据量下的准确率。
对于MSTAR数据集,分别对比了训练集每个类别随机取10%、20%、30%和70%的情况下,模型对测试集的准确率。不同模型的准确率对MSTAR数据集的识别结果对比如表2所示,CBAM-CapsNet方法的混淆矩阵如表3所示。准确率对比结果表明,不同数据量下,相比于其他算法,本文算法的准确率均有提高。其中,在训练数据为10%的情况下,CBAM-CapsNet相比于胶囊网络,准确率提高3.22个百分点,相比于传统的卷积神经网络,准确率提高27.51个百分点。
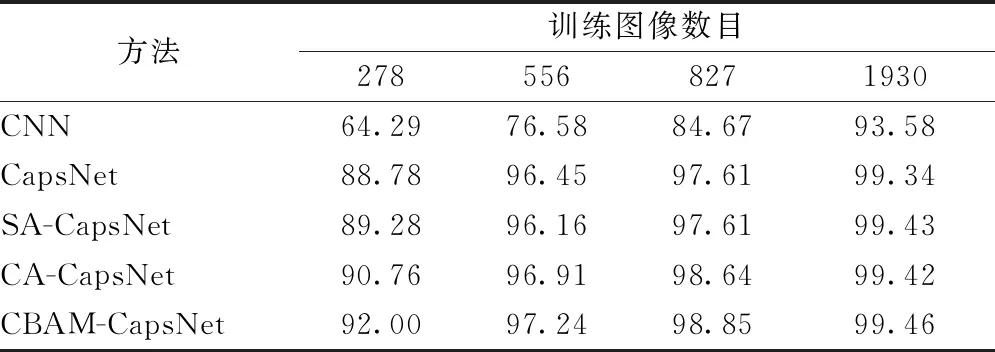
表2 MSTAR数据集不同数据量下、不同方法对比
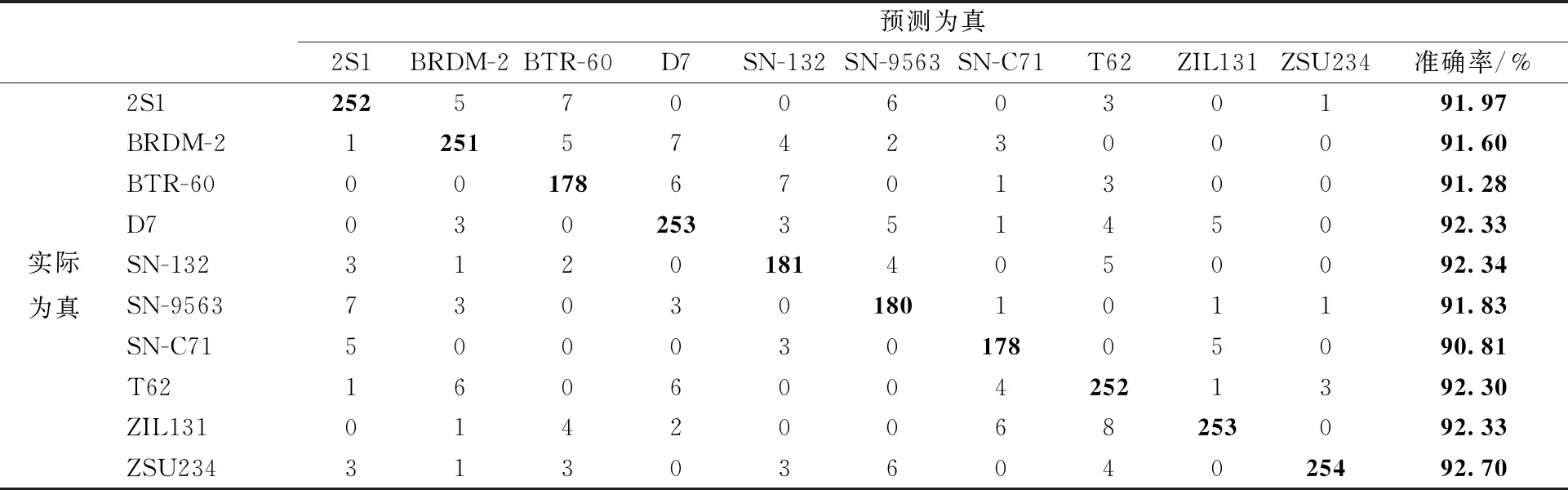
表3 CBAM-CapsNet在MSTAR数据集10类目标10%数据量下的混淆矩阵
对于实测车辆数据集,不同数据量下的准确率表格如表4,混淆矩阵表格如表5所示。结果表明,在训练集分别取50、100、150和275张的情况下,相比于卷积神经网络,CBAM-CapsNet算法的准确率分别提高22.91%、17.6%、26.51%和8.28%;相比于其他算法,本文所提算法的准确率也有一定提高。当训练集的数据量为50张时,相比于胶囊网络,本文所提算法的准确率提高9.09个百分点。注意到,CBAM-CapsNet算法的准确率略高于CBAM2-CapsNet算法。可见,将注意力机制模块加入卷积层1后面的准确率要高于加入卷积层2后面的准确率。卷积层1所提取出的特征为初级特征,卷积层2提取出的特征为高维抽象特征,可能为目标纹理、姿态等。在初级特征后加入注意力机制,可以提前抑制对分类结果不重要的初级特征,提高卷积层2提取高级特征的效率。如果在高级特征后才加入注意力机制,卷积层2会对所有的初级特征进行相同权重的学习,降低了提取高级抽象特征的效率。因此,CBAM-CapsNet算法的准确率略高于CBAM2-CapsNet算法。在少样本目标的情况下,目标特征缺乏,如果一开始就注意到目标区别于其他类别目标的重点部位,随后再对重点的初级特征赋予较高权重,提取高级特征,给予更多的关注,相比于对所有部位进行相同程度的提取高级特征来说,会提高神经网络提取信息的能力。
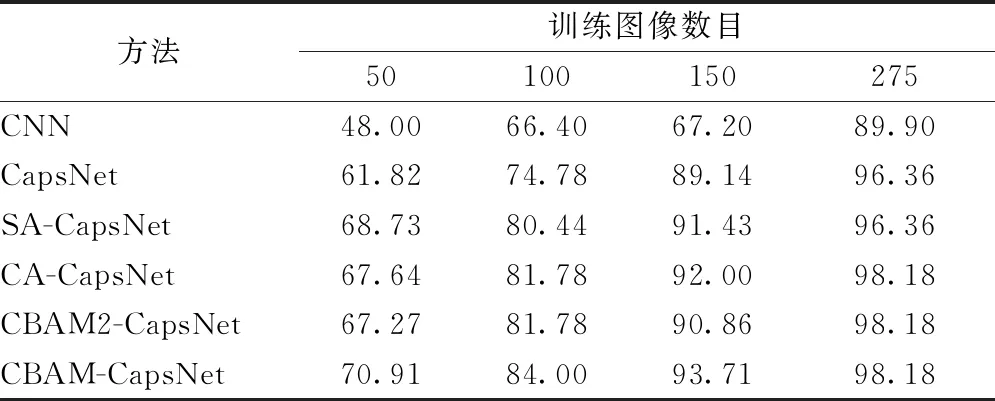
表4 实测车辆数据集不同数据量下不同方法准确率对比

表5 CBAM-CapsNet在车辆目标数据集5类目标100张数据量下的混淆矩阵
CNN方法与本文所提算法的特征图对比如图 6所示,从第1~5行依次是消防车、救护车、油罐车、相撞的2辆小汽车和追尾的2辆小汽车的图;第1列是每类图随机选取的一张SAR图像;第2~3列分别是CNN算法的第1层卷积层和第2层卷积层提取出的特征图;第3~4列分别是CBAM-CapsNet第1层卷积层和第2层卷积层提取出的特征图。将特征图进行对比可得:CNN提取出的特征仅为目标的大体轮廓,特征图比较模糊,不够清晰;而CBAM-CapsNet提取出来更细节更抽象的特征,特征图更清晰,细节更明显。其中,较为直观的是第4类目标:2辆小汽车相撞的特征图,该类目标的原SAR图像中有一个明显的“拐角”,对比CNN网络和CBAM-CapsNet网络中卷积层2提取出的高级特征发现,CNN的卷积层2提取出的特征包含整个目标,“拐角”特征不够明确;而CBAM-CapsNet的卷积层2将“拐角”作为单独的特征重点提取出来,使得后续神经网络专门针对“拐角”特征进行特征提取和分类决策,更有利于提高分类网络的准确率。此外,第2类目标救护车的SAR图像中,“竖线”属于实验场景中的背景回波,会影响神经网络对目标类别的判断。而在提取出的特征图中可以明显地看到,CNN在Conv1和卷积层2都提取出了“竖线”作为特征进行学习,使得后续神经网络误以为“竖线”也是目标的特征,干扰神经网络的特征提取和决策;但是,CBAM-CapsNet提取出的特征中不包含“竖线”,只提取出了目标的特征,更有利于后续的特征提取和分类决策。
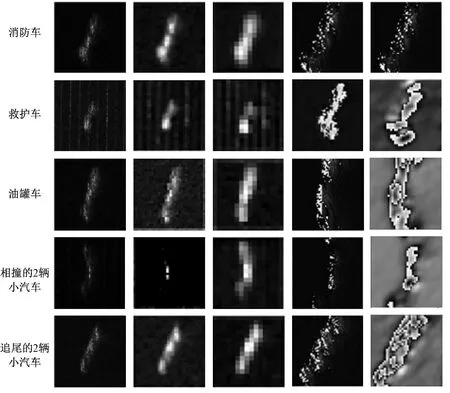
每列从左到右依次是:SAR原图、CNN第1层卷积特征图、CNN第2层卷积特征图、CBAM-CapsNet第1层卷积特征图和CBAM-CapsNet第2层卷积特征图
对比MSTAR数据和实测车辆数据的数据结果发现,实测数据的准确率整体上低于MSTAR数据的准确率,这是因为实测数据的数据量小于MSTAR的数据量。因此,CBAM-CapsNet基本符合训练集数据量越大,准确率越高的规律。在所有的实验结果中注意到2个细节:
一是2个数据集样本数目相差不多时,实测车辆数据的准确率略高于MSTAR数据集的准确率:实测数据中,当样本数目为275时,准确率为98.18%,MSTAR数据中,当样本数目为278时,准确率为92%。这是因为实测车辆目标数据集为五分类问题,分类难度略低于十分类问题的MSTAR数据,并且实测车辆目标数据集的分辨率也高于MSTAR数据集。
二是随着数据量的增多,本文算法对准确率改善程度呈现下降趋势,尤其是在实测车辆数据集中,当样本数目为275时,本文所提算法与CBAM2-CapsNet和CA-CapsNet这2种算法的准确率持平。对这一现象主要考虑到2点原因,一是本文所提算法旨在解决当数据量不足的情况下,如何使得神经网络更加充分高效的提取特征信息这一问题。当数据量增多时,意味着特征信息量增多,经典算法学习到了更多的信息量后,准确率会提高。二是实测车辆数据十分有限,当训练集为275时,测试集只有55张样本,98.18%的准确率意味着测试集中有一张SAR图像没有被正确分类。不同于MSTAR数据集的3 203张测试集,有限的测试集图像数目会导致测试结果存在一定的误差。
3 结论
本文研究基于CBAM注意力机制和胶囊网络的少样本SAR目标识别方法,解决了现有方法对少样本数据集识别准确率低的问题。利用胶囊网络可以使得神经网络表征更丰富的特征,在胶囊网络中引入CBAM注意力机制可以引导网络在学习过程中重点关注对分类结果贡献大的特征,弱化对分类结果贡献小的特征。在MSTAR数据集和实测车辆SAR图像数据集上分别对比不同数据量下本文算法和其他算法的准确率,结果验证了本文算法的有效性。因此,本文所提的模型在少样本数据集情况下,相比于传统算法,更具优势。
