基于深度学习的图书馆电子资源绩效评估探索
——以中南财经政法大学图书馆为例
2022-11-08唐鹏宇
唐鹏宇 葛 红
(1.中南财经政法大学图书馆 湖北武汉 430073)
(2.华南师范大学计算机学院 广东广州 510631)
1 引言
随着计算机和网络技术的发展,电子资源迅速增长,逐渐成为图书馆馆藏资源的重要组成部分。如何对其进行有效评价,并及时调整采购策略,合理分配经费,是高校图书馆资源建设面临的主要问题[1]。现阶段,大部分电子资源绩效评估研究通常采用统计分析工具或是决策树、BP(Back-Propagation)神经网络等简单的机器学习(Machine Learning,ML)方法实现。但是,这些方法缺乏主动性和深度性,往往是运用模型对已采购的资源进行浅层评估,并不能学习采购过程中的深层逻辑和内部规则,模型也无法像采访馆员一样进行学习、分析并得出结论。深度学习(Deep Learning,DL)是近年来发展起来的机器学习方法,具有强大的数据分析和建模能力。“深度学习”这一概念在1976年由美国学者Ference Marton提出,强调机器学习算法的主动性[2]。与以往的机器学习方法不同,深度学习强调学习样本数据的内部规则和表示层次,最终目标是使机器学习算法能够像人类一样分析和学习,能够自动识别和分析输入的信息并得出结论[3]。目前,深度学习技术以其获取的主动性和结构深度性,已经被广泛应用并推广于数据挖掘等领域并取得了良好的效果[4]。利用深度学习方法对图书馆资源进行评价,比传统的统计分析方法或是简单的回归建模方法要更为准确、高效,是未来的一个发展方向。将深度学习方法引入电子资源绩效评估中来,使得模型算法能够像采访馆员一样分析和学习,自动识别和分析数据资源并得出采购结论,降低采访馆员个人意愿对采购客观性的影响,减少采访馆员更换对于采访策略的影响,维持电子资源建设的客观性和连续性。
2 电子资源绩效评估指标体系研究
深度学习模型的建立与学习需要大量的基础数据[5]。因此,构建电子资源绩效评估指标体系并收集相关的数据是深度学习建模的第一步。
20世纪90年代以来,随着计算机和网络技术的发展,电子资源迅速增长,逐渐成为图书馆馆藏资源的重要组成部分。针对图书馆电子资源,欧美和一些国际机构设立了许多知名的绩效评估体系,如《信息与文献 国际图书馆统计》数据标准ISO2789、欧洲委员会EQUINOX电子服务绩效评价和指标体系、美国图书馆协会的电子资源在线使用统计项目COUNTER(Counting Online Usage of Networked Electronic Resources)以及美国研究图书馆协会(Association of Research Library,ARL)的E-Metrics项目等,这些体系注重电子资源的使用统计分析[6]。除此之外,还有eVALUEd(英国高等教育基金会项目)、LIBQUAL+(ARL项目)等系统侧重于用户满意度的电子资源评价体系[7]。
近年来,国内图书馆电子资源绩效评估指标体系研究方面主要是学习和借鉴国外的经验,国内学者多以定性和定量研究方法相结合的层次分析方法进行指标体系的构建。比如侯振兴采用层次分析法确定高校图书馆电子期刊数据库绩效评价指标体系及权重并进行了评价验证[8]。陈英在利用层次分析法的基础上结合客观赋权方法中的CRITIC(Criteria Importance Though Intercrieria Correlation)方法进行评价指标的权重组合,从而测算高校图书馆电子资源的绩效评估价值[9]。但是,截止到目前,国内外并没有一个获得普遍认同的电子资源评价指标与体系[10]。绝大多数学者的研究是根据实际情况,结合国外认可度较高的评估体系,综合构建适合其研究的指标体系。
因此,本文在国内外已有学者研究基础之上,考虑到电子资源绩效评价影响因素的研究和后续评价模型的构建需求,结合中南财经政法大学图书馆的实际情况,主要选择了具有独立性、可得性、有效性和可定量的关键指标。从“信息质量”“使用质量”“服务质量”“资源成本”四个维度构建了中南财经政法大学图书馆电子资源绩效评估指标体系,如表1所示。
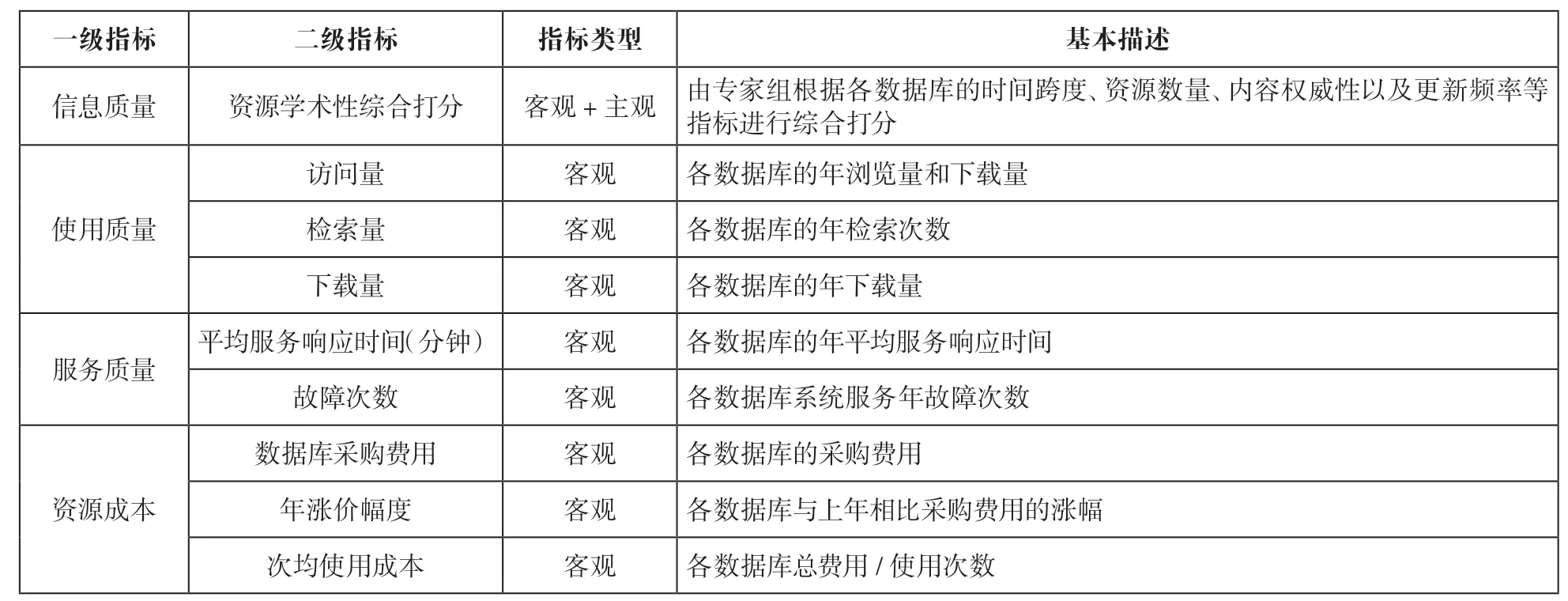
表1 中南财经政法大学图书馆电子资源绩效评估关键指标(以年为单位)
首先,信息质量是评估信息是否成功的重要维度之一。根据DeLone和Mclean提出的信息系统成功模型(D&M Information system success model,简称D&M模型),信息质量直接影响了用户的使用效果和满意度,是信息资源评价的重要指标[11]。高校图书馆所采购的电子资源应当具有较高的信息质量,应当是在该学科领域具有较高说服力和认可度的。考虑到电子资源的信息质量难以量化,因此,“信息质量”纬度主要以组织专家组进行综合打分的形式进行,专家组根据各数据库的时间跨度、资源数量、内容权威性以及更新频率等指标对以往所采购的数据库的信息质量进行综合打分。
其次,使用质量是电子资源评估的基础客观指标。COUNTER项目是电子资源管理与评价中最常使用的标准,它定义了电子资源在使用过程中需要统计的数据量,包括电子资源的使用量、检索量、下载量等指标,能够帮助图书馆获得一致的、可比的和可靠的电子资源统计报告,并且在国际上认可度较高[12]。因此,“使用质量”纬度选取COUNTER项目中的关键指标,并结合本校实际数据的可得性,构建了电子资源的“访问量”、“检索量”和“下载量”三个二级指标。
再次,服务质量是电子资源评估中不可缺少的指标。根据Pitt、Watson和Kavan的研究,服务质量能够反映读者使用和满足需求的程度,电子资源的绩效评估应该增加服务质量这个维度[13]。我国高校图书馆数字资源采购联盟(Digital Resource Acquisition Alliance Chinese Academic Libraries,DRAA)也对集团采购的电子资源进行了服务质量的调查与评估,主要对数据库商的售后服务、检索系统等维度进行评估[14]。因此,综合相关数据的可得性和有效性,本纬度采用了“平均服务响应时间”和“系统服务故障次数”两个二级指标作为电子资源评价中的服务质量评价指标。
最后,资源成本是电子资源评估的常见硬性指标。一般来说,需要从软硬件两个方面考虑图书馆为电子资源的建设和使用所支出的费用。但是,由于目前中南财经政法大学图书馆绝大部分电子资源的使用均为远程访问方式,硬件投入相对较少,可以忽略不计。因此,选择电子资源的“采购费用”“年涨价幅度”“次均使用成本”作为资源成本的关键指标。
3 基于深度学习的电子资源绩效评估模型构建
深度学习是多层级机器学习模型及算法的总称,因其强有力的数据分析和建模能力而得到广泛应用。深度学习通过多层级结构实现逐层多级特征提取,自动完成了大量数据预处理和特征提取工作,是一种端到端的、能有效进行复杂问题建模的机器学习方法。如前所述,电子资源评价是一个涉及多方面多层次的复杂问题,其模型是一个多元的非线性函数。传统的依据主观判断或简单模型进行评估的结果,缺乏准确性和实用性。因此,笔者收集了中南财经政法大学图书馆2017—2021年五年间的电子资源相关数据,尝试利用深度学习技术对中南财经政法大学图书馆的电子资源进行建模、学习、评估和预测,以期为电子资源的选择和配置决策提供参考。
具体而言,本文所讨论的电子资源评价问题,是指依据前述影响电子资源的关键指标对某个特定的电子资源进行定量评价即评分。可表达为获取一个电子资源评价模型,如下所示:
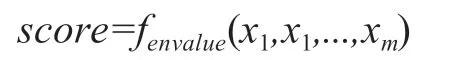
其中,score为对某个电子资源的评价分值,Xi(i=1,2,3,...m,m=9)为该资源的关键影响指标的值。通过建立电子资源评价模型,可以依据某个电子资源的关键影响指标的数据,快速、高效、准确地给出该资源的评分,为图书馆采购电子资源及对现有资源评价提供重要参考。
在各种各样的深度学习模型中,我们选择多层前馈神经网络作为电子资源评价模型。多层前馈神经网络是深度学习中拟合能力最强、应用最广泛且最为简单有效的模型。依据前述电子资源关键指标的研究以及深度学习模型的决定性要素,通过中南财经政法大学图书馆2017—2021年五年间的电子资源相关数据集,对多层前馈神经网络进行训练和测试,构建电子资源评价模型。
多层前馈神经网络结构示意图如图1所示。决定多层前馈神经网络功能实现和性能优劣的关键要素包括:网络的层数及各层的节点数;节点的激活函数;各层节点之间的连接权重。
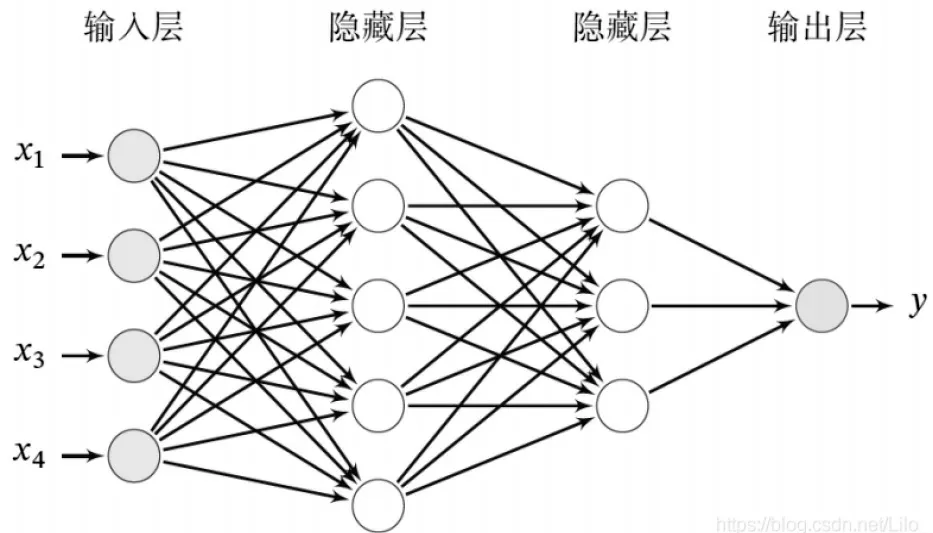
图1 多层前馈神经网络结构示意图
多层前馈神经网络模型的输入层(即第一层)的节点数通常与模型函数的自变量的个数相同,针对电子资源评价问题,输入层节点数就是关键影响指标的数量。模型的输出层节点数取决于整个模型的输出变量,所以,本文的电子资源评价模型的输出就是一个评价值。介于输入层和输出层之间的隐层的层数和每层的节点个数取决于模型的数据对象,一般而言,数据越复杂,对应的模型的隐层数和节点数就越多,所以,这部分结构需要通过实验决定。同样的,模型中各个节点的激活函数,通常是在线性函数或sigmoid函数、tanh函数、Relu函数、softmax函数等非线性函数中选取,具体选择何种激活函数,也需要通过实验决定。
4 实验及结果分析
实验的数据集来源于中南财经政法大学图书馆2017—2021年各年的电子资源数据。数据集规模为324×10,即324个样本数据,每个数据包括表1所列的9个关键影响指标及一个对电子资源的评价分值。数据集中每个电子资源的评价分值以其历年购买的几率值为依据评定。将2020年及之前的数据作为训练集,2021年的数据作为测试集。模型采用深度学习框架keras实现。
首先,对不同层数、不同节点数、不同激活的函数模型进行实验,来获取适合本文问题的模型。由于可选择的激活函数有限,因此实验中隐层节点采用tanh函数,输出层节点采用sigmoid函数。另外,为便于比较,所以模型训练次数都为15 000次。实验结果如表2所示。
表2所列实验结果表明,在训练次数相同的情况下,隐层数较少(1层和2层)的模型的训练精度和测试精度都比较低,说明模型的复杂度偏低,不能有效拟合输入变量与输出变量之间的函数关系。而当隐层数较大(4层)时,训练精度较高而测试精度偏低,表明该模型出现了过拟合的问题。因此,最佳的模型结构就是包含3个隐层的深层前馈神经网络。
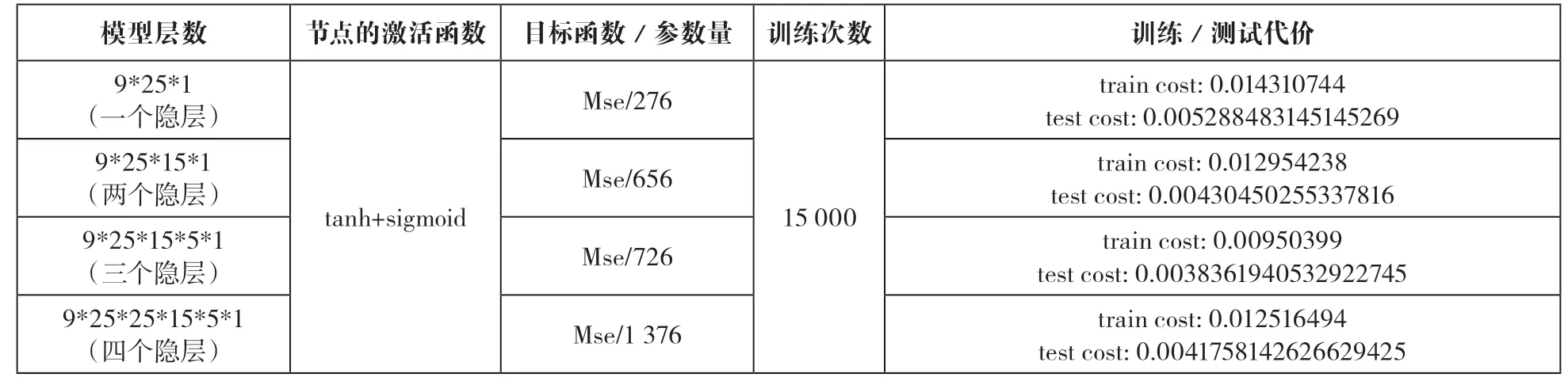
表2 深度前馈神经网络模型实验
接下来,在最佳模型上进行调参实验,以确定最佳超参数组合。分别对隐层节点数和隐层节点的激活函数进行实验,实验结果如表3所示。
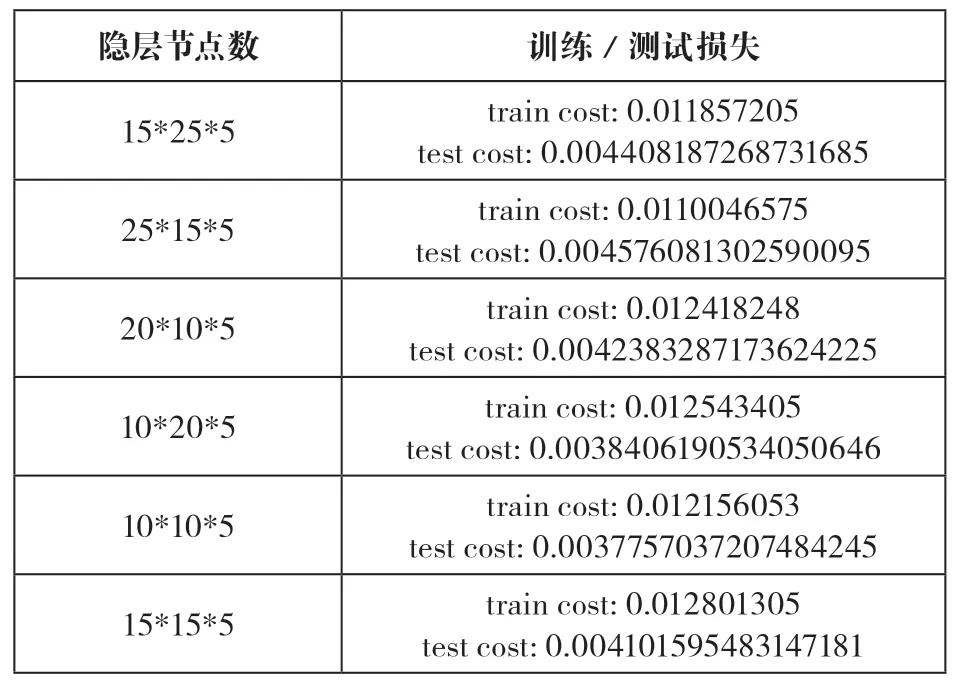
表3 隐层节点数实验
依据表3的实验结果,选择训练误差和测试误差最小的模型,得到实现电子资源评价的最佳模型结构为一个4层的前馈神经网络。其中,输入层有9个节点,分别用于输入表1中的9个关键指标,3个隐藏层的节点数分别为10、10、5,最后是只有一个节点的输出层,用于输出对应电子资源的评价值。从实验结果可见,最佳模型的训练精度和测试精度都达到99%以上,验证了该模型在电子资源评价的可行性和有效性。
多层前馈神经网络是一种通用的“万能逼近器”,理论上讲,包含一个隐层的前馈神经网络,就可以表达任何连续的输入输出关系。在实际应用中,可以通过增加隐层层数,减少每个隐层节点数的节点数,来降低模型复杂度和参数量,从而提升模型性能,避免过拟合的风险。同时,由于模型的输入变量是问题直观的特征描述,而多层前馈神经网络的隐层的功能在于提取输入信息中的隐含特征,可以通过对特征维度的先升后降来实现有效特征的提取和融合,获得最好的问题模型构建。本文最后得到的最佳模型结构表明,输入变量经过两次升维(9维输入变量提升为10维特征)以及一次降维(10维特征降维到5维)的特征变换,较好地获取了输入信息的重要特征,有效实现了问题模型的构建。
值得注意的是,在现有模型的基础上,通过后续数据的添加,可以不断训练模型的迁移学习能力,从而进一步提升模型的精度和性能。
5 总结与不足
高校图书馆电子资源的合理有效的配置和采购,是图书馆资源建设和学科服务的重要任务。深度学习是一种端到端的多层级机器学习模型,利用深度学习方法对图书馆电子资源进行学习和评估,比传统的统计分析方法或是简单的回归建模方法要更为准确、高效,是未来的一个发展方向。根据实际情况构建图书馆电子资源绩效评估指标体系,使用基于关键影响指标的深度前馈神经网络模型,使得系统能够学习该图书馆的采购深层逻辑,高效深入地评估和预测电子资源采购。实验结果分别取得99.8%和99.7%的训练精度和测试精度,表明所提指标和模型的可行性和有效性,具有明确的应用意义。
然而,本文的研究知识是在人工智能的发展趋势下的一种尝试,要训练深度学习模型,需要较多的训练数据。由于受到数据的可得性的限制,本文对于几个重要指标采用综合打分的方式获取,会降低模型的客观性。接下来,可以对相关重要指标做进一步的分析和量化,采用更为全面而详细的影响指标,以期得到更为准确的电子资源评价模型。
“双一流”建设需求对高校图书馆的资源组织和服务拓展提出了更高的要求。高校图书馆有必要将电子资源绩效评估与最新科学技术相结合,大胆尝试,构建更加丰富、客观和多元化的评估指标体系,重视多源多模态数据的组织与分析服务。并且,有必要结合各个高校的实际情况,提升数据的可得性,根据高校的特点对评估进行细分,针对特定资源、具体阶段和优势学科开展评估业务。此外,有必要对图书馆资源进行持续、长期的监测与评估,形成定期管理并及时反馈,从而提高图书馆的资源服务能力。最后,要充分发挥行业协会的组织协调作用,开展统一、通用的资源绩效评估实践,超越单一机构的局限性,建立全国性的图书馆资源评估指标大数据平台,推进融合化的创新服务平台建设。
