一种考虑货位共享效应的Fishbone仓储布局优化方法
2022-11-09刘建胜高腾飞
刘建胜,杨 林,高腾飞
(南昌大学 1.先进制造学院;2.经济管理学院,江西 南昌 330031)
近年来,国际竞争日益激烈,德国提出“工业4.0”以来,各国纷纷出台相关政策。我国战略性布局“中国制造2025”,振兴制造业,实现从制造大国向智造强国转变,围绕智能工厂、智能车间、智能仓储、智能物流等主题内容,实现我国制造业提质降本增效的管理目标。仓储物流是制造产业链中重要一环,在制造业以及零售业中扮演着愈发重要的角色。根据仓储运作流程,仓储效率影响因素主要包括仓储布局设计、货位分配以及拣货作业。
仓储布局设计问题长期以来受到国内外学者广泛重视。2009年美国学者Gue等[1]创新仓库布局规则,提出非传统布局方式,并发现在一定的假设条件下,该布局方式能够减少平均10% ~ 20%的移动距离。这种显著优势激发了广大科研人员对仓储布局优化的重新思考,以非传统仓储布局为对象,相关理论研究成果不断丰富。Pohl等[2-3]在Fishbone设计中分析单、双命令操作和基于周转率的存储策略,结果表明,使用随机存储策略获得的最优布局参数用于周转率存储策略时,拣货距离表现同样优异。Öztürkoğlu等[4]在随机存储策略基础上,建立一个连续空间模型,用于分析和优化仓库设计,得到Chevron型、Leaf型、Butterfly型3种非传统布局。Cardona等[5]给出一种基于参数确定三维鱼骨布局的设计方法,以仓储面积成本和货物拣选成本最小为目标,建立仓储布局设计优化模型,采用遗传算法求解。Venkitasubramony等[6]基于精确的多边形轮廓,建立随机、基于分类和全周转率存储策略下Fishbone布局的离散和连续的距离模型。国内方面,张志勇等[7]对现有方法进行改进,提出一种形似两片树叶的双叶Leaf布局方法。蒋美仙等[8]在研究Fishbone布局时结合贯通式货架系统的思想,给出一种改进Fishbone仓库布局方法。
货位分配优化问题是解决如何将货物分配到最“合适”的位置上,以使得仓储效率最大化。其主要涉及到3种存储策略,分别为随机存储策略、分类存储策略和全周转率存储策略(每个类别中存储一种货物)。已有文献对货位分配优化问题进行研究,对于多层货架而言,其主要优化目标为出入库效率最高和货架的重心最低[9]。现有研究大部分是基于“存储货物所需的货位数量等于其平均库存水平”假设条件下,仅探讨基于货物周转率进行多个存储类别的划分,以期带来仓储效率的提高,而忽略了一个存储类别中不同货物之间货位共享效应的降低会导致仓储所需货位个数增加,致使仓储效率降低。Yu等[10]证实仅当一个存储类别中,货物的种类数趋近无穷大时,“存储货物所需的货位数量等于其平均库存水平”这一假设才会成立。而实际仓储运作中,一个存储类别中存储的货物种类数是有限的,因此,在衡量仓储出入库效率时,应同时考虑货物的周转率效益和货位共享效应,目前极少文献考虑这两方面因素。Yu等[10]通过考虑有限数量的物品并放松一定的假设,构建一个拣货时间模型,结果表明更多的存储分类并不是最优的。Guo等[11]在传统矩形仓储中探讨3种存储策略在拣货距离方面的表现时,涉及货位的共享效应,构建平均拣货距离函数模型并进行求解,结果表明,在考虑货位共享时,基于分类的存储策略优于随机存储策略和全周转率的存储策略。Venkitasubramony等[12]研究一种单分区货架的仓库布局设计问题,并在纵向和横向两个维度上都采用基于周转率的仓储分配,在确定仓库规模时,将货位共享效应对仓储空间需求的影响考虑在内。
综上所述,货位共享效应真实存在,考虑共享效应的仓储布局设计在仓储运作管理中扮演着越来越重要的角色,现有文献暂未发现在考虑货位共享效应的前提下,研究3种存储策略对非传统仓储布局设计影响。本文将重点探讨基于货位共享效应的新型Fishbone仓储布局优化设计问题,并给出解决此类型仓储布局问题的方法。
1 仓储布局设计
1.1 仓储布局
企业土地资源成本上升,仓库设计不合理不仅造成仓库面积利用率不高,而且拣货效率低下。因此,需要设计合理的仓库布局和结构,在尽可能保证仓库面积成本及面积利用率的前提下提高货物存取效率。图1所示是非传统Fishbone型仓库布局,以此进行参数设置,具体见1.2.1中参数说明。

图1 Fishbone型布局相关参数Figure 1 Fishbone layout parameters
1.2 Fishbone仓储设计
1.2.1 假设条件及参数说明
假设条件如下。
1) 仓储为单元式货架仓库;
2) 采用单命令存取方式,即每次存或取一个货物;
3) 每个货位的几何尺寸一致;
4) 存储货物规格与仓储货位尺寸匹配;5) 货物周转率已知。相关参数说明如下。


第7步 计算仓库中每个货位到P&D点的距离,公式如下。

1.2.3 优化模型的建立
参数说明如下。
S:需求倾斜因子;
ε:货位共享因子,0 <ε≤1;
i:第i种货物的序号,周转率较低的货物种类具有较大的序号值;
n:存储系统的分类数量;
k:第k类的序号值,k= 1, 2, ···,n;
ik:第k类中周转率最低货物种类的序号值;
jk:第k类中距离P&D点最远存储位置的序号值,它可表示第1类到第k类所需的总存储货位数量;
N:存储在仓储中货物的种类数;
tk:存储一个货物到k类中或从k类中拣选一个货物的单程平均移动距离;
D(i):第i种货物在一段时间内的需求量;
Tn:n类存储系统中,存/取单个货物的单程平均移动距离。
根据给出的符号,基于n类存储系统的平均拣货距离表示为


目标函数式(28)表示单程平均拣货距离最短;约束条件式(29)表示jk与ik之间的关系;约束条件式(30)表示仓储所提供的货位数量大于或等于存储一定数量货物所需的货位总数;约束条件式(31)表示一个存储类别中至少存储一种货物。
2 Fishbone仓储布局优化方法
2.1 分次逼近策略
Fishbone仓储结构难点在于分拣路径的不确定性会导致拣货距离建模困难。通过将各个货位到P&D点距离进行排序的方式虽可实现模型建立,但是需要每次提前获得最优存储策略下满足要求的最小总货位数量,以此优化dj,从而确定出最优存储分类数量及类别边界,否则会因误差过大导致所求的优化解并非最优。因此,为了解决此问题,本文采用分次逼近策略,步骤如下。
第1步 初始化一个较大的C值,通过式(27)初步获得近似最优的所需货位数量,得到此结构下N种分类中最大的货位数以第1次优化dj;
第2步 利用第1步得到的dj,可以获得此结构下近似最优的货物分类数量n, 并第2次优化dj。
第3步 通过搜寻n+1个类中的最小单程平均拣货距离,从而获得精确的Tn值、最优存储分类数量及每个类别中货物的种类数。
2.2 动态规划算法设计
当n=1或n=N时,可直接 代入式(27)和式(28)计算得出仓储所需货位数量及平均拣货距离,其他情况的求解可通过动态规划算法帮助完成,以获得相应的分类数量及其类别边界。步骤如下。

2.3 基于自适应的遗传算法设计
2.3.1 遗传算法
遗传算法主要用于处理优化问题,然而标准的遗传算法也存在着诸如进化初期存在“早熟”、进化末期难收敛等问题[13]。因此,设计自适应遗传算法(adaptive genetic algorithm,AGA),采用动态自适应策略,对算法的交叉、变异算子进行改进,并且在算法后期插入一个小种群的最优个体,使得算法具备跳出局部最优解的能力。本文以单程平均拣货距离函数的倒数作为适应度函数。
2.3.2 整数编码
整数编码方式无需进行编码和解码操作,能够很大程度上提高解的精度以及收敛速度;便于在大空间内搜索,而且还能避免二进制编码导致的海明悬崖(Hamming cliffs)问题。另外,遗传算法的整数编码策略用于解决离散变量的寻优问题时表现优异[14],基于上述分析,再加上本问题的特征,这里采用整数编码方式。
2.3.3 操作算子
选择算子。选择算子的作用主要是使适应度值高的个体能更大可能性被选中,有更大机会作为父代,从而提高遗传算法的计算效率和效果。选择算子采用轮盘赌法进行个体选择。
交叉算子。交叉算子是遗传算法区别于其他优化算法的本质特征,通过交叉组合的方式产生新的个体,同时也降低了对表现优异父代特征的破坏程度,从而起到全局搜索寻优的效果。采用整数编码的交叉算子可以表示为

2.3.4 自适应策略
Srinivas等[16]提出一种自适应遗传算法,主要是通过适应度值自动改变其中的交叉概率Pc和变异概率Pm。其具体思想体现为当种群个体的适应度值趋于一致时,交叉概率Pc和 变异概率Pm增大,以增强种群跳出局部最优解的能力;而当群体的适应度值相对分散时,Pc和Pm减小,以使种群能够迅速收敛。与此同时,对于种群中一些适应度值高于群体平均适应度值的个体,Pc和Pm较小,使这些个体能进入下一代;而对于低于平均适应度值的个体,Pc和Pm较大,该个体将被淘汰。因此,自适应策略中的Pc和Pm能 够自动匹配最佳Pc和Pm给对应的个体,可以看出,该策略能够实现在保持群体多样性的同时,保证遗传算法的收敛性。本文提出交叉概率Pc和 变异概率Pm计算公式如下。

3 仿真实验
3.1 实验参数设定
设Fishbone型布局仓储主通道和拣选通道的宽度均为1 m,即w=1;仓储中货位是宽深度均为1 m的正方形,we=de=1;I1取 值为[1,50],有t anθ∈[3/50,3];仓储中货物的种类数N=50;这里假定实验的周期是以月为单位,并假定一个月内的货物总需求R=10 000;订货成本与持有成本的比值K= 2;货位共享因子 ε=0.22;需求倾斜因子由大到小分别取S=1, 0.569, 0.317, 0.139, 分别表示 20%的货物量贡献了2 0%,40% , 6 0%,80%的货物需求[11]。
为了验证上述所提算法的有效性,将对基于自适应的遗传算法、文献[17]提出的改进遗传算法以及标准遗传算法进行对比分析及验证。3种算法主要参数设定种群大小为20,进化代数为150代,标准遗传算法以及改进遗传算法的交叉概率为0.7,变异概率为0.01;自适应遗传算法的交叉概率最大值为0.9,最小值为0.6;变异概率最大值为0.1,最小值为0.01。
3.2 仿真结果
图2给出需求倾斜因子S=1时,基于自适应遗传算法、改进遗传算法以及标准遗传算法的平均移动距离变化曲线。三者前期逐步跳出局部最优解,基于自适应遗传算法相比于改进遗传算法和标准遗传算法,收敛速度和最优值搜寻表现更为优异,能够更有效地找到最优解。

图2 单程平均移动距离随进化代数变化规律Figure 2 The law of change of average moving distance
由图3可知,除S=1外,多个ABC需求倾斜因子的最优单程平均移动距离都随着分类数量的增加先减小后增加,且在最优类附近的平均拣货距离对分类数量的变化不敏感。此外,在考虑货位共享效应的前提下,基于分类的存储策略在拣货距离上表现优于全周转率的存储策略。

图3 平均移动距离变化曲线Figure 3 Change curve of average moving distance
表1给出4种需求倾斜因子所对应的最优分类数量及每个类别的货物种类数。在实际运用时可参考此表中的分类数量及相应的类别边界进行货物的分类存储,以获得成本优势。

表1 最优分类数量及每个类别的货物种类数Table 1 The optimal number of categories and the number of categories of goods in each category
由表2可知,随着需求倾斜因子的减小,平均拣货距离是减小的,所需的货位数量也有着减少的趋势。说明当仓储存储的货品需求差异变大时,考虑货位共享效应的优势就越明显,可以带来更多的成本节约。
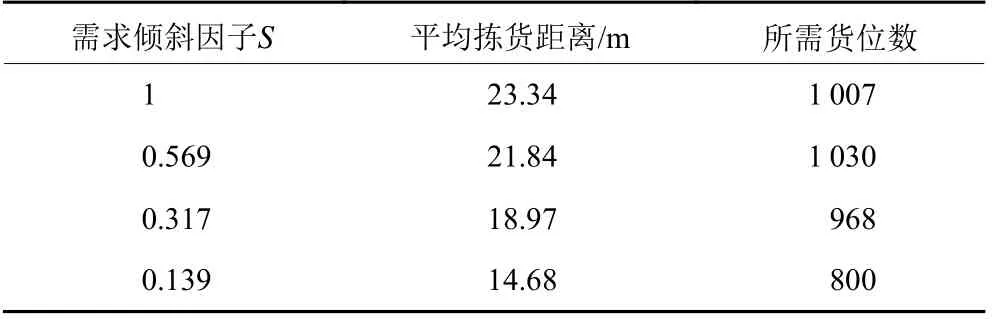
表2 最优分类时的最优目标函数值Table 2 The optimal objective function value for optimal classification
通过表3可知,Fishbone布局在不同的S参数值下,仓储的最优结构相差不大,仅是货架行的数量由于所需货位数量不同而不同。因而当货物需求发生改变时,仓储的原有布局结构同样可以获得较为理想的结果。

表3 获得最优目标函数值时仓储的布局参数Table 3 The layout parameters of the warehouse when the optimal objective function value is obtained
4 结论
本文在Fishbone布局中考虑货位共享效应,以单程平均货物拣选距离最短为目标,提出分次逼近策略,并设计动态规划算法与自适应遗传算法;探讨随机、基于分类以及全周转率的存储策略对仓储布局的影响。结果表明,在考虑货位共享效应的前提下,Fishbone仓储布局中基于分类存储策略的拣货距离优于全周转率策略,且最优分类的数量较少,最优分类数附近的平均拣货距离对类的变化不敏感;而且,货品的需求倾斜因子S越小,使用基于分类存储策略就越有效,函数目标值就越小,可带来的成本优势就越显著,基于以上4种需求倾斜因子,最高可缩短37.1%的单程平均货物拣选距离。此外,根据本文所提方法设计的仓储,当货物需求发生变化时,原有的仓储结构仍然适用。
本研究今后探讨双命令模式下的布局设计方法;以及解决具有多个P&D点的Fishbone仓储布局设计问题。
