基于嵌套生成对抗学习的网络嵌入
2022-11-09沈鹏飞
沈鹏飞,徐 臻,王 英
(1.中国电子科技南湖研究院,浙江嘉兴 314001;2.吉林大学计算机科学与技术学院,吉林长春 130012)
1 引言
信息实体数量不断增加导致信息数据极速增长,从如此海量数据发掘有价值信息,则需对数据进行合理整合才能高效分析[1~3].由于网络结构具有融合不同信息实体和关系的天然优势,已成为大数据分析的重要数据结构,且在数据挖掘和人工智能的相关研究中,无不对数据特征精确提取和分析,但随着信息维度不断增加,数据网络结构也会变得异常复杂,网络嵌入将很好为这两项研究做好基础工作[4~6].网络嵌入的研究目标就是将高维复杂的信息网络用低维向量表示,且低维表示包含的有效信息越多,则嵌入越成功,可应用于的任务也更多[7~9].
在当前网络嵌入的研究中,大部分工作都是更多考虑网络结构特征和结点之间的近似关系.但信息网络中不只表达结点结构,还包含了大量潜在信息,如结点局部关系和自身属性等.针对以上情况,本文借鉴生成对抗学习思想提出了一种嵌套的生成对抗网络模型N-GAN(Nesting Generative Adversarial Networks for Network Embedding),将网络结构、结点对近似关系以及结点属性信息,通过一个三级对抗模型逐级学习,将不同特征信息嵌入在一个低维的表示中.由此不仅将网络结构和结点对的近似关系嵌入在低维表示中,还将结点属性特征也嵌入到表示向量中,从而保留了原始网络更丰富的数据信息[10~12].N-GAN模型中第一级生成对抗模型学习保存网络的结构特征,在第一级模型基础上第二级对抗网络学习结点对属性信息,第三级网络在前两级基础上学习结点局部特征信息,每一级都是确保上一级特征充分学习的基础上再学习新的特征信息,从而使得不同特征信息平滑融入低维表示向量中.本文主要做了以下三方面的工作:
(1)根据信息网络的结构数据以及结点的属性,依次计算了结点对的三级特征,作为嵌入模型学习数据.
(2)借鉴生成对抗网络的思想,通过嵌套的方式提出一个三级组合的生成对抗网络结构N-GAN,并且详细给出了模型的运算理论和各个子模型的网络结构.
(3)在真实数据集上设计了多组实验,与相关模型进行了比较分析,验证了N-GAN算法性能,并讨论了算法稳定性及效率.
2 相关研究
当前网络嵌入的研究大致可以划分为两类,分别为基于关系矩阵分解[13]和基于深度神经网络方法.关系矩阵一般是网络结点的邻接矩阵、拉普拉斯阵、PPMI(Positive Pointwise Mutual Information)矩阵,基于关系矩阵的网络嵌入的研究应该可以追溯到很早,从谱聚类算法到矩阵的非负分解都是将高维的网络用低维向量表示.矩阵分解主要是针对邻接矩阵和PPMI矩阵,文献[14]通过对社交网络中结点间邻接关系矩阵的非负分解得到网络的低维向量表示,从而预测用户之间的信任关系.Cheng等人[15]借鉴矩阵分解的思想对符号社交网络提出一种非监督的特征提取方法,实现了在符号网络中结点低维表示之间的近似关系与高维网络中一阶近似和二阶近似相一致.Wang等人[16]提出通过最优化矩阵的非负分解模型同时实现网络结点的社区发现和网络表示,实现结点的低维表示可以同时保存网络的局部结构和社区结构.Qiu等人[17]发现了Deepwalk[18]产生的隐式矩阵和Laplace图之间新的理论联系,并且指出Deepwalk,LINE(Large-Scale Information Network Embedding)[19],PTE(Predictive text embedding)[20]和node2vec[21]本质上是隐式的矩阵分解.但是随着网络规模的增加,矩阵分解的时空复杂性会限制算法效率.
在以往的研究中,神经网络模型大致可以分为生成模型和辨别模型.Goodfellow等人[22]创造性地提出了生成对抗网络GANs(Generative Adversarial Nets),将生成模型和辨别模型结合起来,形成一个统一的对抗学习模型.Mirza等人[23]在GANs的基础上对目标函数做了改进,提出了一个基于条件概率的生成对抗网络模型(Conditional Generative Adversarial Nets,CGANs).Tolstikhin等人[24]通过训练权值和弱生成器的方式提出一种新的生成对抗模型AdaGAN(Adaptive GAN),Ada-GAN模型每次都是由上一次的弱生成器和训练好的权值以加权的方式产生新的生成器.Arjovsky等人[25]用Wasserstein距离代替传统生成对抗网络中的KL散度,提出了WGAN(Wasserstein GAN),WGAN成功解决了传统生成对抗网络梯度消失、训练不稳定、模式崩溃等缺点.Mao等人[26]通过在对抗训练的目标函数中使用最小二乘法提出了LSGAN(Least Squares Generative Adversarial Networks),LSGAN不仅克服了训练过程不稳定,梯度消失的缺点,且LSGAN收敛速度更快.
3 数据分析
本文收集了三个真实数据集:arXiV-AstroPh、arXiv-GrQc、Cora.arXiV-AstroPh是在arXiv在线电子版上一个关于论文作者之间的科研合作关系的网络.arXiv-GrQc是arXiv上关于广义相对论和量子宇宙学范畴的论文作者之间的科研合作关系网络.Cora数据集包括两部分:一部分是论文之间的引用关系,另一部分是论文的类别数据,每一篇论文都有一个类别标签.arXiVAstroPh和arXiv-GrQc的相关统计信息如表1所示,Cora相关统计信息如表2所示.
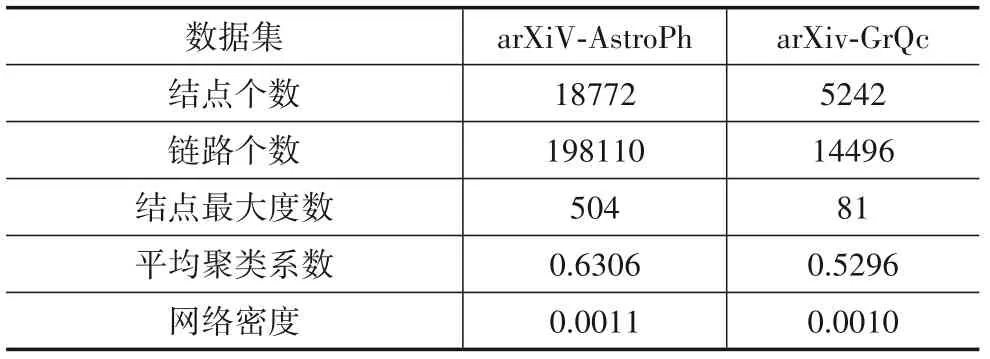
表1 数据集arXiV-AstroPh和arXiv-GrQc信息统计
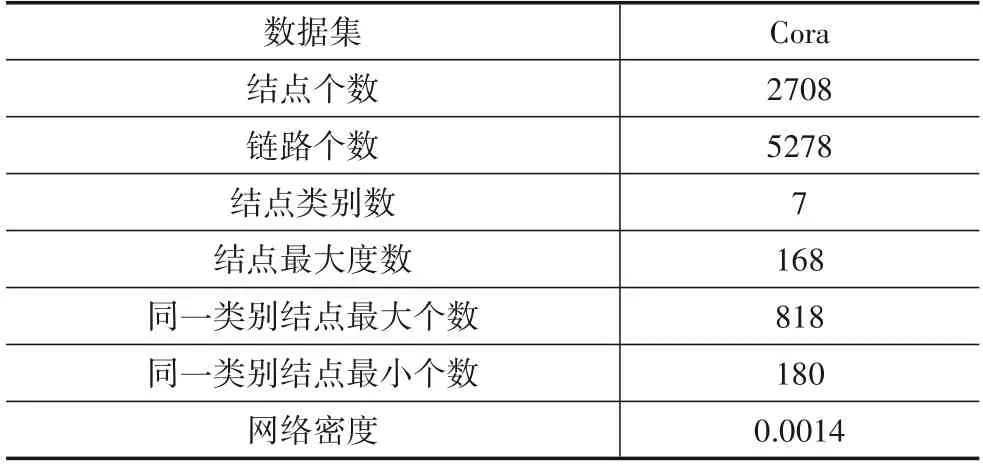
表2 数据集Cora信息统计
本文对数据集做了简单的预处理,首先只关注不同结点之间的联系因此删除了有自环的链接,其次为了确保结点在网络中有足够的结构信息,本文删除了没有链接和只有一条链接的结点.由表1和表2可以计算出arXiV-AstroPh和arXiv-GrQc中平均每个结点分别有10.55和2.77个链接,在Cora中平均每个结点有1.95个链接.三个数据集的网络密度分别是0.0011、0.0010、0.0014.
4 问题定义
网络结构的组成元素就是结点和边,本文用G={V,E}表示网络,其中V={v1,v2,v3,…,vn}是结点的集合,E={e12,e13,…,eij,…,enx}是网络中所有边的集合.网络嵌入的目标就是通过嵌入算法将网络信息投影在一个低维的空间,网络嵌入的研究问题可以如式(1)所示:
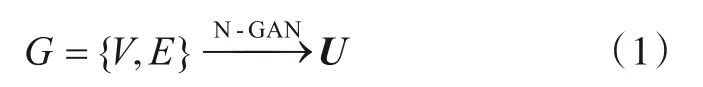
其中,U∈Rn×d,d是嵌入维度且d<n,U表示网络G的低维表示.
5 N-GAN模型
为了能对N-GAN模型有一个直观的了解,N-GAN模型的架构如图1所示.
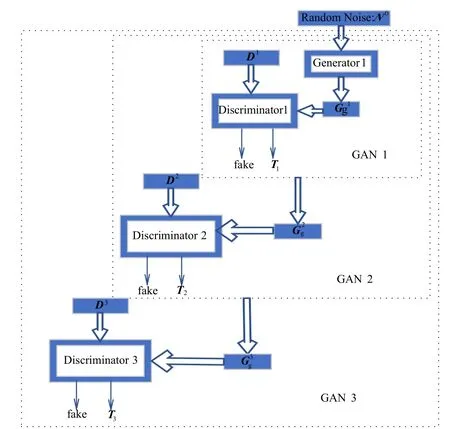
图1 N-GAN模型架构说明图
由图1可知,N-GAN模型通过嵌套组合的方式构成一个大的生成对抗网络,并且其中的每级内部也是一个生成对抗结构.整个模型中只有一个生成器,三个辨别器分属于三个对抗网络,其中GAN1、GAN2、GAN3分别表示三个生成对抗网络.三个辨别器分别学习不同的网络特征,其中D1、D2、D3表示三个辨别器的真实输入数据,Gg1、Gg2、Gg3表示生成器网络在三次递进学习过程中的生成数据.
5.1 N-GAN模型工作原理
N-GAN模型中生成器网络逐级学习,每一级的辨别器只学习信息网络的一个特征.生成器首先和第一级的辨别器对抗学习,生成器不断调整使得生成数据的分布接近网络的第一特征,然后再和第二级对抗网络对抗学习,以此使得生成器逐步融合网络结点对不同属性特征.
首先介绍GAN1网络的结构和工作原理.网络结构是网络嵌入首要考虑的重要特征,因此将N-GAN的第一级生成对抗网络用于学习网络的结构特征.为了表示网络结点对之间的结构信息,本文通过结点对之间的最短路径表示了结点对关系矩阵XS如下所示:

其中,sij表示网络中结点i和结点j之间的最短路径.很明显结点对之间最短路径越小,XS矩阵中对应的元素值越大.生成器网络中,本文首先从网络全局角度计算结点对余弦相似度表示低维空间中的邻近程度.生成器目标就是将生成结点的低维表示之间的相似度分布无限接近XS.在GAN1中比较特殊的是D1和T1都等于XS.为了避免传统生成对抗网络训练不稳定导致的模式崩溃,本文选择了Wasserstein距离计算数据分布差异.如果将生成器和辨别器分别表示为参数化函数G(·)和D1(·),则GAN1的目标函数可定义如下:
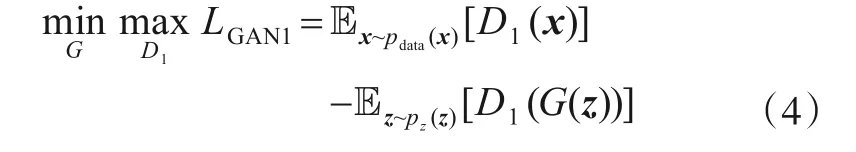
其中,x表示真实数据,z表示生成数据样本,初始为随机数据.由此可见随着G(·)和D1(·)之间不断的对抗学习,生成器生成结点的表示数据基本保留了结点对在网络中的邻近关系,即N-GAN模型通过GAN1网络保存了网络的结构信息.
本文基于结点关系矩阵XS和结点对相似性定义了一个结点对近似关系矩阵NP,计算如式(5)~(7)所示:
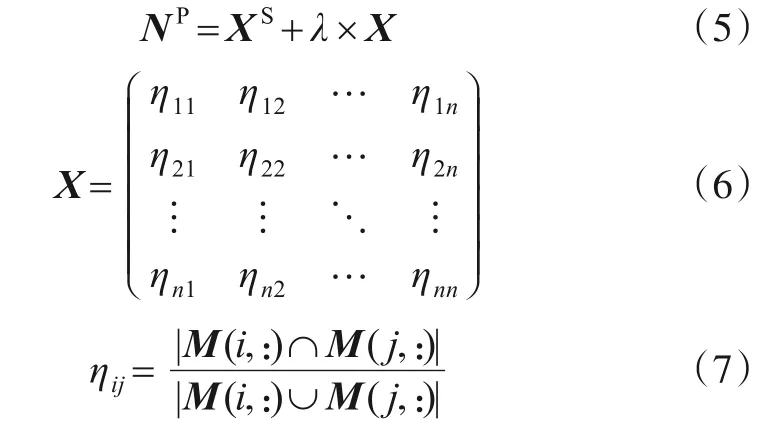
其中,M为结点邻接矩阵,式(7)的分子部分表示结点Vi和Vj的共同邻居的数目,分母部分表示两结点所有邻居的数目,λ是一个超参数取0.25,用于调和XS和X之间关系,希望能更合理反映结点对之间的近似关系.相关研究发现网络结点的度是一个重要属性,对于反映结点相关特征具有积极作用[27],本文在NP基础上加入结点的属性定义了XSim,如下所示:
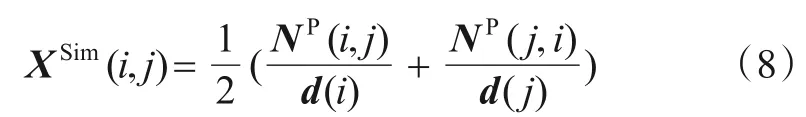
其中d(i)表示结点Vi的度.由此可见XSim中元素值是在对应的结点对直接近似和间接近似的基础上加入了结点度的影响,通过结点度数调节结点对之间的近似关系.
随着生成器在GAN1中训练,逐渐学习了网络的结构特征,N-GAN模型希望在保证生成数据保留结构特征的前提下继续学习新的特征.因此将XSim作为网络结点对的新的特征,通过GAN2将生成器和第二级辨别器对抗学习,其中第二级辨别器的输入D2为XS,输出T2为XSim.这是因为经过GAN1的训练之后,生成器生成的数据分布接近于XS,所以第二级辨别器目的就是学习从XS到XSim的映射,从而在对抗学习的过程中促进生成器在保证满足上一级网络的基础上生成具有XSim特征的表示.如果将经过GAN1训练好的生成器函数表示为G1(·),第二级辨别器函数表示为D2(·),则GAN2的目标函数可表示为:
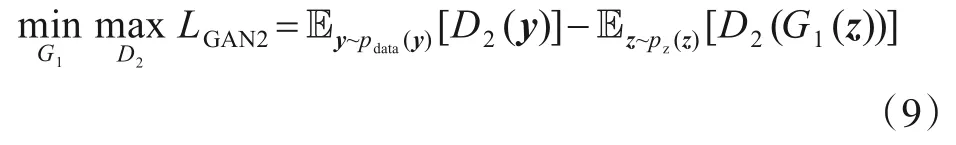
其中,y表示真实数据XS,D2(y)是辨别器学习到的数据,z表示生成数据样本.
生成器经过前两级对抗训练,逐步学习了网络结构特征和具有结点属性的近似关系.但结点之间的关系衡量不能单纯的依赖结点对之间的最短路径,根据物以类聚,人以群分的特点,考虑这样一种情况,如果结点Vi有六个邻居结点,其中五个邻居结点聚集更密集,另外一个结点相对疏远,则结点Vi向五个密集邻居结点靠拢的可能性更大.本文计算了每个结点被其邻居结点的吸引程度,吸引力越强,则两个结点之间的关系越亲密.为定义这种邻居结点的吸引力,假设任意结点Vi的邻居结点表示为NVi={Via,Vib,Vic,Vid}.为了计算各个结点对结点Vi的吸引程度,本文首先计算每一个邻居结点与其他所有邻居的结点的邻近程度,以结点Vib为例,假设用pb表示Vib与其他所有邻居结点的邻近量,计算方法如下:
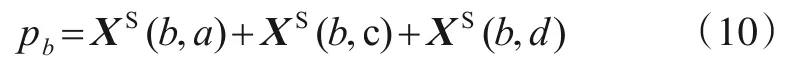
计算pa,pc,pd的方法和式(10)类似.由此可得结点Vi的邻居结点与其余邻居的邻近量表示为PVi=(pa,pb,pc,pd),根据该向量本文定义了不同邻居结点对结点Vi的吸引程度,假设grav(i,b)表示结点Vb对结点Vi的吸引程度,则计算如下:

计算其他邻居结点对结点Vi的吸引程度与此类似.由此本文结合网络结点的邻接矩阵XD定义了一个邻居结点吸引力矩阵Y,具体如下:

其中φ是超参数,为0.5,本文结合矩阵Y和XSim定义了网络中结点之间的聚集程度,用矩阵XJ表示,其中XJ的计算如下,⊙表示矩阵的Hadamard积.

在第三级生成对抗网络中,第三级辨别器的输入D3为XSim,输出T2为XJ.通过生成器和第三级辨别器的对抗学习,使得第三级辨别器学习从XSim到XJ的映射,从而使得生成器生成结点数据分布在满足前两级特征的基础上不断接近XJ.如果将经过GAN2训练的生成器表示为G2(·),三级辨别器表示为D3(·),则GAN3的目标函数可表示为:

其中,w表示真实二级特征数据XSim,D3(w)是辨别器学习到的数据.
根据以上过程可知,随着每一级的生成对抗网络的嵌套,生成器学习能力逐级递增,最终生成的低维表示融合了更丰富的网络特征数据.
5.2 N-GAN算法描述
上文对N-GAN设计结构和运行原理作了详细介绍,本节将对N-GAN算法运行过程进行描述,具体如算法1所示.
从算法过程可以看出N-GAN模型将生成器嵌套在三个生成对抗网络中,逐级学习,并且每一级学习新的特征的过程总是一个平滑过渡,最终将三个特征矩阵的信息融合在低维表示中.
5.3 实验验证
为验证N-GAN模型的有效性,本文选择了两个应用:链路预测和网络可视化,同时选取七个方法模型作为对比.本文将对比模型和N-GAN对同一数据集进行嵌入计算,然后将不同模型计算的低维表示应用在实验任务中,通过实验结果分析算法性能.
Deepwalk:首个在网络嵌入时将网络结构通过随机游走转换成结点序列,并且利用Skip-gram学习结点的低维表示.
LINE-O1:提出了计算结点对之间相关近似的方法.LINE-O1是基于结点之间的一阶近似的LINE.

算法1 N-GAN输入:λ,超参数,lr,学习率,k,嵌入维度,h,批量数,结点对关系矩阵XS,XSim和XJ,NO,随机数据,T,辨别器网络的训练次数.m,模型训练迭代数(epochs)输出:生成器G(θG),辨别器D1(θD1),D2(θD2),D3(θD3)1:随机数据初始化参数θG,θD1,θD2,θD3 2:for epoch=1:m do 3: 生成器生成数据↦Gg 1 4:XS中按批量抽取结点的关系数据5:Gg 1中按批量抽取结点的生成数据6:极小极大化Ex~pdata(x)[D1(x)]-Ez~pz(z)[D1(G(z))]更新参数θG和θD1 7:更新后的生成器,生成数据↦Gg 2 8:XS中按批量抽取结点的关系数据9:XSim中按批量抽取结点的关系数据10:Gg 2中按批量抽取结点的关系数据11:极小极大化Ey~pdata(y)[D2(y)]-Ez~pz(z)[D2(G1(z))]更新参数θG和θD2 12:更新后的生成器,生成数据↦Gg 3 13:XSim中按批量抽取结点的关系数据14:XJ中按批量抽取结点的关系数据15:Gg3中按批量抽取结点的关系数据16:极小极大化Ew~pdata(w)[D3(w)]-Ez~pz(z)[D3(G2(z))]更新参数θG和θD3 17:结束for循环18:生成低维表示
LINE-O2:类似于LINE-O1,通过保存结点之间的二阶近似实现网络嵌入.
struc2vec[28]:通过计算网络中结点之间的空间结构相似性实现网络结点的低维嵌入.
GAN1:N-GAN嵌套模型中第一级生成对抗网络.
GAN2_a:N-GAN嵌套模型中二级嵌套生成对抗网络,其中第一级辨别器学习特征XS,第二级辨别器学习特征XSim.
GAN2_b:N-GAN嵌套模型中二级嵌套生成对抗网络,其中第一级辨别器学习特征XS,第二级辨别器学习特征XJ.
需要说明的是所有网络层均选用leaky ReLU激活函数,其中leak值为0.2,嵌入维度d设置为128,所有网络模型的优化器都为“Adam”,学习率lr设置为0.001,超参数λ和φ分别设置为0.25和0.5.为了保证结果的可靠性,实验重复5次取平均值.
5.3.1 链路预测
链路预测是信息网络研究中的一个重要应用,通过预测结点之间可能发生的关系链路,对舆情监测、社区发现和精准推荐等任务具有很大帮助.本文将数据集arXiV-AstroPh和arXiv-GrQc作为链路预测实验数据.实验准备时,将实验数据网络中20%的边隐藏起来作为需要预测的链路,所有模型根据已知的80%的链路信息将网络嵌入在低维表示空间.在求得网络低维表示后,本文选用最简单分类器KNN(k-Nearest Neighbor)作为链路预测工具.在链路预测前将所有结点对的低维表示相减取绝对值,作为KNN分类器的特征输入,KNN的输出就是对应结点对的标签数据,其中KNN参数设置邻居个数为2.为了使预测结果更可靠,本部分选用了10折交叉验证,每次对10折验证结果求平均,并通过准确率和F1-macro两个指标定量分析不同模型的嵌入效果.N-GAN和各个对比模型根据上述方法,在两个数据集上链路预测结果如表3和图2所示.
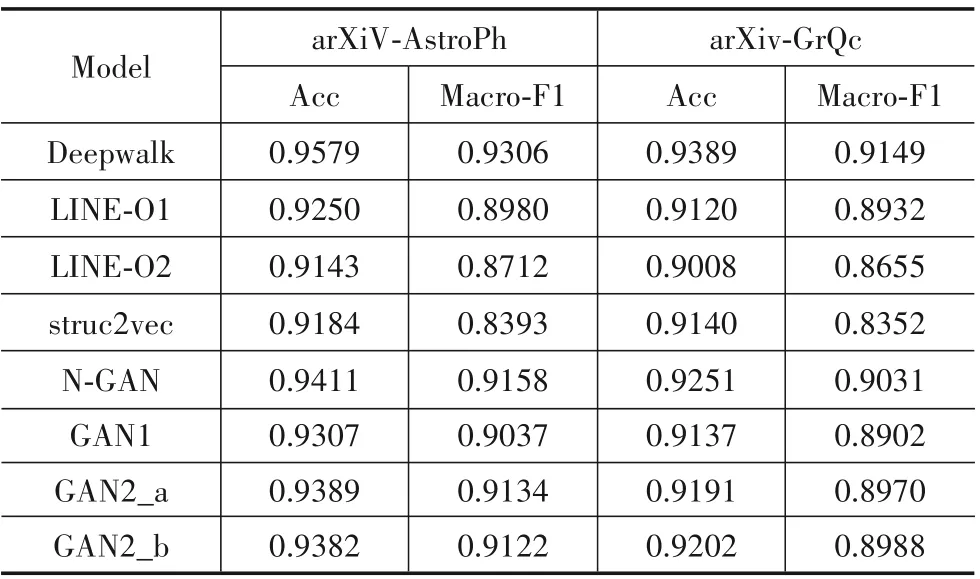
表3 数据集arXiV-AstroPh和arXiv-GrQc上链路预测结果

图2 不同模型嵌入向量的链路预测分布
根据以上结果可以清楚的观察到,N-GAN模型计算的低维表示向量在链路预测的任务表现出了相对不错的性能.在两个数据集中预测准确率分别到0.9411和0.9251,F1-macro分别达到0.9158和0.9031.N-GAN计算的低维表示在链路预测时的准确率平均比GAN1高0.0109,比GAN2_a高0.0041,比GAN2_b高0.0039,比LINE-O1高0.0146,比LINE-O2高0.0256,比struc2vec高0.0169;F1-macro指 标 平 均 比GAN1高0.0125,比GAN2_a高0.0043,比GAN2_b高0.0040,比LINE-O1高0.0139,比LINE-O2高0.0411,比struc2vec高0.0722.同时可知N-GAN结果优于GAN2_a、GAN2_b两个二级嵌套模型,GAN2_a、GAN2_b的结果又优于GAN1,因此可以证明经过嵌套学习三级特征保存了相对较多的有效信息.
5.3.2 网络可视化
网络可视化是检验网络嵌入算法有效性的另一个重要应用.本文在Cora数据集中选择了三个类结点作为本部分实验的验证数据,且选用PCA作为降维工具.可视化结果如图3所示,其中图中红色菱形表示“强化学习”,绿色三角形表示“基于案例”,蓝色星号表示:“理论”.
由图3可直观的观察到三类结点不同模型计算的低维表示的分布,很明显GAN1、GAN2、N-GAN三个模型计算的结点的表示向量具有相对更好的质量,但图3(d)、(e)两个子图在同类节点的集中程度和不同类别结点的疏远程度都没有N-GAN效果好.从图3(f)子图可以看出,三类结点分布在三个区域,并且同一类别相对集中,不同类别的结点在显示空间中相对较远.在这项任务中.从图3(a)子图可以看到Deepwalk基本将不同类别的结点集中在一起,但是“基于案例”和“理论”两个类型的结点重合较多.LINE-O1计算的表示向量相比Deepwalk有较好的表现,将三类结点很好的分布在三个区域,但是三个区域的接壤部分重合太多,各类别结点也不够集中.
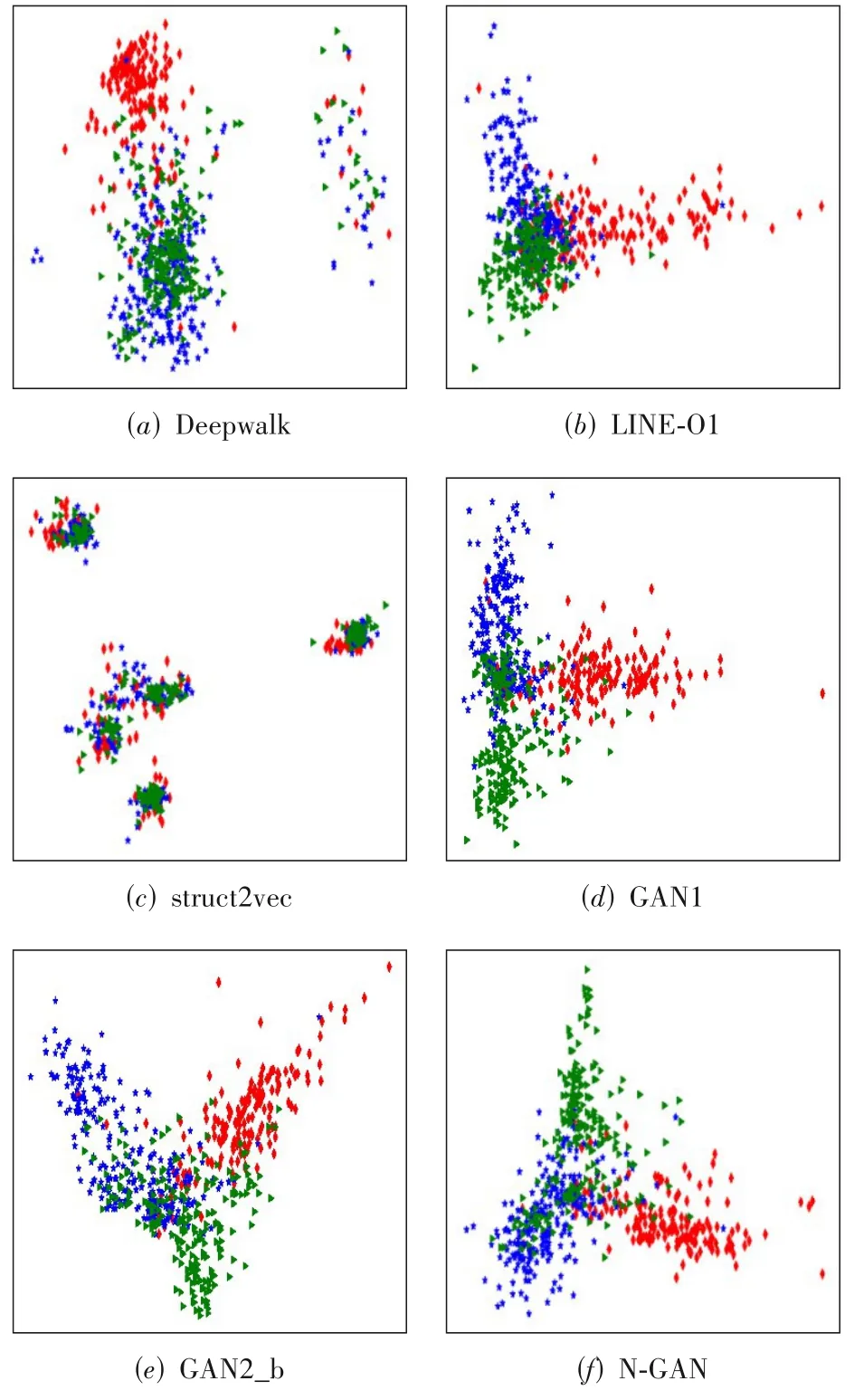
图3 可视化结果
5.3.3 参数设置
深度网络模型在训练过程中,参数选择会成为影响模型性能的关键因素.为解释N-GAN中相关参数的选择过程,本部分以链路预测为例,设置了多组实验验证不同参数取值对模型性能的影响.N-GAN模型中主要有φ和λ两个超参数和迭代轮次epoch.因篇幅有限,此部分以φ的选择过程为例,λ过程类似.为了探究不同的φ值在不同训练次数下对N-GAN的性能影响,本文将N-GAN中epoch分别设置为{50,150,250,500},φ分别设置为{0.01,0.1,0.3,0.5,0.7,1.5},在两个数据集上链路预测结果如图4所示.当epoch从50增加到150时,不论φ取何值,N-GAN模型的性能都明显变好,这说明随着训练深入模型得到了充分的学习.当epoch继续增加,N-GAN嵌入能力也在逐步改善,但幅度不大.不考虑epoch影响,当φ从0.01增加到0.5时,N-GAN模型的性能在逐渐变好,但φ大于0.5之后,模型的性能有所下降,因此综合两个数据集考虑运行时间和算法性能,本文将迭代轮次epoch和φ分别取值250和0.5,使模型效率达到相对最优.

图4 超参数φ性能影响分析
5.3.4 算法收敛性及效率分析
由上文可知N-GAN模型是一个嵌套的生成对抗网络,随着三级网络的嵌套,很明显增加了N-GAN网络模型的深度,本节通过分别分析三级网络的收敛性,讨论N-GAN算法整体的收敛性.为了直观的展示各个生成对抗网络的收敛性,以迭代次数为横轴,三级网络的目标函数误差损失值为纵轴,分别对三级网络作图,如图5所示.GAN1随着迭代次数不断增加,函数损失值不断降低,收敛性并不是很好,这是为了同时观察三级网络的收敛情况,此部分迭代次数设置较少,在实际实验过程中,当迭代次数超过200后GAN1误差损失的变化范围将维持在一个非常小的范围.GAN2当迭代次数从1增加到20时函数损失值缓慢降低,当迭代次数超过20后GAN2的误差损失基本趋于稳定.GAN3(相当于N-GAN)在迭代次数从1增加到25时函数损失值降低较快,当迭代超过25次后GAN3的误差损失趋于稳定.综上所述,本文提出模型N-GAN在总体上保持了良好的收敛性,确保了算法运行的稳定.
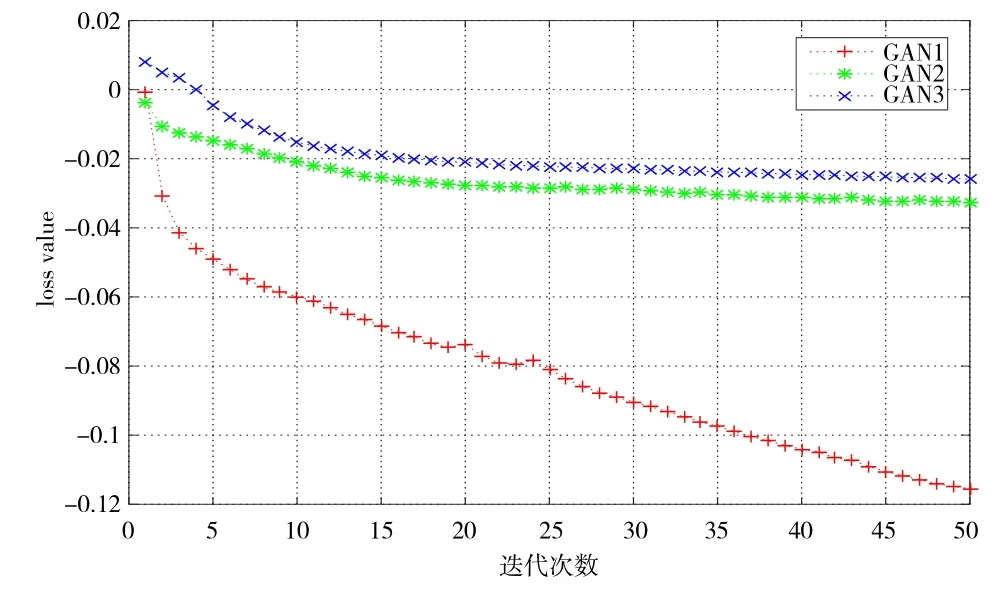
图5 N-GAN算法收敛性分析
由于神经网路训练参数较多导致训练时间较长,本文模型通过一种嵌套得方式增加了训练深度,导致N-GAN在运行效率上有所下降.为探究嵌套模型运行效率,本文统计了GAN1、GAN2、GAN3多组迭代轮次的训练时间,如图6所示.从图6可知,随着嵌套加深,模型时间复杂度在逐级增加,因此嵌套级数的选择不能无限制叠加,需要综合考虑性能和效率,增强模型实用性.
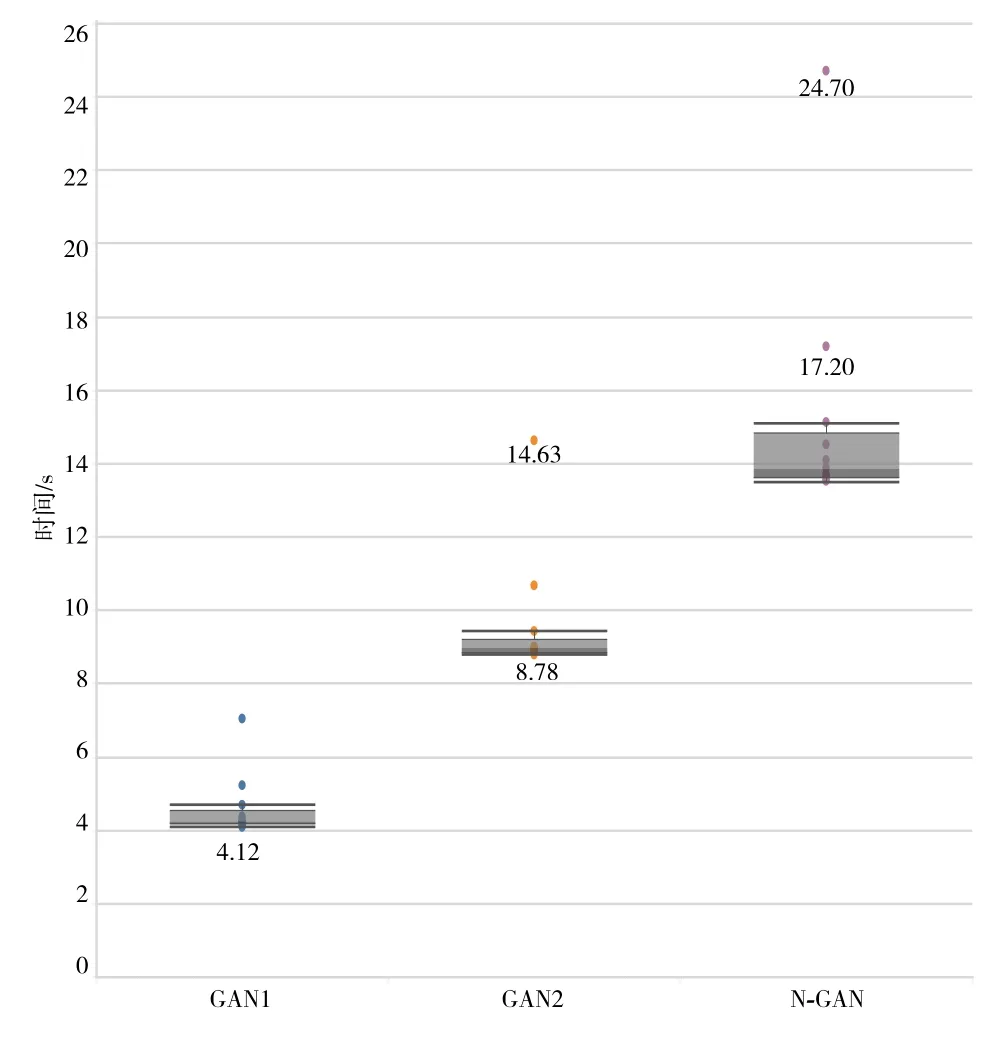
图6 模型运行时间分析
6 结束语
本文提出一种嵌套的生成对抗结构,通过嵌套的方式将三个生成对抗网络组合起来,形成一种新的生成对抗学习结构N-GAN.在N-GAN中每一个子模型内部是对抗学习,模型与模型之间也是对抗学习,由此实现了逐级学习网络不同特征信息,最终将不同特征信息平滑融合在低维表示中.本文在真实数据上根据两个应用任务设计了多组实验,验证了N-GAN算法的有效性.在下一步研究中,将结合生成对抗学习模型和强化学习,进一步提高网络嵌入模型效率.
