融合自注意力机制的诈骗电话分类模型*
2022-11-10姜彤彤许鸿奎周俊杰张子枫卢江坤胡文烨
姜彤彤,许鸿奎,2,周俊杰,张子枫,卢江坤,胡文烨
(1.山东建筑大学信息与电气工程学院,山东 济南 250000;2.山东省智能建筑重点实验室)
0 引言
随着科学技术的发展,我国通信行业迅速崛起。在智能设备使用规模和网民数量不断增加的同时,电信网络诈骗犯罪也在不断升级,给国家和人民带来了巨大损失,更是在社会上造成极其恶劣的影响,尽管近几年国家对电信诈骗的治理力度不断加大,但个别地区形势依旧严峻。
电话诈骗是指以电话为载体,犯罪分子通过冒充淘宝客服、冒充熟人、冒充公检法等手段对受害人实施诈骗的一类犯罪行为,具有诈骗套路多、诈骗金额大、诈骗成功率高的特点。尽管各种治理手段不断地更新、迭代,但当今社会,个人信息保护意识薄弱,姓名、银行卡、手机号码等个人隐私信息的泄露严重,人们往往防不胜防,尤其在老年人群体中,电话诈骗仍占有很高的比重,因此,不断完善对电话诈骗的治理方案、加大打击力度刻不容缓。
传统的电话诈骗治理方式主要是基于信令数据,通过对主叫号码的结构进行分析,以及结合投诉数据,建立黑白名单库进行实时分析,实现对诈骗号码的拦截处理,但此种方式只能实现对有一定规律性的号码进行拦截,犯罪分子通过频繁更换号码或使用改号软件模拟真实号码等手段可轻松绕开这种反诈骗手段,可见传统的拦截方式无法实现精准、实时拦截,已无法适应当前的严峻形势。
机器学习的迅速发展,为电话诈骗的治理打开了新思路。文献[1]针对传统的骚扰电话识别误报问题,提出一种基于用户呼叫行为的识别算法,并引入随机森林,识别精度有较大的提升。文献[2]提出基于大数据的诈骗电话分析技术,通过建立分析模型,对海量呼叫信令进行分析,实现了通话结束后3~5min内输出疑似受害用户号码,通过及时回访达到事前预防的目的。文献[3]通过提取诈骗电话特征、分析通信行为探索结果等建立基于随机森林的诈骗电话普适模型,对诈骗电话号码进行了有效识别。文献[4]等通过对用户通话行为、上网行为、用户基本属性、手机终端信息等进行综合分析,建立基于机器学习的诈骗电话识别模型,有效提高了诈骗电话的识别率。
机器学习的相关技术和工具在诈骗电话治理上的应用,使得反诈骗手段有了较大的提升,而神经网络算法较传统的机器学习算法,具有算法更强大、准确率更高的优势,因此,提出了一种基于自然语言处理技术(Natural Language Processing,NLP)的诈骗电话识别模型,首先将电话语音转成文本,本文的研究是对语音识别后的文字进行处理,利用文本分类技术对文本进行预处理、特征提取、分类等操作,达到识别诈骗电话的目的,为诈骗电话的治理提供了一种新的技术选择。
1 相关工作
自然语言处理技术是近几年的研究热点,已广泛应用于情感分析、垃圾邮件检测、词性标注、智能翻译等领域。互联网的迅速崛起,也伴随产生了大量的数据信息,包括文字、图片、声音等,其中,文本资源占据了一大部分,我们获取的信息有很大一部分都来自于文本,文本分类的目标是自动对文本进行分门别类,帮助人们从海量的文本中挖掘出有用的信息。文本分类的研究大致分为三类:基于规则、基于机器学习和基于深度学习的方法。基于规则的方法是通过人工定义的规则对文本进行分类,但这种方法依赖于专家的领域知识,须耗费大量的人力物力,且编写的规则只适用一个领域,迁移性差;基于机器学习的方法以支持向量机、朴素贝叶斯、决策树等为代表,较基于规则的方法,机器学习的方法有了很大的进步,但是由于文本表示巨大的数据量,对机器学习算法的运行效率提出了新的挑战;深度学习的快速发展,为学者在文本领域的研究打开了新的大门,文献[5]首次提出将卷积神经网络应用于文本分类。文献[6]提出一种基于多通道卷积神经网络的分类模型来提取微博情感分析任务中特有的情感信息。文献[7]将卷积神经网络用于Twitter的极性判断任务。
注意力机制源于人类大脑的视觉信号处理机制,本质是对信息资源的高效分配,被广泛应用在图像处理、自然语言处理等领域,谷歌在2017 年提出了Transformer 模型[8],将注意力机制的优势发挥到了极致,同时具有并行计算和抽取长距离特征的能力。Transformer 仅由自注意力机制和前馈连接层叠加组成,具有良好的特征抽取能力。很多学者将自注意力机制用于不同的研究领域,并且取得了不错的效果,文献[9]将其用于解决长文本的相似度计算问题,提高了对深层次的语义信息抽取能力,文献[10]将其用于推荐系统来提取不同子空间的特征信息。受此启发,本文将自注意力机制与卷积神经网络结合,用于诈骗电话的识别任务,CNN 具有捕捉文本的局部语义特征和并行计算的优势,利用自注意力机制对CNN输出的浅层特征进一步提取其序列的内部依赖关系,提高模型的表征能力,分类效果更好。
2 系统模型
2.1 模型总体架构
本文构建了一种基于融合自注意力机制和CNN的诈骗电话识别模型CNN-SA,结构如图1所示,由词嵌入层、卷积层、自注意力层和分类层组成。

图1 CNN-SA结构图
2.2 词嵌入层
电话文本输入分类模型之前,首先需要进行文本预处理,获取文本的词向量表示。目前常用的主流方法是以Word2Vec[11]和GloVe[12]为代表的词语的分布式表示,这种方法可以表示出词与词之间的相似性关系,且向量维度低,避免了维度爆炸问题。本文的词嵌入层选择的是基于Word2Vec 的预训练词向量表示,向量维度为300 维,该模型按训练方式分为Skip-Gram和CBOW 两种,Skip-Gram是由当前词来预测上下文词,而CBOW 正相反,是由上下文词来预测当前词,其结构分别如图2和图3所示。

图2 Skip-gram

图3 CBOW
2.3 卷积层
TextCNN 的原理是将卷积神经网络应用到文本分类任务中,通过设置不同大小的卷积核可以更好地捕捉句子的局部特征。TextCNN 的网络结构如图4所示,包括卷积层、池化层和全连接层。卷积层的输入是用Word2Vec 或者GloVe 方法预训练好的词向量组成的嵌入层;在卷积层中,卷积核的宽度与词向量的维度一致,高度可以自行设置为2、3、4等,实现对不同局部大小的特征进行提取。
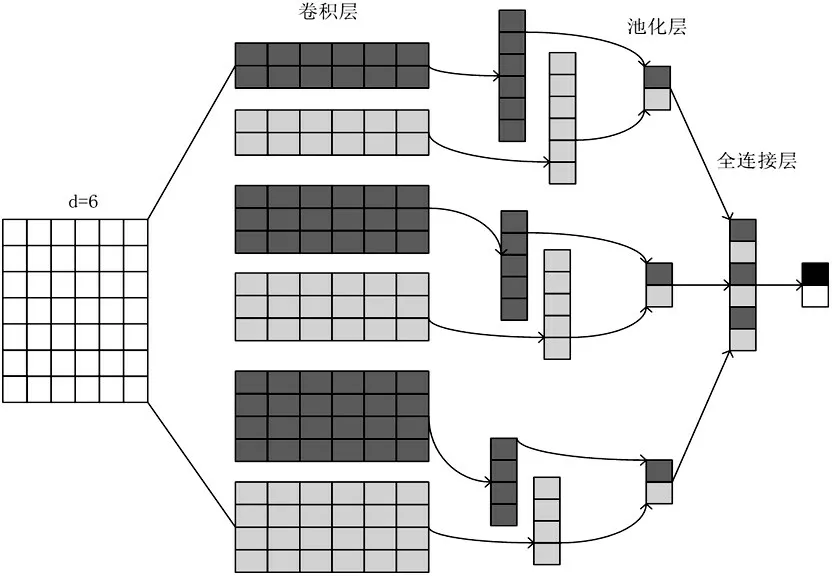
图4 TextCNN结构图
卷积操作的过程可以表述为:

其中,X为输入词向量,W为权重向量,b为偏移量,⊗表示卷积运算,f(·)为激活函数。
在池化层中,为减少重要信息丢失,放弃最常用的最大池化操作,选择平均池化,可以更加突出整体信息,通过池化运算对卷积层输出进行下采样,一方面达到特征降维的作用,另一方面也极大减小了参数量,可以防止过拟合。经过池化层后,每个卷积核得到一个值,最后将这些值拼接起来通过全连接层输入softmax层进行分类。
2.4 自注意力层
注意力机制的提出,大大提高了人类对信息处理的效率和利用率,自注意力机制是注意力机制的一种特殊形式,较注意力机制,它更擅长捕捉特征的内部相关性,减少了对外部信息的依赖,其原理是通过缩放点积注意力(Scaled Dot-Product Attention,SDA)和通过向量点积进行相似度计算得到注意力值来实现的。SDA 的结构如图5 所示,首先Q、K 通过点积运算,进行相似性计算,然后使用softmax 函数进行归一化计算,最后结果乘以V,得到输出,计算过程表示为:
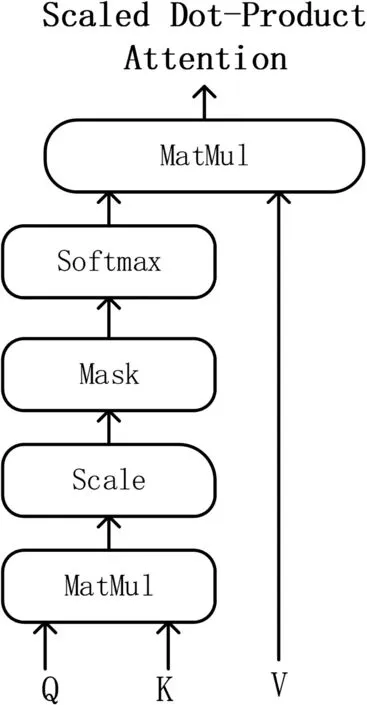
图5 SDA结构图
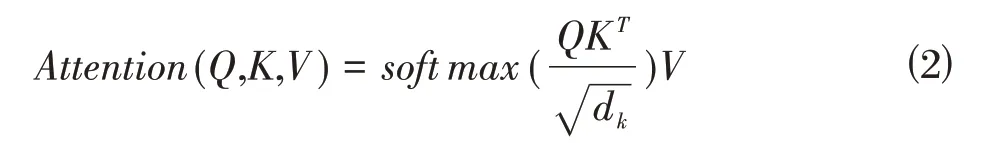
其中,Q、K、V分别为查询矩阵、键矩阵、值矩阵,为调节因子,使得Q、K的内积不至于过大。
3 实验
3.1 数据集
本文采用的数据集为自己构建的电话文本数据集,包含诈骗文本和非诈骗文本各约5000 条,是从微博、知乎、百度等网站抓取整理的,其中诈骗文本包含近几年频繁出现的网络贷款、网络刷单、冒充客服退款、虚假购物、注销“校园贷”、买卖游戏币等各类电话诈骗类型。本文实验的训练集、验证集和测试集大小分别划分为6000、3000和1200。
3.2 实验环境及实验参数设置
实验的硬件环境为:操作系统为Windows 10,GPU 为NVIDIA GTX1650,CPU 为i5-10300H;软件环境为:Python 3.7,学习框架Pytorch 1.5。
在电话文本数据集上,采用Word2vec词嵌入方法训练词向量,词向量的维度设置为300维。CNN-SA的参数设置为:卷积核的大小为(2,3,4),数量为256,步长为1,卷积层后采用relu 激活函数,池化层采用平均池化。经过反复实验,提出模型的最优学习率为0.0001,batch为128,epochs为30,dropout的比率为0.5。
3.3 实验结果
为验证本文提出CNN-SA 的有效性,将电话文本数据集分别在以下几种模型上进行对比实验分析。
⑴ TextCNN:单一TextCNN 模型提取序列局部特征,参数设置与CNN-SA中TextCNN模型相同。
⑵ BiLSTM 与BiGRU:单一双向LSTM 与双向GRU结构,参数设置两者相同。
⑶ BiLSTM-attention 与BiGRU-attention:在双向LSTM 和双向GRU 结构后,引入传统的attention 机制,提取关键特征。
⑷CNN-SA:本文提出的一种的融合自注意力机制和CNN的混合分类模型。
实验采用的评价指标为准确率Accuracy、精确率Precision、召回率Recall和F1值,在电话文本上的实验结果如表1所示。

表1 实验结果
3.4 结果分析
从表1 可以看出,提出模型CNN-SA 的各项衡量指标均明显优于单一TextCNN、BiLSTM 和BiGRU 模型以及BiLSTM-attention 和BiGRU-attention 模型,这表明融合模型CNN-SA 提取的特征信息更充分,因而分类效果最好。
在准确率方面,BiGRU模型的性能要优于BiLSTM模型,有0.42%的提升;BiLSTM-attention较单一BiLSTM模型提高了0.58%,BiGRU-attention 较单一BiGRU模型提高了0.33%,这表明,引入attention 机制可以使模型更好地提取关键信息,从而提升分类性能;而所提模型CNN-SA 比单一TextCNN 模型提高了1.75%,这是因为引入自注意力机制,可以使模型更好地关注序列的内部依赖关系,弥补了TextCNN 模型只关注局部信息的不足。
4 结束语
本文针对目前电信诈骗中案发率比较高的电话诈骗问题,提出了一种基于NLP 的识别方案,建立融合自注意力机制和卷积神经网络的诈骗电话识别模型CNN-SA。首先利用词嵌入模型Word2vec 获取预处理后的文本的词向量,并将其输入TextCNN 模型,捕捉文本的局部特征信息,再利用自注意力机制进一步提取电话文本序列内部的依赖关系,最后将其输入softmax层进行分类。
