融合情感评论倾向与均衡长尾物品的推荐方法
2022-11-10王谢宁李玉蒻朱志国刘琦卿
王谢宁, 李玉蒻, 朱志国, 刘琦卿
(东北财经大学 管理科学与工程学院,辽宁 大连 116025)
0 引言
随着网络技术的成熟,互联网产品的与日俱增,用户的选择范围不断增加,个性化推荐系统因其能主动发掘用户喜好,向用户生成有效推荐,在各行业被广泛应用。协同过滤算法虽然是当下最流行使用范围最广的推荐算法,其由于算法维度有限问题导致推荐精度有限,针对有时用户评分无法表示用户的真实兴趣从而使得推荐准确率相对较低的问题始终无法解决[1]。另一方面,由于网络系统自身存在着明显的马太效应,使得系统无法充分发挥长尾效力,系统中的大部分产品无法被推荐,这直接影响到了系统的经济效益。
目前的研究主要集中在针对传统协同过滤算法的改进,以提高其覆盖率和推荐精度。董晨露,柯新生[2]考虑评论与评分的基于物品的协同过滤算法,该算法为目前国内外基于用户评论进行推荐的主流算法,即利用LDA主题模型计算用户评论主题相似度并与用户评分相似度加权进行协同过滤的推荐算法。然而用户对物品的评分是多重因素的结果,用户打分还有可能受到当前推荐系统的影响,同时因系统自身存在的马太效应导致的长尾问题依旧存在。丁勇,刘菁等[3]以基于位置的社交网络好友推荐为切入点,对距离, 熟识度,兴趣相似性属性进行多维度集成考虑,划定不同属性的线性权重,构建了基于用户交友偏好的好友推荐模型,一定程度上缓解了单一属性下推荐机制的冷启动问题,提升了算法的有效性和实用性。焦富森,李树青[4]在考虑用户评分受物品质量和评分偏好影响的基础上,融合了基于贝叶斯估计的物品质量评估以及用兴趣度对相应的用户评分进行修正的方法,提出了新的协同过滤算法,有效提高了推荐的效果。罗辛等[5]针对K近邻模型中预设的K值超出最优取值区间的两难选择,提出了相似度支持度这一新的K近邻度量值,并基于评分相似度和相似度支持度,提出了三种k近邻模型推荐系统的优化策略,有效改善了推荐过程计算的复杂程度,提供了更优的推荐效果。而杨阳等[6]通过奇异值矩阵分解的方式解决数据量过大或者过小而导致的时间和空间复杂度提高的问题,借助已有的用户档案建立近邻模型,实现基于矩阵分解与用户近邻模型的协同过滤推荐模型,减少了空间开销,提高了预测的准确率。陶维成等[7]为解决数据在高维度高稀疏下推荐算法的质量问题,创新的将灰色关联聚类应用到协同过滤算法中,定义了基于用户的灰色关联聚类,总结归纳了相应推荐算法的实现过程,有效地缓解了推荐系统的冷启动问题。冷瑞等[8]通过引入用户集聚系数这一统计量,借助经典的基于物质扩散的改进协同过滤算法,考察二部分图中用集聚系数对协同过滤算法的影响,以度量用户兴趣为核心思想,引入目标用户的集聚系数并赋予合理权重,形成了基于改进后的结合用户集聚系数的协同过滤算法。张文等[9]关注用户评分矩阵存在的全局稀疏性问题,将用户和商品采取分别聚类的措施,利用分块评分矩阵划定目标用户对商品偏好的局部性特征,并通过奇异值分解,施密特变换借助稠密分块近似预测用户对未知商品的评分,建立基于聚类矩阵近似的协同过滤推荐算法CF-cluMA,提升了推荐系统的稳定性和计算效率。与此同时,为了解决新项目新用户的冷启动问题导致推荐算法的精确度无法得到保障的问题,于洪等[10]在考虑到以往研究缺少对项目自身的基本信息和用户评分时效性情况下,对用户进行分类,建立用户时间权重的概念,以用户、项目属性、标签等信息为基础,得到个性化的预测评分值公式,提出了应对新项目冷启动问题的CUTATime个性化推荐算法。Toledo等[11]通过解决嘈杂评级问题,进一步提高推荐的准确度的同时,缓解了系统冷启动问题。李聪等[12]以Web日志为研究背景,得到用户的商品项访问序列,进而定义了n序访问解析逻辑,提出了基于改进最频繁项提取算法的top-N推荐,在一定程度上有效地消除了新用户冷启动的问题。
上述文献虽然从不同角度提升了推荐的准确度,但仍存在某些问题。首先,推荐系统的维度有限问题。评分不是代表用户兴趣的唯一标准,用户对于物品的喜好不能再简单以物品评分进行衡量,只有多维度的分析才能使推荐结果更加精准。其次,评论情感倾向划分单一问题,当前研究多局限于对正负两极情感倾向的判断,无法对用户的中性情感进行分类,对用户真正情感的判别存在较大程度的误差,从而使得在推荐过程中,对用户真正兴趣点把握错误,降低推荐结果的准确度。再次,推荐系统的长尾问题,即便上述文献进行了一定程度的长尾优化算法中,热门物品依然更倾向与热门物品相似,在用户喜欢热门物品的情况下,系统依旧很难推荐尾部冷门的物品[13]。
论文研究如何利用LSTM神经网络模型对用户情感进行分析以提高推荐系统的准确率,通过对热门物品进行惩罚从而增加推荐结果的覆盖率,将用户情感倾向得分与用户评分进行有机结合,设计融合用户评论情感倾向的个性化推荐算法;借鉴经济学中的基尼系数通过对热门物品的惩罚,发掘系统的长尾能力,改进衡量推荐算法覆盖率的指标,再分别调试用户情感系数和惩罚系数,利用随机搜索交叉验证法得出模型参数的最优组合,完成本文个性化推荐模型的构建。
1 融合情感因素的基于物品的推荐算法
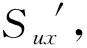
(1)
(2)
考虑不同用户评分习惯和评分范围的不同,本文引入物品评分标准差σx,得到用户u对物品x的标准化评分S(Sux):
(3)
公式(4)中U(x)表示喜欢物品x的用户集合,U(y)表示喜欢物品y的用户集合,物品x和物品y之间的相似度表达式如下,从公式中我们可以发现,物品x和物品y越相似则他们同时被越多的用户喜欢,这就会导致流行物品和其他任何物品的相似度都偏高,在后面我们将引入惩罚函数对其进行处理:
(4)
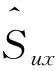
(5)
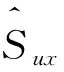
2 增加惩罚系数的基于物品的推荐算法
基于物品的协同过滤算法主要分为两个步骤:(1)计算物品相似度;(2)生成推荐列表。如上所述,物品流行度高的物品对应的用户数往往很少,如图1所示,而事实上相对冷门的物品带来的效益甚至能超过总体效益的四分之一。推荐系统应该为用户推荐所有用户可能喜欢的物品,而不应该几乎只推荐流行度高的物品。只有把握好对于一些冷门物品的适当推荐,才能让推荐系统在覆盖率和精准性之间更加均衡科学,让使用推荐系统的企业获得更多收益。流行物品之所以很容易向用户推荐,是由于流行物品受很多人喜欢,从公式(4)中可以发现,流行物品和任何物品的相似度都很高,他们都共同被很多用户喜欢,从而很容易被推荐给其他用户从而引发推荐系统的马太效应,使得推荐系统失衡。
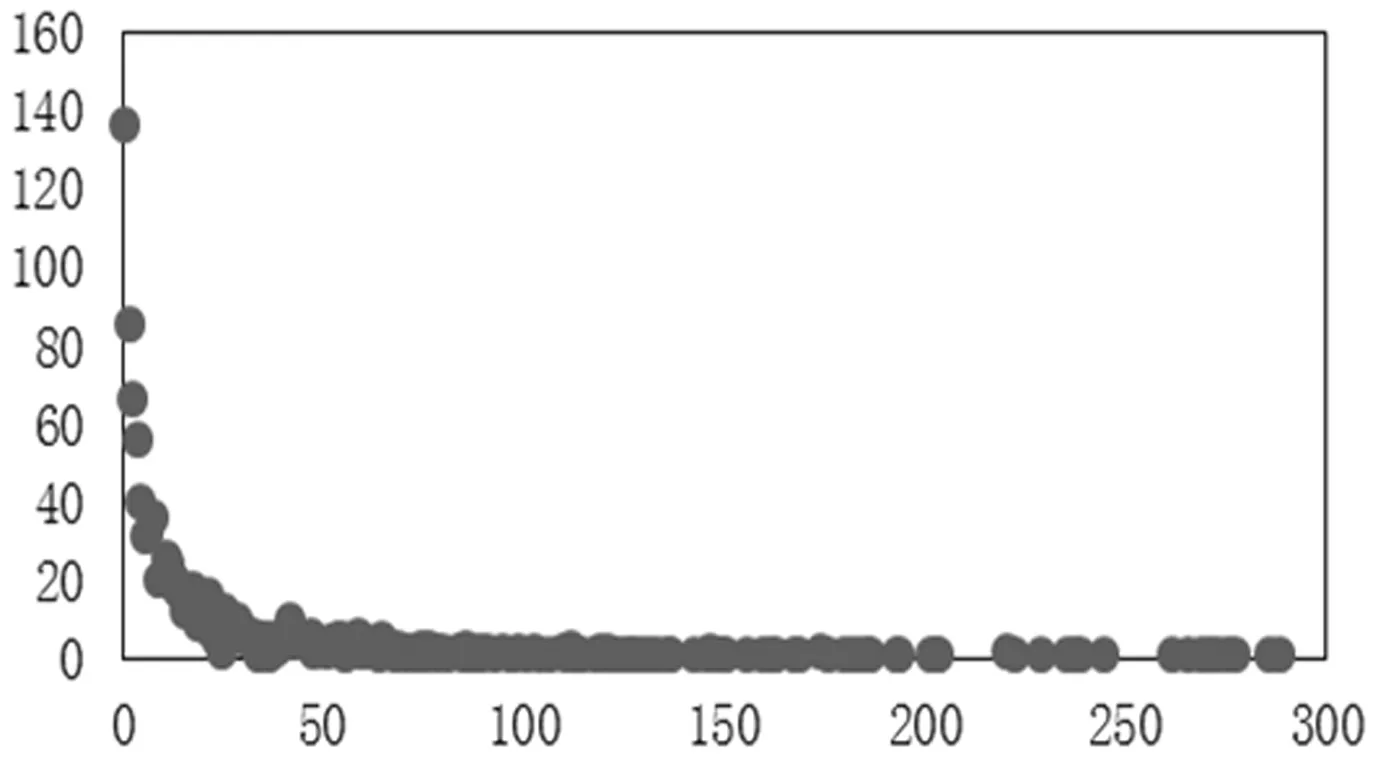
图1 推荐物品流行度的长尾分布
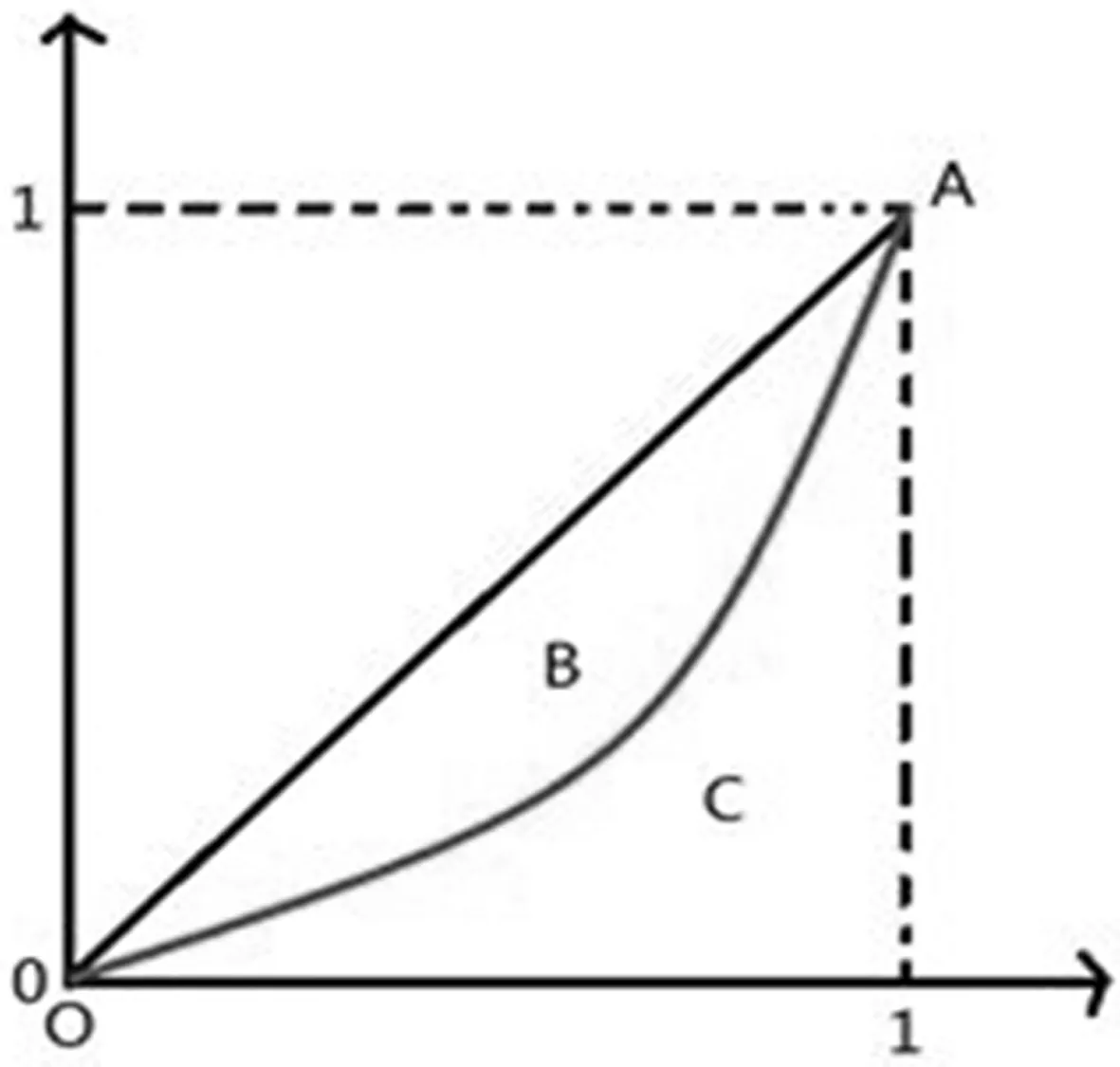
图2 利用基尼系数衡量物品推荐频数的平均程度
一个健全的推荐系统除了要有较高的准确率外还要善于发掘用户可能的潜在兴趣,利用好推荐系统的长尾能力,以更好地实现效益最大化。在本文中利用基尼系数来定义推荐系统的覆盖率,来衡量一个推荐系统的优劣。基尼系数是用来衡量一个国家或地区居民收入差距的常用指标,基尼系数的大小,表示了收入不平等程度的大小,但其实质是对分布均匀度的量化分析,并不是经济学的专有名词[15],目前已经应用在其他学科与均匀度方面的相关分析中[16]。不同热度的商品对于不同用户的分配推荐场景非常类似于国民收入的差距和均匀程度的分配,因此本文利用基尼系数衡量物品推荐频数的平均程度,如果基尼系数小,则说明不同流行度的物品被推荐的次数几乎相同。
如图2所示,其中横轴表示物品数量的累积百分比(按流行度从低到高排列),纵轴表示流行度的累积百分比。直线OA代表理想状态下,推荐物品完全覆盖所有物品的情况,曲线OA以上和直线OA围成的图形为B,曲线OA以下的图形和直线OA围成的图形为C,那么基尼系数即为SB/(SB+SC),由此可知,基尼系数越小,则SB越小,曲线OA更趋近于直线OA,系统推荐的物品流行度分配也更加平均。系统中衡量覆盖率的基尼系数表达式如下,其中l(itemi)表示物品流行度从小到大排序的物品列表中的第i个物品的流行度:
(6)
同时,为了避免流行物品泛滥和系统的失衡,本文引入惩罚系数对相似度计算公式进行修正。如果物品y是流行物品,受到很多人的喜欢,那么通过提高β的值并除以物品长度函数,就可以惩罚物品y,以减轻物品y在计算中所占的权重,如下所示:
(7)
其中α+β=1,β∈[0.5,1],依据这一步计算所得的物品相似度,预测用户对物品的评分,并进行排序向用户进行推荐。
3 实验分析
3.1 数据筛选
本文使用的数据为马蜂窝网上爬取的数据,共10841条实验数据,囊括192个用户,主要包括两部分:用户信息和项目信息。总共爬取用户信息表三个,项目信息表两个。清洗、筛选、整理并统一数据格式,保留有评论的用户数据,调整其格式,使得用户信息表拥有五个属性:用户ID、用户名、用户性别、用户等级和用户居住地;项目信息表拥有如下七个属性:用户ID、旅游城市ID、旅游项目ID、旅游项目名称、旅游项目评分、旅游项目类型和旅游项目评论。然后随机将数据集按8:2比例分成训练集和测试集,分别保存,用户评论再单独另存为一个文件。经过处理后的文件即可正常被读取进行实验运算。用户评论的文件将被用于进行情感极性分析,以解决推荐系统维度有限性问题,得到的分析值将与项目信息表进行整合,获得用户对物品的重估评分,并在此基础上增加惩罚函数对推荐算法进行重新构造,从而为用户生成推荐列表。
3.2 实验结果分析
为了评估模型性能,本文的改进的基于物品的协同过滤算法主要与以下三种算法进行对比分析:(1)传统的基于物品的协同过滤算法,(2)考虑评论与评分的基于物品的协同过滤算法,(3)基于用户评论主题相似度的协同过滤推荐算法。本文将第一种算法命名为ICF算法,将第二种算法命名为PICET算法,将第三种算法命名为CFRTS推荐算法,将本文改进的算法命名为PICETP算法。
将用户数据和项目数据,包括用户ID,项目ID,项目评分,用户评论等属性,在为评论计算情感值时,设置epoch=10,测试出准确率最高的参数,该算法选用的主要参数为词语创建词字典的最低词频,将两算法不同词频值对应的算法准确率统计如表1所示,由表1可以发现,不同的词频对于两类算法的结果影响都较小,二分类和三分类情感分析模型在词频设置为10时,均拥有最高的准确率。

表1 不同词频对应准确率
虽然将LSTM神经网络结构模型的loss函数换为categorical_crossentropy函数,激活函数换为softmax函数,输入三种情感极性的训练数据构造三分类情感分析模型时,准确率有所降低,但是对于中性情感的分类更加准确,能有效区分中性评论。从实验结果来看,该模型对于中性情感评论把握更加准确,这在事实上提升了对用户评论情感分析的准确性,对于用户评分的修正也更加可靠。而对于三分类情感分析准确率较低的现象,本文认为主要原因有训练集中性情感数据的数据量相对较少,训练语料只有其他两种情感训练集的一半,另一方面,由于三分类情感分析目前研究较少,导致中性情感的数据集质量不高,使得训练结果欠佳。
利用LSTM神经网络模型计算得出的用户评论情感倾向值和用户评分进行加权求和,得到一个新的用户评分,计算方法如下表所示,其中γ+δ=1:
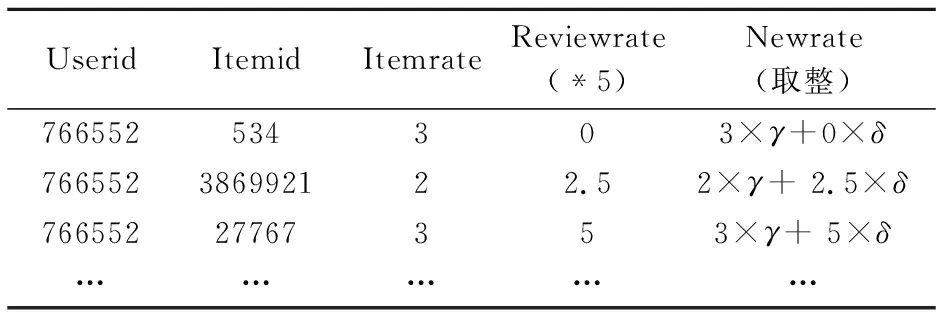
表2 情感值与用户评分加权方法
PICETP算法在基于物品的协同过滤基础上融合了用户评论情感倾向值和惩罚系数,从而实现算法的准确率和覆盖率的提高,故总共有4个参数值需要调整,包括:邻域个数k[5,10,20,40,80]、推荐个数n[5,10,15,20,25]、情感因素权重Γ[0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]、惩罚系数β[0.5,0.6,0.7,0.8,0.9],验证复杂度达到O(|k|·|n|·|Γ|·|β|·m),如果手动对参数进行调参,将极大地增加实验的复杂度和实验时间。另一方面,虽然推荐个数对算法的准确率和覆盖率会产生一定影响,但本文认为推荐个数对于准确率和覆盖率的影响不具有代表性,不能说明算法的性能,故本文所有实验都在推荐个数n=5的情况下进行。最后,利用网格搜索m折交叉法对参数进行调优,考虑算法的复杂度和实验时间,选择m值为10,本文在推荐个数固定为5且未增加惩罚系数的情况下,利用网格搜索方法对上文中的每组参数组合在马蜂窝数据集上进行了十折交叉验证。
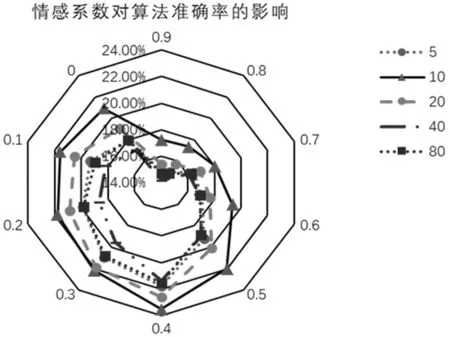
图3 n=5时,不同情感系数和邻域数对应准确率
实验平均准确率的输出结果如图3所示,主坐标轴代表算法的准确率,环形排列的副坐标轴代表算法中使用的情感系数。可以发现,邻域数量为10的情况下,准确率值最高,并且准确率值并不随着邻域数量的增长而增长,主要因为邻域数量较少时,可能未完全包含用户的兴趣,而邻域数量过多时,可能包含了用户兴趣之外的其他兴趣,这两种情况都会导致推荐的准确率降低。在情感系数取值为0.4时,即用户评分与用户评论情感倾向得分按6:4加权计算作为推荐依据的情况下,不同邻域数量对应的准确率值均最高。同时可以发现单纯以用户评论情感为依据和单纯以用户评分为依据的准确率均没有融合两者得出的准确率高,并且在情感系数取值范围在0~0.4的情况下,准确率随着情感系数递增,这说明了用户情感倾向得分对用户评分起到了较优的修正作用,使得算法的准确率得以提升,而情感系数取值在0.4~0.9的情况下,准确率随着情感系数递减,出现该类现象的原因考虑是本文利用的情感分类模型对评论的情感倾向分析只有三分类,这就导致情感倾向分值并不能完全代表用户兴趣偏好,而如果主要以情感倾向分值作为向用户推荐的依据则会使得算法的准确率降低。由此可见,考虑情感因素对推荐算法的准确率确实有积极作用,能在一定程度上提高算法的准确率。通过网格搜索交叉验证法对参数进行的上述实验可发现,在Γ=0.4时,模型拥有最高的推荐准确率,故此次实验是在Γ=0.4的情况下对惩罚系数进行调整,分析惩罚系数对推荐覆盖率的影响,图3中所示曲线块为情感因素占比为40%时,不同惩罚系数对应的覆盖率值。
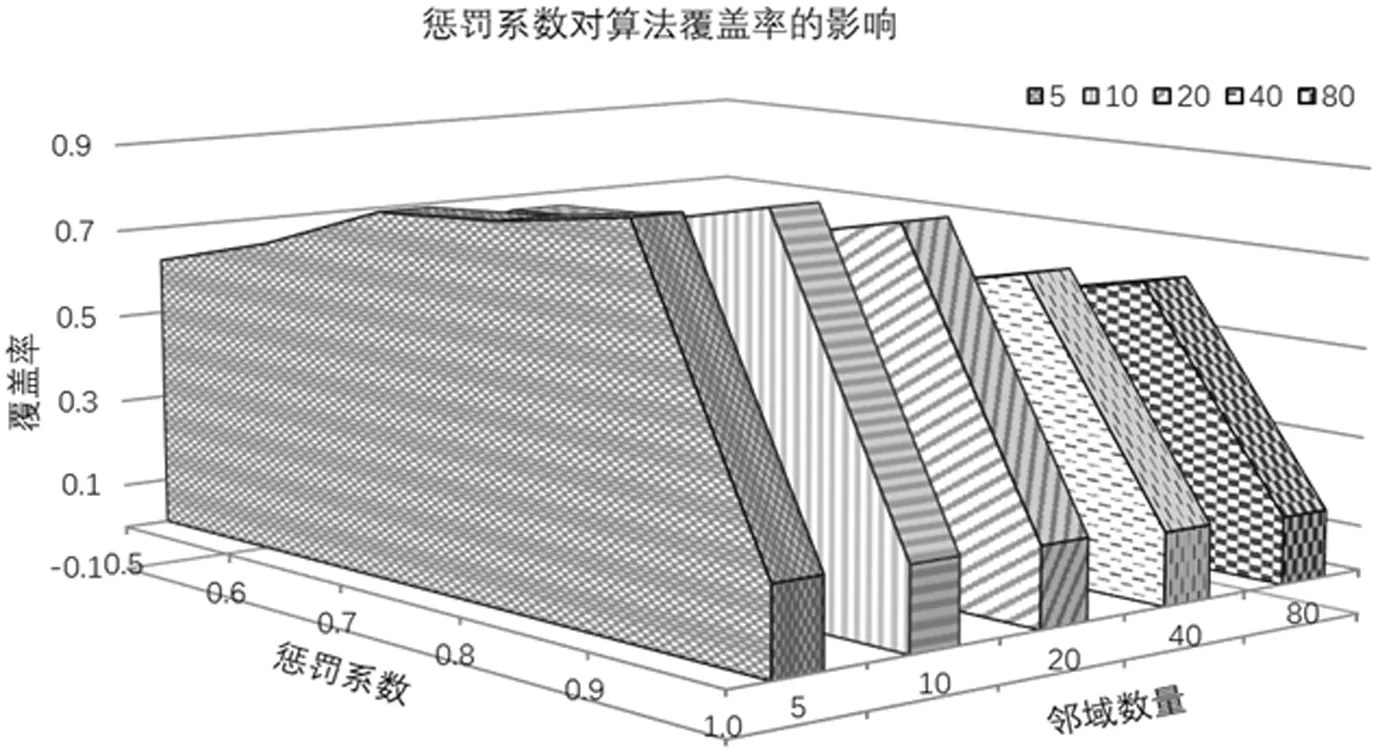
图4 n=5,Γ=0.4时,不同惩罚系数和邻域数对应覆盖率
由图4的输出结果可以发现,在惩罚系数取值为0.6~0.9时,随着惩罚系数的增大算法的覆盖率得到了明显的提升,但当惩罚系数取值为1时,算法的覆盖率出现了突然地下降,此现象的出现是由于计算物品相似度时,考虑的是物品间的关联性,当惩罚系数为1时,将直接导致热门物品被忽略,从而使得计算物品-物品相似度时最相似的物品为自身,大大降低了算法的覆盖率。同时,随着邻域数量的增加,PICETP推荐算法的覆盖率逐渐下降,这主要因为推荐系统具有马太效应和数据的稀疏性,而考虑了更多的邻域将导致所有物品均更容易与热门物品相似,所以使得推荐算法的覆盖率降低。

图5 n=5,Γ=0.4时,不同惩罚系数和邻域数对应准确率
图4为推荐个数为5,情感系数为0,4时,不同惩罚系数对应的算法准确率,结合图5可以看出,当不添加惩罚系数时,算法的推荐结果是最精准的,但是覆盖率较低,而当惩罚系数持续增大时其将导致热门物品几乎被忽略,从而使得物品与物品间的关系减弱,从而使得准确率出现明显下降。并且,推荐系统如果推荐率较低,总是单一重复的推荐流行物品,而不推荐其他物品,不仅不能主动发掘用户的其他潜在兴趣,还很难推广推荐系统中的其他产品包括新品,这将很难满足用户的个性化需求,同时还会导致推荐系统的经济价值不能被完全开发。结合图3、图4和图5,可以发现融合了用户评论情感因素的推荐算法拥有更高的准确率,由于未融合用户评论情感因素的算法,同时,增加了惩罚系数的推荐算法在牺牲较小的准确率的情况下,较大幅度地提升了推荐算法的覆盖率,并且本文添加惩罚系数牺牲了准确率后其准确率仍高于未融合用户评论情感倾向的推荐算法。综上,证明本文所提出的PICETP算法在实验指标测评结果对比中,在准确率和覆盖率指标上有了更好的推荐结果。
3.3 实验结果对比
在上述实验中,已经测试得出PICETP推荐算法的最佳参数组合,在推荐列表长度为5,邻域数量为10,情感系数为0.4,惩罚因子为0.6时,拥有较高的准确率,同时有着较高的覆盖率。本文将对比PICETP推荐算法和其他几种算法之间结果的差异,主要有以下几种算法:①ICF算法,即基于物品的协同过滤算法,②CFRTS算法,利用LDA主题模型计算用户评论主题相似度并与用户评分相似度加权进行协同过滤的推荐算法,③PICET算法,即考虑评论与评分的基于物品的协同过滤算法,④PICETP算法,即融合了情感因素和惩罚函数的基于物品的推荐算法,该方法即本文提出的实验方法,参数使用前面实验得出的最佳参数组合。
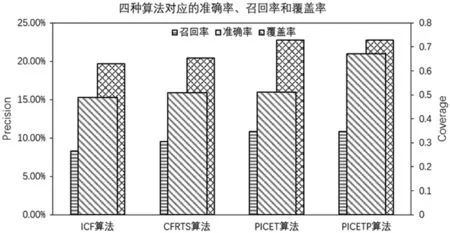
图6 四种算法对应的准确率、召回率和覆盖率
考虑时间和算法复杂度等其他因素,取推荐长度为固定值5,邻域数量取固定值为10, 四种推荐算法对应的准确率、召回率和覆盖率如图6所示。同ICF推荐算法相比,只考虑评论与和评分的PICET推荐算法由于考虑了用户评论情感倾向的修正作用,相较于ICF算法拥有更高准确率和召回率,也即其在一定程度上提升了推荐的准确度。而CFRTS算法由于在计算物品相似度时,加权了用户评论的主题相似度,从多方面挖掘了物品之间的相似度,故其在一定程度上也提升了算法的准确率。然而,由于PICET算法和CFRTS算法对于热门物品权重未做处理,代表其推荐产品时还是存在网络系统中由于热门物品导致的马太效应,使得其得到的覆盖率几乎与ICF算法一致。即融合了用户评论情感分值的PICET算法和考虑用户评论主题相似度的CFRTS算法能有效提升算法的准确率,却无法有效提升算法的覆盖率。而PICETP算法同时融合了用户情感因素和热门物品的惩罚效应,将同时作用于推荐算法的准确率和覆盖率,在提高推荐算法准确率的同时提升算法的覆盖率。
综合上述实验可以发现,相较于现存的多种算法,PICETP推荐算法在准确率和覆盖率上均有所提高,证明了评论的情感因素和惩罚系数对于构建性能更佳的推荐模型的有效性。
4 结论
本文在研究用户历史行为的基础上,考虑热门物品权重和用户隐藏情感对用户未来可能产生行为的影响,在基于物品的推荐方法上进行改进,融入情感因子和惩罚系数,构建PICETP算法,分析其和其他推荐算法间性能的优劣。综合实验结果,针对用户评论和评分经常存在不一致现象,企业在未来的营销环节应该更加注重用户的真实情感,更多参考用户的评论价值。同时,根据用户属性将用户分类,对不同类的用户需要采取不同的推荐手段,以此达到推荐算法的人性化,经济效益的最大化。相信本文研究结果对日后的个性化推荐方法有借鉴意义。后续将利用更多的属性和特征模型对算法进行优化与完善。
