基于生成对抗网络的情感语义描述与生成*
2022-11-09刘仲民周志亮
刘仲民 周志亮
(兰州理工大学电气工程与信息工程学院 兰州 730050)
1 引言
图像语义描述[1~2]是涉及计算机视觉[3]与自然语言处理[4]的交叉学科,具体任务是指让计算机识别图像中包含的信息,并将该信息用文本语言描述出来。该学科是许多重要应用的基础,如帮助视障人士感知周围环境,使人机交互更加智能化等。
早期的图像语义描述主要使用基于检索的方法和基于模板的方法,主要代表有Ordonez等[5]和Kulkarni等[6]提出的方法。
随着人工智能的发展,深度学习的优越性也逐渐展现出来,使图像描述进入一个崭新的阶段。Vinyals等[7]提出了谷歌神经图像描述模型(Neural Image Caption,NIC)做文本描述,在编码阶段采用Google Net,解码阶段采用长短期记忆模型(Long Short-Term Memory,LSTM),取得了不错的效果。此后图像语义描述基本都围绕编解码框架展开。后来随着注意力机制的出现,被广泛应用在神经网络之中。在图像描述中主要代表有Xu等[8]和Li等[9]提出的方法。
虽然编解码框架被广泛应用于图像描述,但是这种方法容易产生梯度爆炸和梯度消失的问题。而且在解码阶段生成语句使用的方法为最大似然估计法,下一个生成的单词依靠前一个单词,容易产生偏差,如果前一个单词产生一个偏差,那么会累积到下一个单词上,通过不断累积,那么最后生成的单词越来越差。而基于生成对抗网络的图像语义描述很好的解决了上述问题。Dai等[10]提出Conditional GAN模型,通过对初始化生成器LSTM隐藏层向量方差的控制,对图像生成多个描述。Shetty等[11]也将Conditional GAN用在图像描述中,在输入项中增加了目标检测的特征,使用。Zhang等[12]提出两个GAN组成的网络,其中一个用来绘出背景的分布,产生一个图像,另外一个用来结合描述语句。
综上所述,目前对于语义丰富性的研究仍在早期阶段,虽然生成对抗网络已经应用到了图像描述中,但是丰富性和准确性还有待提升。基于此,本文使用生成对抗网络来搭建图像描述模型,为了使生成图像的语句更加具有丰富性,在其中加入语料库Senticap[13]来训练模型;为了使提取图像特征更加充分,加入注意力机制模型。
2 图像的语义描述模型
为了建立图像语义描述模型,采用图1所示结构,主要包括生成器和判别器两个部分,其中生成器用来生成描述语句,用来欺骗判别器;判别器用来判断该描述语句是真实的还是虚假的,同时也会输出一个0~1之间的评分,该评分还会作为奖励输出到生成器,激励生成器继续训练。

图1 基于生成对抗网络的结构图
2.1 生成器部分
生成器部分主要用来生成描述语句,该描述语句会在判别器网络中进行判别,本文中生成器部分主要包括特征提取部分、注意力机制以及LSTM部分。生成器部分如图2所示。
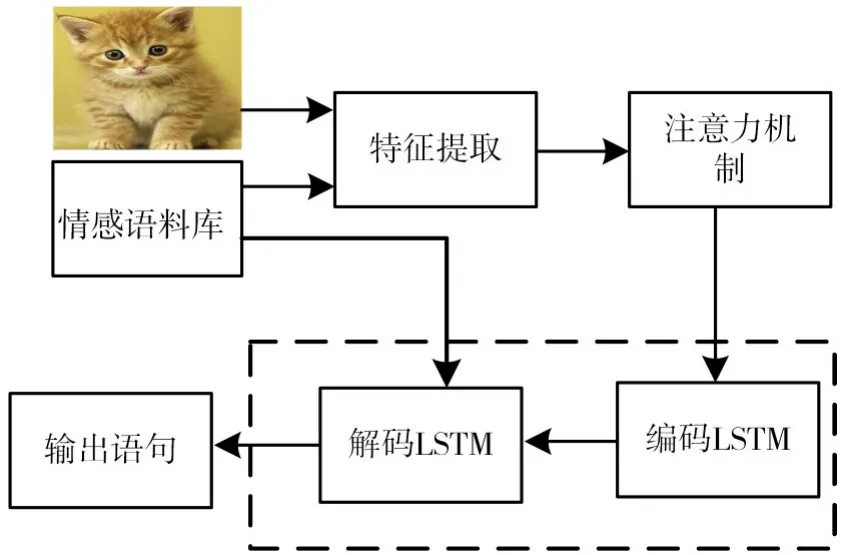
图2 生成器部分
2.1.1 特征提取
目前提取图像特征最重要的工具之一是深度卷积神经网络,其中ResNet(Residual Neural Network)在ILSVRC2015比赛中取得冠军,在top5上的错误率仅为3.57%,同时参数量比VGGNet低,效果非常突出。ResNet的结构可以极快的加速神经网络的训练,模型的准确率也有较大提升。因此本文使用ResNet101作为图像的特征提取网络。
2.1.2 注意力机制
尽管神经网络在图像处理方面有很大的优势,但是在特征提取方面无法区分特别关注点和一般关注点,对于一些需要重点去关注的对象和区域,应该尽可能的去保留其特征。注意力机制很好的解决了该问题,传统的注意力机制只考虑了通道方面或者空间方面,因此本文使用卷积块注意力机制模型 (Convolutional Block Attention Module,CBAM),该方法很好地将通道注意力机制和空间注意力机制进行了融合,模型结构如图3所示。

图3 注意力机制模型
通道注意力机制如式(1)所示,其中MLP(MultiLayer Perceptron)表示多层感知机,AvgPool表示平均池化,MaxPool表示最大池化,σ表示激活函数,W1和W0表示两层卷积层。空间注意力模型如式(2)所示,将通道注意力机制生成的特征图作为空间注意力模型的输入,将该特征图进行平均池化和最大池化,然后进行通道拼接,再经过7*7卷积操作和激活函数激活,最后生成输出模型。
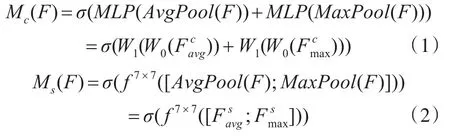
2.1.3 LSTM部分
经过注意力机制处理后的图像特征向量如式(3),vi是图像特征向量中某一位置的图像特征,其中i={1,2,…,n};n代表图像特征的个数。
该图像特征向量将会送到LSTM编码部分并学习序列之间的相关性,然后在编码LSTM中运用极大似然估计法,对每个可能出现的单词的概率进行预测,概率最大的单词则被索引到下一个LSTM中。计算过程如式(4)和(5)所示。其中c0和h0是初始化的网络输入值,finit,c和finit,h为单层感知机计算函数,vi代表图像的特征,n则代表图像特征的个数。
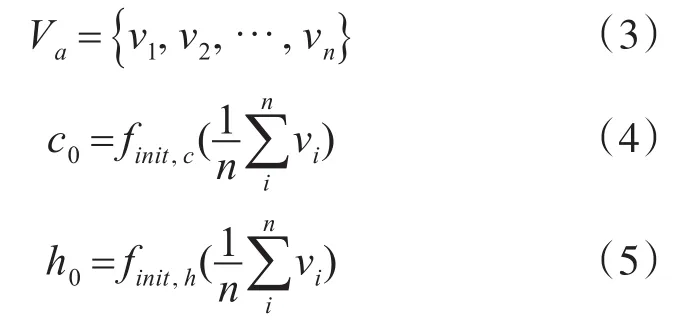
在LSTM解码部分,输入填充的情感语句并且进行学习,引导LSTM生成带有情感色彩的描述语句。在LSTM解码部分将编码LSTM的输出、上下文向量、先前生成的单词等进行相加,最后得到一个关于情感描述语句单词的输出。
2.2 判别器部分
判别器部分的主要作用是将生成器部分的生成语句进行判别,并反馈一个奖励值给生成器,该值介于0~1之间,越接近0,证明生成语句越虚假,越偏离真实语句;越接近1,证明生成语句越接近真实语句,描述效果较好。
目前卷积神经网络在建模时普遍存在参数多,网络层数深,缺少局部的等变特性,随着网络层数的增多也会出现泛化能力降低的问题,基于此本文在判别器中用胶囊网络(Capsule Networks)对句子进行重构和概率预测,重构后的句子与图像在语义上一致,该网络有助于对特征之间的关系进行编码。重构完的句子会在判别器的作用下生成奖励值,并反馈给生成器。
3 实验设置
3.1 数据集
数据集采用 MS COCO[14]数据集,该数据集的每个图像至少有五个标题。实验中,以标签中最长的语句作为参考,设置句子长度为40,将不够40的语句用<pad>进行填充,训练开始语句为<start>,结束语句<end>。
同时添加Senticap语料库,该语料库是在MS COCO的基础上生成的具有客观描述的情感图像语句,该语料库包含1027个正面情绪的形容词-名词对,436个负面情绪的形容词-名词对。
3.2 评价指标
为了对生成的描述语句进行客观评价,采用BLEU、ROUGE、CIDEr评价指标。
其中BLEU是一种自动评估机器翻译,且独立于语言的方法。计算公式如下:
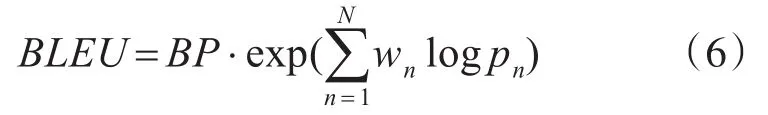
其中n表示n-gram,wn表示n-gram的权重;BP表示短句子惩罚因子,用r表示最短的参考翻译的长度,c表示候选翻译的长度。
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一组关于评估自动文摘和机器翻译的指标,主要是通过自动生成的摘要或者翻译与人工生成的摘要进行比较并计算出分值,衡量出两者之间的相似度。
CIDEr是基于共识的评测标准,计算n元语言模型(N-gram)在参考描述句子和模型生成待评测句子的共现概率。
4 实验结果
本文实验结果如图4、图5、图6所示,左边是图像,右边是该图像生成的描述语句,其中包含积极描述和消极描述,可以看到消极描述带有一些人类的负面情感在里面,比如冰冷的空气,寒冷的山,孤独的街道等,都是一些带有消极的形容词,而积极描述则有好天气,繁忙的街道等,有一些中性词和积极乐观的形容词。通过这些描述语句可以看出,本文所提出模型在情感丰富性上有了较大的提升,多了人类的感情色彩在描述语句中。

图4 用于生成描述语句的示例1

图5 用于生成描述语句的示例2

图6 用于生成描述语句的示例3
为了验证本文方法的正确性和有效性,与原来方法进行对比,结果如表1,可以看出本文方法相比较其他传统方法,在评价指标上具有较大的优势,在准确性指标BLUE上面的性能均有所提升,在语义描述的摘要质量ROUGE-L上面也比其他模型更好,在语义丰富程度指标CIDEr上面的指标与其他模型基本保持相似水平。
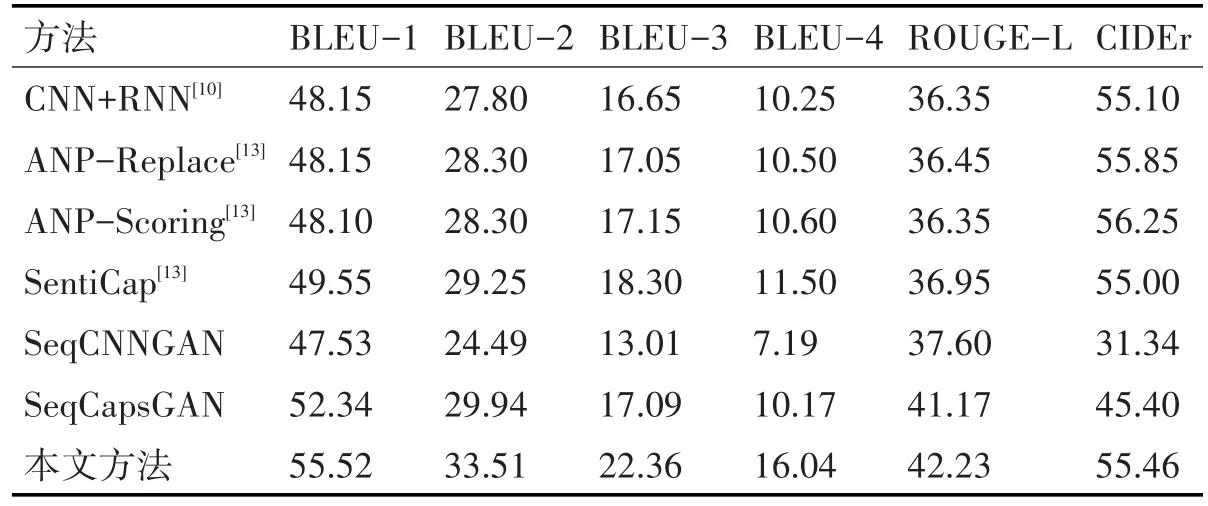
表1 性能实验对比
5 结语
利用Senticap语料库以及CBAM模型,提出了一个基于生成对抗网络的图像语义描述框架。通过生成器和判别器的对抗训练,描述出带有正面和负面情绪的语句,在生成器部分对图像特征进行提取,加入CBAM注意力机制,让模型可以更好地关注到重点视觉区域,充分提取图像特征并结合Senticap语料库对生成语句进行训练,接着在判别器部分对输入语句的真实性进行判别,输出一个0~1之间的值,并将该值反馈给生成器部分用以激励生成器的训练,最终在生成器和判别器的对抗训练下,生成近似于真实值的描述语句。实验结果不仅描述出了图像中的内容,还带有一定的感情色彩,包括人的负面和正面情感,可以看出模型在情感丰富性上有很大提升,同时在性能上也得到一定程度的提高。
