应用多层感知机回归的无参考型超分辨图像质量评价
2022-11-11朱丹妮许小华贺静婧张凯兵
朱丹妮,许小华,贺静婧,王 晨,张凯兵
(1.延安职业技术学院 网络信息中心,陕西 延安 716000;2.延安职业技术学院 公共教学部,陕西 延安 716000;3.延安职业技术学院 经济管理系,陕西 延安 716000;4.西安工程大学 电子信息学院,陕西 西安 710048)
0 引 言
当今社会,人们对相机、手机等设备的图像分辨率要求越来越高,利用超分辨来提高图像分辨率的技术越来越受到关注。图像超分辨率是一种利用一幅或多幅低分辨率图像重建出一幅具有更多纹理细节的高分辨率图像的图像恢复技术,该技术在公共安全、医疗影像等多个领域具有广阔的应用前景[1-2]。因此,如何评价超分辨重建图像的质量, 进而评价不同超分辨重建算法变得非常重要[3]。
根据评价主体的不同,评价图像的方法包括主观质量评价和客观质量评价。由于主观质量评价方法无法运用数学模型对其进行描述,因此客观质量评价方法在实际中更具有研究价值。客观质量评价旨在通过算法自动实现图像的质量评价。根据所需原始图像信息的多少,客观质量评价方法可以划分为全参考型图像质量评价(full reference image quality assessment,FR-IQA)、部分参考型图像质量评价(reduced reference image quality assessment,RR-IQA)和无参考型图像质量评价(no-reference image quality assessment,NR-IQA)3大类评价方法[4-5]。目前,在图像超分辨重建领域,峰值信噪比(peak signal-to-noise-ratio, PSNR)和结构相似度(structural similarity, SSIM)等指标被广泛用于评价超分辨图像的质量。然而,这些传统方法的评价结果与主观感知的一致性较差[6]。此外,在采用FR-IQA和RR-IQA方法评价超分辨图像时,都需要获取原始高质量图像的信息作为参考,但在实际应用中,获取原始高质量图像需要付出很大代价,有时甚至无法获取。因此利用NR-IQA方法评价图像受到更多研究人员的青睐。
NR-IQA旨在不依靠原始的参考图像,直接对图像视觉质量进行评估[7-11]。针对超分辨图像,研究人员从不同技术角度预测超分辨图像的质量[12-13]。比如,黄慧娟等提出根据奇异值分解度量超分辨图像质量[14]。YEGANEH等从频域和空域建立概率统计模型,并将其转化为超分辨图像质量模型[15]。MA等分别从局部频域、全局频域、空间域提取特征,再根据随机森林和脊回归构成两阶段回归模型,从而预测超分辨图像质量[16]。ZHANG等利用AdaBoost回归和和脊回归级联来评估超分辨图像质量[17]。除了上述传统方法之外,神经网络也被广泛应用于超分辨图像质量评估的任务中。FANG等提出了基于深度卷积神经网络(deep convolutional neural network, DCNN)的超分辨图像评价方法[18]。BARE等利用残差网络的特性构建了一种跨连接模型,从而实现超分辨图像质量评估[19]。刘锡泽等提出一种基于多任务学习的超分辨图像质量评估网络[20]。ZHOU等设计了一种将纹理特征与结构特征相结合的双流网络模型来评估超分辨图像的质量[21]。
大规模的数据集上预训练的VGGNet等经典深度学习网络被用于解决小样本任务并取得了较好的成果。此外,MLP作为最早被提出的神经网络模型,在图像处理、模式识别等诸多领域具有良好的表现[22]。鉴于深度特征与MLP在计算机视觉领域的成功应用,本文提出一种应用MLP回归的SRIQA方法。该方法利用预训练好的VGG16模型提取影响图像质量变化的深度特征,然后利用MLP构建特征与质量分数之间建立回归模型,从而实现超分辨图像质量的评价。
1 图像质量评价模型
1.1 深度特征提取
神经网络与传统算法相比无需设计人工特征,可以将图像直接作为网络的输入,避免了传统算法中复杂的特征提取和数据重建过程,使得研究人员的研究方向逐渐从统计特征向深度特征进行转变。考虑到训练程度高的神经网络模型时间复杂度较高,本文利用预训练的VGG16图像分类模型提取超分辨图像视觉统计特征[23]。
VGG16net主要包含5部分卷积层(13个卷积层)和3个全连接层,其中前2个全连接层的神经元个数为4 096,最后一层神经元个数为1 000。随着网络层数的增加,所获得的特征图更宽,同时高维度的特征能更充分表征所提取图像的信息,因此本文从预训练模型的7层全连接层提取4 096维特征用于描述超分辨图像的失真机制。
1.2 多感知机回归模型
本文提出的评价模型构建主要分为2个阶段,即训练模型阶段和测试模型阶段。
1.2.1 训练模型阶段
本文提出的评价模型训练过程如图1所示。

图 1 MLP回归的无参考型SRIQA方法训练过程
从图1可以看出,在训练模型阶段,首先通过预训练好的VGG16网络提取训练集图像的深度特征,然后利用MLP建立深度特征与平均主观意见值之间的回归模型,即可得到图像质量评价模型。

根据MLP回归算法,第1步为前向传播,将训练集中的第i幅图像的特征xi提供给输入层,那么第i幅图像隐含层的第j个神经元所对应的输出可以表示为
Hij=g(xiWj+bj)
(1)
式中:Wj为输入层到隐含层的第j个神经元的权重向量;bj为输入层到隐含层的偏差参数;g(·)为激活函数。
然后,经过前向传播的隐含层,第i幅图像输出层神经元所对应的输出可以表示为
(2)

在输出层,利用平方误差损失函数计算输出预测分数和主观质量分数误差,其损失函数可以表示为
(3)

第2步为误差反向传播过程。首先计算输出层神经元损失函数的梯度,然后计算隐含层神经元损失函数的梯度。由于输出层到隐含层的权重与隐含层到输入层权重更新方式相同,本文将更新权重的数学表达式统一表示为

(4)
式中:t为当前迭代次数;η为学习率,其数值范围为0<η<1。同样地,由于输出层到隐含层的偏差与隐含层到输入层偏差更新方式相同,通过梯度下降更新偏差参数,可表示为

(5)
该算法在达到预设的最大迭代次数或损失小于一定阈值时停止。
1.2.2 测试模型阶段
MLP回归模型的测试过程如图2所示。

图 2 MLP回归的无参考型方法测试过程
图2中的测试图像首先通过VGG16网络提取图像的深度特征,然后将接收到的VGG16深度特征作为MLP回归的输入层,馈送到训练好的MLP回归模型中,即可获得待测超分辨图像的质量预测分数。
2 实验结果及分析
2.1 超分辨图像数据库介绍
为了评估所提出的评价方法的有效性,本文采用文献[16]中的超分辨图像数据库作为基准来评估所提出评价方法的性能。该图像数据库中包含1 620张超分辨图像以及相应主观质量分数。其中1 620幅超分辨图像由9种不同的超分辨算法对180幅低分辨进行超分辨图像重建得到。
2.2 衡量算法评价技术指标
在实验中,采用3类指标中的4种具体性能指标衡量不同超分辨图像质量评价算法的性能。
2.2.1 准确性指标
均方根误差(root mean square error,RMSE)使用该指标计算主观质量分数与预测分数之间的误差。当RMSE的值越小,表明该算法预测结果的准确性越高。
2.2.2 相关性指标
PLCC[24]主要反映的是主观质量分数与算法预测分数之间的相关性。通常,当PLCC值接近1时,表明算法预测结果与人眼主观具有良好的相关性。
2.2.3 单调性指标
SROCC[25]和肯德尔秩序相关系数(kendall rank order correlation coefficient,KROCC)[26]用于衡量主观质量分数与预测分数之间的单调性。如果SROCC和KROCC的值越接近1,则意味着图像质量评价算法具有更好的单调性。
2.3 有效性实验
首先通过实验验证深度特征的有效性和MLP回归模型的有效性,然后通过交叉验证实验确定了MLP回归模型的各个参数设置,同时分析了训练集规模对评估模型性能的影响。为了证明所提出方法的有效性,从准确性和一致性2个方面比较所提出方法与其他6种不同图像质量评价方法的性能。
2.3.1 特征有效性
采用VGG16的预训练模型提取图像深度特征。为验证所提取特征的有效性,提取了VGG16模型第7层全连接层(fully connected layer 7, FC_7)和第8层全连接层(fully connected layer 8, FC_8)的深度特征,通过MLP回归建立其与质量分数之间的映射模型,并进行对比实验。为了减少随机选择数据造成实验的误差,本文随机选择数据集中80%的样本参与训练,剩下的20%作为测试,该实验重复进行100次,计算平均值作为最终的衡量指标。表1是2类特征的性能指标比较的结果,其中加粗的数字表示最佳性能。
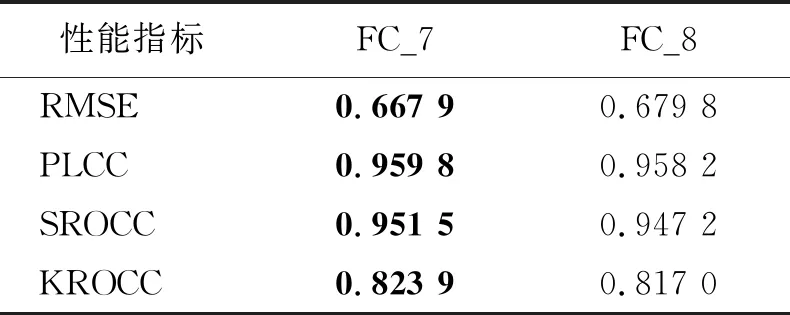
表 1 2类特征的4种性能指标比较
从表1可以看出,4 096维FC_7特征表现出比FC_8特征更好的性能,表明所提取的FC_7特征更能表征超分辨图像的质量,后续实验中均采用FC_7特征度量超分辨图像的质量。
2.3.2 回归模型有效性
为验证MLP回归的有效性,本节将传统的支持向量回归(support vector regression, SVR)模型性能与之进行对比。实验中,仍然选择数据集中80%的样本参与训练,剩下的20%作为测试,表2展示了2种回归模型在测试集上获得的客观评价的比较结果,其中加粗的数字表示最佳性能。

表 2 2种回归模型的4种性能指标比较
从表2可以看出,MLP在预测超分辨图像质量方面的准确性更高。这是由于MLP回归首先将超分辨图像的深度特征通过非线性函数映射到一个高维的隐空间,然后在高维空间的特征与质量分数间建立回归关系,表现出比SVR更强的非线性映射能力。因此,相比于SVR,MLP回归的效果更优。
2.4 MLP模型参数选择实验
对于任意一个回归模型,参数的选择对模型性能的影响极其重要。在本节中,首先确定MLP回归的激活函数。其次,根据选择的激活函数,通过一系列交叉验证实验确定MLP相关超参数(MLP隐含层中神经元的个数和正则项参数),以优化相应的模型。
2.4.1 激活函数的选择
激活函数对于MLP回归模型的优化学习来说具有十分重要的作用。在实验中,本文保持其他参数不变,通过改变不同的激活函数,通过观察均方误差(mean square error,MSE)的变化情况,选择合适超分辨图像质量评价模型的激活函数。本文选择identity、logistic、tanh和relu 等4种不同的激活函数进行对比实验,图3展示了保持其他参数不变,不同激活函数对应的MSE值。

图 3 4种激活函数对应的MSE值
从图3可以看出,identity激活函数所对应的MSE最大,其性能表现最差,而另外3种激活函数MSE值相当,logistic所对应的MSE值最小,其性能表现最好。同样地,根据网格交叉验证实验也得出相同的结论。因此,随后的实验均选择logistic作为激活函数。
2.4.2 MLP隐含层中隐含层神经元个数的设置
选择合适的层数以及隐含层节点数,在很大程度上都会影响MLP回归模型的性能。理论上网络层数越深,拟合函数的能力增强,效果更好。但是实际上更深的层数可能会带来过拟合的问题,同时也会增加网络的训练难度,导致模型难以收敛。通过实验选择单个隐含层的MLP回归模型。
在确定隐含层的层数之后,接着确定隐含层中包含的神经元个数。通常情况下,隐含层中较少的神经元会导致欠拟合。相反,当神经网络具有过多的神经元时,有限信息量的训练集不足以训练隐含层中的所有神经元,容易会导致过拟合现象。而且,即使训练集中拥有足够的样本,隐含层中过多的神经元会增加训练时间,难以达到预期的效果。因此,选择一个合适的隐含层神经元数量至关重要。为获得合适的隐含层神经元数量,从100到500个神经元开始,每隔100个神经元在训练集上进行交叉验证实验。图4为隐含层中不同神经元个数的MSE值。

图 4 不同神经元个数的MSE值
2.4.3 正则化参数的选择
在MLP回归模型中,另一个重要的参数为公式(3)的正则化参数α。本质上,该参数的大小会影响预测结果。为了得到准确的参数以合理平衡重构误差项和正则化项,本文根据经验预设了7个不同的α值(10-6,10-5,10-4,10-3,10-2,10-1,1),在训练阶段进行交叉验证实验以获得最优α。图5提供了选择不同正则化参数值时的学习误差。

图 5 随着α值的增加MSE相应的变化
从图5可以看出,随着α值的增加,MSE值也发生相应的变化,选择其中最小MSE值对应于最优的正则化参数值α,本文取α=10-4。
2.5 训练集的大小对模型性能的影响
本节对比了不同大小的训练集对预测性能的影响。实验中,将数据库随机划分为2部分,使训练集在数据库中所占比例从10%到90%变化,变化间隔为10%,其余样本构成测试集。为了减小随机因素引起的误差,在相同网络参数条件下重复100次实验,计算测试集上的评价指标的均值作为各个模型最终性能指标。图6展示了随训练集比例规模的增加各个模型最终性能指标的变化。

图 6 训练集比例对4种性能指标的影响
从图6可以看出,随着训练集比例的增加, 模型的性能指标也在提升,当训练集比例达到一定比例时,各个性能指标提升较小且几乎不再变化。其中,采用数据库的30%作为训练集时,SROCC指标已经超过0.9。根据实验结果可以得出,本文方法能够在使用少量训练样本的情况下,能获得一个性能较优的图像质量评价模型。
2.6 一致性实验
为了验证本文方法的实验结果与主观感知分数之间的一致性,本文分别与6种不同的无参考型评价方法(文献[8]、文献[7]、文献[27]、文献[10]、文献[4]和文献[16])进行对比实验。在一致性实验中,将数据将划分为2部分,随机选取数据库中80%的样本参与训练,剩余的20%的样本作为测试集,以评估模型的性能。图7展示了100组实验中的其中一组训练测试实验的散点图。

(a) 文献[8]
从图7可以看出,这些方法都取得了较理想的主客观一致性,其中图7(a)文献[8], 图7(b)文献[7], 图7(c)文献[27]3种方法一致性结果比图7(d)文献[10]的方法, 图7(e)文献[16]的方法的一致性结果较差。这是由于图7(a)、(b)、(c) 3种方法都是基于自然图像设计的评价模型,而且这3种方法都采用传统的统计特征表示超分辨图像质量,使用单一的SVR建立评价模型,所以实验结果不理想。虽然图7(e)文献[16]的方法采用了传统的统计特征,但是它采用了回归森林的方法建立评价模型,因此取得比图7(a)、(b)、(c) 3种方法更好的结果。图7(d)文献[10]的方法设计了一个将特征提取和回归整合在一起的卷积神经网络进行图像质量评价,但是由于浅层的卷积神经网络模型难以充分表征超分辨图像失真机理,因此实验结果较差。图7(f)文献[4]的方法采用了稀疏表示的方法,但是由于该方法无法更新字典,因此实验的一致性结果略差。在一致性实验结果中,本文方法优于其他对比方法,这是因为一方面,本文方法从提取特征到回归映射都是基于DNN的网络框架,DNN通过深层次特征学习,可以获得更利于表达图像质量的深度特征;另一方面,所采用的MLP回归本质为主动寻找有效的映射方式将低维空间的训练数据映射到高维空间,然后在高维空间建立回归模型,相比于被动的映射SVR、MLP的回归效果更优。
为了减小单次实验可能的性能偏差,将训练测试实验进行100次,计算各个评价算法性能的平均值,见表3,其中加粗的数字表示最佳性能。

表 3 不同图像质量评价方法的4种性能指标比较
表3中,文献[8]、文献[7]和文献[27]3种评价算法的RMSE指标均大于1,表现出较差的准确性。而文献[10]、文献[16]、 文献[4]和本文提出的质量评价算法对应的RMSE指标均小于1,而且本文方法具有最小的RMSE值,展现出最好的性能。类似地,文献[8]、文献[7]和文献[27]3种评价算法的SROCC均小于0.95, KROCC值均小于0.8,而本文算法对应的SROCC指标超过于0.95,KROCC指标大于0.8,表现出良好的单调性。此外, 本文算法的PLCC指标展现出最优的相关性,在性能上明显优于其他评价方法。
为进一步证明所构建的MLP回归模型与主观感知具有较好的一致性,文章首页的OSID码“开放科学数据与内容”的图片展示了本文方法在训练测试实验中9个最佳例子评估结果,以验证本文方法的与主观感知具有更好的一致性。每幅图片正下方的数值依次对应了每幅图像相应的主观感知分数/本文方法的预测分数/文献[16]方法的预测分数。从该幅图片的预测结果可以看出,对于第一行纹理细节较为丰富的超分辨图像,尽管文献[16]的方法预测结果很接近主观感知分数,本文方法的预测结果比文献[16]的方法更接近主观感知分数。对于后两行缺失较多纹理细节的超分辨图像,与文献[16]的方法预测结果相比,本文方法也可以获得与主观感知分数更接近的质量分数。尤其对最后一行的超分辨图像,本文方法预测的结果与主观感知分数几乎相同。通过对比观察可以看出本文方法不仅可以较准确评价纹理细节较为丰富的超分辨图像,也可以有效评价图像质量较差的图像。这是因为基于深度学习的特征可以充分且准确描述超分辨图像降质的过程。此外,深度特征与主观感知分数之间的映射关系更容易通过MLP回归的非线性映射能力获得较高的预测精度。
3 结 语
本文提出一种应用MLP回归的无参考型超分辨图像质量评价方法。该方法先采用VGG16提取图像的深度特征,再将得到的特征作为MLP回归模型的输入,建立深度特征与主观感知分数之间非线性映射关系。实验结果表明,本文所构建的MLP回归模型可以较准确地评价超分辨图像质量,且与主观感知具有较好的一致性。
在今后的研究中,该方法可以从以下2个方面改进:一是由于本文直接采用ImageNet数据集的图像分类预训练模型提取超分辨图像的深度特征,因此可以考虑在超分辨图像数据库中训练模型,以提取能充分表征超分辨图像质量的感知特征。二是增加有利于评价超分辨图像的先验知识训练评价模型,以提高评价模型的性能。
