融合文字与标签的电子病历命名实体识别①
2022-11-07杜昕娉高延军马慧敏
赵 奎,杜昕娉,高延军,马慧敏
1(中国科学院 沈阳计算技术研究所,沈阳 110168)
2(中国科学院大学,北京 100049)
3(中国医科大学附属第四医院,沈阳 110032)
4(东软集团股份有限公司 医疗解决方案事业本部,沈阳 110003)
1 引言
医疗电子病历[1]现今在临床诊断中被广泛应用,近几年伴随着机器学习、深度学习的快速发展,结构化电子病历得到了大众的关注.由于难以将医生对病症的描述进行统一,使得结构化医疗术语无法建立.具体来说,对于同一种疾病,不同的医生在表达方式、中文的繁简体,英文字母的大小写上的区别,导致在医疗领域难以形成规范化的标准.
命名实体识别(NER)是自然语言处理(NLP)中信息抽取任务的一种,在NLP 的基础建设中有着较为广泛的应用.结构化的电子病历需要实体的准确描述,不能存在歧义或表述不明.中文由于没有明确的分隔符,使得实体识别的难度大大增加.就模型训练而言,使用词作为最小粒度还是字作为最小粒度会随着不同的应用场景有不同的效果,难以确定使用哪种方式最好.
就提高命名实体识别的准确率方面,孟捷[2]使用条件随机场CRF 先对文本进行分词,之后对分词结果进行属性标注,并在词典中引入ICD-10 标准,使得实体识别取得了较好的效果.江涛[3]提出了一种兼顾字词并通过自注意力机制延长实体联系距离的WCLSTM 模型,使用Word2Vec 训练的100 维词向量嵌入模型,并与Bi-LSTM 和Lattice-LSTM 模型进行对比.沈宙锋等人[4]基于XLNet-BiLSTM 模型,通过对电子病历的序列化表示,使得一词多义的问题得到了更好的解决.王若佳等人[5]在使用无监督学习的AC 自动机上对中文电子病历进行分词,结合条件随机场和不同的实体类别,得到了较好的识别模板.Zhang 等人[6]为解决中文实体的边界问题,提出了一种基于单词方法和基于字符方法进行识别的方式,在研究中,为解决字符缺乏词级别信息和词边界信息,使用了一种融合自匹配词特征的神经实体识别模型,并在训练集上取得了不错的效果.Ji 等人[7]提出一种句子级的基于多神经网络模型的协同协作方法来进行实体识别,通过Word2Vec、GloVe、ELMo 对特定汉字嵌入预训练,在BiLSTM-CRF 和CNN 模型上进行了模型测试.李丹等人[8]提出了一种部首感知的识别方法,该方法将部首信息编码到字向量中,利用BiLSTM-CRF 结合Bert 模型,使实体识别有一定的提高.
在过去的研究中,大部分研究人员着重在于对文字进行处理,而对标签在文本的上下文中的作用以及文本的预处理结果是否符合规范缺少关注.查阅资料中考虑到,如果可以在研究文字的同时挖掘电子病历标签中的隐含信息,对于命名实体识别工作会有帮助.例如,病历中常用“宫颈癌”作为疾病术语,那么在宫颈一词中被预测为疾病的实体,应该以3 个字的可能性较大,不会出现诸如“宫颈的癌”或“宫颈的癌变”这样的实体,从而提高实体识别的准确性,且多头注意力机制使得模型在训练过程中关注模型感兴趣的部分,对于模型的训练有益.基于以上描述,本文以建立结构化电子病历为目的,从电子病历的实体识别开始研究,提出WT-MHA-BiLSTM-CRF 模型,该模型同时考虑文字和标签中的信息.为保证模型的可信性,将实验结果与BiLSTM-CRF[9],BiGRU-CRF,MHA-BiLSTM-CRF 模型进行了对比.
2 电子病历数据预处理
2.1 类别定义
人工将实体分类分为以下6 个方面: 病症,身体部位,手术,药物,化验检验,影像检验.在测试中发现,如果直接以中文作为类别标签,会导致训练结果较差,因此本文将上述6 个类别使用英文简写代替,病症的标签为DISEASE,身体部位的标签为BODY,手术的标签为OPERATION,药物的标签为MEDICINE,化验检验的标签为LAB-CHECK,影像检验的标签为IMGCHECK.实验期望得到的实体识别效果如图1 所示.
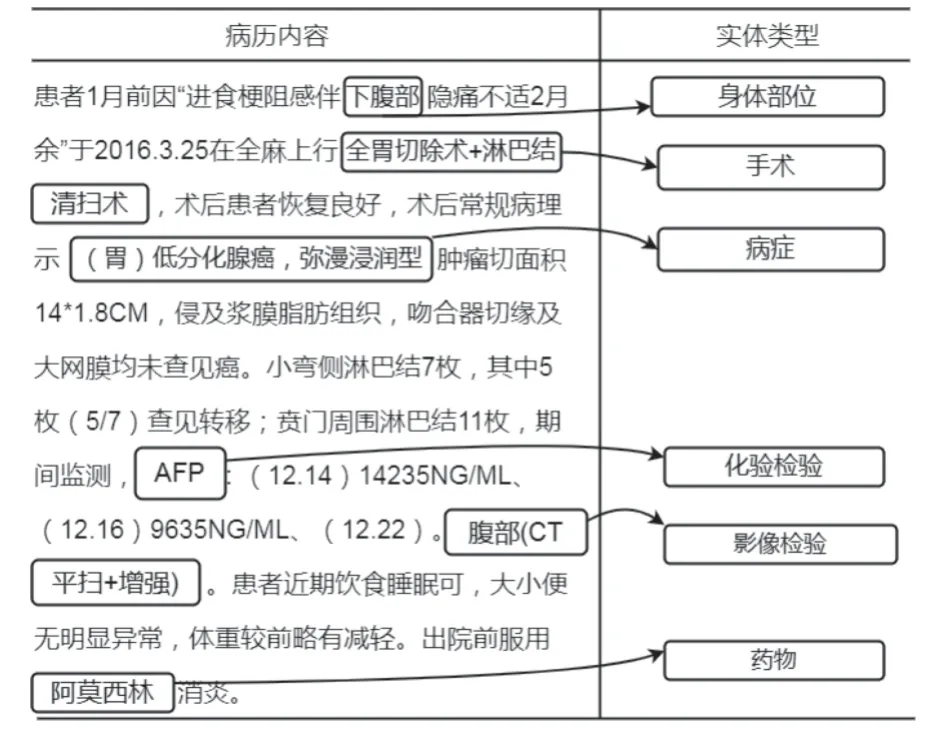
图1 电子病历实体对应关系图
2.2 原始数据清洗
数据清洗的过程主要利用Python 程序将原始文本中的空格,首尾标点符号以及一些错误符号进行删除,并检查人工标记的起始位置和终点位置的实体是否标记有误,例如起始位置开始过早或者终点位置结束过晚等情况.为了防止标点符号的使用不一致情况,本文将原始文本中的标点全部使用英文标点表示.实验发现,没有进行过数据清洗的数据会比进行过数据清洗的数据在训练结果上产生的误差在10%左右,说明对于原始数据进行清洗在模型训练中存在一定的作用.
3 模型结构
本文提出的一种融合文字与标签的WT-MHABiLSTM-CRF 模型结构如图2 所示.在模型中,输入层获取电子病历的每个文字及文字对应的标签,将文字和标签分别建立字典,得到每个字和标签对应在字典中的序号,即向量化表示后的结果,将两者进行结合,输入到multi-head attention[10]中,attention 机制会使得模型在句子中捕捉到更多的上下文信息,其输出结果是在3 个维度上的加权整合,并映射到模型设定的矩阵维度上.该输出的结果作为BiLSTM 模型的输入,BiLSTM 模型根据上下文信息,计算每个字符在每一个类别中的概率值大小.基于BiLSTM-CRF 模型抛弃了Softmax 层并使用CRF 进行代替,CRF 层在训练过程中可以自主学习到一些约束规则,这些约束可以保证预测标签的合理性,CRF 层将BiLSTM 层的输出结果作为输入,进一步约束,得到更加准确的输出结果,整体模型将CRF 的输出作为最后的预测结果,并与标准结果进行比对,计算预测的误差.
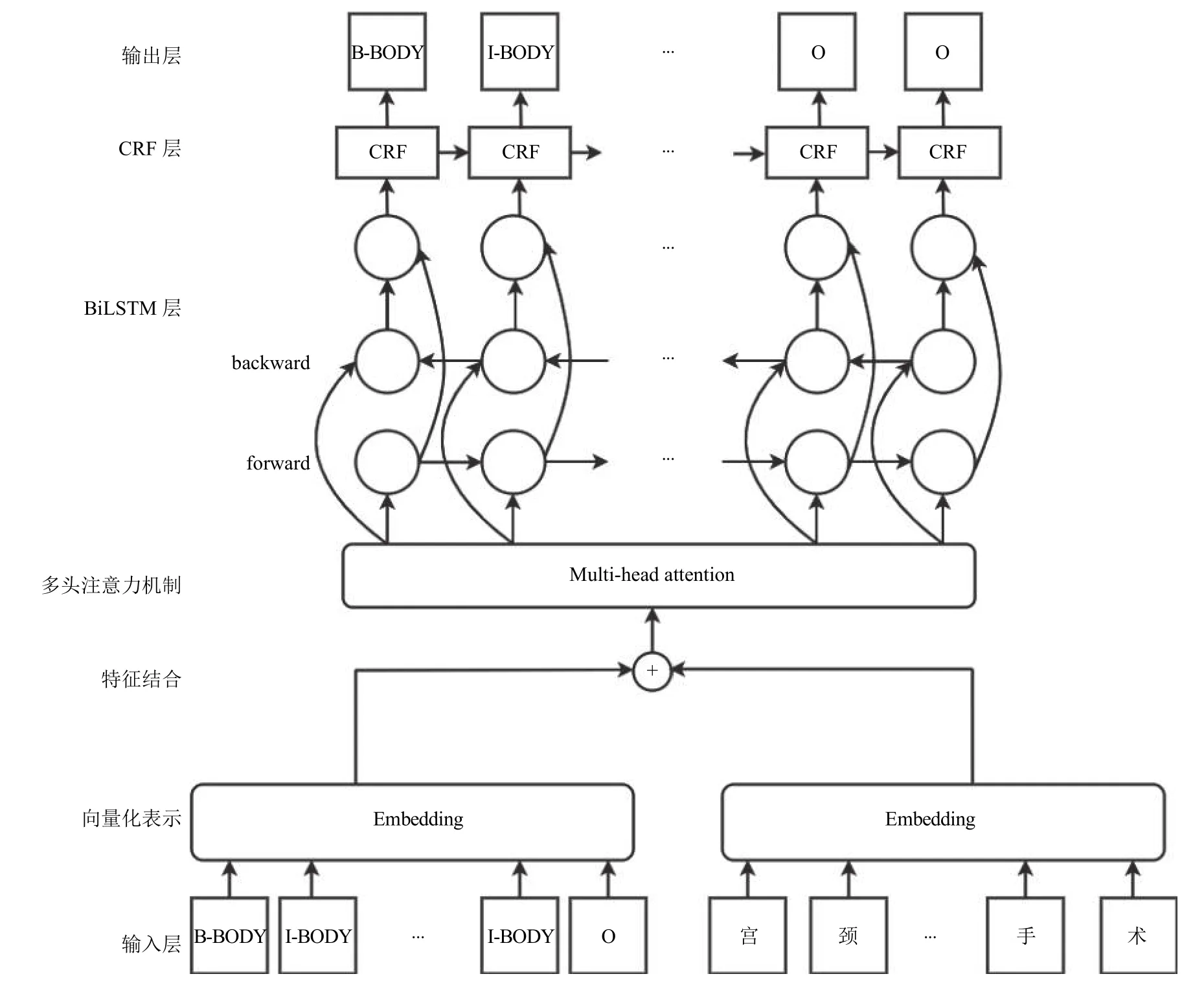
图2 WT-MHA-BiLSTM-CRF 模型结构图
本文提出的模型相对于传统的命名实体识别模型来说,同时关注文字和标签中的信息,使得输入信息更加充分,发现标签中的隐含信息对模型结果带来的价值.
3.1 BiLSTM 模型
双向长短期神经网络(BiLSTM)[11]是一种为解决循环神经网络(RNN)中梯度消失或者梯度爆炸问题而提出的模型,它较好地解决了RNN 在长依赖训练过程中的缺陷.长短期神经网络(LSTM)是一种单向网络,主要使用门机制[12]来解决RNN 中的长期依赖问题,其模型结构如图3 (图中sig 代表Sigmoid 函数)所示.
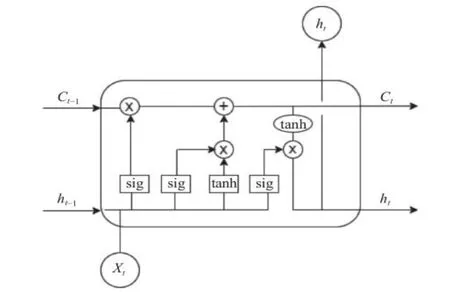
图3 LSTM 模型结构图
LSTM[13]在隐藏单元中提出了3 种门的概念: 输入门,输出门,遗忘门.式(1)和式(2)体现了输入门与单元状态更新的计算公式:
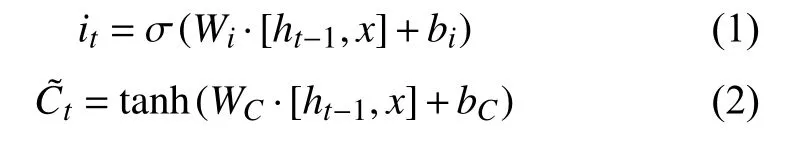
输入门用来确定当前输入中被保存状态的个数,其中,it为输入门,W、b分别表示权重矩阵和偏置向量,σ(·)代表Sigmoid 激活函数,tanh(·)代表tanh 激活函数,其表达式分别为式(3)和式(4)所示.
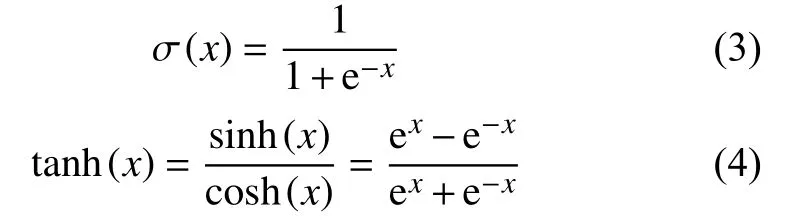
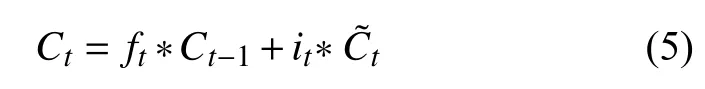
输出门将会决定传输多少个单元状态作为 LSTM的当前输出值,通过计算隐藏节点ht来计算预测值和下一个时刻的输入,式中ot代表输出值.
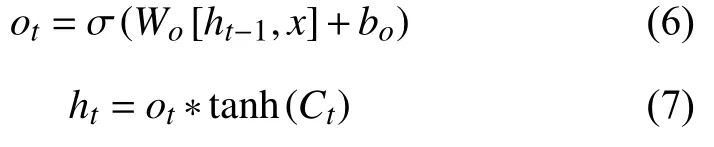
遗忘门负责上一个时刻的单元状态保存多少到当前时刻,表现为Ct-1中哪些特征将被用于计算Ct,遗忘门ft中的每个值位于[0,1]中,计算公式见式(8).
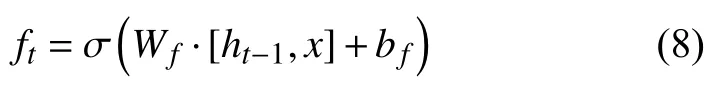
单元状态作为LSTM 中的核心部分,始终贯穿整个计算,其计算表达式为:
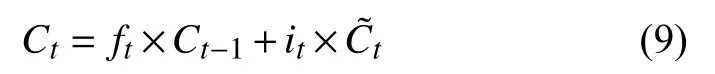
本文使用的BiLSTM 模型相对于LSTM 模型来说,能够在未来上下文的预测中有较好的表现,使得训练不仅能够接受前文的序列也可以得到后续序列,在进行命名实体识别的过程中会有更好的效果.
3.2 GRU 模型
门控循环单元(GRU)也是为了解决循环神经网络存在的长期依赖问题而提出的,模型中使用了更新门和重置门两种门机制,使得模型在训练效果不变的同时,计算更加简单,其计算过程如式(10)-式(13)所示.
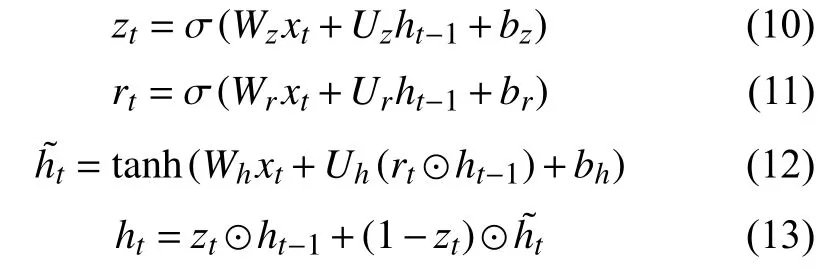
其中,σ(·)、tanh(·)同上述描述,代表哈达马乘积,用于计算两个阶相同矩阵的对应位置,并将它们相乘得到一个新矩阵,zt代表更新门,其作用是决定多少信息从之前状态ht-1保存到当前状态ht,以及在候选状态h~t中得到多少信息.rt代表重置门,决定了候选状态h~t的计算是否依赖于之前状态ht-1.
3.3 Multi-head attention 原理
由于单层的attention 所包含的信息可能不够支持众多的下游任务,因此2017年谷歌推出的Transformer将其堆叠成multi-head attention (MHA),其本质是多次的self-attention[14]计算.Attention 机制[15]会使网络在训练过程中更多的注意到输入包含的相关信息,而对无关信息进行简略,从而提高训练的准确性.
Self-attention 对输入的每个词向量创建3 个新向量:Query、Key、Value,这3 个向量分别是词向量和Q,K,V三个矩阵乘积得到的,Q,K,V三个矩阵是一个需要学习的参数,其定义如下所示:
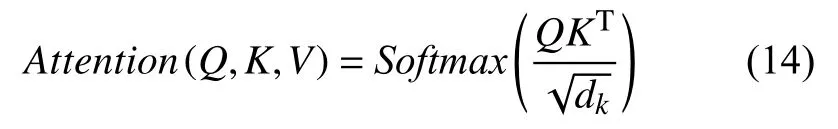
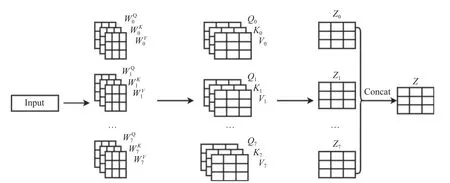
图4 Multi-head attention 计算过程图
MHA 定义如式(15)所示:
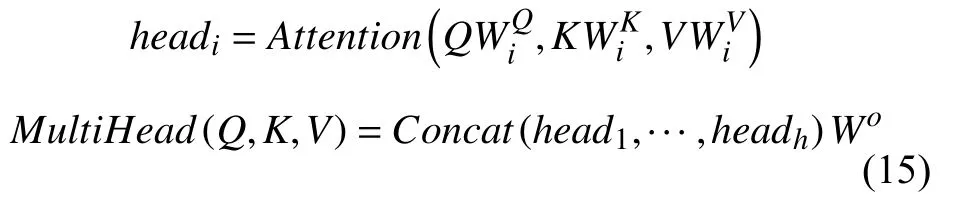
其中,WiQ,WiK,WiV是需要训练的参数权重,Wo属于Rdmodel×hdV,dmodel代表了模型中Q,K,V的维度,Concat()代表拼接函数,用于将多层的Q,K,V函数拼接起来.
3.4 CRF 模型
条件随机场(CRF)[16]是一种较为经典的条件概率分布模型,通过观测序列X=(x1,x2,···,xn)来计算状态序列Y=(y1,y2,···,yn)的条件概率值p(y|x),CRF 的简化定义公式如下:

其中,w代表权值向量,F(y,x)表示全局特征函数.CRF 模型可以自主的学习到文本中的约束,例如在命名实体识别[17]中,I-标签的后面不会出现B-标签,O 标签的后面不会出现I-标签等,这些约束会帮助训练结果更加合理.
CRF 模型通过式(17)得到评估分数,式中Emit代表BiLSTM 输出的概率,Trans代表对应的转移概率.
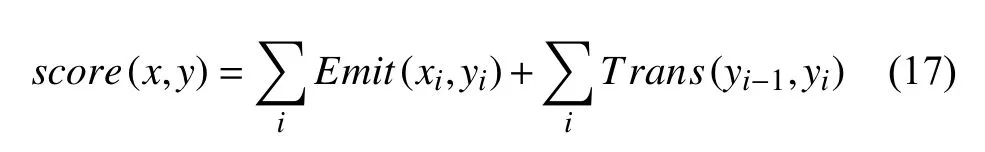
最后模型使用最大似然法来进行训练,相应的损失函数为:
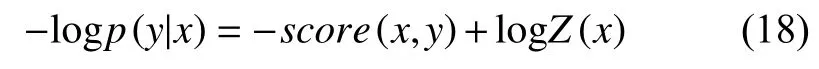
由于Z(x)无法直接计算,因此使用前向算法进行推导,在深度学习框架中可以对损失函数进行求导或者梯度下降的方法来优化,使用Viterbi 算法进行解码,从而找到最优结果.
4 实验及结果分析
4.1 实验数据集
实验过程中比较了4 种模型的训练情况,使用人工标注过的1 000 份数据集,按照6:2:2 的比例将数据划分为训练集、验证集、测试集.在实体识别中常用的实体标注方式[18]包括BIO、BIOE、BIOES 等,本实验使用BIO 标注方式,具体的标注情况与实体数量见表1 和图5 所示.根据第2.2 节中所述,数据集的准确性对模型最终结果存在影响,因此实验对原始数据进行预处理,主要包括中英文统一,利用程序检查原始数据集中是否有启始位置错误信息,并针对错误信息进行修改.
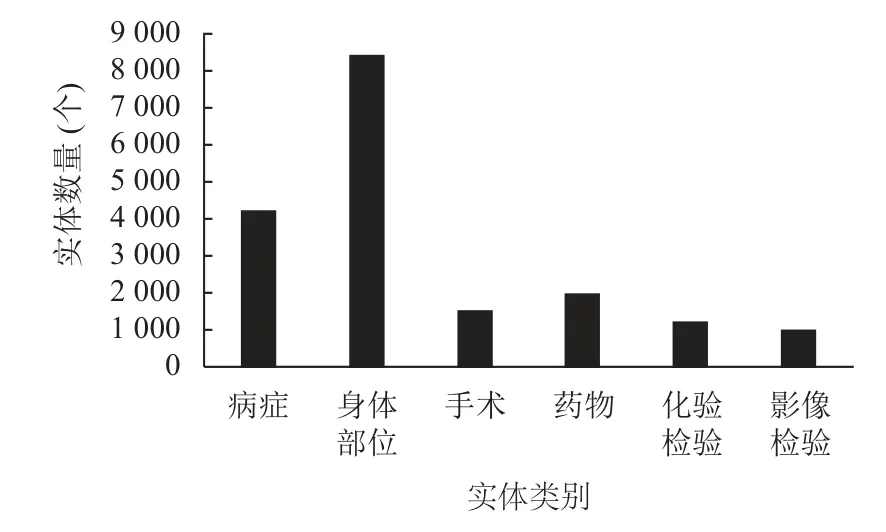
图5 实体数量图
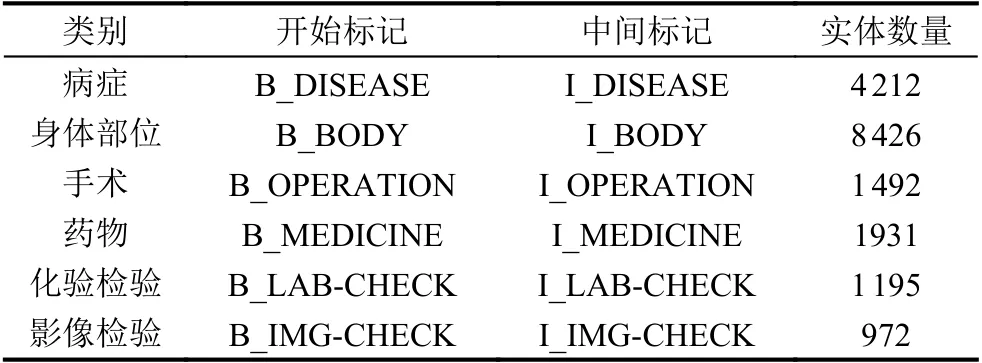
表1 数据标注表
4.2 数据集评价指标
实验使用精确率(结果中的P值)、召回率(结果中的R值)和F1 值作为模型评价指标,其中精确率代表在所有预测结果中为正确的个数在实际正确分类所占的比例; 召回率代表所有预测正确的结果在实际正确中的占比;F1 值使用加权和平均来保证两者在结果中的作用,由于综合考虑了精确率和召回率的结果,因此F1 的值往往作为实验结果的最有力的证明,其值越高说明实验的效果越好,三者的计算过程见式(19)-式(21).
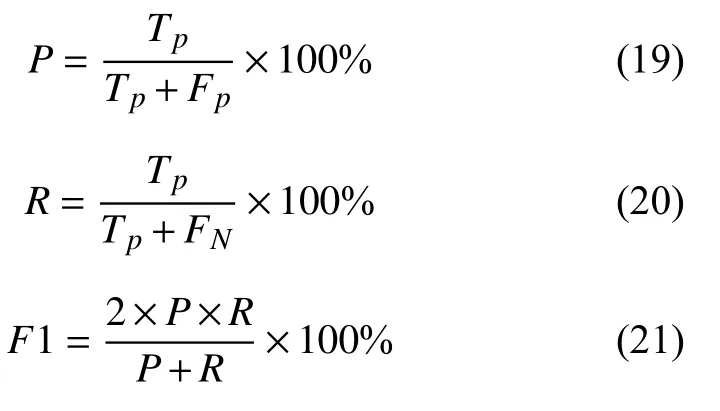
其中,Tp表示在测试集中正例被正确分类的个数,Fp代表负例被错误分类为正例的个数,FN表示正例被错误分类为负例的个数.
4.3 实验环境与结果
本文中命名实体识别模型基于PyTorch 框架,详细实验环境设置见表2 所示.

表2 训练环境表
训练中模型的详细参数为: 每次训练选取的样本数batch_size 值为64,学习率lr 设定为1E-4,训练轮数epoch 设置为30,时序模型的网络层数设置为1,词向量维数为128,使用Adam 优化器,丢失率dropout 值为0.5.
本文对4 种模型进行了测试来增强模型结果的说服力,4 种模型定义如下.
(1)BiLSTM-CRF: 使用单层的BiLSTM 网络,并将模型的输出结果直接作为条件随机场的输入计算最终结果.
(2)BiGRU-CRF: 使用单层的BiGRU 模型,将输出结果投入CRF 计算.
(3)MHA-BiLSTM-CRF: 对字向量做Embedding后先进入mutli-head attention 模型中,模型输出的结果作为BiLSTM 模型的输入,其结果作为CRF 层输入.
(4)WT-MHA-BiLSTM-CRF: 同时对字、标签做Embedding,将两者结合,作为mutli-head attention 的输入,之后进入BiLSTM 模型训练,最终进入CRF 层进行训练.
表3 展示了4 种模型在各个实体上的精确率、召回率和F1 值,从结果来看,WT-MHA-BiLSTM-CRF 在大多数的实体分类结果上均有一定的提高,与BiLSTMCRF 模型的比较中,在病症方面F1 值提高了3%,身体部位提高了6%,手术提高了4%,化验检验提高了7%,影像检验提高了11%.但是在药物的类别方面,WT-MHA-BiLSTM-CRF 的结果与其他模型相比有些下降,初步分析原因是,由于本文提出的模型是针对字和标签同时作为模型的输入来进行训练,并且经过attention 机制的处理,在实验过程中,可能过度的对某些字、标签产生了过度的关注,而使得分类结果产生了误差,因而导致分类效果的下降,在以后的研究中会针对这一方面进行深入研究.最后,图6 展示了WTMHA-BiLSTM-CRF 模型在各个实体中的预测结果.
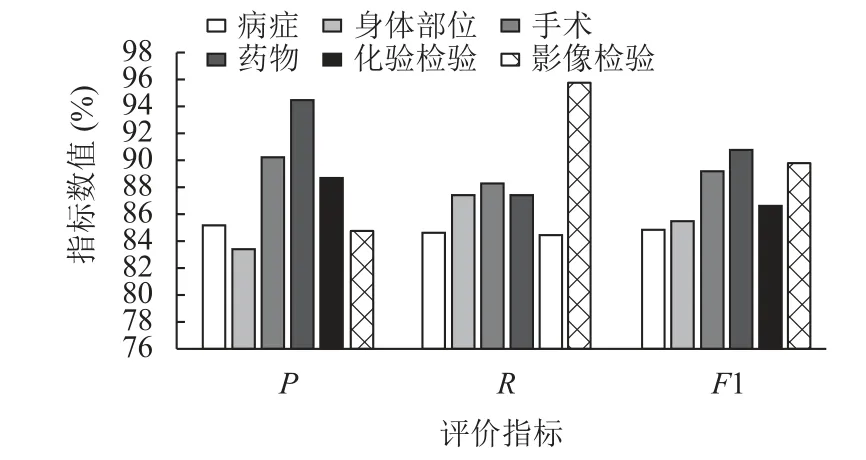
图6 WT-MHA-BiLSTM-CRF 模型各类别结果图

表3 实验结果表(%)
5 结论与展望
本文提出了一种结合字与标签同时训练的WTMHA-BiLSTM-CRF 模型,用于解决结构化电子病历中命名实体识别的问题.传统的BiLSTM-CRF 模型更多的注重字在模型中训练产生的结果,忽略了标签中可能隐含的信息,因此在训练输入之前,将字和标签同时做Embedding 处理.并使用mutli-head attention 使模型更多的注意力放在关键的字和标签上,BiLSTM 结合上下文得到每个字的类别概率,模型的最后使用CRF对分类结果进行处理,使得模型的预测输出更有说服力.从实验结果中可以看出,该模型在大部分的类别识别中均有提升.对于个别类别来说,考虑到模型的结果中可能有部分信息被过度关注,导致训练结果上有些许问题,在以后的研究中也会针对这个问题着重来处理.
