基于回译和集成学习的维汉神经机器翻译方法
2022-11-07杨雅婷艾孜麦提艾尼瓦尔
冯 笑, 杨雅婷*, 董 瑞, 艾孜麦提·艾尼瓦尔, 马 博
(1.中国科学院 新疆理化技术研究所, 新疆 乌鲁木齐 830011; 2.中国科学院大学, 北京 100049; 3.新疆民族语音处理实验室, 新疆 乌鲁木齐 830011)

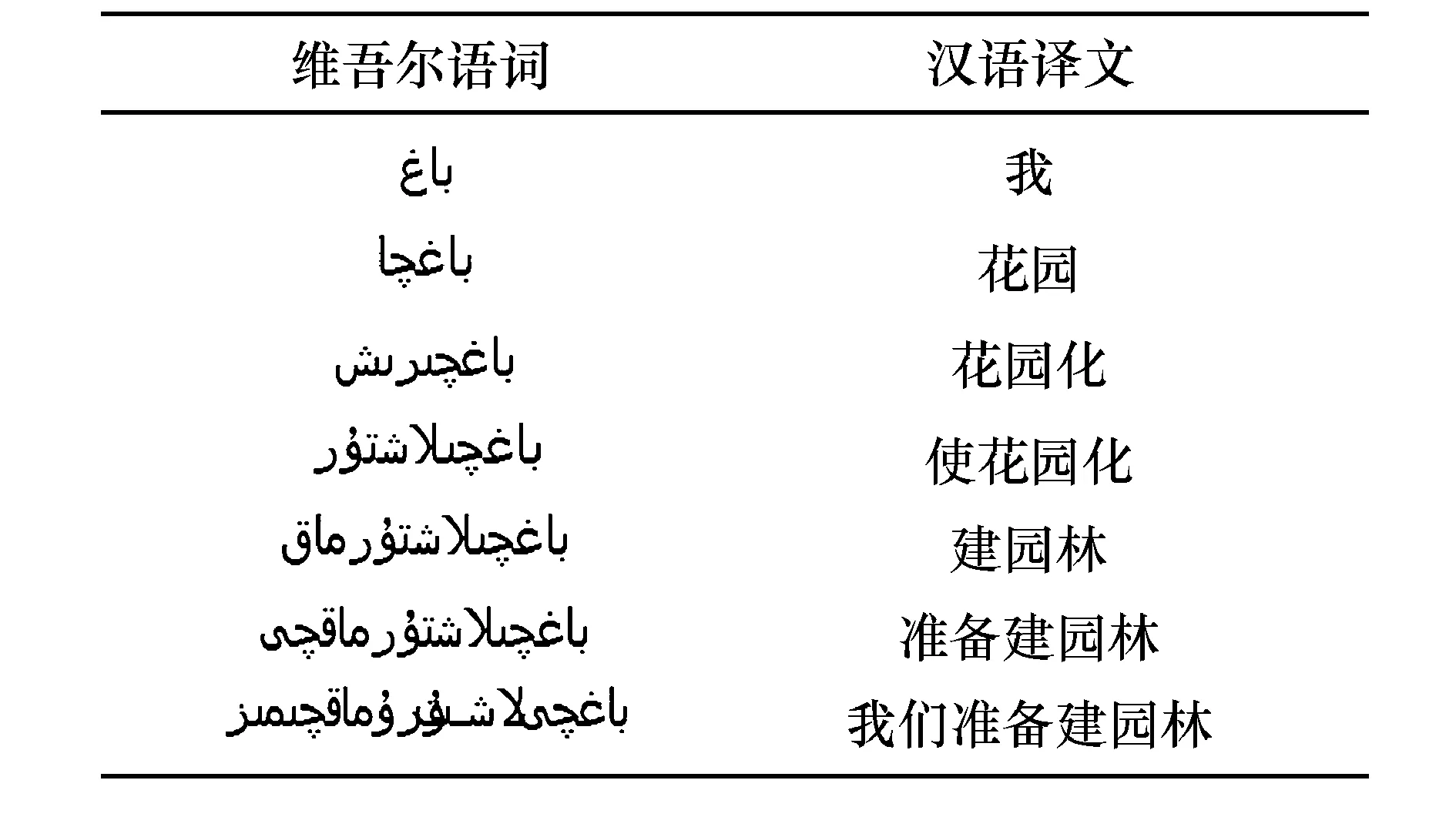
表1 维吾尔语言特性举例
为了能够获得性能更好的神经机器翻译系统,研究人员尝试了各种方法.回译可以利用大规模单语语料来提升机器翻译模型性能.它首先训练一个目标语言到源语言的机器翻译系统,然后将目标端单语数据翻译成源端数据,得到伪平行语料对训练数据进行扩充.Sennrich等[3]经过实验证明回译能够提升神经机器翻译系统的性能.Poncelas等[4-5]探究了平行语料和伪平行语料的规模比例对机器翻译性能的影响,并且发现机器翻译模型的性能和所使用的单语数据的领域有着十分重要的关系.Hoang等[6-7]提出了一种迭代训练方法,通过不断对反向翻译系统和最终翻译系统进行迭代,同时提升反向翻译以及最终翻译系统的性能.Poncelas等[8]通过将统计机器翻译模型和神经机器翻译模型进行回译所得到的伪平行语料混合,显著提升了机器翻译的效果.Luo等[9]针对低资源语言,提出一种将回译与迁移学习相结合的神经机器翻译模型.
集成学习是通过构建并结合多个模型来完成学习任务,结合后模型的泛化性能通常会优于单一的模型,是一种在机器学习任务中有效而且使用广泛的技术[10].常用的集成学习方法主要有Bagging[11]、Adaboost[12]等.集成学习能够显著提高神经机器翻译的准确率,这使其成为在机器翻译领域中被广泛使用的技术[13-19].Vaswani等[13]提出将单一模型训练过程中不同时刻保存的N个模型的参数进行平均来获得鲁棒性更强的模型.Sennrich等在WMT16[14]测评任务中使用了模型参数平均的方法,在WMT17[15]测评任务中使用了独立集成的方法,均取得了优异的成绩.李北等[16]通过实验总结出了一种在机器翻译中更高效的集成方法.张新路等[17]通过集成学习整合多个模型预测的概率分布,提出了基于集成学习的双向重排序模型.Wang等[18]提出了一种TEL(transductive ensemble learning)的方法,该方法能够在测试集源语言已知的情况下有效地集成多个NMT模型,进一步提升了强翻译模型的性能.
利用回译进行数据增强并结合集成学习可以进一步提高模型的性能,但传统集成学习需要从头训练多个子模型,存在训练周期长、计算资源消耗大的问题,当训练集进行了数据增强时,这个问题会更加突出.为了缓解这个问题并提升维汉机器翻译系统的质量,本文提出了一个基于回译和集成学习的方法(BTEM,back translation and ensemble),在CWMT2015和CWMT2017测试集上的实验证明,BTEM相对于基线系统的BLEU值分别提升了2.37和1.63,且训练周期和计算资源消耗大大缩减.
1 相关技术
1.1 神经机器翻译
神经机器翻译是一个序列到序列的学习任务,通常用一个编码器-解码器的框架来建模[19].使用编码器将一个源语言句子X=(x1,x2,…,xn)编码为中间向量Z,解码器根据Z生成目标语言句子Y=(y1,y2,…,yn).对编码器和解码器进行联合训练,使给定源序列的目标序列条件概率最大化:
(1)
编码器和解码器可以使用不同的神经网络结构来实现,包括GRU[20]、CNN[21]以及Transformer[13]等.基于自注意力机制的Transformer是神经机器翻译领域中最先进的架构.
基于注意力机制的Transformer抛开了传统的循环神经网络的序列结构,不但保证了模型的并行化,也改善了模型的表示能力,提升了模型的精确度.Transfomer采用的是编码器-解码器的结构,由N个堆叠的编码器-解码器层组成.因为它没有使用循环或卷积神经网络,为了得到序列的位置信息,在词向量中注入了位置编码信息.Transformer中的编码器由N个相同的层堆叠而成,每一个层有两个子层,分别是多头注意力机制和简单的前馈神经网络.同编码器类似,解码器在编码器的基础上增加了一个能够处理从编码器端输出的多头注意力机制的子层.为了保证梯度传递的稳定性和模型收敛的速度,在编码器端和解码器端的每一个子层后面都增加了正则化操作和残差连接[22].为了从不同位置的不同表示子空间获取信息,Transformer使用了基本单元是缩放的点积注意力模型的多头注意力机制,这种注意力的输入为dk维的query,dv维的key和value,每一个头对应一个点积注意力模型,计算公式如下:
(2)
式中:查询矩阵Q的每一行与一个query相对应;每一个query与键值矩阵K的转置相乘后,可以得到一个dv维的加权求和的结果.多头注意力机制就是把query、key、value映射成h组维度大小是dq、dk、dv的向量,分别进行按比例的点积注意力,最后输出拼接得到的h个向量,如下式所示:
(3)
MultiHead(Q,K,V)=Concatj(headj)WO
(4)
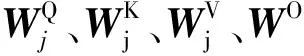
1.2 集成学习
在词级集成中,一组个体模型逐步地联合生成一个序列.即给定一个源语言句子x∈X,第t个位置将要输出的单词y(t)的选择式如下式所示:
(5)
其中:y=(y(1),y(2),…,y(t),…)是源语言句子x的译文.
给定源句子x,每个模型独立生成一个译文,得到候选句子对集合T(x)={(x,fm(x))|m∈M},句子级集成最常见的就是对集合中的句子对进行重排序[23],由所有M个模型评估的得分最高的译文作为最终的输出:
(6)
根据Imamura和Sumita[24]的工作可以看出,句子级别的集成和词级别的集成在不同的环境下通常可以获得类似的结果,所以在本文后面的部分,主要使用词级集成.
1.3 回译
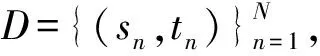
2 问题描述
新疆地区作为“一带一路”倡议中连接亚欧大陆的国家开放大通道,构建性能良好的维汉机器翻译系统促进地区发展、文化交流对“一带一路”倡议的繁荣发展具有重要意义.“数据驱动”的神经机器翻译在中英、英德等资源丰富的平行语料上取得了巨大的成功,但是维吾尔语作为一种低资源语言,维汉平行语料的匮乏严重限制了维汉机器翻译的质量.而人工标注维吾尔语-汉语平行语料需要大量的人力、物力,既费时又费力.因此,从充分利用现有资源的角度出发,研究如何在平行语料匮乏的条件下有效地提升维汉神经机器翻译的质量具有重要意义.
3 本文方法
为了缓解上述问题,本文提出了一个BTEM方法.本节介绍该方法的基本思想以及与其他工作的联系和区别.
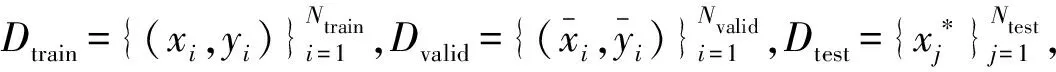
2)利用fbt对Dtrgmo做回译,得到伪平行语料:
(7)
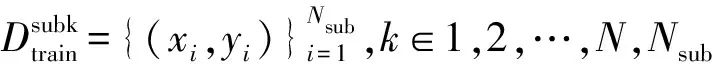
5)使用这N份子训练集分别对中间模型fitm进行微调,增加其对不同数据的敏感度,得到N个具有差异性的子模型:
k∈{1,2,…,N}
(8)
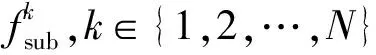
(9)
vt是目标语言词汇表.
BTEM方法的结构图如图1所示.
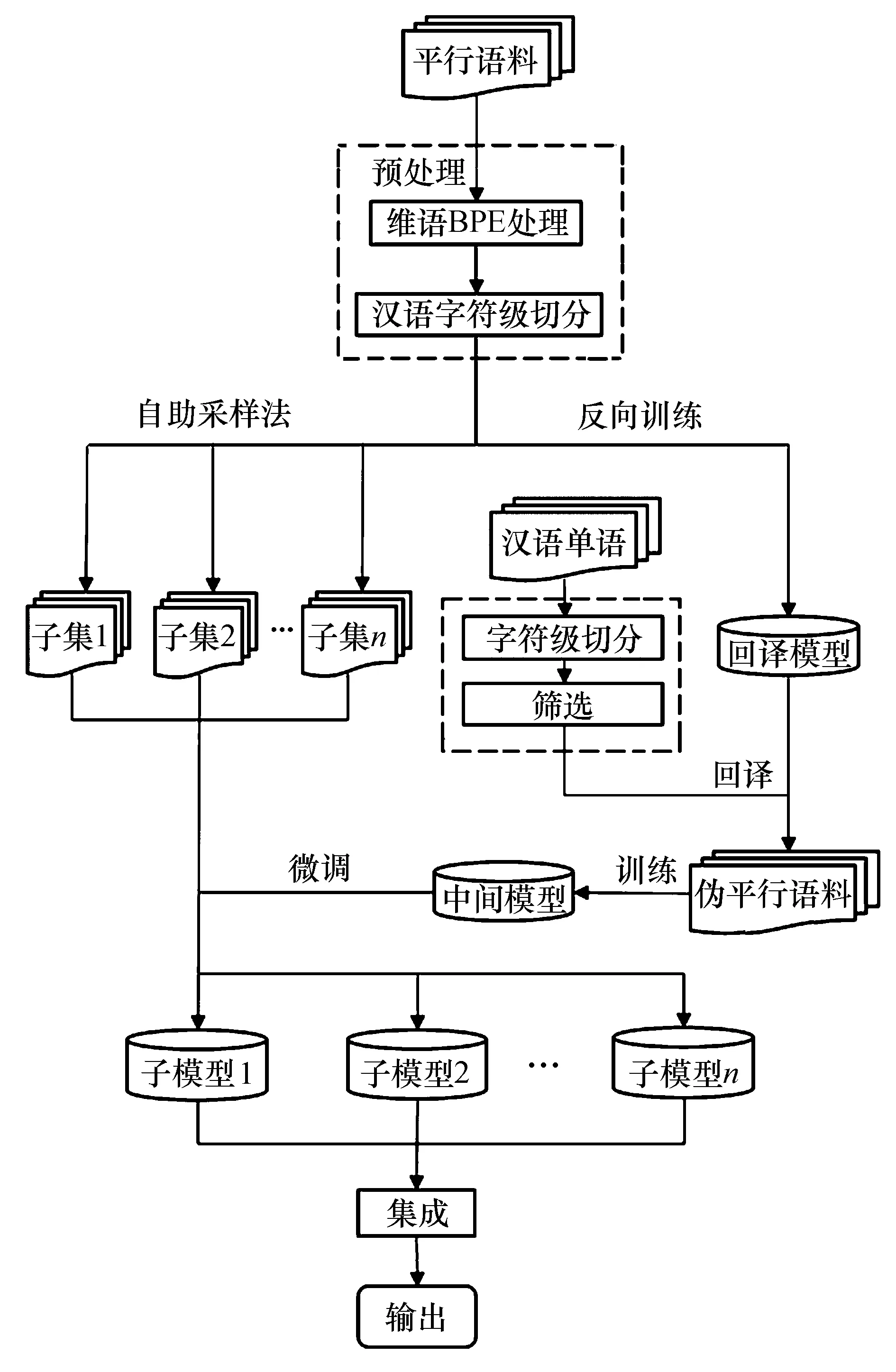
图1 BTEM方法结构图
BTEM方法和其他集成学习、回译的方法有以下不同之处:
1)传统的回译方法主要用作数据增强,将回译所得到的伪平行语料和平行语料混合后直接训练,在BTEM方法中,伪平行语料用来训练中间模型.
2)Bagging集成学习方法是使用有差异性的子训练集从头训练多个模型,但BTEM方法是使用不同的子训练集对中间模型进行微调,来得到多个具有差异性的子模型.
3)BTEM充分吸收了数据增强和Bagging集成学习的优点,可以显著提升译文质量,但考虑到训练周期和硬件代价问题,该方法不需要从头训练多个模型,是一种非常高效的方法.
4 实验
本节主要介绍了本文在维汉机器翻译任务上的实验,验证BTEM方法的有效性.
实验运行环境:操作系统为Ubuntu 18.04.1 LTS(GNU/Linux 4.15.0-42-generic x86_64),gcc版本为5.4.0,编程语言为python 3.6.9,深度学习框架为pytorch 1.3.1,在2块Tesla k80 GPU上进行训练.
4.1 数据及预处理
本文使用的数据集是CCMT2020提供的500万句汉语单语语料以及CWMT2015提供的35万维汉平行语料,测试集为CWMT2015和CWMT2017所提供的测试集.
对于维吾尔语,使用subword-nmt工具进行BPE[26]处理缓解未登录词的问题,BPE融合数设置为32 000.与维吾尔语不同,汉语的基本构词单位是字,常用字只有1万多个,但是词的规模达到了30万,以词为单位会由于词表过大而放大数据稀疏问题,所以本文实验对汉语进行字符级切分.
其次,对于500万汉语单语语料,同样对其进行基于字符级别的切分.借鉴之前的一些研究工作[27],在本文中根据切分后的汉语单语语料中所有词在平行语料词典中出现的比例,选出比例大于0.9的汉语单语句子,使得汉语单语语料的领域更加接近维汉平行语料.剔除汉语单语语料中句子过长、过短以及含有乱码的句子,处理后的数据集信息见表2.

表2 实验数据集
4.2 实验设置
实验采用fairseq作为模型框架,使用Transformer模型作为实验的基线模型.采用Transformer_base模型,编码端和解码端的层数都是6层,词向量的维度为512,前馈神经网络为2 048维.采用Adam算法[28]作为优化算法,Dropout[29]设置为0.3来缓解模型训练过程中的过拟合问题,从头开始训练模型时学习率设置为5×10-4.解码时使用Beam-search策略,beam-size大小设置为5.使用机器翻译领域最常用的机器双语互译评估值[30](BLEU)对模型效果进行评价.基于上述参数,训练得到基线模型,在CWMT2015和CWMT2017测试集上的BLEU值分别为54.30和31.11.
4.3 不同参数对微调结果的影响
首先,只使用伪平行语料训练得到中间模型,该模型在CWMT2015和CWMT2017测试集上的BLEU值分别为44.58和25.09.在使用子训练集进行微调的时候,如果学习率设置较大,则会出现灾难性遗忘的问题,即模型在学习新知识的时候将中间模型的知识遗忘;如果学习率设置太小,又会出现参数更新速度太慢,导致模型无法快速地找到好的下降方向,消耗更多的训练资源.本文首先探索了学习率(learning rate)和预热值(warmup updates)对微调的影响,如表3所列.从表3可以看出,当学习率设置为1.2×10-4,且预热更新步数为10 000的时候,微调模型效果相对较好,下面的实验中微调全部采用此参数.
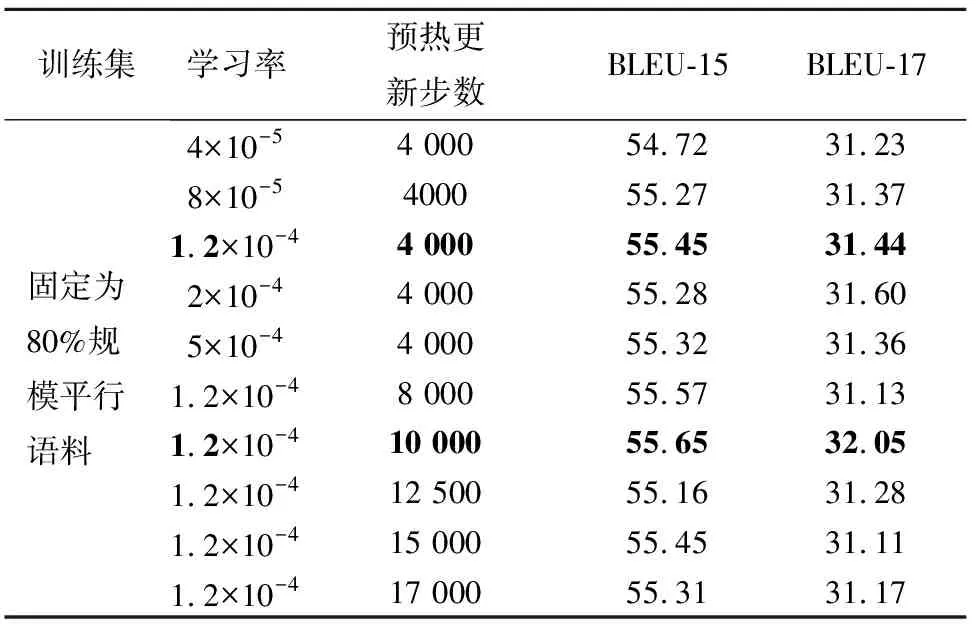
表3 不同微调参数对模型性能的影响
4.4 不同子集规模对微调和集成的影响
在进行集成学习时,需要遵循“好而不同”的原则,即参与集成的子模型效果要好而且相互之间具有差异性.在进行子集的抽取时,如果子集规模抽取得太小,会无法充分利用平行语料,导致单个子模型性能过低,但是如果子集规模过大,那么子模型之间的差异性就大大降低.本小节探索不同子集的规模对子模型微调和集成效果的影响,并对回译和集成学习在BTEM方法中所起的具体作用进行了分析,如表4所列.

表4 子集规模对模型微调和集成的影响
表4中,子模型是使用重采样后的训练集对中间模型进行微调的结果.可以看出,基本上所有的子模型在两个测试集上相对于基线模型都有了不同程度的提升,这是因为中间模型是使用回译和大规模单语语料所得到的伪平行语料训练而来,通过原始平行语料对其微调,可以将大规模的目标端单语数据知识有效地融合到模型中,同时模型避免了伪平行语料中噪声的影响.
在CWMT2015测试集上,使用100%规模原始平行语料微调后的4个子模型BLEU值从整体上看比其他规模略高,这是因为其充分利用了原始平行语料.但在CWMT2017测试集上,整体上却比90%规模微调后的子模型略低,通过对比这些子模型在验证集上BLEU值可以发现,在验证集上使用100%规模原始平行语料微调后的4个子模型的BLEU值整体上比90%规模的更高,如表5所列.由此推测,这是因为重采样后的训练集与CWMT2017测试集中的数据分布相对更加接近.
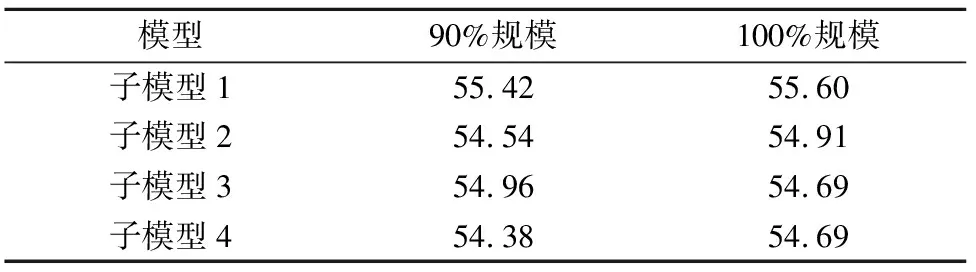
表5 不同规模子模型在验证集上的BLEU值
从表4中还可以看出,将4个子模型进行集成之后,所得到的集成模型的BLEU值相对于各子模型都有所提升.这是因为4个子模型是分别使用规模相同但内容有差异的4个子训练集对中间模型微调而来,增加了4个子模型之间的差异性;而集成学习是一种联合多个模型进行协同决策的机器学习方法,它有效整合了4个子模型预测的概率分布,提升了翻译质量.当子集的规模为原始平行语料的90%时,微调后的4个子模型集成的效果最好,在CWMT2015和CWMT2017测试集上的BLEU值分别达到了56.67和32.74.当使用100%规模原始平行语料进行微调时,因为数据差异性较小,所得到的子模型间差异性较小,集成时所提升的效果有限.
4.5 对比方法
本实验将BTEM方法分别与基于Transformer的神经机器翻译系统、Bagging、数据增强、数据增强+Bagging以及模型参数平均等方法进行了对比.
1)基于Transformer的神经机器翻译系统
实验采用由Vaswani等提出的Transformer模型,训练采用3.2节所述参数,训练得到的模型记为Base Model,并以此作为基线系统.
2)Bagging
Bagging是一个非常经典、有效的集成学习方法,其基本思想是分别使用重采样后的子数据集训练多个子模型,预测时对不同模型的输出结果取平均得到集成模型的输出.
3)数据增强(data augmentation)
将回译所得到的伪平行语料与原始平行语料混合后直接训练.
4)随机种子+数据增强+Bagging(RBD)
将数据增强(平行语料与伪平行语料混合)后的数据集进行Bagging集成学习,初始化子模型的时候利用不同的随机种子增加子模型间的多样性.
5)100%-fine-tune
使用100%规模平行语料对中间模型微调.
6)模型参数平均(parameters on average)
因为模型在训练的过程中要更新一定的轮数才能收敛,为了获得更具有泛化性的模型,Vaswani等[13]提出了模型参数平均的方法,即将单一模型在训练过程中最近保存的N个模型的参数矩阵对应位置数值进行平均得到新的参数矩阵,本次实验将数据增强实验训练过程中保存的模型进行参数平均.
7)TEL(transductive ensemble learning)
基于集成学习思想来利用全部或部分源语言端测试数据.具体来讲,首先利用随机种子训练得到多个不同但性能较好的模型,其次使用这些模型将验证集和测试集的源语言端句子翻译到目标语言,并将其合并得到新的数据集,然后在合成数据集上微调各模型,最后保留在验证集上BLEU值最高的单一模型[18].
4.6 模型参数平均
Vasawani等提出模型参数平均方法时并没有给出经验性的结论,本小节探索了在维汉神经机器翻译中参与平均的模型数量对模型性能的影响,如图2所示.从图中可以看出,当对最近保存的10、15、20个模型进行平均,BLEU值均得到了提升,其中对最近保存的10个模型进行平均时BLEU值最高,在CWMT2015和CWMT2017年的测试集上分别为55.79和31.88,在以后的工作中可以考虑对最近保存的10个模型进行参数平均.
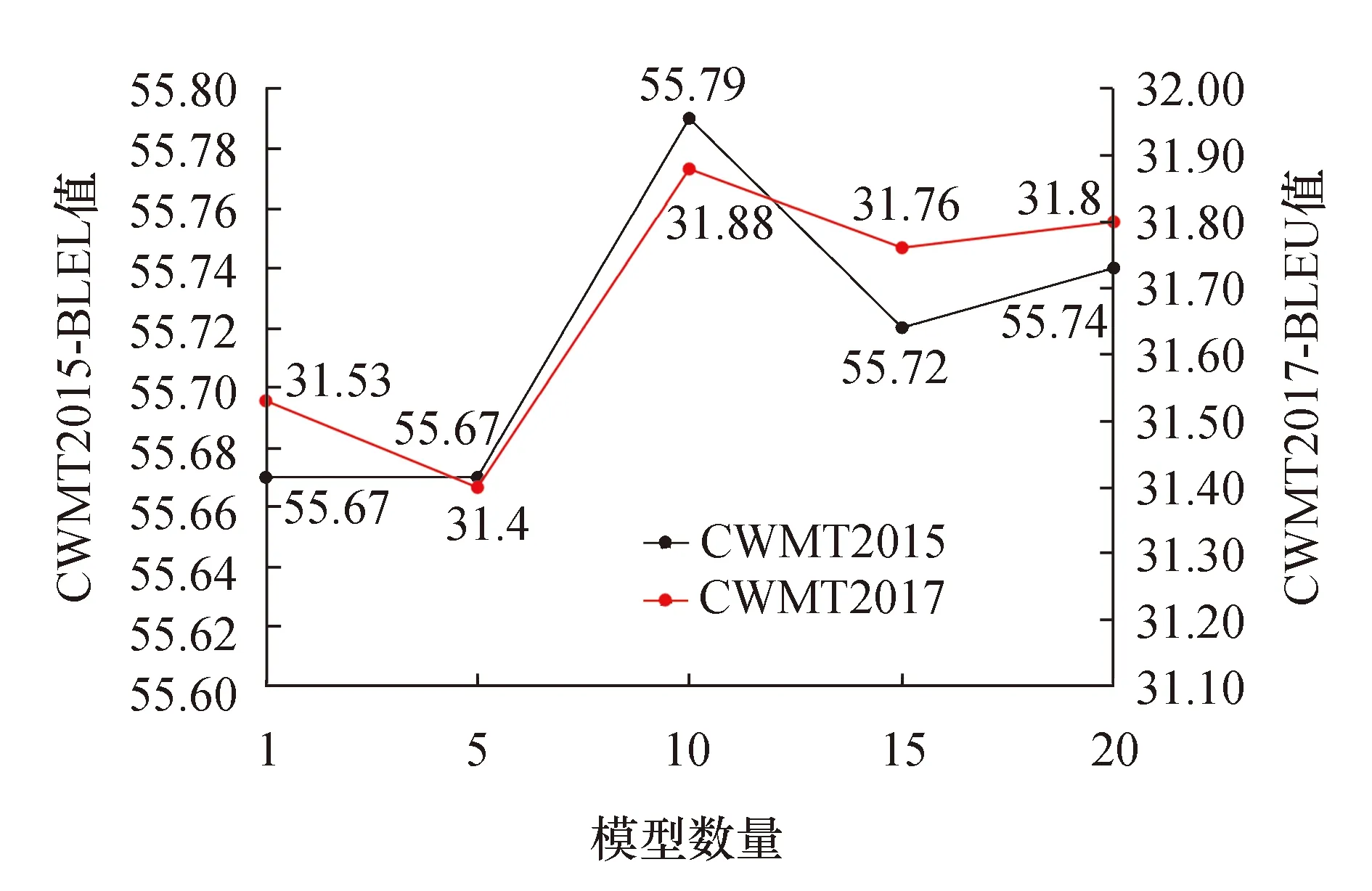
图2 平均不同数量模型参数结果
4.7 实验结果对比与分析
BTEM方法与其他方法的对比结果见表6.通过表6可以看出,各种方法相较于BaseModel,BLEU都有了一定的提升,且BTEM方法在CWMT2015和CWMT2017的测试集上分别提升了2.37和1.63.这是因为BTEM方法首先利用回译和大规模单语语料获得伪平行语料,使用伪平行语料训练得到中间模型;然后使用原始平行语料对其微调,将单语数据知识有效地融合到子模型中;最后联合多个子模型进行协同决策,整合多个子模型的预测概率分布,进一步提升了翻译效果.
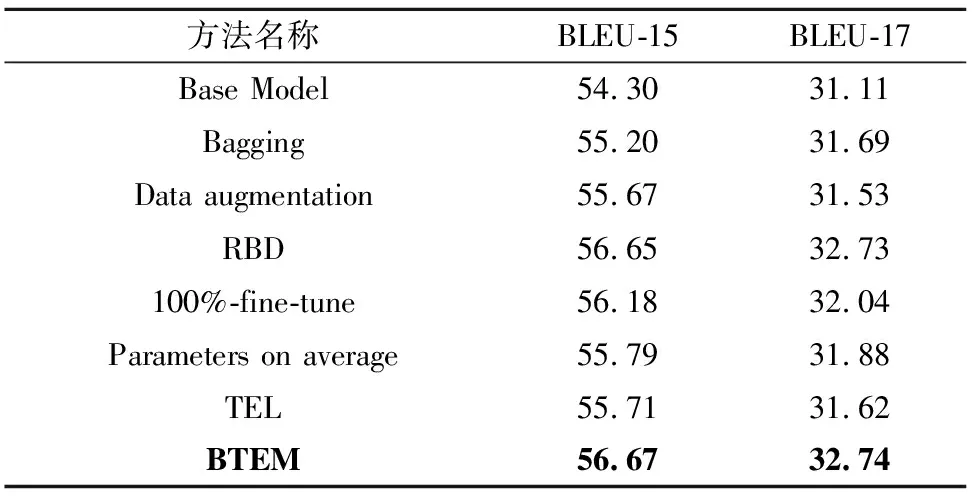
表6 不同方法对比
表6中的结果表明,BTEM方法优于基线系统和其他几种方法,但该方法在统计意义上是否具有显著的效果也很重要,所以本文使用了自举检验法[31]对BTEM方法进行统计意义上的检验.
自举检验法的工作原理如下:假设有测试集T0中有N个测试样例,使用有放回的重采样方法从T0中进行重采样得到一个规模同样是N的新测试集T1.然后再重复该步骤M-1次,可以得到M+1个测试集.在本文中M设置为1 250.
使用BTEM方法训练所得到的模型在这1 251个测试集上测得BLEU值,然后基于这1 251个BLEU值计算出本方法在CWMT2015和CWMT2017测试集上的95%置信区间,分别为[56.64,56.87]和[32.67,32.80].从表6可以看出,除了RBD方法以外,其他方法在测试集上的BLEU值都落在BTEM方法的置信区间下限以下,表明BTEM方法明显优于其他方法.
除RBD方法外,BTEM的BLEU值相对于其他方法都有了一定提升.相对于RBD方法,BTEM方法的优势是只需要在大规模的伪平行语料上训练1次得到中间模型,再使用几份规模较小的平行语料对中间模型进行微调就可以得到多个子模型,而RBD方法需要在平行语料和伪平行语料混合后的大规模数据集上从头训练多个子模型.表7展示了BTEM和RBD方法进行训练时所使用的数据规模.

表7 两种方法所使用的数据规模
如表7所列,本文实验中BTEM方法先利用全部的伪平行语料训练得到中间模型,然后分别使用4份90%规模的平行语料对中间模型进行微调得到4个子模型,实现了中间模型的复用.而RBD方法是使用平行语料和伪平行语料混合后的大规模训练集的90%从头训练了4次得到4个子模型.虽然BTEM方法相对于RBD方法BLEU值并没有明显提升,但其训练周期更短,节省了大量计算资源,相对来说更加高效.
5 结论
本文针对维汉平行语料匮乏导致的神经机器翻译系统质量不佳的问题,提出一种BTEM方法来构建维汉机器翻译系统.在测试集CWMT2015和CWMT2017上的实验结果显示,使用该方法训练所得到的维汉神经机器翻译系统的BLEU值相对于基线系统分别提升了2.37和1.63,能够显著地提高维汉神经机器翻译的性能,且相对于RBD方法节省了大量的训练时间和计算资源.目前集成学习相关的工作中,大部分都使用了多个模型,下一步工作将会探索在维汉神经机器翻译系统中,子模型的数量对集成系统效果的影响.
