基于机器学习组合模型的用户消费行为预测
2022-11-10张丽娜李静静
张 峰,张丽娜,李静静
(河北工程大学,河北 邯郸 056038)
0 引言
在企业的日常运营中,无论是线上还是线下都产生了大量的用户消费行为数据。这些数据为企业带来了新的发展机遇但也使企业面临巨大的挑战,如何判别高质量的用户和渠道、优化营销成本成为各领域企业的痛点。对企业而言,传统的营销渠道已经无法有效地满足用户的个性化和多样化需求,互联网和数据挖掘技术的发展,为公司拓宽了获客渠道。因此,以用户消费行为分析为核心,依托互联网技术和数据挖掘技术的精准营销日渐成为各大企业关注的焦点。2020年,根据中研普华产业研究院调研数据显示,有超过60%的企业将大数据应用于营销分析[1],用户行为数据对企业的帮助作用日益突出,各企业也逐渐开始重视将大数据加入营销的各个环节。因此,如何充分挖掘和分析用户消费行为数据,并依据分析结果制定营销策略,已成为各行业企业亟需解决的重要问题。
为提高对用户消费行为的精准预测,针对用户消费行为预测方法,国内外学者做了一些研究。Schmittlein等[2]针对用户消费行为预测问题提出了经典的概率预测模型,即Pareto/NBD模型。李美其和齐佳音[3]基于大众点评网站的用户数据,使用Pareto/NBD模型对用户购买行为进行预测,实验表明该方法的精度得到了提升。随着机器学习方法的发展,不少学者开始将机器学习方法应用到用户消费行为预测问题上。白婷等[4]利用网站上的用户消费行为数据,提取有效特征,使用加权GBDT(Gradient Boosting Decision Tree)模型对用户购买商品进行了预测。葛绍林等[5]提出深度森林模型,对用户消费行为进行预测分析,结果表明该方法具有较好的预测效果。
因为用户消费行为预测问题的复杂性,单一模型常常会产生过拟合现象,因此也有不少学者利用组合模型对用户消费行为数据进行挖掘和预测分析。张韶[6]基于京东大数据平台上的真实数据,经过数据处理和特征选择,然后选取了LightGBM、Cat-Boost和XGBoost模型进行单项训练,通过加权投票和Stacking融合策略构建组合模型,并进行对比实验,结果表明基于加权投票的组合模型的预测效果要优于其余单项模型。张建彬和霍佳震[7]基于已有的销售数据,提出了一种基于机器学习和Stacking集成的综合预测模型,结果表明该融合模型的预测效果优于单一模型,准确率达85%。
综上所述,对用户消费行为预测问题的研究仍处于不断发展阶段,国内外学者从最初的统计学方法发展到现在的机器学习方法,通过模型构建方式对用户消费行为预测进行了深入研究。然而,在具体的实际问题中,当前方法的预测性能还不是十分理想。因此,本文将针对某平台上的用户消费行为数据,分析用户消费行为与商品之间的潜在关系,结合处理效率较高的随机森林和Logistic模型,提出一种基于组合模型的用户消费行为预测方法,以提升用户的购买转换率,增强预测模型对实际问题的适用性。
1 数据来源及清洗
1.1 数据来源
数据来源于2021年全国大学生数据统计与分析竞赛(https://m.saikr.com/dsa/2021),原始数据集包括用户信息表(user_info)、用户登录情况表(login_day)、用户访问统计表(visit_info)、用户下单表(result)4部分,各部分的特征字段和样本情况,如表1所示。

表1 用户消费行为数据情况Table 1 Data of user consumption behavior
1.2 数据清洗
由于原始数据中存在大量缺失、异常以及重复等情况,为了对用户的消费行为进行可视化和预测分析,本文需要对初始数据进行清洗,进一步提高数据集的质量。
首先,对缺失值进行删除。缺失数据是指数据集中存在空白或未知数据的情况。针对用户信息表中“城市”字段存在缺失(共计28209条)问题,进行删除处理。
其次,对异常值进行清除。异常值是指在数据记录中存在不符合实际情况的数据,比如在用户登录情况表和用户访问统计表中,用户没有领券访问次数的记录却存在已经领券的情况、平台开课数为0但用户学习课节数和完成课节数不为0的情况、用户登录时长为0但用户的登录天数和最后登录距期末天数的值却不为0等多种不切实际的情况,约占整体数据的18.66%。将这些异常值进行删除,剩余有效数据共计110306条。
再次,对重复值进行处理。重复数据是指同一数据多次出现的情况,比如在用户下单表中,用户ID为“2000002390697240”、“2000002516432100”和“2000002480841520”等均重复出现多次,在用户信 息 表 中 用 户ID为“2000002352923140”、“200000235 2922980”的用户均重复出现多次。因此,本文对用户信息表中的9979条重复值、用户登录情况表与用户访问统计表中的4条重复值、用户下单表中的13条重复值进行删除。
通过上述步骤对4个部分的数据进行清洗处理后,以用户ID进行匹配合并,得到新的样本数据共计86776条。
2 数据的可视化分析
为找出其中的行为规律以及挖掘数据中更为丰富的潜在价值,本文根据数据清洗得到的用户消费行为数据进行可视化分析。这里主要对数据集中的用户城市分布情况、用户登录情况(包括登录天数、登录间隔、最后登录距期末天数和登录时长)两个方面进行可视化分析。
2.1 用户城市分布情况
对数据中的城市字段(city_num),首先按照各城市所属的省(市、自治区)进行统计划分,然后统计各省市中总用户数量和购买用户数量,最后借助ArcGIS软件,利用自然间断法将用户数量分成5个等级(city_rank),可视化结果如图1所示。
在图1中,左图为总用户数量地区分布情况,右图为购买用户数量地区分布情况。由于不同地区的用户数量不同,在图中呈现出的颜色存在较大差异,颜色越深表示该省市用户数量越大,反之用户数量越小。从图中可以看出,总用户数量和购买用户数量在空间分布上不均匀,呈现“东高西低、南高北低”的空间分布格局,其中购买用户数量在空间分布上的这种格局表现尤为显著。总用户数量较高的地区主要集中在重庆、广东、四川、山西、山东;对应的下单购买用户数量较高的地区主要集中在东部沿海地区和经济发达地区。而青海、西藏等省市由于人口基数小、互联网普及率相对较低等原因,用户数量较少。

图1 总用户和购买用户所在地区空间分布图Figure 1 Spatial distribution of users and purchasing users
2.2 用户登录情况
从登录天数 (login_time)、登录间隔(login_diff_time)、最后登录距期末天数(distance_day)和登录时长(login_time)四个方面对用户的登录情况进行分析,由于字段中的数据均为离散型数据,因此先对数据进行分段处理,统计该区间内用户数量并绘制图表,如图2、图3、图4及图5所示,其中折线表示总用户数量,条形图表示购买的用户数量。

图2 用户登录天数(login_day)情况Figure 2 Number of login days

图3 用户登录间隔(login_diff_time)情况Figure 3 User login interval(login_diff_time)
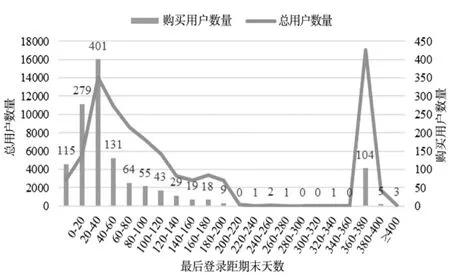
图4 用户最后登录距期末天数(distance_day)情况Figure 4 The number of days between the user's last login and the end of the term(distance_day)
如图2所示,横轴表示用户登录的天数,纵轴表示总用户数量和购买用户数量。可以看出,随着用户登录天数的增加,总用户数量和购买用户数量变化趋势基本相同,都呈现出先上升后下降的趋势,但是购买用户数量的下降趋势与上升趋势相比较为平缓,总用户数量的上升趋势与下降趋势相对较为平缓。当登录天数为5时,总用户数量和购买用户数量同时达到峰值,此时总用户数量为13307,约占总体的15.33%,其中购买用户数量为268。
如图3所示,横轴表示用户登录间隔,纵轴表示总用户数量和购买用户数量。可以看出,无论是购买用户还是未购买用户,其登录时间间隔都较为集中,主要分布在0.5~1和1~1.5两个时间间隔内。在该间隔内的购买用户总数达946人,占总体比例的73.9%;用户数达63608人,占总用户数量的73.3%。这说明选择购买的用户一般登录的时间间隔都比较短,会及时地进行登录并产生消费行为。时间间隔为0.5~1的总用户数量少于时间间隔为1~1.5的用户数量,但是时间间隔为0.5~1的购买用户数量却多于时间间隔为1~1.5的购买用户。同时,当登录间隔超过1.5时,随着登录间隔的增加,总用户数量和购买用户数量逐渐趋近于0。
如图4所示,横轴表示用户最后登录距期末的天数,纵轴表示总用户数量和购买用户数量。可以看出,总用户数量和购买用户数量都随着最后登录距期末天数的增加呈现先增加后减小的走势,但是在最后登录距期末天数为360~380范围内的总用户数量和下单购买的用户数量陡然上升,且总用户数量达到最高。这说明存在大量的用户在近一年的时间内都未曾消费该企业的产品,其中包含104个下单购买过的用户,表明该企业存在用户大量流失的情况。其次,购买过的用户和其他用户一般最后登录距期末天数集中于0~60这个范围内;其中处于20~40范围内的人数最多,占购买用户数的比例为31.33%,占总用户数的比例为16.15%,说明一般用户的登录周期可能在20~40之间。
如图5所示,横轴表示用户登录时长,纵轴表示总用户数量和购买用户数量。可以看出,随着登录时间越长,总用户数量和购买用户数量越来越少,并逐渐趋近于0。在登录时长为0~10的范围内,登录的总用户数量最多,此时购买的用户也高达302人,占总购买用户的23.57%,说明用户在登录前已经具有明确的消费目标。随着登录时长的增加,购买的人数逐渐减少,原因是用户不存在明确的消费目标,只是随机浏览并进行一些非理性的消费。
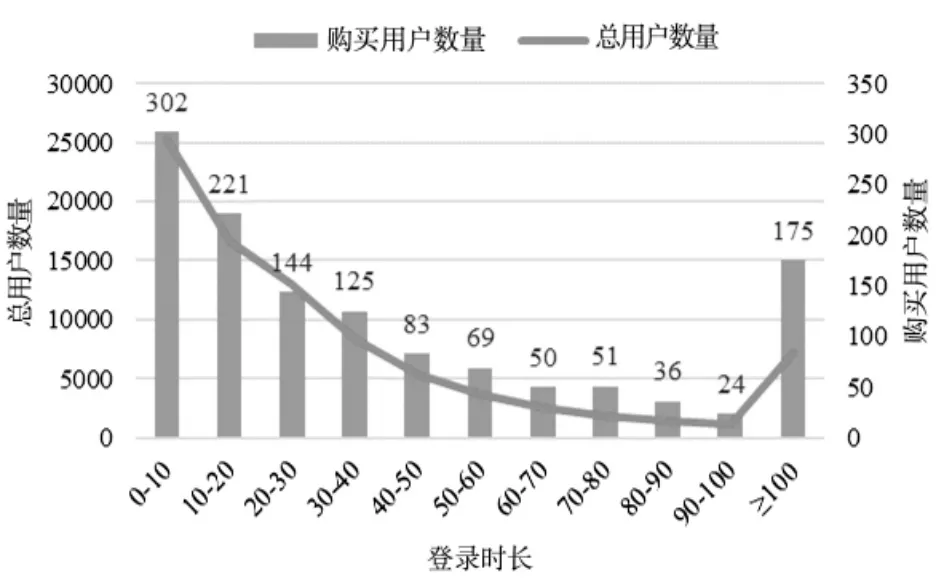
图5 用户登录时长(login_time)情况Figure 5 User login duration(login_time)
3 数据的特征选择
通过对数据的清洗,共收集有效数据86776条,包含49个字段。特征个数过多,会增加模型的训练时间成本、模型的复杂度,易发生过拟合问题,因此需要进行特征选择。特征选择的目的在于根据统计学方法或机器学习模型的特征需要找到最优的特征子集。为构建更准确的用户消费行为预测模型,本文将分两个步骤对数据集进行特征选择,即剔除无关变量与Lasso特征选择。
首先对数据集中的无关变量字段进行剔除,包括user_id、app_num、model_num、platform_num、age_month、first_order_time和first_order_price等,从而降低数据量,提高运算速度。处理后数据集的具体变量描述如表2所示。

表2 用户消费行为数据变量及其描述Table 2 Data variables of user consumption behavior and their description
其次,进行Lasso特征选择。用户消费行为指标应具有较强的解释意义,并且要符合一定逻辑。然而该数据集中的指标变量包含着大量的冗余信息,这将直接影响用户消费行为预测模型的性能,甚至会出现较大的偏差。因此,还需对上述指标变量进行二次选择,选择出更具重要性的指标。此外,考虑到变量间多重共线性对模型的影响,尤其是对Logistic模型的解释性会产生极大影响,所以选用Lasso方法进行变量选择,以有效克服上述问题[8]。
经过上述两个步骤,最终选择出20个有效变量x1,x2,x3,x10,x12,x13,x15,x16,x18,x19,x20,x24,x26,x27,x28,x29,x36,x39,x40,x41。最后重新组成新的样本数据,有效数据样本总计84104条,其中下单购买的用户样本有1209个,未购买的用户样本有82895个。
4 基于随机森林和Logistic回归的用户消费行为预测
用户消费行为预测是一个典型的机器学习分类任务。因此,选取了处理效率较高的随机森林(Random Forest,RF)和Logistic回归对用户消费行为数据进行学习。
4.1 随机森林
随机森林[9]是一种集成多棵决策树的集成学习算法,可用于解决分类及回归问题。随机森林的“随机”体现在两个方面:
(1)随机抽取样本。针对分类问题,RF的训练集通过有放回的自助法随机产生,每一轮训练所使用的训练集均以同样方式生成,以保证所有样本都有机会参与训练。
(2)随机属性选择。首先从该节点的全部属性集合中随机抽取若干个属性组成子集;其次从属性子集中找到最优分裂属性进而划分。每一棵决策树在其生成中都会随机生成不一样的分裂属性子集,随机属性选择增强了树之间的独立性,也增加了算法的随机性。
经过模型内部处理,在每个训练集上构建一种决策树,N棵树就会有N种分类结果,根据投票原则,将投票最多的类别指定为模型的最终输出。而正因为随机森林的“随机”,使模型不易过拟合。此外,该模型在处理高维度数据中具有明显的优势,在预测准确度上也有较好的效果。
4.2 Logistic回归
Logistic回归[10,11]是将多元线性回归的思想拓展成一种用于解决分类问题的模型。该模型对数据分布没有严格的条件,并且具有结构简单、参数易解释、节约算力、稳健性较好等优点。假设y表示用户是否下单购买,即“0”表示未下单购买,“1”表示下单购买。若模型的预测结果是y=1的概率,其表达式可以表示为:
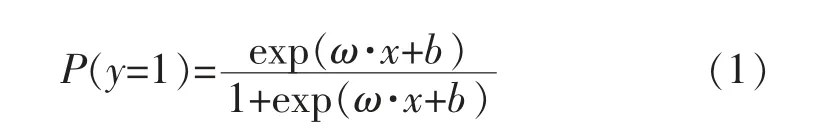
其中,x∈Rn是输入,y∈{0,1}是输出,ω∈Rn和b∈R是参数,ω称为权值向量,b为偏置,ω·x为ω和x的内积。模型的输出结果可通过与阈值0.5比较,若大于0.5,则表示下单购买,否则表示未下单购买。
4.3 基于随机森林和Logistic回归的组合模型
经过数据清洗和特征选择后,新的用户消费行为数据共计84104条,其中下单购买的用户样本有1209个,未购买的用户样本有82895个,存在着严重的类别不平衡问题。因此,本文采用欠采样技术[12]进行数据层面上的处理,以平衡正负类样本数量。首先,从未购买用户样本中随机抽取1209个样本,与已购买用户的1209个样本组成第一平衡训练集。其次,从未购买用户样本与已购买用户样本中分别随机抽取800个样本,组成第二平衡数据集,并按8∶2对其划分数据集。
为进一步提高用户消费行为预测模型精度,将RF与Logistic模型进行串行组合,其构建原理如图6所示。RF与Logistic的组合模型具体构建思路[13]:首先,用第一平衡训练集对RF进行训练。其次,将训练好的RF对第二平衡数据集进行预测,将得到的输出结果作为一个新的输入变量添加到Logistic模型中,而Logistic模型中其他的输入变量保持不变,得到组合模型。

图6 改进模拟退火算法的迭代过程图Figure 6 Iterative process diagram of the improved simulated annealing algorithm

图6 RF-Logistic组合模型的构建原理Figure 6 Construction principle of RF-Logistic combination model
最后,本文将第二平衡数据集的训练集部分用朴素贝叶斯(Naïve Bayes,NB)、支持向量机(Support Vector Machine,SVM)等其他单一模型进行训练,并在测试集上作对比,以保证各自模型最终所得出的预测准确率在比较分析中更具有说服力。
5 对比实验
5.1 模型性能评估指标
根据用户消费行为预测用户是否购买产品,是一个典型的二分类任务。本文使用二分类问题中常用的评估指标,包括准确率A(Accuracy)、精确率P以及F1分数来评估模型性能[14]。
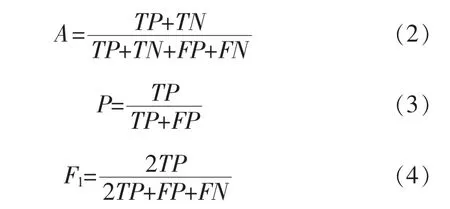
其中,FN表示正类样本(即标签“1”)预测为负类(即标签“0”)的样本数,TP表示正类样本预测为正类的样本数,FP表示负类样本预测为正类的样本数,TN表示负类样本预测为负类的样本数。
此 外,本 文 采 用ROC(Receiver Operating Characteristic)曲线和AUC(Area Under the Curve of ROC)值来验证模型的判别能力和预测精度。ROC曲线[15]一般应用于二分类模型的评估,其绘制方法基于两个重要的指标,即灵敏度(True Positive Rate,TPR)和特异度(False Positive Rate,FPR)。灵敏度表示预测为正类的样本数占所有正类样本数的比例;特异度是指当前被误分到下单购买用户中真实的没有下单购买的用户占所有用户数的比例。其具体计算公式如下:

根据以上原理,对样本按预测结果排序,再对每个样本分别以TPR和FPR为坐标点绘制ROC曲线。若坐标点离左上角越近,则表示分类器的预测准确率越高;若坐标点离右下角越近,则表示其预测准确率越低。此外,若画出的曲线足够平滑,基本可以判断没有太过拟合。ROC曲线线下面积即AUC值,也是分类任务中的常用评估指标。若AUC值越大,表明模型的分类准确率就越高。
5.2 结果分析
本文将构建的组合模型和常用的单一模型在同一测试集上进行预测,其分类效果如表3所示。
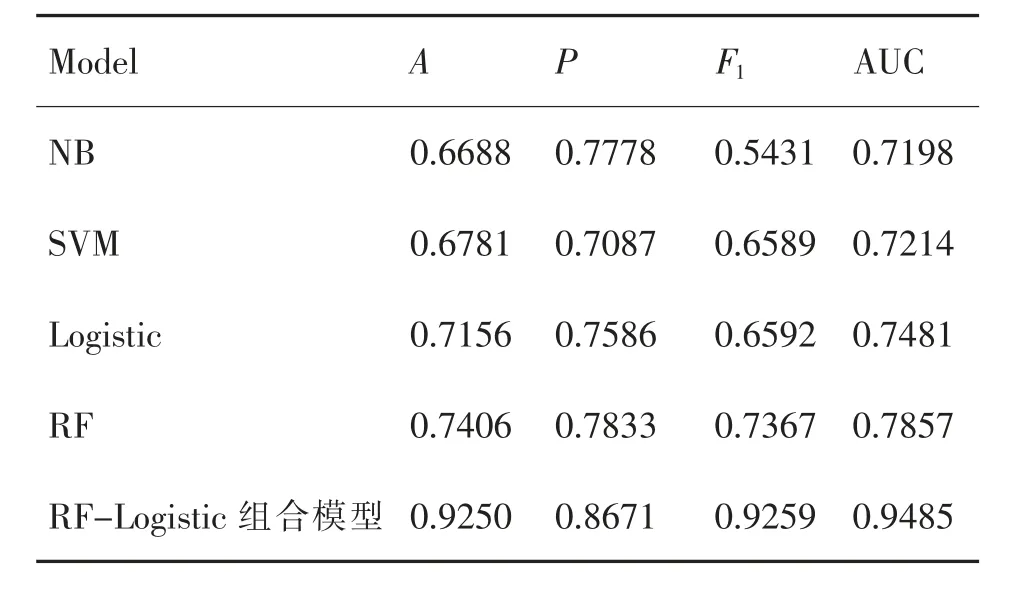
表3 常用分类模型和组合模型的测试评估指标结果Table 3 Test evaluation index results of common classification models and combination models
由表3可知,NB与SVM模型的预测准确率A值分别为66.88%和67.81%,其分类效果在其余评价指标上也表现得非常不理想;Logistic和RF模型的预测准确率分别为71.56%和74.06%,均显著优于NB和SVM模型;RF-Logistic组合模型的预测准确率高达92.50%,与Logistic和RF模型相比,在预测准确率上分别提高了20.94%和18.44%。综合来看,RF-Logistic组合模型的F1分数高达92.59%,与NB、SVM、Logistic和RF单一模型相比,组合模型的分类效果得到了大幅度提高。
此外,本文绘制了ROC曲线来进一步直观地反映组合模型与其他单一模型在下单购买行为预测(即标签“1”)上的分类效果,如图7所示。
从图7可知,NB模型、SVM模型、Logistic模型、RF模型以及RF-Logistic组合模型的ROC中AUC值 分 别 为0.7198,0.7214,0.7481,0.7857和0.9485。其中RF-Logistic组合模型的AUC值最高,说明组合模型对判别用户是否购买的分类效果较好。根据以上评估结果及分析,验证了RFLogistic组合模型可作为最终的用户消费行为预测模型。
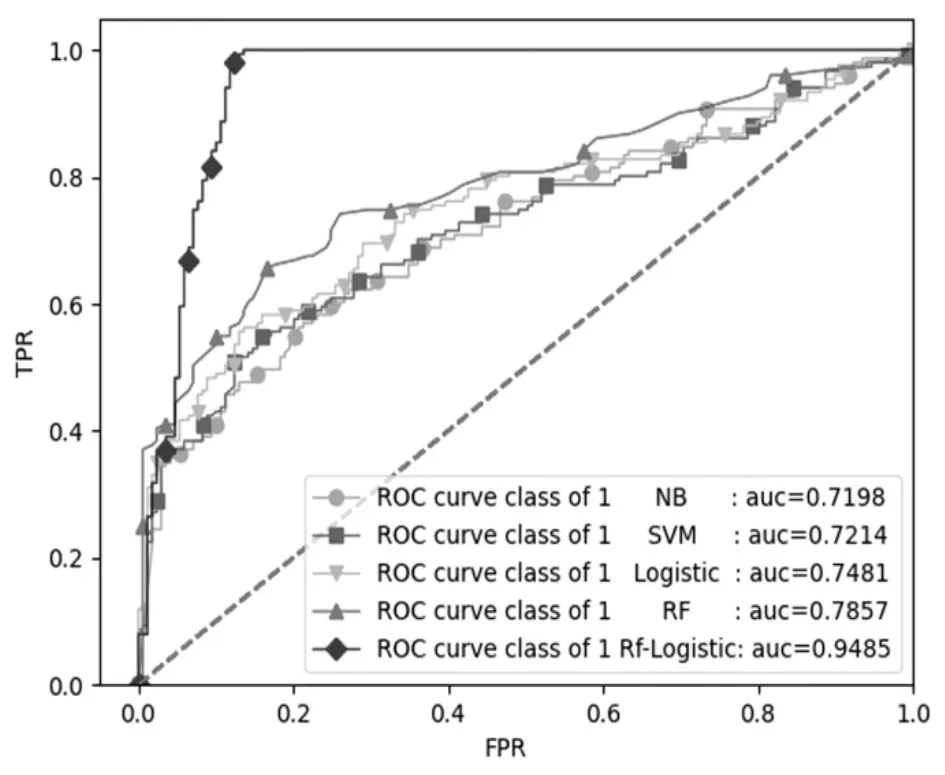
图7 组合模型与常用分类模型的ROC曲线Figure 7 ROC curves of the combined model and the commonly used classification model
6 结论
本文通过对用户消费行为数据进行清洗、可视化分析和特征选择,建立了基于随机森林和Logistic回归的用户消费行为预测模型,较大地提高了用户消费行为数据的预测准确率。这为帮助企业分析用户的消费行为规律、判别高质量用户,进而制定合理的营销策略提供了有益的借鉴。结合模型的分析结果,本文提出了如下的营销建议。
6.1 地区差异性营销
在对用户城市分布情况进行可视化分析后,发现总用户数量和购买用户数量存在同增同减关系,且在空间分布上呈现“东高西低、南高北低”的不均匀空间分布格局。根据这一现象,相关企业可以按区域进行营销,若营销推广所在区域位于东南地区,可以采取促销满减、开通会员打折等形式吸引用户注册购买,增加用户数量和购买用户数量。若营销推广所在区域位于西北地区,应该先注重增加用户数量,因为位于这些地区的用户往往比较看重价格,因而可采取降价、打折等形式进行促销。
6.2 登录签到有奖
在对用户登录情况进行可视化分析后发现,用户登录的时间间隔越短,下单购买的用户越多。根据这一情况,企业可以采取一定的措施来减少用户登录的时间间隔,即增加用户登录的次数,来促进用户下单购买,比如对登录时间间隔较长的用户设置签到有奖的活动,签到的次数越多,获得的奖励就越多越丰厚。此外,还可以设置用户在有限时间内登录平台达到一定次数时发放优惠券,来调动用户登录的积极性。
6.3 优惠券精准投放
根据用户消费行为数据分析,其中领券访问数仅占7%,而发生领券购买行为的用户数仅占4%,说明优惠券并未达到预期的营销效果。这说明企业在投放优惠券的时机选择和人群选择上具有较大的盲目性,定位不够准确,并且部分用户在浏览平台产品时收到不感兴趣的优惠券推送消息时,会产生反感情绪而导致用户不断流失。因此,建议企业在发放优惠券时,按照场景进行设定:获取新用户、提高活跃度、提高转化率和自传播。针对从未下单购买的用户,可以通过注册激活发券、下单有礼等方式获取新用户;通过发放优惠券的方式将已注册激活的用户唤醒召回;通过满减劵或者折扣券来实现用户从低价值向高价值的转化。通过场景设定,将优惠券发放给最有可能使用的人,以达到精准投放的目的。同样,也可考虑设定优惠券的具体面值、有效期和使用范围。
6.4 社交分享激励
根据数据分析,点击分享访问的用户占比61.43%,说明用户乐于与好友互动,将产品分享给好友。相关企业可以通过增加分享、关注、进群、做任务、添加好友等社交互动方式,鼓励用户和亲朋好友一起参与,促进用户的增长,提升用户的触达范围和转化效果:通过登陆和访问页面的推送,激励用户点击分享内容,提高用户活跃度,同时促进产品的宣传和推广。
