基于改进GraphSAGE的高光谱图像分类①
2022-11-07尤晨欣吴向东王雨松欧运起
尤晨欣,吴向东,王雨松,欧运起
1(长安大学 信息工程学院,西安 710064)
2(长安大学 公路学院,西安 710064)
近年来,高光谱图像分类在军事目标检测和灾害防控等领域受到越来越多的关注[1].与传统的多光谱遥感图像相比,高光谱图像由数百个光谱波段组成,有助于更加精细地实现地物分类和目标识别.高光谱图像具有较高的空间分辨率,可以识别各种土地覆盖类型[2].早期的高光谱图像分类方法旨在提升分类性能,比如支持向量机[3]等; 之后,出现一些利用特征提取技术进行高光谱图像分类的方法探索地物表面的空间信息,如基于空间光谱稀疏表示的方法[4]等,通过建立函数映射以期分离高维空间中的光谱信息,实现地物分类.早期的高光谱图像分类方法中的图结构均为人工构造,无法捕捉不同类之间的细微差别和同类之间的大差别,普适性差且分类精度较低.深度学习为高光谱图像的特征提取提供了理想的解决方案[5].
深度学习可以从数据中自适应地提取高光谱图像的光谱空间特征,具有很好的鲁棒性.Chen 等[6]采用卷积神经网络从高光谱图像中提取空间光谱特征,获得了更好的分类性能; Qin 等[7]提出利用半监督图卷积网络将高光谱图像编码成图结构,并根据相邻像素的光谱相似性和空间距离在像素之间传播信息; Wan 等[8]提出上下文感知的动态图卷积网络,用于捕获远程上下文关系,细化图边缘权值和图像区域之间的邻接关系; Mou 等[9]提出将整张图像作为输入,同时处理标记和未标记样本数据,对图像中的所有像素节点进行分类处理; Sellars 等[10]提出一种基于图论的超像素高光谱图像分类算法,降低了算法复杂度.此外,通过多尺度和小批次处理高光谱图像成为近期研究的热点,建立不同邻域的多个输入图,利用不同尺度的光谱空间相关性细化图信息[11-13]; Yang 等[14]通过GraphSAGE 归纳学习的方式构造图结构,对于采样节点数不足的情况,采取有放回的节点采样方法,可能造成子图中的局部信息不完整,导致特征模糊,从而使算法的分类误差增大.
为了充分利用图结构的空间相关性,本文提出了基于改进GraphSAGE 的高光谱图像分类方法.首先采用简单线性迭代聚类算法(simple linear iterative clustering,SLIC)[15]将高光谱图像分割为超像素,降低后续学习的图节点数; 再通过改进的GraphSAGE 算法生成目标节点的嵌入,利用平均采样得到训练样本,选取平均聚合函数更新多阶节点的信息.通过提取空间光谱信息来提高性能,既无须对整张图进行节点嵌入,也最大化保留了局部图结构的信息,从而提高算法的分类精度.
1 GraphSAGE 算法介绍
传统的图卷积网络主要是在单一固定的图像中进行节点嵌入,无法为未见节点或者全新子图生成快速嵌入.为解决这种问题,Hamilton 等[16]提出了GraphSAGE算法,通过学习一个嵌入函数,利用节点的局部邻域取样和聚合特征,实现未见数据的生成嵌入.其流程如图1 所示.
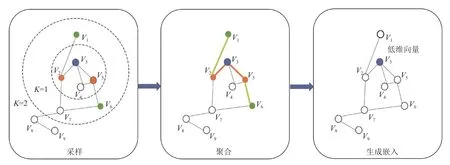
图1 GraphSAGE 算法流程
对于已知无向图G=(V,E),其中,V表示节点集,E表示边集.所有的节点v∈V,需要学习K个函数来聚合当前节点的邻域特征,具体做法如下.
(1)采样: 通过随机游走的方式获取目标节点,考虑到计算效率,以有放回采样的方式抽取目标节点的K阶样本,设置固定数量的邻居,步骤如图1 所示.K表示目标节点的搜索深度.
(2)聚合: 通过选取聚合函数聚合邻居节点,更新自身节点信息.本文选取平均聚合的方式对邻居节点进行聚合,将目标节点与邻居节点的第K-1层向量拼接起来,再对向量的每个维度求均值,最终通过非线性变换产生目标节点的第K层表示向量,具体实现如下:

其中,N(v)表示节点v的近邻点,表示节点v的任意相邻节点u在k-1层的嵌入信息,hN(v)表示节点v在第k层中所有邻居节点的特征表示.
通过聚合后节点特征用于不同层之间的信息传播,定义如下:

其中,σ是非线性激活函数,Wk是需要学习的权重表示.
图卷积网络的节点嵌入需要所有节点参与训练过程,而GraphSAGE 算法通过聚合邻居节点的特征信息,为局部图节点获取嵌入向量.新的图结构的节点嵌入只需利用学习的聚合函数,就能输出低维向量,进行节点分类.
2 改进GraphSAGE 的高光谱图像分类算法
2.1 总体架构
本文总体架构流程如图2 所示.对于给定的高光谱图像,先对其进行预处理,采用SLIC 算法将其分割成若干同质的超像素; 然后采用改进的GraphSAGE 算法对这些超像素进行平均采样并聚合节点信息,使同类的超像素聚合到一起,再对输入图生成节点嵌入; 最后将生成的低维向量输入到全连接层进行分类,再输出分类结果.
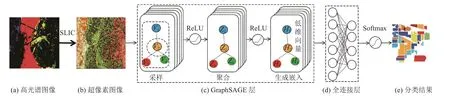
图2 改进GraphSAGE 网络架构
2.2 超像素分割
高光谱图像通常包含数十万像素,且某些像素的差别不明显,在节点嵌入和分类过程中容易增大计算复杂度.为了解决这个问题,采用SLIC 算法实现超像素分割,实现过程如下: 首先将原始图像数据进行均值标准差标准化,再将其分割成空间连通且光谱相似性很强的均匀图像区域,即超像素; 其次将超像素的中心表示为一个图节点,并通过梯度下降法更新节点矩阵;最后通过建立超像素之间的邻接关系,将高光谱图像转换成无向图,构造超像素图像的特征以及标签.将高光谱图像分割为超像素能显著减少图节点的个数,有助于保存局部结构信息,提高计算效率.
2.3 改进的GraphSAGE 算法
由于在采集高光谱图像的过程中不可避免地会引入一些噪声,且其边缘部分的像素分布不均匀,因而传统的GraphSAGE 模型采集的样本具有短缺性和随机性.针对传统GraphSAGE 算法中图像边界采样节点数不足以及有放回的采样引起特征误差的问题,本文提出平均采样的GraphSAGE 模型,采样过程的具体实现流程如算法1 所示.
算法1 改进GraphSAGE 算法的平均采样具体思想是: 每一次迭代,对目标节点v的k阶邻居节点进行采样,V(k)表示第k层的节点,K表示采样的层数.对目标节点采样时按照k=K,···,1的顺序,以达到聚合过程中按照k=1,···,K的顺序聚合的目的.若节点u是V(k)的邻居,则取为邻居节点.若阶层节点个数达不到采样值,取本阶层节点的平均光谱特征作为补充,此过程可以表示为式(3):
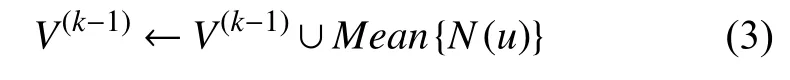

算法1.超像素的邻居采样输入: 图; ; 搜索深度 ; 平均采样函数输出: 平均采样邻居样本G{V,E}v∈VKN()V(k)←V 1)2)for do k=K,···,1 V(k-1)←V(k)3);u∈V(k)4)for do V(k-1)←V(k-1)∪Mean{N(u)}5)6)end 7)end
结合本文提出的平均采样的思想,介绍模型具体实现流程,如算法2 所示.
算法2 的核心内容是: 先根据平均采样的方式抽取固定数量的邻居节点,然后学习聚合函数对邻居节点的信息进行聚合得到信息; 最后获得图中每个节点的低维向量表示供下游学习.经过改进的GraphSAGE 层得到的低维向量作为全连接层的输入,经过Softmax 激活函数,预测目标节点的标签,从而得到真实值与分类输出值之间的差异; 最后使用NLL loss 损失函数进行反向传播.
NLL loss 函数如式(4)所示:
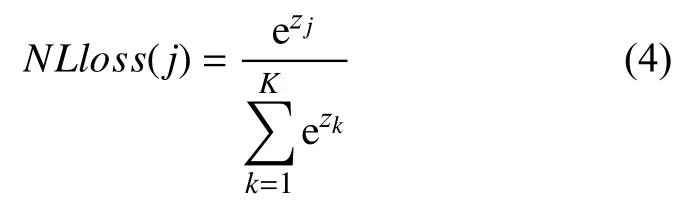

算法2.平均GraphSAGE 节点嵌入G(V,E)Wk ∀k={1,···,K}σ()N()输入: 图; 搜索深度K; 权重矩阵 ; ; 非线性激活函数 ; 平均聚合函数; 平均采样函数zv输出: 生成向量表示h0v←Xv,∀v∈V(0)1)初始化:2)for do k=1,···,K v∈V(k)3)for do 4)hkN(v)←Mean({hk-1 u ,∀u∈N(v)})v ,hkN(v)))5)hkv←σ(Wk·CONCAT(hk-1 6)end hkv←hkv/‖hkv‖2 7)zv←hkv,∀v∈V 8)9)end
3 算法仿真分析
3.1 数据集
为了验证本文所提网络模型的有效性,在公开的Pavia University 和Kenndy Space Center 数据集上进行实验,并和其他算法的分类结果进行了对比.
(1)Pavia University 数据集,见表1.该数据集是意大利帕维亚城的一部分高光谱图像.图像具有610×340 个像素以及115 个光谱波段,空间分辨率为1.3 m,去除受噪声和水汽影响因素后剩余103 个波段,包含9 个地物类别.

表1 Pavia University 数据集训练、测试样本数
(2)Kenndy Space Center 数据集,见表2.该数据集是在美国肯尼迪航天中心上空获得的,图像包含224 个波段和614×512 个像素.空间分辨率为18 m,去除水汽和受噪声影响的波段后剩余176 个波段,包含13 个地物类别.
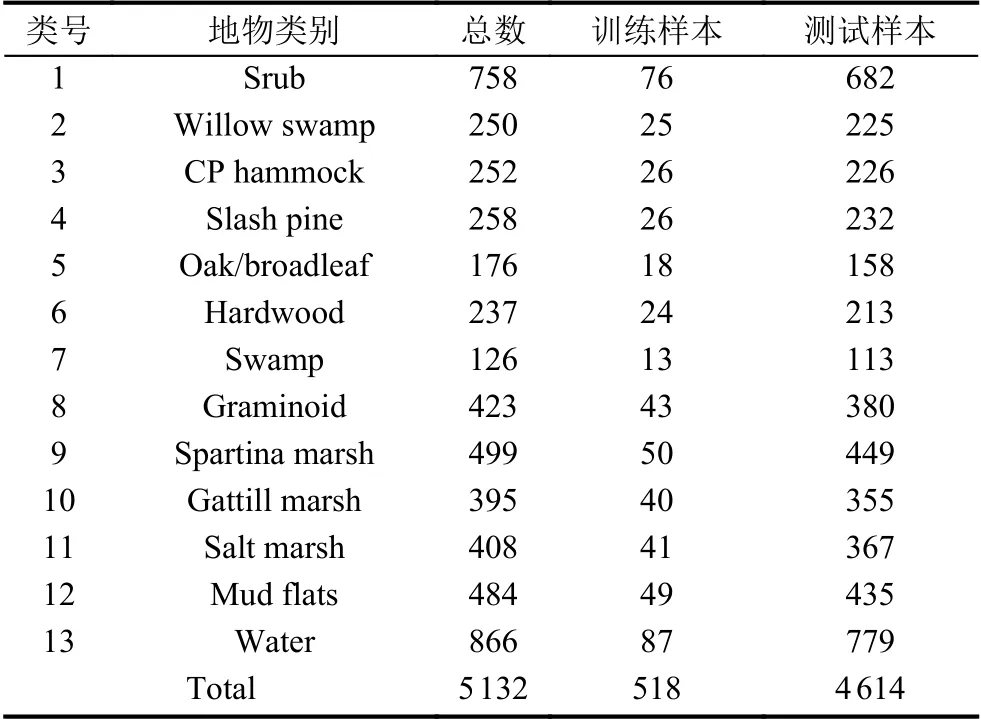
表2 Kenndy Space Center 数据集训练、测试样本数
3.2 仿真实现
本文采用改进GraphSAGE 算法对Pavia University和Kenndy Space Center 两个数据集进行分类实验,取数据集的10%作为训练样本,剩余90%作为测试样本.模型参数设置如下: 学习率为0.01,权重衰减为5E-3,迭代次数为100,使用Adam 优化器.网络训练过程中,设置采样层数K=2,聚合二阶邻居特征,对一阶邻居抽样5,二阶邻居抽样15.
Pavia University 数据集分类实验的训练样本和测试样本数见表1.将标准化后的数据作为SLIC 算法的输入数据,输入大小为610×340×103 的图像.为提高计算效率,将原始图像进行2 500 次分割,得到1 487 个超像素.将得到的超像素作为改进GraphSAGE 算法的节点,最终特征数设置为9,经训练后输出9 个数目为1 487 的张量,从而进行分类
图3 为不同方法的Pavia University 数据集分类结果,基于RDF 的支持向量机(RDF-SVM)需手动设置专业的参数提取特征,可能产生较多的误分类; 二维卷积神经网络(2DCNN)无法灵活的获得边界信息,容易造成特征误差; 传统的GCN 只利用像素的光谱特征,无法表示其内在相似性.分类结果表明,本文方法的分类结果和样本分布图具有高度一致性,可以很好地区分不同的地物类型,具有较强的空间相关性.在算法精度方面,表3 Pavia University 数据集上各种分类方法的分类评价指标表明,在总体分类精度(OA)、平均分类精度(AA)和Kappa 系数3 个精度指标上,本文分类方法的精度均优于其他方法,改良方法的效果十分明显.
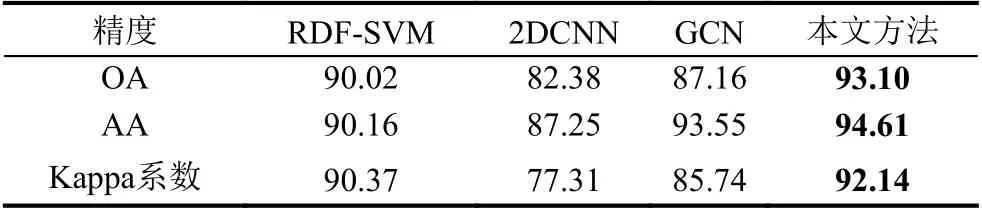
表3 Pavia University 数据集分类评价指标对比 (%)

图3 Pavia University 数据集分类结果
Kenndy Space Center 数据集分类实验的训练样本和测试样本数见表2.训练过程与Pavia University 数据集训练过程相同,原始图像分割后得到1 462 个超像素,最终输出13 个数目为1 462 的张量用于图像分类过程.
对比图4 的样本分布图与其他算法分类图,可以发现部分算法的分类结果存在误差.将每一张分类图的关键区域放大,其中,图4(a)红色圆圈中的地物类别是“Swamp”,图4(b)中是“Mud flats”,这两种地物类别具有相似的光谱特征.在所有的分类图中,“Swamp”的部分像素被误分类为“Mud flats”,其中,图4(d)中的误分类区域最小.结果表明,和Pavia University 数据集分类结果相似,分类结果和实际分类结果具有很好的一致性,可以很好地区分不同的地物类型.在算法精度方面,表4 中各种分类方法的分类评价指标表明,本文分类方法的精度远高于GCN,略优于RDF-SVM 和2DCNN,改良效果明显.

图4 Kenndy Space Center 数据集分类结果

表4 Kenndy Space Center 数据集分类评价指标对比(%)
3.3 算法分析
在原有GraphSAGE 算法的基础上引入了SLIC 超像素分割算法,对Pavia University 和Kenndy Space Center原始图像进行了2 500 次分割,将拥有数十万像素的高光谱图像降维成仅有数千个超像素的超像素图像,即用少量的超像素代替大量的原始图像像素来降低图像维度,减少了图节点个数,进而降低后续计算复杂度.
此外,对GraphSAGE 算法的采样过程进行改进,引入平均采样的思想.图3 与图4 可以看出,改进后的GraphSAGE 算法在Pavia University 和Kenndy Space Center 数据集上的分类结果与真实标签结果十分相近,误分类区域较少,尤其是在模型边界处的分类效果较好.分析表明,平均采样克服了有放回采样引起特征误差的问题,以阶层节点的平均光谱特征补充采样值,能解决图像边界采样节点数不足的问题.由表3 与表4可知,改进的算法模型分类精度高于其他分类方法,在大部分物体上获得了比较好的分类精度值.分析表明,改进的GraphSAGE 算法对各类物的识别具有很强的适用性,模型分类结果和实际分类结果高度一致,具有较强的空间相关性,进一步验证了本文方法的优越性.
4 总结
为了提高高光谱图像的分类精度,本文提出了一种改进GraphSAGE 算法的高光谱图像分类网络模型.为减少图节点个数,降低计算复杂度,该模型引入了超像素分割算法对原始图像进行预处理; 针对图像边界采样节点个数不足和有放回采样引起的特征误差问题,通过平均采样的方式补充边界缺少的节点,降低了提取特征的误差,提高了分类准确度.该模型在Pavia University 和Kenndy Space Center 数据集上达到了较高的分类精度,能有效降低计算复杂度,提高分类效率.通过一系列对比实验评估本文模型的优越性,结果表明,与RDF-SVM、2DCNN 和GCN 相比,改进的GraphSAGE算法弥补了边界部分采样节点不足的缺陷,提高了分类准确度.但本文网络对邻域大小的确定模式单一,下一步将会借助注意力机制自适应的学习邻居节点的个数,加快网络训练速度.
