普洱季风常绿阔叶林乔木物种多样性高分辨率遥感估测
2022-11-11刘鲁霞桑国庆李增元
刘鲁霞,庞 勇,桑国庆,李增元,胡 波
1 济南大学水利与环境学院,济南 250024 2 中国林业科学研究院资源信息所 国家林业和草原局林业遥感与信息技术重点实验室,北京 100091
季风常绿阔叶林是我国热带季雨林、雨林向亚热带常绿阔叶林过渡的植被类型,具有丰富的物种及复杂的垂直结构,林冠高度一般在28 m以上[1]。由于复杂的结构及较高的生产力水平及生物多样性水平,季风常绿阔叶林对于保护环境和维持全球碳平衡都具有不可替代作用[2]。季风常绿阔叶林是云南普洱地区主要的森林植被类型之一,由于受人类种植活动的影响,其分布面积逐年下降,严重影响到森林生态系统功能与服务的发挥[3]。近年来,随着天然林资源保护工程等生态工程的实施,森林面积呈现恢复性增长的趋势,但新增加森林的功能仍然需要更长时间才能恢复[4]。因此,对季风常绿阔叶林群落生物多样性维持机制研究对天然林保护具有重要意义。
尽管地面调查如森林动态监测大样地建设或离散小样方取样是研究群落结构、功能及动态、群落与环境因子关系以及生物多样性维持机制等的重要手段。由于人力、物力所限,地面调查不可能对森林生物多样性进行全面而详细的调查及监测,如何将小尺度地面调查信息推演到大尺度是当前面临的重大挑战[5]。遥感观测技术具有覆盖广、持续、动态的特点,为生物多样性大区域、持续监测提供了大量数据源。一般来说,森林物种多样性遥感监测有两种方法:一是利用遥感数据直接监测森林生物个体;二是利用遥感获取的环境参数间接估测森林物种多样性[6]。由于热带、亚热带地区森林垂直结构复杂,使用高分辨率遥感直接监测森林生物个体面临很大困难。根据森林物种多样性与环境之间的假设,如生产力假说、环境异质性假说及光谱异质性假说,使用遥感技术如Landsat长时间序列卫星遥感数据间接监测物种多样性应用越来越广泛[7]。生产力假说主要是基于生态系统食物网和资源制约理论,该假说认为当资源量充足可靠时,单位面积上共存的物种数量就会越多[8]。长期以来,生态学家一直对物种多样性及环境异质性之间的关系进行研究,环境异质性越高,其包含的潜在生态位越多,能够支持的物种数量越多[9]。其中,根据遥感信号中的光谱变异或光谱异质性也间接反映了环境异质性,也被当作估测物种多样性的有用工具。因此,代表生产力水平的植被指数[10]和垂直结构,代表环境异质性的土地利用类型、植被类型分类数据[11],代表光谱多样性的光谱反射率变异参数[12]等遥感获取的间接参数用作解释森林物种多样性。
使用遥感数据监测森林物种多样性时,一般来说遥感数据的空间分辨率即像元大小要小于样地大小[13]。Rocchini等[14]在对比不同空间分辨率遥感数据对生态系统α多样性的估测能力影响时发现由于混合像元问题,更粗的空间分辨率导致对α多样性的估测能力较差。更高的空间分辨率能获取样地尺度内遥感变异参数,对于使用遥感数据解释森林物种多样性比粗分辨率遥感数据更有优势。因此,高分辨率遥感数据在估测区域森林物种多样性中发挥着不可替代的作用[15]。机载高光谱数据由于其较高的空间和光谱分辨率,在森林树种分类应用上具有较大优势,对精细尺度森林物种多样性估测研究具有重要价值[16]。光谱异质性假说是连接高光谱数据与植被生物多样性之间的桥梁,生物多样性丰富的植被在高光谱数据中往往具有更高的异质性。在国内外的相关研究中,很多种光谱多样性(Spectral Diversity)参数经常被用作估测植被物种多样性:光谱指数或波段反射率变异系数[17—18]、光谱反射率导数[19—20]、包络线去除[21]、光谱凸包体积或面积[22—23]、光谱角制图[24]、光谱信息发散[21]等。先前的研究证明这些光谱多样性参数对物种多样性估测能力受很多因素影响如空间分辨率、时相、物种分布、气候、地形、土壤等,而且并没有找到对物种多样性估测最敏感的光谱多样性参数[21]。
被动光学遥感数据可以用来识别植被类型和水平景观结构,然而植被的水平及垂直结构在生物多样性监测中都是十分重要的[5]。森林垂直结构越复杂,表明森林群落中拥有更多的潜在生境和生态位,意味着可以支持更多的植被种类生存[25]。LiDAR技术可以直接获取地表的三维结构信息,被广泛应用于森林垂直及水平结构参数提取,如树冠高度、单木分割、叶面积指数与郁闭度、冠层垂直剖面、生物量水平及树种分类等[5],这些间接获取的环境参量都可以用于森林物种多样性估测。近年来LiDAR数据提取的森林垂直结构参数开始用于森林乔木物种多样性建模中。根据Bergen等[26]的研究,发现LiDAR提取垂直结构参数对物种丰富度具有较好的指示作用,尤其在森林垂直结构复杂的区域。Wallis等[27]则发现基于机载LiDAR提取的森林垂直结构参数对森林物种组成及分布具有显著影响。一般来说,从LiDAR中提取的与森林物种多样性相关的参数主要包括:微观地形(局部坡度、粗糙度等)、宏观地形(海拔、坡度、坡向等)及冠层结构信息[28]。相对于森林物种多样性遥感估测应用较为广泛的光谱异质性假说,Torresani等[29]提出了高度异质性假说。在他的研究中,Torresani基于LiDAR提取的冠层高度模型(CHM)使用异质性指数Rao′Q 计算高度异质性,并建立高度异质性与森林物种多样性之间的关系。
关于我国南亚热带季风常绿阔叶林物种多样性维持机制的研究还不够充分[30],而且鲜有用遥感技术研究针对南亚热带季风常绿阔叶林物种多样性进行估测研究。然而对南亚热带季风常绿阔叶林物种多样性估测对当地天然林的保护具有重要意义。本文以普洱季风常绿阔叶林为研究对象,使用同步获取的机载高光谱和激光雷达数据,提取适用于研究区森林乔木物种多样性监测的光谱多样性参数和森林垂直结构参数,探讨机载高光谱和激光雷达数据对研究区季风常绿阔叶林森林乔木物种多样性估测能力。
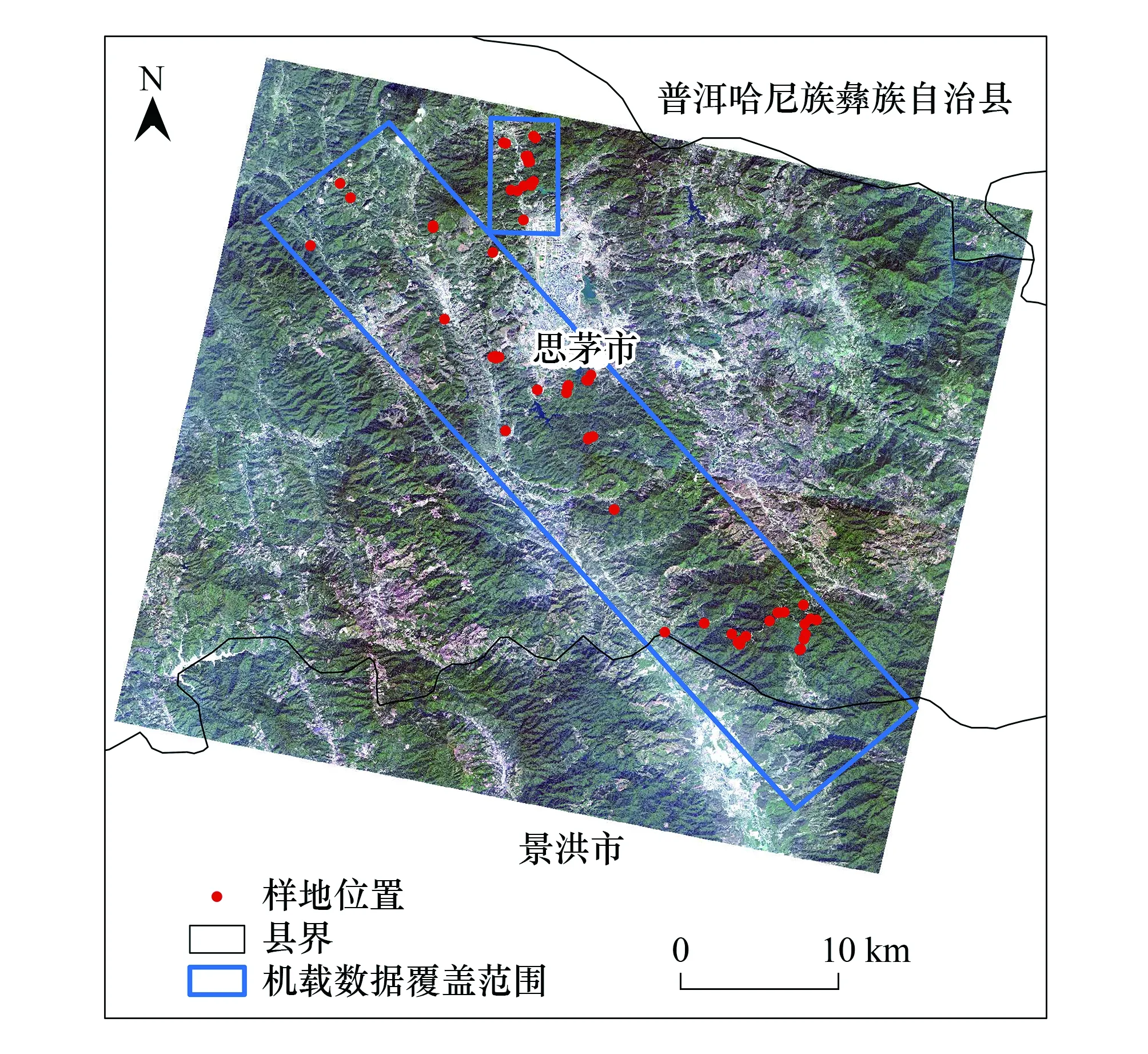
图1 研究区位置及样地分布Fig.1 Study area and plot′s location
1 研究区与数据
1.1 研究区概况
研究区位于云南省普洱市,地理位置为22°27′—23°06′N,100°19′—101°27′,海拔500—2200 m,地形起伏较大,为典型的高山地貌。受亚热带季风气候影响,降水量丰沛但季节分配极不均匀,表现为5—10月降水量占全年降水量的86.9%,年降水量在1200 mm以上。年平均气温为17.7℃。
研究区(如图1机载遥感数据覆盖范围)内植被以季风常绿阔叶林、思茅松林为主,同时还有一部分山地雨林和沟谷季雨林。季风常绿阔叶林作为该区域的地带性植被类型,林冠层主要由壳斗科(Fagaceae)物种如短刺锥(Castanopsisechidnocarpa)、红锥(Castanopsishystrix)及山茶科(Theaceae)物种如西南木荷(Schimawallichii)等组成[31]。受人类活动影响,季风常绿阔叶林常被砍伐作为薪碳、改造成茶园和农地等。近年来随着各项保护措施出台,季风常绿阔叶林不断恢复,形成不同恢复群落如思茅松林、以思茅松为优势木的针阔混交林和阔叶混交林[32—33]。
本研究获取的机载遥感数据覆盖了太阳河省级自然保护区大部分区域,该自然保护区保留着中国面积最大、最完整的季风常绿阔叶林为标志的南亚热带原始森林,具有南亚热带和北缘热带的代表性植被类型和动物种群,是北回归线上不可多得的自然生态景观和生物资源宝库[34]。
1.2 数据获取及处理
1.2.1机载遥感数据
机载遥感数据采集时间为2014年3—4月,飞行平台是运- 12小型运输机,可以低速稳定飞行,相对飞行高度约为1500 m。飞机上搭载的传感器系统为中国林业科学研究院资源信息所集成的LiCHy系统[35],可以同步高效获取LiDAR、CCD、高光谱数据。
其中获取LiDAR数据的传感器为Riegl公司的LMS-Q680i,获取的LiDAR数据为全波形数据。经过波形分解、地理编码等一系列预处理后,获取的激光点云密度为1.5 pts/m2。然后使用TerraSolid、Lastools等软件对分解点云进行预处理,包括去除噪声点、地面点分类和生产数字高程模型(Digital Elevation Model,DEM)、数字表面模型(Digital Surface Model,DSM)、冠层高度模型(Canopy Height Model,CHM)和点云高程归一化处理。获取高光谱数据的传感器为AISA Eagle Ⅱ,获取的高光谱数据经辐射定标、几何校正、BRDF辐射校正等预处理后得到光谱分辨率为9.2 nm,空间分辨率为1 m的高光谱反射率数据[36]。通过对比机载激光雷达数据提取CHM与机载高光谱影像,两种数据的配准精度小于两个像元。
1.2.2群落调查数据
为了获取地面建模和验证数据,于2013年11—12月对研究区季风常绿阔叶林群落进行了野外调查,共获取半径为15m的圆形样地数据58块,分为思茅松林(S1)、针阔混交林(S2)和阔叶混交林(S3)三种类型。样地分布如图1所示。样地每木调查起测胸径为5 cm,调查因子主要包括:样地中心位置、树种以及每木的胸径、树高、冠幅等因子。单木的树高采用激光测高仪进行量测,中心位置的获取使用差分全球定位系统。在本研究中乔木物种多样性计算指标为Shannon-Wiener物种多样性指数,可以对群落物种组成的丰富度及均匀度进行综合评价,是目前应用较为广泛的指标。样地Shannon-Wiener物种多样性指数计算方式如下式所示。
Shannon-Wiener指数:
(1)
其中pi为有S个物种的群落中第i个物种的个体数占所有物种总个体数的比例。
样地Shannon-Wiener物种多样性指数分布如表1所示,多样性指数在1—2.5之间的样地分布最多。所有样地中包含最少树种为3种,最多树种为27种。包含树种较少的样地一般来源于思茅松林,来源于季风常绿阔叶林被采伐后的恢复群落。

表1 样地乔木Shannon-Winner物种多样性指数和物种丰富度汇总
2 研究方法
本研究的总体技术路线如图2所示。根据光谱异质性和环境异质性假说,分别从经过预处理的机载高光谱和LiDAR点云数据中提取光谱多样性特征集和垂直结构特征集。由于获取的遥感特征集较多,采用相关分析、RFE特征选择等方法选择适用于表征研究区森林乔木物种多样性的光谱和垂直结构特征。最后采用随机森林模型(Random Forest,RF)对森林物种多样性进行建模并分析模型表现。
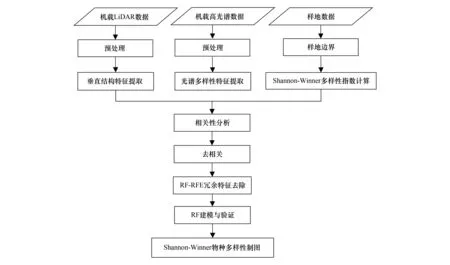
图2 技术流程图Fig.2 Technical flowchart
2.1 光谱多样性特征提取
根据光谱异质性假说,使用机载高光谱数据共提取以下几个方面的光谱多样性特征。
2.1.1光谱反射率的变异系数
在一些研究中,使用指定区域如样地范围内光谱反射率的变异系数来建立光谱异质性与物种多样性指数的关系[37—38]。光谱反射率的变异系数计算方法为:首先计算样地范围内每个波段反射率的变异系数,然后对所有波段取平均值。
2.1.2光谱植被指数
从特定波段计算出的光谱植被指数被广泛应用在探索植被生物化学参数中,为森林树种分类或估测森林物种多样性提供了特征提取方式[39]。使用ENVI软件从高光谱数据中计算所有可以计算的光谱指数,其中包括与宽带绿度(如归一化植被指数、比值植被指数)、窄带绿度(如红边归一化植被指数、改进红边比值植被指数、红边位置指数等)、光利用率(光化学植被指数、结构不敏感色素指数等)、叶色素(类胡萝卜反射率指数、花青素反射率指数)、冠层水分含量(水波段指数、水分胁迫指数等)等相关植被指数。
使用高光谱数据计算的大量光谱指数具有一定的相关性,因此先对这些植被指数进行相关性分析,去除Pearson相关系数的绝对值大于0.9(|R|>0.9)的植被指数。然后每个植被指数计算样地范围内的变异系数。
2.1.3植被冠层光谱反射和吸收特征
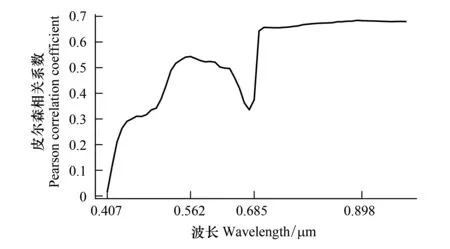
图3 各波段反射率变异系数与Shannon-Winner多样性指数相关关系Fig.3 The Pearson′s correlation between the cv of all band′s reflectance and tree species Shannon-Winner diversity index
一般来说,健康植被光谱反射曲线具有典型的光谱反射和吸收特征。本研究利用高光谱反射率数据和高光谱一阶导数数据,提取绿波段反射峰、红波段叶绿素吸收谷、红边位置、近红外反射峰和波段深度等植被光谱吸收和反射特征。
同时,本研究根据所有63个高光谱波段反射率变异系数与样地Shannon-Winner物种多样性指数之间的相关性(如图3所示),选择两个与样地Shannon-Winner物种多样性指数之间的相关性较高的波段,即中心波长位于0.55μm附近的绿光波段和0.9μm附近的近红外波段组成绿光-近红外组合指数(如公式2所示),增大不同像元之间森林冠层在近红外和绿光波段反射率的差异。
(2)
式中N.G为构建的绿光-近红外组合指数,ρ900和ρ550是中心波长位于900nm和550nm的波段反射率。
2.1.4凸包体积
在植被光谱多样性相关研究中,光谱反射率凸包体积(Convex Hull Volume, CHV)经常被使用[22—23]。凸包体积计算方法如下:首先使用高光谱反射率数据计算样地范围内所有像元的前三主成分,然后计算这些三维散点形成的凸包体积。凸包体积越大,代表样地范围内光谱异质性越高。
2.1.5光谱角制图
光谱角制图通过计算像元光谱与参考光谱之间矢量夹角,根据夹角的大小来确定光谱的相似程度。因此在植被光谱多样性相关研究中,光谱角制图法应用较为广泛。角度越大,代表样地范围具有较高的光谱异质性。本研究通过调用R语言中RStoolbox内sam()函数计算样地范围内所有像元与平均光谱反射率之间的夹角来代表光谱异质性参数。
2.1.6光谱平均距离
光谱异质性也可以通过计算样地范围内所有像元的光谱反射率至样地范围内平均光谱反射率(光谱中心)的距离的均值来代表。Oldeland等发现光谱反射率至光谱中心的平均距离与样地Shannon-Wiener多样性指数具有一定的相关关系,Pearson相关系数达0.62[40]。
2.2 垂直结构特征提取
本研究通过对点云数据的统计提取的点云垂直结构参数来代表森林垂直结构。根据样地调查尺度,本研究的统计单元为30 m×30 m。统计中包括点云高度统计(高度统计值和高度分位数)和点云百分比统计(指定高度点云所占比例,植被点高度阈值设置为0.5 m)。通过在研究区不同位置截取LiDAR点云垂直剖面发现,研究区常绿阔叶林可大致分为灌木层(H<5 m)、下层木(5 m
2.3 随机森林模型
随机森林(Random Forest,RF)模型是一种基于分类树的算法,通过对大量分类树汇总来提高模型预测精度。模型首先由Breiman提出,广泛应用于分类和回归任务[41]。随机森林模型“随机”且有放回地从样本中抽取训练样本,没有被抽到的数据集组成袋外数据(out-of-bag, OOB),可用作预测模型正确率或特征的重要性。随机森林模型同时“随机”选取分裂特征集,从选取特征中选择最具区分能力的某个特征使节点分裂。因此随机森林模型不易陷入过拟合,而且通过特征对节点纯度的影响,也可以对变量重要度进行排序。除此之外,随机森林模型还具有较强的处理高维特征能力、参数调整较少、建树过程中内部使用无偏估计、可以很好处理缺失值等优点,在生态遥感应用广泛。随机森林模型通常只需要设置3个参数:终节点规模(nodesize),每个分离点选择的变量数(mtry)及树分类器的个数(ntree)[42]。为了选择最优参数,本文使用网格寻优方法选择最佳随机森林模型参数。

表2 基于机载LiDAR数据森林垂直结构参数统计表
2.4 特征选择
由于提取的特征值之间相关性较高,为了减少进入模型的特征数量,本研究首先根据特征值之间的Pearson相关系数,经过反复对比分析,去除相关性|R|>0.9的特征值。然后利用样地实测Shannon-Wiener物种多样性指数与挑选出的特征值开展相关分析,经过对比分析之后去除相关性|R|<0.2的特征值。这些被去除的特征参数对模型精度没有显著影响。
由于本研究中遥感特征值较多,而样本个数较少,因此执行随机森林建模之前,使用基于随机森林算法的递归特征消除方法(Random Forest Recursive Feature Elimination, RF-RFE)去除对模型精度没有显著贡献的变量[15]。RF-RFE方法的基本步骤为:根据随机森林模型给出的变量重要性,参考多次10折交叉验证的模型精度,从最重要变量到最不重要变量迭代考察每个加入变量对模型精度的影响。对于没有显著提高模型精度的变量最终得以剔除。
2.5 季风常绿阔叶林乔木物种多样性指数建模与制图
使用随机森林算法,以实测Shannon-Winner物种多样性指数为因变量,以RF-RFE方法选择出的机载高光谱和LiDAR特征集为自变量建立估测模型,并以R2与RMSE作为模型评价指标。最后利用建立的随机森林模型估测研究区季风常绿阔叶林乔木物种Shannon-Winner多样性指数的分布。结合NDVI和CHM,区分研究区非植被区域、低矮植被区域和森林区域。本研究仅对研究区森林区域Shannon-Winner物种多样性指数进行预测、制图。
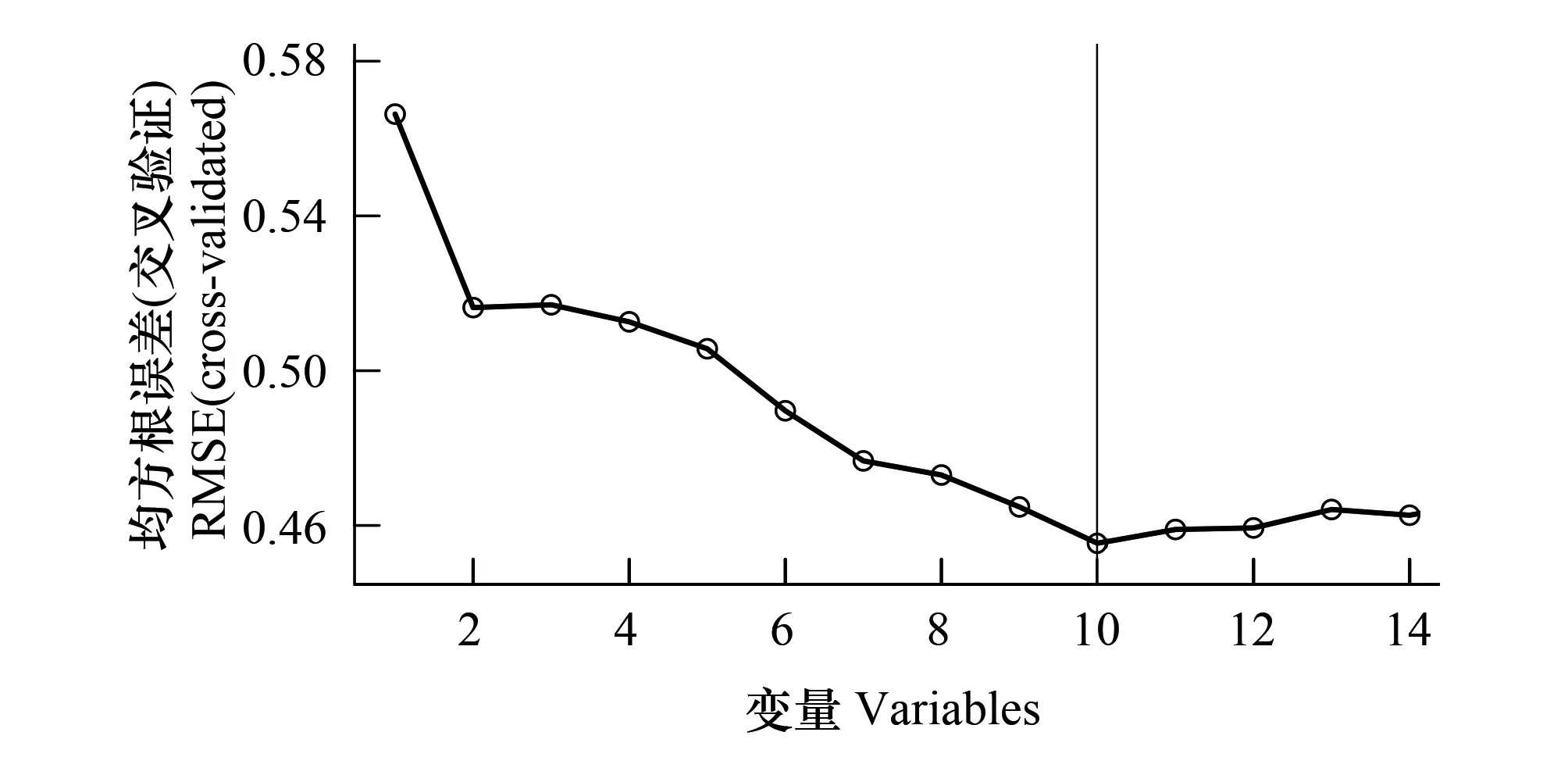
图4 基于随机森林算法的光谱多样性RFE冗余特征去除Fig.4 RF-RFE feature selection from spectral diversity features
3 结果与分析
3.1 特征选择
3.1.1光谱多样性特征选择
图4展示了使用光谱多样性特征的RFE冗余变量去除结果。通过对高光谱数据光谱多样性特征提取、筛选,共获取18个光谱多样性特征进入RF-RFE特征选择。这些特征与Shannon-Winner多样性指数相关性|R|均大于0.25并具有显著性差异,特征之间相关性|R|不大于0.9。根据随机森林给出的变量重要度排序,随着变量个数增加,随机森林模型十折交叉验证中RMSE先大幅下降后再小幅下降并保持低值。因此,对随机森林估测模型没有显著贡献或者降低模型精度的变量被去除,共10个光谱多样性特征被选择(如表3所示)。这些特征与Shannon-Winner多样性指数、特征之间的相关性、显著性如图5所示。其中,SW表示样地实测Shannon-Wiener物种多样性指数。
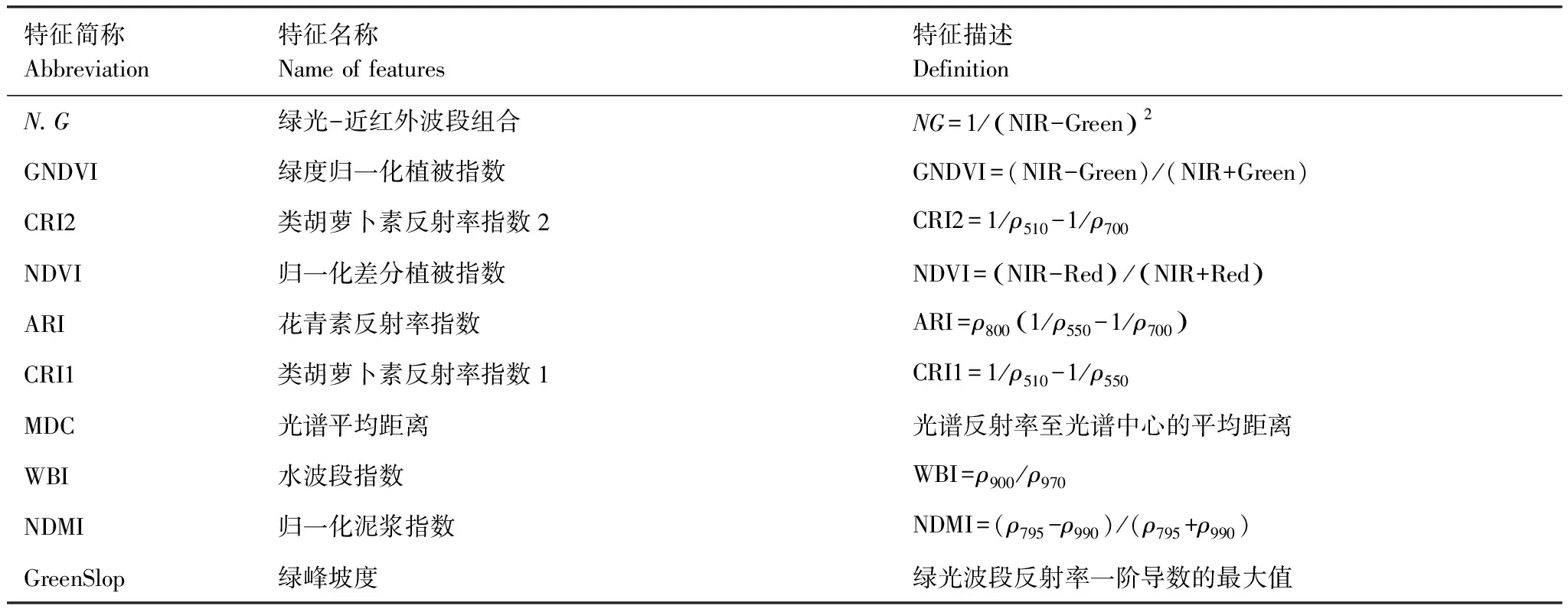
表3 RF-RFE选择的光谱多样性特征
在没有进入RF-RFE特征选择中的光谱多样性特征中,“红边位置指数”(皮尔逊相关系数R=0.52),“近红外反射率变异系数”(R=0.5),“改进非线性指数”(R=0.48),“光谱反射率平均变异系数”(R=0.43),“单一比值指数”(R=0.41),“转换叶绿素吸收反射比指数” (R=0.37),“平均光谱角”(R=0.34)等光谱多样性特征与样地实测Shannon-Winner多样性指数均具有较好的线性相关关系。但是在特征选择中,这些特征对模型精度没有显著贡献。相反,被RF-RFE特征选择出的“归一化植被指数”、“水波段指数”和“归一化泥浆指数”与样地实测Shannon-Winner多样性指数均具有相对较差的线性相关关系。结果表明使用高光谱数据提取的光谱多样性特征参数对研究区内森林乔木Shannon-Winner多样性进行建模时,线性回归模型并不适合。同时说明在进行乔木物种多样性建模之间,对拟参与建模特征进行选择的必要性。
3.1.2垂直结构特征选择
图6展示了使用LiDAR数据提取的垂直结构特征的RF-RFE冗余变量去除结果。通过对LiDAR垂直结构特征提取、筛选,共获取18个垂直结构特征进入RF-RFE特征选择。这些特征与Shannon-Winner多样性指数相关性|R|均大于0.2并具有显著性差异,特征之间相关性|R|小于0.8。根据图7中随机森林模型交叉验证RMSE变化情况,去除对随机森林估测模型没有显著贡献或者降低模型精度的变量。共4个垂直结构特征被选择(如表4所示),包括2个5—10 m间点云高度分布特征和2个与植被覆盖度有关的特征。这些特征与Shannon-Winner多样性指数、特征之间的相关性、显著性如图7所示。
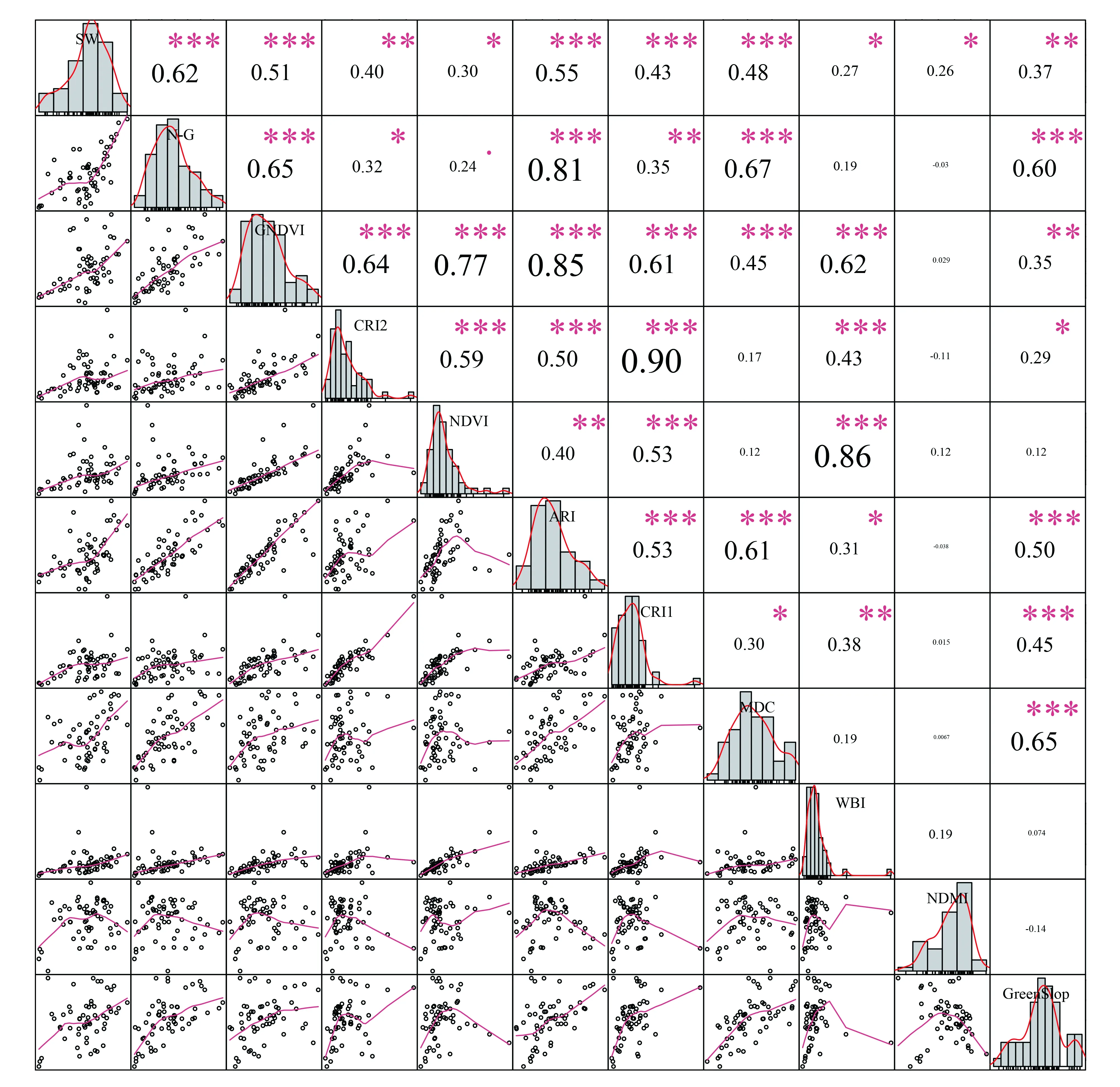
图5 RF-RFE选择光谱多样性特征与Shannon-Winner指数之间相关关系Fig.5 Correlation between RF-RFE selected spectral diversity features and Shannon-Winner species diversity index图中对角线为样本分布柱状图;左下角为散点图;右上角数字为样本特征之间Pearson相关性,显著性代码为:0‘***’,0.001‘**’,0.01‘*’,0.05‘.’,0.1‘ ’

表4 RF-RFE选择的垂直结构特征

图6 基于随机森林算法的垂直结构特征RFE冗余特征去除Fig.6 RF-RFE feature selection from vertical structure features
除了“5—10m间点云高度分布峰度值”和“5—10m间点云高度分布中值”以外,在没有进入RF-RFE特征选择中的垂直结构特征中,如“5—10 m点云高度分布标准差”(R= 0.48)、“10—20 m点云高度分布变异系数”(R= 0.42)、“0.5—5 m点云高度分布变异系数”(R= -0.42)、“0.5—5 m点云高度分布偏度”(R= -0.44)与样地实测Shannon-Winner多样性指数之间具有较好的线性相关关系。点云高度分布的标准差、变异系数及峰度、偏度等统计特征表明了点云在垂直方向上分布的异质性,与点云覆盖度相关特征相比对森林乔木Shannon-Winner物种多样性指数更具有指示作用。虽然选择出的点云覆盖度相关特征与森林乔木Shannon-Winner物种多样性具有较小的线性相关关系,但是其对提高模型精度具有较大贡献。因此根据LiDAR提取垂直结构特征的RF-RFE特征选择结果,选择4个垂直结构特征进行森林乔木Shannon-Winner物种多样性建模。
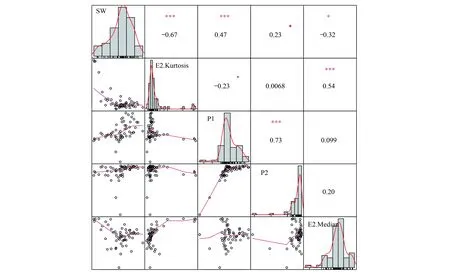
图7 RF-RFE选择垂直结构特征与Shannon-Winner指数之间相关关系Fig.7 Correlation between RF-RFE selected vertical structure features and Shannon-Winner species diversity index图中对角线为样本分布柱状图;左下角为散点图;右上角数字为样本特征之间Pearson相关性,显著性代码为:0‘***’,0.001‘**’,0.01‘*’,0.05‘.’,0.1‘ ’
3.1.3光谱+垂直结构特征选择
根据选择出的10个光谱多样性特征和4个垂直结构特征,执行RF-RFE特征选择。图8展示了使用光谱+垂直结构特征的RF-RFE冗余变量去除结果。虽然单独使用光谱或者垂直结构特征进行建模时,RF-RFE特征选择方法选择了对模型精度具有最大贡献的少量特征。当把两种选择出的特征组合在一起时,仍有一些特征对提高模型精度没有显著贡献。因此本研究最终选择出7个光谱+垂直结构特征参与最终的Shannon-Winner物种多样性指数建模与预测。这7个特征包括E2.Kurtosis、P1、P2、E2.Median垂直结构特征和GNDVI、N.G、ARI光谱多样性特征。
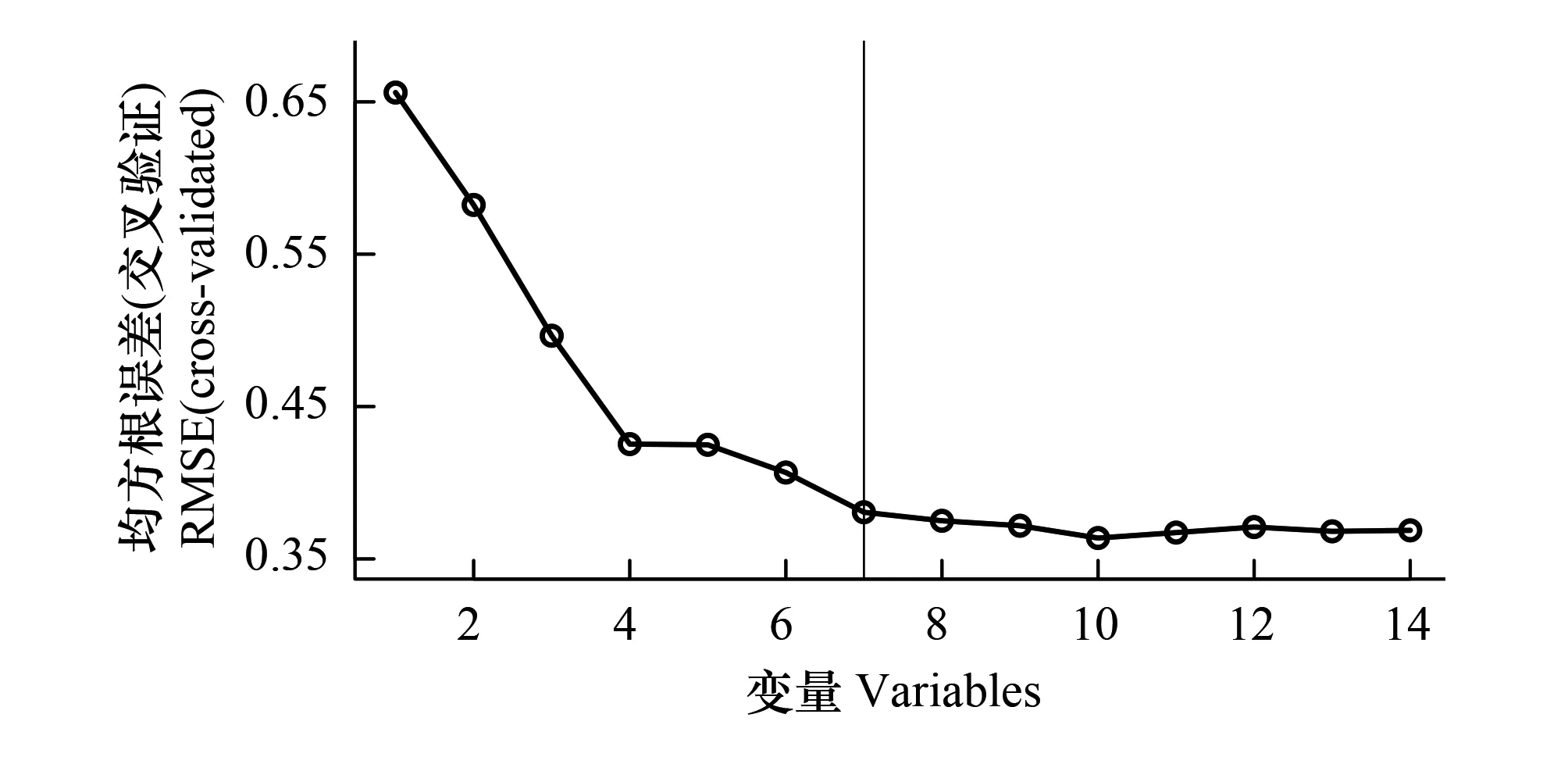
图8 LiDAR&高光谱数据RF-RFE特征选择结果 Fig.8 RF-RFE feature selection from airborne hyperspectral and LiDAR features
3.2 物种多样性指数建模及结果预测
3.2.1特征重要度排序
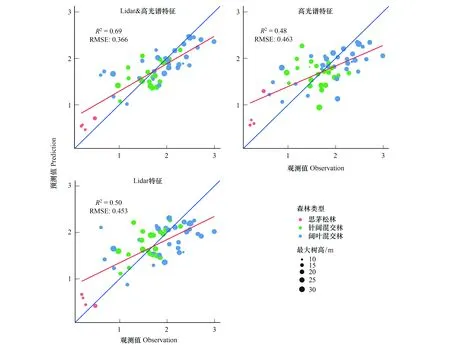
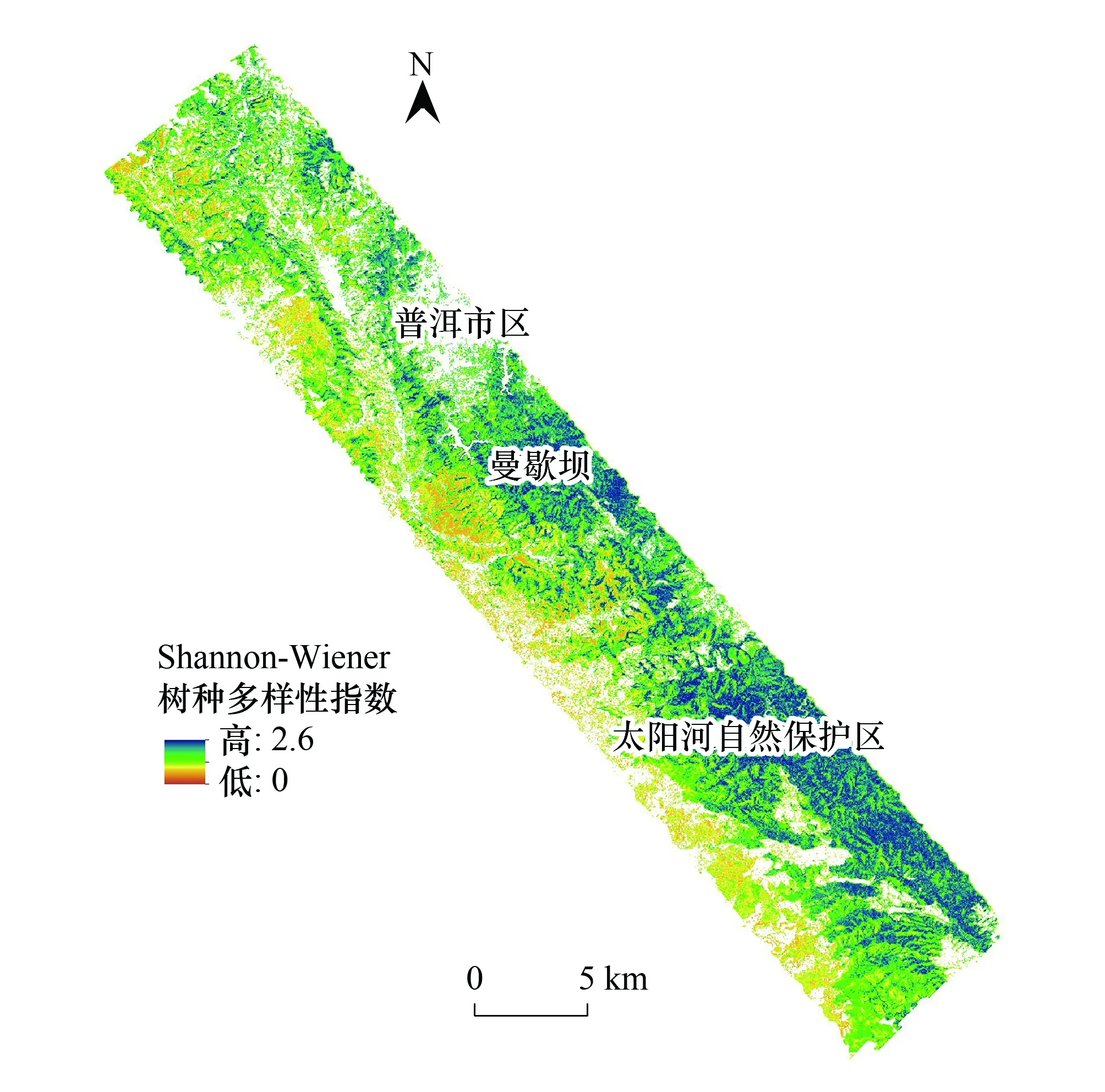
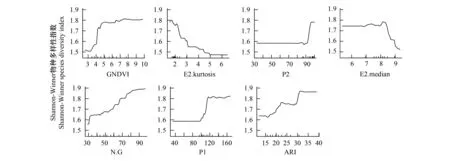
在Shannon-Winner物种多样性指数建模过程中,分别从高光谱、LiDAR数据提取特征中选择10个和4个特征。得到随机森林模型后,使用袋外交叉验证中各特征对模型精度均方误差(Mean Squared Error,MSE)增加的大小(%IncMSE)评价特征重要度。这些特征在模型中的重要度排序如图9所示。在基于高光谱数据光谱多样性特征的随机森林模型建模中,近红外-绿光波段组合指数(N.G)、绿度归一化植被指数(GNDVI)、光谱平均距离(MDC)和花青素反射率指数(ARI)对模型建模精度的影响较大。在基于LiDAR数据垂直结构特征的随机森林建模中,与冠层覆盖度相关的特征相比,下层木(5 m 图9 随机森林模型变量重要度排序Fig.9 The variable importance of random forest model 3.2.2物种多样性指数建模结果 图10展示了使用随机森林模型和高光谱、LiDAR数据以及高光谱+LiDAR数据提取特征对Shannon-Winner物种多样性指数建模结果散点图。图10中蓝色直线为1∶1线,红色直线为线性回归线,样地最大树高以散点大小标记,样地森林类型以散点颜色区分(S1为思茅松林,S2为针阔混交林,S3为阔叶混交林)。 图10 基于高光谱和LiDAR数据的Shannon-Winner物种多样性随机森林模型预测结果Fig.10 The scatter plots between prediction and observation for Shannon-Winner species diversity index 从图10来看,使用随机森林模型对样地Shannon-Winner物种多样性指数的估测结果均出现对高物种多样性样本的低估情况。使用LiDAR数据提取的垂直结构特征对Shannon-Winner物种多样性指数的建模精度(R2为0.5,RMSE为0.45)略高于使用高光谱数据提取的光谱多样性特征的建模精度(R2为0.48,RMSE为0.46)。然而,结合LiDAR数据提取的垂直结构特征和高光谱数据提取的光谱多样性特征,使用随机森林模型对Shannon-Winner物种多样性指数的建模精度大大提高(R2为0.69,RMSE为0.37),估测结果更加收敛。结果表明结合森林垂直结构信息和水平光谱分布信息对研究区森林Shannon-Winner物种多样性具有更好的估测作用。 从图10中可以看出,使用高光谱数据提取的光谱多样性特征对针阔混交林的估测结果较差。可能的原因是针阔混交林内上层木一般被高大的阳性树种思茅松覆盖,使用高光谱数据很难获取中下层木的光谱异质性特征。而阔叶混交林上层覆盖物种更加多样,与样地中整体物种多样性分布更加相关,因此使用高光谱数据获取的光谱多样性特征对研究区阔叶混交林的估测精度比针阔混交林更高。由于不同的树种分布往往表现出不同的森林垂直结构,因此使用LiDAR数据提取的垂直结构特征对研究区针阔混交林和阔叶混交林均具有一定的代表性。与高光谱数据相比,使用LiDAR提取的垂直结构指数对阔叶混交林、针阔混交林Shannon-Winner物种多样性指数的估测结果没有显著差异。因此结合两种数据有助于提高对研究区森林Shannon-Winner物种多样性指数的反演精度。 3.2.3研究区物种多样性制图 太阳河自然保护区分布着大片、连续的原始季风常绿阔叶林,具有丰富的生物多样性。从图11中可以看出,太阳河自然保护区和曼歇坝地区具有较高的物种多样性。在曼歇坝的西部,分布着大片思茅松人工林,物种丰富度较低。飞行范围西部为昆磨高速及其缓冲范围,受人类活动影响该区域森林分布较少且破碎、物种多样性较低。研究区Shannon-Winner多样性指数预测图在较大尺度展示普洱季风常绿阔叶林乔木物种多样性的分布,对研究区生物多样性保护和森林管理策略制定具有重要意义。 图11 研究区季风常绿阔叶林乔木物种Shannon-Winner多样性指数预测图Fig.11 The prediction of Shannon-Winner species diversity in study area 本研究使用机载激光雷达和高光谱数据提取的垂直结构特征和光谱多样性特征估测了普洱季风常绿阔叶林森林乔木物种多样性,取得了较好的结果。根据特征重要度排序,对叶绿素更加敏感的绿度归一化植被指数对模型的贡献度最大。除此之外,LiDAR数据提取的4个垂直结构特征均具有较高的重要度。以针阔混交林为例,其上层木大多为高大思茅松。从图8可以看出,由于高光谱数据只能获取冠层上层光谱特征,光谱多样性特征对针阔混交林乔木物种多样性的解释能力较差。而LiDAR获取的垂直结构特征从垂直结构上更好的解释了针阔混交林的物种多样性分布。单独使用光谱多样性特征或垂直结构特征对研究区森林乔木物种多样性的分布均具有一定的解释作用,然而结合两种数据源则大大提高了遥感数据对研究区森林乔木物种多样性的反演能力。 森林的生物多样性形成机制及影响因素极其复杂,其空间分布是各种生态、环境、气候等因子梯度变化的综合反映。在区域乃至全球尺度上,气候因子是森林群落生物多样性空间分布的主导因素[43]。地形因子在景观或更小尺度往往导致生境的差异,进而对森林生物多样性的分布具有一定的影响作用。在本研究中,由于实验区尺度较小、样本分布对不同地形的代表性较差等原因,地形因子对样本森林乔木物种多样性分布具有较差的解释能力。根据生产力假说、环境异质性假说和光谱异质性假说,从遥感数据获取的代表生产力水平的植被指数、代表光谱异质性的光谱多样性特征和代表环境异质性的垂直结构特征或植被类型等遥感获取参数在反演森林乔木物种多样性中应用广泛。但是在这些研究中[10—29],对于不同的研究区并没有发现统一的遥感特征参数对森林乔木物种多样性指数具有较好的解释能力。因此使用多源遥感数据构造尽可能多的特征参数,选择合适特征参数反演研究区森林乔木物种多样性十分重要。 通过分析提取的遥感特征参数与样地实测森林乔木物种多样性指数之间的相关关系及对进入模型的特征重要度,发现一些与样本相关性较低的特征参数在模型中的贡献较高,而一些与样本相关性较低的特征参数没有被选择进入模型中。通过随机森林模型变量部分依赖图(如图12)可以看出,遥感特征参数对模型拟合值的影响并不是线性的。因此选择非线性模型建立森林乔木物种多样性遥感估测模型十分重要。本研究使用了在乔木物种多样性遥感建模中应用较为广泛的随机森林模型进行特征筛选和模型建立。模型对研究区森林乔木Shannon-Winner多样性指数的估测结果R2为0.69,RMSE为0.37,对研究区森林乔木Shannon-Winner多样性指数具有一定的解释作用,其预测结果可以为森林经营管理和保护策略提供参考。森林乔木物种多样性形成机制极其复杂,受众多因素影响,遥感数据仅能解释一部分变异。而且由于研究区森林乔木物种多样性分布差异、遥感特征提取差异以及估测模型差异等因素,不同研究对物种多样性估测结果差异较大。 图12 随机森林模型变量部分依赖图Fig.12 Partial dependence plots for the seven most influential variables retained by the random forest model 在生物多样性遥感估测研究中,地面调查样地的尺度面临的问题比遥感数据更加复杂与重要。根据物种-面积曲线,当面积越大时,物种的数量也倾向于越多。代表群落的最小取样面积往往从物种-面积曲线中而来。从李帅峰的研究中可以看出,普洱季风常绿阔叶林乔木物种丰富度增加速度随着取样面积的增加至大约700 m2放缓[33]。当取样面积增加至900 m2,面积解释了94%的总物种数量变化。因此本研究设置的半径为15 m(706 m2)的圆形样地在研究区乔木物种多样性调查中具有一定的代表性。 遥感数据源及特征提取方式对面向生物多样性遥感估测应用极其重要。随着主被动遥感结合、高分辨率、多时相遥感数据海量增加,结合机器学习方法,以地面调查数据为支撑,可以快速挖掘对森林局部物种多样性解释能力高的遥感特征,为大尺度森林生物多样性制图提供基础。 本文基于随机森林模型评估了机载高光谱数据提取的光谱多样性特征和激光雷达数据提取的垂直结构特征对普洱季风常绿阔叶林乔木物种多样性分布的解释能力。主要结论如下: (1)本文提取的光谱多样性特征和垂直结构特征均对研究区季风常绿阔叶林乔木物种多样性指数具有较好的解释能力。结合两种数据源,大大提高遥感数据对研究区森林乔木物种多样性的估测能力。 (2)机器学习方法如随机森林方法有助于从海量遥感数据源中选择适合当前试验区的主要特征,并在线性不可分的情况下充分探索样本中各特征值的分布,提高多源遥感数据源对森林乔木物种多样性分布的解释能力。 (3)对于本研究区而言,与高光谱数据相比,激光雷达数据提取的垂直结构特征对研究区内针阔混交天然林的森林乔木物种多样性的分布更有预测优势。 (4)对季风常绿阔叶林乔木物种多样性的估测有助于研究区生物多样性保护和森林管理策略制定,为监测研究区被破坏原始森林不同恢复时期森林发展状况提供借鉴。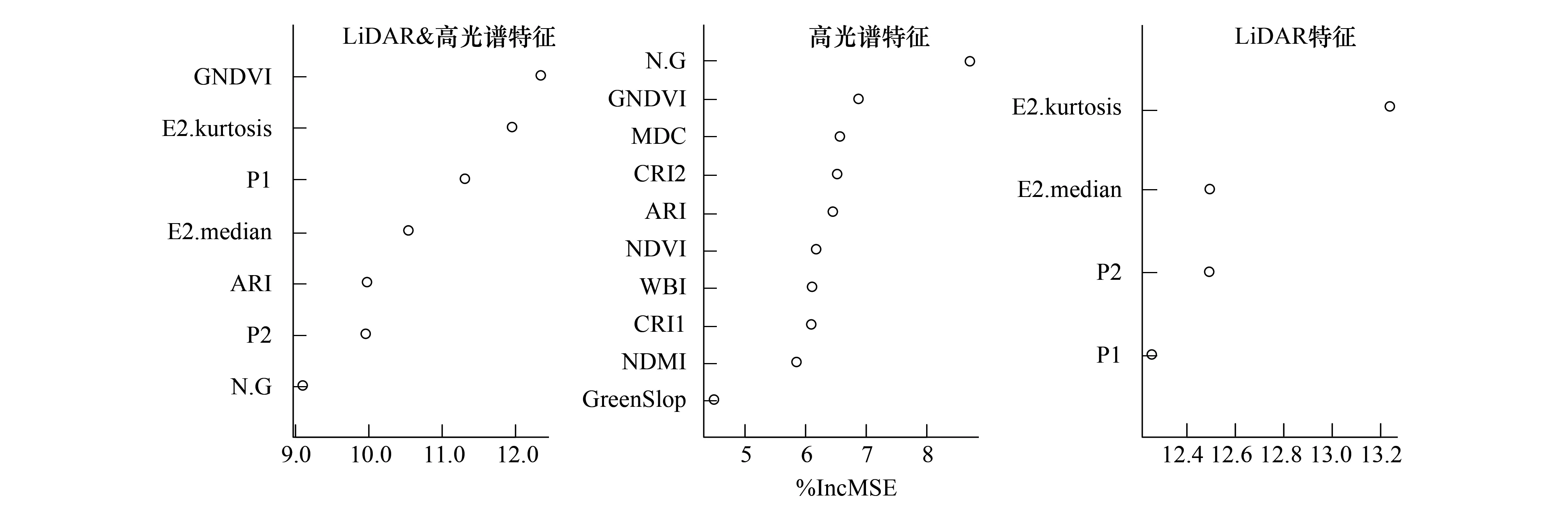
4 讨论
5 结论
