基于多尺度高阶注意力机制的视网膜血管分割①
2022-11-07姜璐璐李思聪曹加旺孙司琦邹海东
姜璐璐,李思聪,曹加旺,孙司琦,冯 瑞,,邹海东,4
1(复旦大学 工程与应用技术研究院,上海 200433)
2(上海交通大学附属第一人民医院,上海 200080)
3(复旦大学 计算机科学技术学院,上海 200433)
4(苏州市产业技术研究院,苏州 215011)
1 引言
血管系统是视网膜的基本结构,其形态学和拓扑结构的变化可以用来识别和分类系统性代谢和血液疾病的严重程度,例如糖尿病和高血压[1].糖尿病性视网膜病变 (DR)是糖尿病的一种常见并发症,是由视网膜微血管渗漏和阻塞导致的一系列眼底病变.DR 可引起新血管的生长,是否有异常新生血管也是判断增殖性DR 与非增殖性DR 的标准[2].高血压视网膜病变 (HR)是另一种常见的由高血压引起的视网膜疾病[3].在高血压患者中,可以观察到血管弯曲度增加或血管狭窄[4].通过视网膜血管获得的血管形状和分叉的信息,可以增强对DR 或者HR 的监测.因此,分割视网膜血管对于一些严重疾病的早期诊断与治疗具有重要意义.
现有的眼底视网膜成像技术有以下几类: 彩色眼底照相 (FP)技术、眼底荧光素血管造影 (FFA)、光学相干断层扫描 (OCT)以及眼底相干光层析血管成像(OCTA).彩色眼底照相是最常用的视网膜成像技术,其优点是获取方式简单、图像易于观察.
传统的无监督方法一般包括: 滤波匹配法、区域生长、血管跟踪、阈值分割和图像形态学处理等.这些传统的无监督方法不需要人工标注,但这些方法依赖于手工提取特征进行血管表示与分割.此外,此类算法存在分割精度不够、泛化性较差等局限性.
与传统的无监督方法相比,深度卷积神经网络方法具有更强大的特征表征和学习能力,在医学图像分割任务中取得了最高水平[5].自2015年引入U-Net[6]以来,它已成为医学影像分割中最具影响力的深度学习框架[7-10].其整体网络采用编码器-解码器的结构,通过“跳跃连接”将不同分辨率的特征图进行通道融合产生较好的分割效果.尽管U-Net 具有良好的表示能力,但它依赖于多级级联卷积神经网络.这种方法在重复提取低层特征时会导致计算资源的过度和冗余使用[11].
注意力机制被提出用于解决以上问题,其模仿了人类视觉所特有的大脑信号处理机制,令网络从大量信息中重点关注对任务结果更重要的区域,而抑制其他不重要的部分[12].在视网膜血管分割任务中,背景像素占比较大,而血管像素的占比小,因此可以采用注意力机制关注血管区域.卷积神经网络可以利用不同类型的注意力机制以关注重要的区域或者特征通道[13-18].例如,空间注意力机制[11,18]利用特征的空间关系生成空间注意力图从而使网络关注具有丰富信息的区域,通道注意力机制[13]通过显式建模通道间的依赖关系来提高模型的性能.空间注意力和通道注意力的融合[15]也已成功地应用于医学分割领域.
然而,这些常用的方法是一阶注意力机制,难以提取图像中一些更为抽象的高阶语义信息且不能充分利用到全图像的信息,导致在处理形状和结构复杂的目标时发生退化[19].尤其在视网膜血管分割任务中,由于血管形态结构多变,以上方法仍欠缺对复杂和高阶特征信息的捕获能力.
本文提出了一种基于多尺度高阶注意力机制的视网膜图像分割方法(MHA-Net),可以明显提高视网膜血管的分割精度.该方法采用改进的U-Net 结构,并引入多尺度高阶注意力模块,对编码器提取到的深层特征进一步处理,聚焦于图像的高阶语义信息,从而改进模型处理医学图像分割时尺度不变的缺陷.经过在DRIVE[20]数据集上的实验证明,该方法有效地提高了分割的精度,同时对细小血管的分割也更为精细.
2 相关工作
2.1 空洞卷积在图像分割中的应用
空洞卷积(dilated convolution)[21,22]通过在卷积核相邻两个元素之间插入零值,在不增加参数量和计算成本的同时扩大了感受野.受空洞空间金字塔池化(ASPP)[23]在语义图像分割中的应用启发,空洞卷积在医学图像分割中同样得到了广泛的应用[17,24].但是,基于空洞卷积的分割方法都存在一个共同问题,稀疏采样会造成详细信息的丢失,从而导致像素级分类不准确.D-LinkNet[25]利用“短路连接(shortcut)”结合了文献[21]的级联模型与文献[1]的并行模型.
之前的研究主要集中在通过增加在不同尺度特征图上的感受野,从而直接提高分割网络的性能.我们的工作与上述方法不同,我们利用空洞卷积对不同尺度的特征图进行采样,并通过聚合这些多尺度的特征图产生高阶注意力图,从而进一步使网络聚焦于更加抽象和全面的语义信息.
2.2 高阶注意力
注意力机制的思想核心是通过计算权重矩阵而使网络有选择地关注具有重要信息的部分[12].Okty 等人[11]提出了用于医疗影像分割的注意力门控(attention gate,AG)模型,该模型可以自动学习区分目标的外形和尺寸,在小目标分割任务中效果尤其显著.不同于在跳跃连接中添加注意力门控(AG)的方法,SA-UNet[14]引入了一个空间注意力模块,通过在空间维度计算注意力权重矩阵并与输入的特征图相乘,实现自适应地细化特征.该方法是注意力模块在U 形分割网络降采样后的深层特征图上的一种应用.Chen 等[19]首先提出了高阶注意力模型,并将其应用于行人重识别建模.该模型利用注意机制中形成的复杂高阶统计量,捕捉行人之间的细微差异,从而产生区别性的关注建议.Ding 等[26]利用图的传递闭包进一步优化高阶注意力模块,在此基础上提出具有自适应感受野和动态权重的high-order attention (HA)模块.HA 模块通过图的传递闭包构建注意力图,从而捕获高阶的上下文相关信息.
之前的一些工作(如文献[13])通过在U 型网络的底部引入注意力机制来进一步挖掘深层次的特征.然而,这些网络更多地关注了局部信息,而忽略深层特征中的全局信息.这导致尽管在提取深层特征时添加了几种不同类型的注意力模块,也不能有效地提高医学图像分割任务的性能.相反,模型的性能甚至会略有下降.
本文的工作是在上述注意力机制[14,19,26]上的改进.在U 形网络的多个降采样块之后所得的深层特征的噪声相对较小,因此注意力模块需要尽可能地挖掘深层特征中的全局信息.另一方面,与浅层特征相比,在深层特征中引入噪声会对整个模型造成更大的损害.因此,本文设计了多尺度高阶注意力(MHA)模块,其在不引入噪声的前提下引导网络提取深层特征中的更为全局的信息,有效提高了视网膜血管中分割性能.
3 基于多尺度高阶注意力机制的分割网络
3.1 网络框架
图1 给出了基于多尺度高阶注意力机制的视网膜图像分割方法(MHA-Net)的网络架构,其遵循了编码器-解码器的U 型结构.编码器包含若干个下采样块和MHA 模块,其中每个下采样块由1 个3×3 的卷积层、1 个批处理规范化层和一个ReLU 激活函数层组成,3 个下采样块连接在一起后紧跟一个2×2 的最大池化操作.在下采样完成之后,将提取到的图像深层次特征输入到MHA 模块进行细化,MHA 模块的位置放置于网络底部,即U 型收缩路径和扩张路径之间.在此处加入attention 模块的原因是在靠前位置采集到的为低层次结构信息,包含有许多噪声.此外,加权的shortcut 被引入以保留原本的上下文信息.最后,经过融合得到的特征图通过编码器产生最终的分割结果.解码器部分使用反卷积[27]进行上采样操作.

图1 MHA-Net 架构图
3.2 多尺度高阶注意力模块
本文提出的多尺度高阶注意力模块如图2 所示.在编码器的底部,原始的特征图Xin∈RH×W×C通过并行的共享权重的空洞卷积(膨胀率r分别为1,2,4,8),产生新的多尺度特征图分为为Xr(r=1,2,4,8),通过1×1 卷积得到的特征图为X*.将这些多尺度特征图使用式(1)计算得到融合的多尺度注意力矩阵:

图2 多尺度高阶注意力(MHA)模块
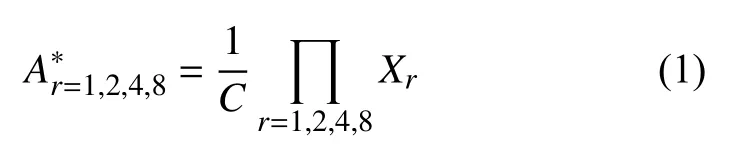
其中,1/C是用来控制数值爆炸的缩放因子.之后,利用图的传递闭包计算了多尺度高阶注意力矩阵A,m∈{1,2,···,n}.具体计算的细节将在第3.3 节讨论.最后,将特征图X*与归一化的高阶注意力矩阵相乘得到细化的特征图Xm,如式(2):

Γθ代表1×1 卷积.在多尺度高阶注意力模块之后,将细化后的特征图Xm乘上自适应因子 α以抵消缩放因子1/C的偏移影响,如式(3):
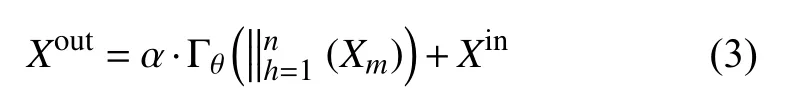
深层特征图在通过多尺度高阶注意力模块之后,提取了更加高阶抽象的语义特征,也更具有区分力,从而更聚焦于血管的分割.之后,再通过解码器模块,逐渐从低分辨率重构至高分辨率.
3.3 高阶注意力传播机制
根据文献[26],最初的多尺度注意力融合矩阵可以看做图的邻接矩阵,图中的边表示连接的两个节点属于同一类.如图3 所示,给定注意力图,通过阈值化删去低置信度的边后形成下采样的图如式(4):
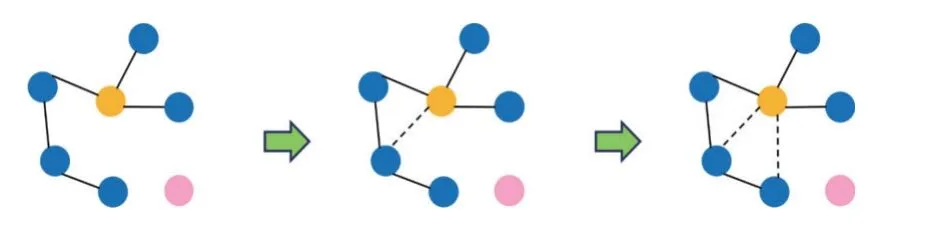
图3 三阶高阶注意力传播原理图: 以黄色点为中心点通过图的传递闭包进行传播
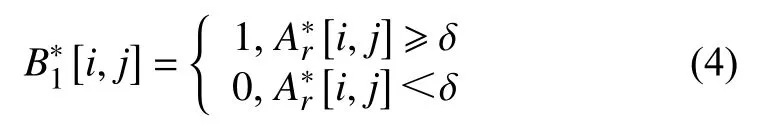
其中,δ代表阈值,设置为0.5.如图4 所示,根据图的传递闭包,可以通过邻接矩阵自乘m-1 次得到:


其中,m表示邻接矩阵幂次的整数,代表注意力传播的阶数.因此,不同层次的注意力信息通过解耦成不同的注意图并得到高度相关的邻居.生成的高阶注意图用于聚合多层次的上下文信息.
4 实验验证与结果分析
4.1 数据集与实验参数
本文使用的数据集是DRIVE (digital retinal image for vessel extraction)[20].该数据集包含40 张图像像素尺寸为584×565 的彩色眼底图像,其中训练集与测试集各20 张.为扩充数据,避免训练样本过少可能造成的过拟合问题,我们对训练样本随机采样256×256 的patch.此外,使用随机翻转、随机旋转、弹性形变等方法进行数据增强.本文使用PyTorch 框架[28],批量设置为 16,采用Adam 算法[29]优化模型,学习率设置为0.000 1.动量和权重衰减因子分别设置为0.9 和0.999.
4.2 评价指标
为了对实验结果进行客观的定量分析,选取以下指标进行计算: Dice 系数(DSC)、准确率(ACC)、敏感度(SE)、特异性(SP)和ROC 曲线下面积AUC.AUC 的范围在0-1 之间,AUC 越逼近 1,其模型预测能力越高.评价指标的计算方式如下:

其中,X代表金标准,Y代表预测结果.真阳性TP为正确分类的血管像素个数,真阴性TN正确分类的背景点像素个数,假阳性FP为背景像素误分成血管像素的个数,假阴性FN为血管像素误分成背景像素的个数.
4.3 实验结果分析
本文算法性能在DRIVE 数据集上评估,图4 展示了部分分割结果.图4(a)为原始图像,图4(b)为金标准图像,图4(c)为本文算法的分割结果,从结果可以看出,本文算法整体分割效果良好,平滑度也优于金标准.同时,本文算法细节上表现优秀,保持了微血管的连通性,说明本文中采取的注意力机制能够关注到重要的血管区域.

图4 DRIVE 数据集分割结果
为了验证本文所提出的模型性能的优越性,表1将本文算法与近两年最先进的血管分割算法的各项指标进行对比,其中加粗字体部分为每项最优指标.
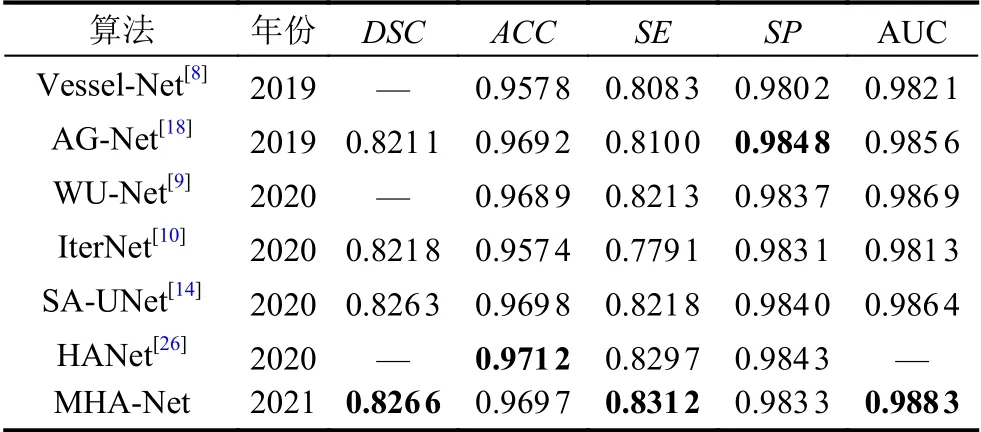
表1 DRIVE 数据集上不同算法分割性能比较
结果表明,本文提出的多尺度高阶注意力方法MHA-Net 取得了优异的表现,其Dice 系数、灵敏度和AUC 分别达到了0.826 6、0.831 2 和0.988 3,在所有方法中表现最优.本文算法在保证高准确率的同时,有着良好的敏感度,这意味着分割结果尽可能地保留血管信息,分割得到的血管连续完整.综上所述,本文算法整体性能优于现有算法.
为了证明提出的多尺度高阶注意力(MHA)模块的有效性,在DRIVE 数据集上还进行了消融实验.表2展示了U-Net、U-Net+MHA、Backbone、Backbone+HA 以及MHA-Net 的分割性能.其中U-Net+MHA 表示在U-Net 基础上引入MHA 模块的网络,Backbone表示在本文使用的骨干网络,Backbone+HA 表示与本文相同的骨干网络上引入原始的高阶注意力HA 模块,MHA-Net 为本文算法,相当于Backbone+MHA,即在本文使用的骨干网络上引入多尺度高阶注意力MHA 模块.
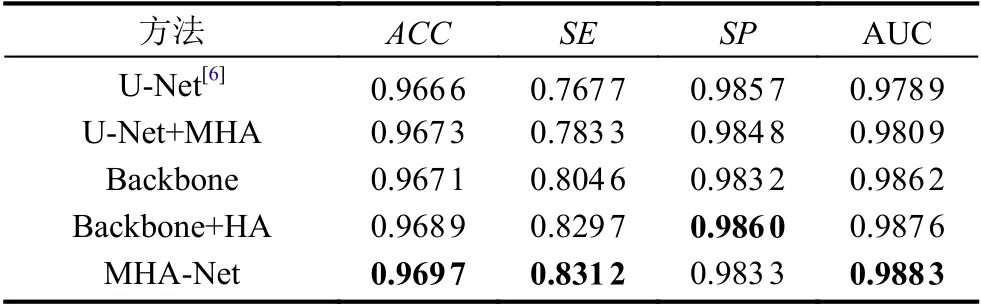
表2 DRIVE 数据集上的消融实验
结果表明: (1)U-Net+MHA 比U-Net 有更好的性能,准确率提高0.07%,敏感度提高1.56%,AUC 提高0.20%,这证明了本文提出的多尺度高阶注意(MHA)模块的有效性.(2)MHA-Net 在准确率、灵敏度和AUC 指标上都优于Backbone+HA,这表明多尺度高阶注意力模块对多尺度上下文特征信息捕捉能力更强,对复杂结构的血管图像有更强的特征提取能力.(3)本文提出的MHA-Net 在大多数指标上都表现最好,在视网膜血管分割领域全面优于U-Net,说明该网络模型的合理性和优越性.
此外,对实验结果进行了可视化分析,如图5 所示,从左至右依次是原始图、金标准、U-Net 分割结果、Backbone+HA 分割结果以及MHA-Net (本文)分割结果.我们放大了微血管,本文提出的MHA-Net 分割结果更加精细,在血管末也未出现粘连或者断裂的情况.

图5 DRIVE 数据集分割结果对比
5 结论与展望
本文针对视网膜血管分割任务中血管粗细不匀、形状多变、微小血管易断裂等问题,本文提出多尺度高阶注意力(MHA)机制以自适应地挖掘深层次特征.MHA-Net 以端到端方式进行视网膜血管分割训练,并通过MHA 模块学习到具有鉴别性的特征.在DRIVE上的实验表明,本文提出的算法取得了优越的分割性能.同时,MHA 模块可以即插即用,在各种医学影像分割任务中适用.后续的工作将尝试把多尺度高阶注意力机制运用到三维的影像分割中.
