基于改进粒子群算法的云计算调度策略
2022-11-12马钰杨迪王鹏
马钰,杨迪,王鹏
(长春理工大学 计算机科学技术学院,长春 130022)
云计算在一定程度上脱离了传统意义上的计算概念,是一个基于Web2.0的计算型服务平台,通过“云”端服务器将巨大的数据处理任务拆解、整合,通过特定的资源调度策略分配给系统内多个计算资源进行分析处理。其中资源调度算法对整个云计算平台具有十分重要的意义,是影响用户体验最重要的环节。云计算资源调度目的在于如何将用户的云任务请求在高服务质量、高响应速度的约束下,分配到云环境中的物理计算资源,其本质是一个NP完全问题,即多项式复杂性的不完全问题[1]。这一过程需要一系列执行效率优秀、结果稳定的调度算法支撑。近二十年来,人们通过对自然界的认知,提出了一个又一个新型群智能算法,并不断进行优化改进。一些性能突出、实现简单、执行稳定的算法,如遗传算法(Genetic Algorithm,GA)[2]、蚁群算法(Ant Colony Optimization,ACO)[3]、粒子群算法(Particle Swarm optimization,PSO)[4]、菌群优化算法(Bacterial Foraging Optimization,BFO)[5]、蛙跳算法(Shuffled Frog Leading Algorithm,SFLA)[6]、人工蜂群算法(Artificial Bee Colony Algorithm,ABC)[7]等已经应用到实际中,在减少能源消耗方面做出巨大贡献。其他新型和融合型算法也受到越来越多的关注。
上述算法中对粒子群算法的研究,重点集中在种群粒子的训练方式,即通过不同适应度函数对粒子进行筛选,保留筛选结果更加优秀的适应度函数,忽略了算法执行过程中的关键参数,即学习因子和惯性权重对算法整体执行效率的影响。
设定固定参数后,由于种群质量不同导致算法执行效率不稳定,部分种群在算法执行后期存在着陷入局部最优解的可能。针对上述不足,本文基于CloudSim平台使用模拟退火、自适应权重策略对粒子群算法进行优化改进,将算法的关键参数,即学习因子、惯性权重等交由上述策略进行实时控制,提高算法初期的全局搜索能力,加快算法后期筛选最优解和收敛速度,从而提高算法平均执行效率,在面对不同的云环境下能够更好更快地执行响应。
1 云计算资源调度算法
1.1 云计算资源调度模型
云计算的主要目标是将可用的云计算资源进行调度层面的优化[8]。调度算法通常目的是将云计算任务分散到各个可用处理器上,并以最大效率利用它们,降低整体运行时间。云计算中任务调度主要包括两方面:一是任务和虚拟资源间的调度关系,为云任务分配虚拟计算资源,二是虚拟计算资源和物理设施的调度关系,为虚拟计算资源提供物理设施支持[9]。
用户将云计算任务提交到分配服务器中,服务器响应到任务后自动将任务分割为一系列最小、可独立执行的子任务,数据中心使用相应优化调度算法,对收到的子任务合集进行合理分配,最终将处理结果展示给用户。云计算资源调度系统模型如图1所示。
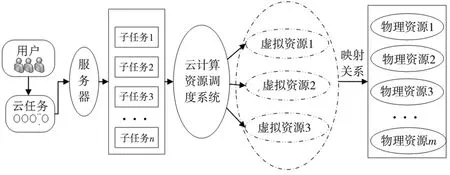
图1 云计算资源调度系统模型
云计算资源调度效率[10]直接影响总体执行效率,直观上反应为用户提交云任务后的响应时间和结果显示时间,对衡量服务质量起决定性作用。云计算中的调度本质上是一种映射关系,将客户提交的任务分配到性能各异的虚拟资源上,随后各个资源节点并行独立计算已分配的子任务。
在数学角度,云计算资源调度问题可描述为:服务端将n个云任务分配到m个虚拟计算资源节点上运算(m<n),Fm表示云任务和资源节点之间的映射关系,任务和资源节点的映射关系如下:

资源调度由资源调度策略、分配优化目标、资源调度算法、调度系统、界定关系和约束关系六部分组成。其中资源调度策略决定了整个云计算平台的总体性能,由服务商实际投入使用的物理资源配置决定;优化目标指调度过程中以用户特定需求、利润率、执行性能等作为目标进行对应的优化;调度算法是指在成本、响应时间等维度上对目标函数进行优化。
1.2 粒子群资源调度算法
粒子群算法是基于自然界中昆虫、兽群、鸟群和鱼群的动物群集智能行为,通过群体中个体之间的信息交流来寻找最优解的智能型算法。这些群体按照一定规律合作寻找目标,群体中的每个成员通过继承和学习其他成员的位置和速度信息不断改变自己的搜索方式。
算法中每个粒子包含两个属性:速度vi和位置xi。假设存在一个n维m个粒子的样本空间代表n个相互独立的子任务和m个虚拟计算资源,第i个粒子的位置表示为:xi={xi1,xi2,…,xij},其中j表示云任务编号,xij表示分配的虚拟资源编号;全局最优解表示为:pg={pg1,pg2,...,pgd}。粒子的速度和位置的更新方法如下:

其中,ω表示惯性权重;c1和c2表示学习因子,c1和c2的大小决定了粒子识别能力的强弱和分享信息的效率[11];r1和r2是[0,1]区间内均匀且相互独立的随机数。
在粒子群算法中,常用适应度来筛选不同的粒子,适应度的值通常通过目标函数计算得出。在云计算调度过程中,常用云任务的总完成时间来衡量粒子优劣。云任务在虚拟计算资源上的执行时间通常使用一个m×n阶的矩阵表示。MATRIX(i,j)表示虚拟计算资源j执行云任务i所用的时间。当MATRIX(i,j)=0时表示子任务i没有进行分配。虚拟计算资源j上分配到的子任务运行时间如下:

其中,i∈ [1,n];j∈ [1,m];n表示分配到单个计算资源上的云任务数量;m表示云计算资源数量。各个虚拟资源都处于空闲状态时,说明所有云任务均执行完毕,得到完成总时间TotalTime,表达式如下:

粒子群算法的核心参数为惯性权重ω与加速系数。如果c1与之较大会导致随机性过大,c2值较大会影响最优值,ω值较大会让粒子速度过大从而越过区域目标,影响算法稳定性。在保证种群规模的情况下,适当提高迭代次数使结果更趋向于最优解。
当粒子群中的某个个体寻找到最优解或接近最优解时,其他的粒子会自发的向其学习,快速向最优方向搜索,大大提高了算法的效率。但粒子群算法依赖于初始种群的质量,如果设置不当会导致算法后期筛选最优解的速度变慢与陷入局部最优解等问题。
2 粒子群算法优化改进
2.1 基于模拟退火的粒子群优化算法(SAPSO)
粒子群算法前期由于参数设置的不同,导致全局寻优能力不足,寻找到的局部最优解数量较少,而模拟退火策略(Simulated Annealing,SA)在全局寻优上有着天然的优势,该策略的核心是物理学中的固体降温退火规律。该算法以一定概率接受劣质解,从而在一定程度跳出局部最优解。本节在粒子群算法的基础上引入模拟退火策略,采用杂交运算和带高斯变异运算[12],通过式(2)、式(3)计算出一代新的群体,独立进行杂交和带高斯变异运算。将得到的结果个体进行模拟退火处理,获得最终可行解个体。
每轮计算中,杂交运算选择一定数量的粒子进行杂交操作,产生新的子代。杂交公式如下:

其中,x代表位置向量,而childk(x)和parentk(x)中的k=1,2对应子代、父代空间位置;p代表随机空间向量。子代粒子的速度计算公式如下:

其中,v代表速度向量;而childk(x)和parentk(x)中的k=1,2对应子代速度和父代速度。变异运算选取定量的粒子进行高斯变异,淘汰变异前的粒子,公式如下:
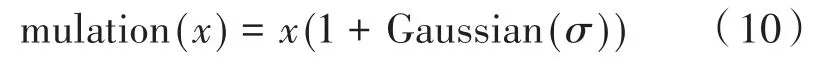
首先通过进化产生一个适应度较高的优良群体,然后以一定概率进行杂交、变异生成一个多样性群体,最后通过模拟退火策略对群体进行降温优化。具体算法流程如下:
(1)初始化参数:交叉概率Pc,变异概率Pm,学习因子c1和c2,温度冷却参数C,初始温度T。
(2)随机产生规模为N的粒子种群。
(3)采用式(2)、式(3)对种群中的粒子进行更新操作。
(4)对步骤(3)产生的种群以交叉概率Pc筛选符合条件的粒子形成新的子种群。从子种群中随机选取两个个体xj,xk,按照式(6)、式(7)进行交叉操作,产生两个新个体x′j,x′k。
计算适应函数值f(xj),f(xk),f(x′j),f(x′k),若min{1,exp(-f(x′j)-f(xj)/T)} >R,则把x′j作为新的粒子个体,若 min{1,exp(-f(x′k)-f(xk)/T)} >R,则把x′k作为新粒子个体。其中R∈ [0,1]。
(5)对交叉操作后产生的新种群以概率Pm筛选出符合条件的粒子形。从新的种群中随机选取粒子个体xj,按式(10)进行高斯变异操作,产生一个新粒子个体x′j,计算目标函数值f(xj)和f(x′j),若 min{1,exp(-f(x′j)-f(xj)/T)} >R,则 把x′j作为新粒子个体。
(6)当经过筛选后的个体满足预定最优解条件时,即为全局最优解,算法结束。
(7)若迭代次数不足,则进行退火降温操作,令T→CT,回到步骤(3)。
基于模拟退火的粒子群算法流程图如图2所示。

图2 基于模拟退火的粒子群算法程图
2.2 基于自适应权重的粒子群优化算法(SAWPSO)
粒子群算法在随机搜索中存在易陷入局部最优解的问题,惯性权重的取值对算法的前期和后期都起着决定性作用,较大的惯性权重会加强算法前期搜索全部可行解的能力,较小的惯性权重会加快算法后期筛选最优解的速度。因此可以通过自适应权重策略控制惯性权重来达到全局搜索能力和局部搜索能力的平衡,加快算法的执行速度。
本节中采用的自适应惯性权重(Self-Adaptive Weight)[13]系数的表达式如下:

其中,ωmax和ωmin分别表示ω的最大值和最小值;f表示粒子目标函数即适应度的值;favg和fmin表示当前粒子的平均目标值和最小目标值。式中的ω使用自适应权重策略进行实施更改。算法具体步骤如下:
(1)将一个云任务和一个虚拟资源的对应分配关系视为一个粒子解,初始化粒子群中的相关参数。
(2)计算每个粒子的适应度的值,并从中筛选适应度最优的粒子作为一个局部最优解。
(3)比较当前粒子的适应度与均值适应度,根据结果更改公式(11)的惯性权重系数。
(4)开始进一步迭代,根据自适应权重方程来调整最优粒子的速度和位置,计算方法如下:

(5)粒子位置更新后再次调用目标函数,并取得最新的适应度与整个算法流程中最好位置gbest比较,如果适应度提升,则将最佳位置更新。
(6)若未满足预定的收敛条件则返回步骤(1),若满足条件则算法终止,求得最优解。
基于自适应权重的粒子群优化算法流程图如图3所示。

图3 自适应权重粒子群算法程图
3 实验结果与分析
3.1 实验环境及参数设置
本文基于CloudSim平台进行仿真模拟实验,通过虚拟化技术将实例对象模拟为实际的物理资源,提供双向分配操作,完成物理主机、虚拟机、云任务之间的相互映射。其中软硬件环境具体配置如表1和表2所示。

表1 硬件环境

表2 软件环境
CloudSim平台虚拟机、算法参数如表3所示。

表3 虚拟机、算法参数设置
3.2 实验结果对比分析
实验中虚拟机和云任务均采用空间共享策略,即运行在同一个虚拟机的任务需要排队按顺序完成。
本文通过以下两个实验对改进前后的粒子群算法进行比对,每组实验结果为运行10次取平均值。
实验1:粒子群算法优化前后的执行效率比对传统粒子群算法(PSO)与基于模拟退火策略(SAPSO)和自适应权重策略(SAWPSO)的优化算法在同等条件下进行测试,测试结果如图4所示。

图4 粒子群算法优化结果
图4中展示了粒子群算法优化前后的执行效率对比结果,从实验结果来看,云任务数量相同时,基于自适应权重的粒子群优化算法所需执行时间更短。
实验2:不同资源调度算法的负载均衡性能比对云环境中随着云任务数量急剧增加,良好的调度算法可以更加高效地处理这些计算任务。本文采用虚拟机负载不均衡率D来衡量每个虚拟资源上分配到的云任务数量情况。由于用户提交的云任务往往在数量上存在很大差异,所以不能以传统的虚拟机-云任务数量对应关系评估,而是选用更加均衡的虚拟机占用时间来衡量,衡量方式如下:

而每个虚拟机占用的时间T如下:

实验过程中将遗传算法(GA)、蚁群算法(ACO)、粒子群算法(PSO)、基于模拟退火的粒子群算法(SAPSO)、基于自适应权重的粒子群算法(SAWPSO)处于不同云任务数量下时虚拟机的负载情况进行比较,实验结果如图5所示。

图5 任务数不同时负载均衡情况对比
通过实验1与实验2得出,基于自适应权重的粒子群优化算法相对于其他调度算法的负载均衡性能更好,执行效率更高,资源利用率更大。优化前粒子群算法存在着固有缺陷,如全局搜索能力不足,后期收敛能力缓慢。模拟退火策略提高全局搜索能力,提高可行解数量,对算法执行效率有一定改进,而自适应权重则侧重于提高算法后期收敛速度,故自适应权重策略对粒子群算法的执行效率提高效果更加突出。
随着任务规模的增加,系统资源利用率逐步提升,由于时间限制,本文采用的虚拟机数量较少,加之群智能算法本身子代的随机性属性,会导致个别虚拟机分配不到任务而造成空闲的情况。但当问题规模足够大时,使用群智能算法进行优化后,资源利用率得到了较大的提升。
4 结论
结合现有的群智能算法和CloudSim云计算平台技术等研究场景,本文的论述重点在于如何最大限度提高资源调度的效率,如何将现有的算法与其他调度策略相融合,应用这些策略后又该如何调节参数来最大化这些优化。基于模拟退火算法和自适应权重的粒子群优化算法在性能上有了一定的提升,但仍有许多地方需要改进。例如针对单个高处理量云任务或碎片化云任务时,算法的执行时间仍不是稳定的,算法的随机性过大,在实际云环境下可能增大云服务器在分配任务过程中的负担,造成不必要的消耗;针对目前的群智能算法发展,不仅要考虑到算法的执行效率,还要考虑到算法在不同环境下的稳定性以及在整个调度过程中的分配任务时间的占比情况,这也将是云计算资源调度等相关领域发展的重点。
