基于卷积神经网络的肺部CT 图像分类算法研究
2022-11-05舒甜督蔡茂
舒甜督,刘 芳,蔡茂
(长春工业大学数学与统计学院,吉林长春 130012)
近年来,人口老龄化问题日益严峻,医学影像检查数量的快速增长是公众健康意识正不断提升的一大体现。医学影像检查数量正在飞速增长,然而,目前仍有许多基层医院尚不具有足够数量的专业影像技术人员和影像诊断医师,医学技术不断发展的同时,医学图像诊断领域供需失衡的问题亟待解决。
深度学习[1]自问世以来,深受国内外图像分类领域研究者的关注和喜爱,在各种图像分类任务的研究中应用广泛。众多先进的卷积神经网络(Convolutional Neural Network,CNN)结构被先后提出,如GoogLeNet[2],VGGNet[3],ResNet[4]等,均在图像分类任务中显现了优秀的结果。在医学图像分类方面,文献[4]将设计的152 层基于残差学习的卷积神经网络ResHist 用于乳腺癌组织病理学图像分类,分类性能得到了很大提升。文献[5]研究了预训练的VGG16 和未预训练的卷积神经网络对24 类组织病理学图像的分类性能。目前,提高数据利用率、分类性能以及缩短训练时间是医学图像分类研究工作中的重点问题。
肺癌作为发病率和死亡率最高的癌症,其早期通常无显著征兆,通过肺部CT 扫描发现的肺结节可能是肺癌的早期迹象。因此,根据CT 图像筛查早期肺结节是降低肺癌死亡率的关键。但CT 图像结构复杂,对比度较低,病变区域与其周围正常组织之间的差异不显著,使得医务人员在逐一查阅和解读大量CT 图像数据时,容易造成误诊[6]。文献[7]用一种基于DenseNet 的深度学习方法来辅助医生对低剂量、低分辨率CT 影像的肺腺癌组织学亚型的分类鉴别。文献[8]研究了支持向量机在肺部CT 图像分类中的应用。文献[9]设计了用于肺癌钙化的深层神经网络,并将其应用于肺部良恶性结节的CT 图像分类中。基于深度学习的医学图像分类算法的性能不断更新,但存在训练过程耗时长、分类准确率不够高等问题,仍有改进的空间。该文针对肺部CT 图像分类任务构建一个新的卷积神经网络模型,通过数值实验研究该模型的有效性,并与未经预训练的VGG16模型和基于迁移学习(Transfer Learning,TL)[10-11]的VGG16 模型在分类效率和准确率上进行比较研究。
1 CT图像卷积神经网络分类模型
1.1 VGG16卷积神经网络模型
输入层、卷积层、池化层和全连接层[12-14]构成卷积神经网络CNN 的主要结构。CNN 是传统神经网络的演变,在其基础上增加了卷积层和池化层用于图像特征的提取。整个模型可以自动学习多个层次的特征,不需要事先对图像进行特征预提取,通过卷积神经网络学习到的特征能够有效用于图像的分类,这也是其能够优于传统机器学习图像分类算法的原因之一。卷积层又称为特征提取层,原图像中符合条件的部分可通过卷积运算筛选出来。经卷积运算后的图像大小不会改变,输入图像的边缘和角等不同的特征都可以很好地被提取到。在卷积神经网络中,经过卷积处理后的图像通常还需要进行池化。池化层又称为特征映射层,通过池化过滤器对输入数据进行降维。经过池化层处理过的图像通过缩减采样缩小了图像的位置差异,所需处理的数据点也得到减少,因此节省了大量的后续运算时间。此外,网络的过拟合概率由于计算量的减少得到了一定程度的降低。最后,全连接层的作用相当于“分类器”,将之前所有层学习到的特征进行汇总并将其映射到相应的标签上实现分类。
VGG卷积神经网络模型于2014年被首次提出[15],VGG16卷积神经网络是VGG多个类别算法中的一种,其网络结构包含13 个卷积层、5 个池化层和3 个全连接层。VGG16卷积神经网络模型反复堆叠3×3的卷积层和2×2 的最大池化层来完成原始数据到隐层特征空间的映射,最后,通过全连接层把所有特征进行加权融合,实现最终的CT 图像分类,其网络结构如图1 所示。

图1 VGG16卷积神经网络模型
1.2 S-VGG卷积神经网络模型
VGG16 网络模型结构简单,拟合能力强,然而其包含的权重数目多达139 357 544 个,不仅需要较大的存储容量,而且不利于模型部署,所需的训练时间过长给参数调整带来了很大困难。
因此,可对VGG16 网络模型的构架进行简化,仅保留四个卷积层、四个池化层和两个全连接层,并在网络结构中加入了批量规范化层(Batch Normalization,BN)[16-17],放置在每个卷积层之后,新网络模型记为S-VGG(Simplified VGG),其结构如图2 所示。

图2 S-VGG卷积神经网络模型
由于是否含有肺结节的CT 图像间差异较小,过多数量的卷积层提取的特征信息量庞大,会增加计算时间与复杂度。对于CT 图像,采用较少数量的卷积层即可提取到图像的大部分特征信息且获取较高的分类精度,故S-VGG 模型减少了相应的卷积层数目及卷积核大小。卷积层从图片中提取特征,对输入数据进行降维后用全连接层进行特征整合。模型的卷积层数目减少后池化层的数目也随之相应减少。VGG16 模型包含3 个全连接层用于图像的1 000 分类,对于二分类问题,过多的全连接层容易导致模型的过拟合,因此S-VGG 模型去掉了VGG16 原有的所有全连接层,依次换上分别具有256 个神经元的全连接层和连接一个二分类的softmax 分类器。同时,BN 层的增加可以减少训练过程中由于参数不断更新而导致的各层数据分布发生变化对模型的影响。在训练模型时,批量规范化使得卷积层后的输出可以通过小批量数据的均值和标准差进行调节,从而使输出数据更加稳定。批量规范化的计算过程如下。
计算每一个训练批次数据的均值μ与方差σ:

其中,xi为批量规范化处理输入数据的样本。
用所求得的均值μ与方差σ对该批次的训练数据做归一化,把它们规整到均值为0、方差为1 的正态分布范围内:其中,ε是一个微小正数(以使分母不为0)。

通过尺度变换和偏移使返回的批量归一化结果的特性和原始输入数据的特性相同,避免数据的特征分布因数据归一化而被破坏:

其中,yi为样本标签,是通过训练学习的参数。
因此,在网络中增加BN 层可以提升模型的训练速度,加快其收敛速度,防止过拟合从而获得更好的分类效果。此外,模型可使用较高的学习率,调参过程得到了简化。
VGG16 模型相较于简化后的模型,各卷积层拥有的卷积数目更多,可提取原始图像中更为详细的特征信息。然而肺结节CT 图像与非肺结节CT 图像之间的差异并不显著,正负样本相似性较高。过多的卷积数目使得学习到的CT 图像相似性特征也在增加,模型计算量庞大,对最后的分类结果造成一定程度上的影响。该文构造的S-VGG 模型与VGG16模型相比,不仅通过卷积层的数目的减少,精简了网络结构,每个卷积卷层的卷积核的数目也进行了相应减少。此时的卷积神经网络能够提取的特征数量虽不如VGG16,但其所获得的图像样本间差异信息相对于所获得的样本间相似信息的比例没有减少,对于正负样本间特征差异小的CT 图像还是能取得不错的分类效果。
1.3 预训练VGG16卷积神经网络模型
相较于采用可用的数据集从零开始设计和训练相同结构的深度网络需要占用更多内存和耗费大量实验与调参时间,使用预训练的网络来提取CT 图像的深层特征只需要根据数据的性质进行微调就能获得较高的准确率起点和更快的收敛时间,这种方式称为迁移学习。因此,采用迁移学习的方法能优化模型的学习效率。VGG16 卷积神经网络模型的预训练是在ImageNet 数据集上进行的,模型通过对几十万张图片进行1 000 分类训练,获得了较好的泛化能力。此次实验将采用基于迁移学习的VGG16 网络对肺结节CT 图像进行分类的计算,并与在Luna16 数据集上从零开始训练的VGG16 网络的结果进行对比。
由于肺部CT 图像是否含有肺结节的分类属于二分类问题,使用VGG16 中1 000 分类的全连接层计算量大且容易导致过拟合。实验将VGG16 预训练模型全连接层之前的所有层进行冻结,只对重新定制的全连接层进行训练,将VGG 模型中的全连接层替换为256 个神经元的全连接层和二分类的softmax分类器。实验模型的参数初始化,仍使用在ImageNet数据集上预训练的VGG16 神经网络模型参数。
2 实验
2.1 实验数据集
实验所用的数据来自于包含888 个病例的肺部CT 切片的Luna16 数据集。将直径大于3 mm 的结节作为样本,并且将相距较近的结节进行合并,检测区域为三位及以上专家标注的结节,肺结节图像有1 186个,非结节图像有549 879个。图3为Luna16数据集中的肺部CT 图像,左边为含肺结节CT 图像,右边为无肺结节CT 图像。
图3 S-VGG卷积神经网络模型
2.2 数据预处理
由于正负样本差距悬殊,为了减少过拟合现象,将非肺结节图像进行随机采样1 186 张,然后对这2 372 个肺结节和非肺结节图像应用随机翻转、平移、旋转变换扩充10 倍,使得最终实验所用正负样本比例为1∶1。对图像进行扩充的部分示例图如图4所示,从左往右、自上而下依次是原图、对图像进行水平翻转、垂直翻转、向右和向下平移、向左和向上平移、逆时针旋转45°、旋转90°的图像、旋转225°的图像。

图4 数据扩充示意图
2.3 实验结果
为了验证构建的S-VGG 模型对肺部CT 图像分类任务的有效性,将其与未预训练的VGG16 模型以及基于迁移学习的VGG16(Transfer Learning VGG16,TL-VGG16)模型对肺部CT 图像分类实验的结果进行了对比,结果如表1 所示。从表1 可知,S-VGG 模型在训练集和验证集上分别达到了99.91%和97.85%的高准确率,以及0.002 0 和0.155 0 的低损失值,其准确率和损失结果与TL-VGG16 模型相当,且训练时间相较于TL-VGG16 模型和未经预训练的VGG16模型有着显著优势,这很好地说明了所构造的SVGG 模型能快速高效地分类出CT 图像是否含有肺结节。
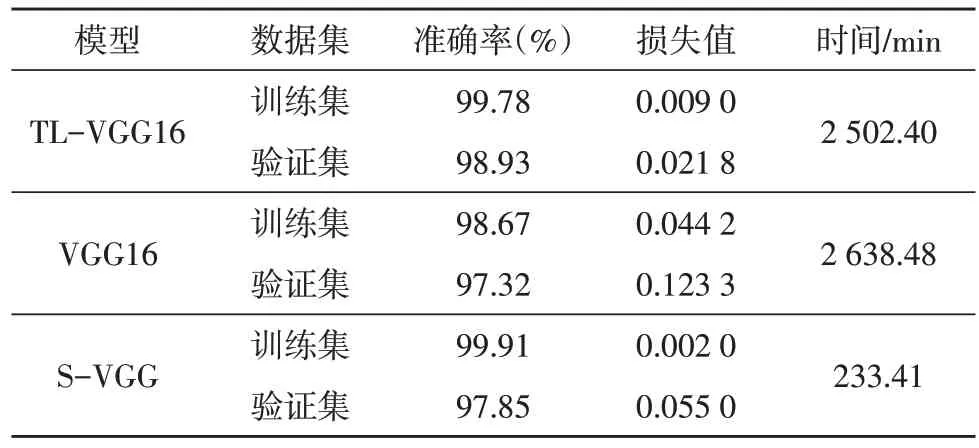
表1 预训练VGG16模型、未预训练的VGG16模型和S-VGG模型分类结果
图5(a)-(d)分别描述了TL-VGG16、未预训练的VGG16 和S-VGG 模型对Luna16 数据集进行CT图像分类完成30 次迭代训练以及测试时准确率和损失的变化。通过图5(a)-(d)可知,未预训练的VGG16 模型准确率上升较慢且验证集上的准确率和损失值有较大幅度的波动,不能很好地收敛。而新构建的S-VGG 模型与预训练的VGG16 模型训练集和验证集上的分类准确率都能很快收敛,迭代次数在10 次左右分类准确率就能接近100%,损失值达到较低值后无大幅波动,可以很好地获取及学习肺部CT 图像的特征以进行高效分类。
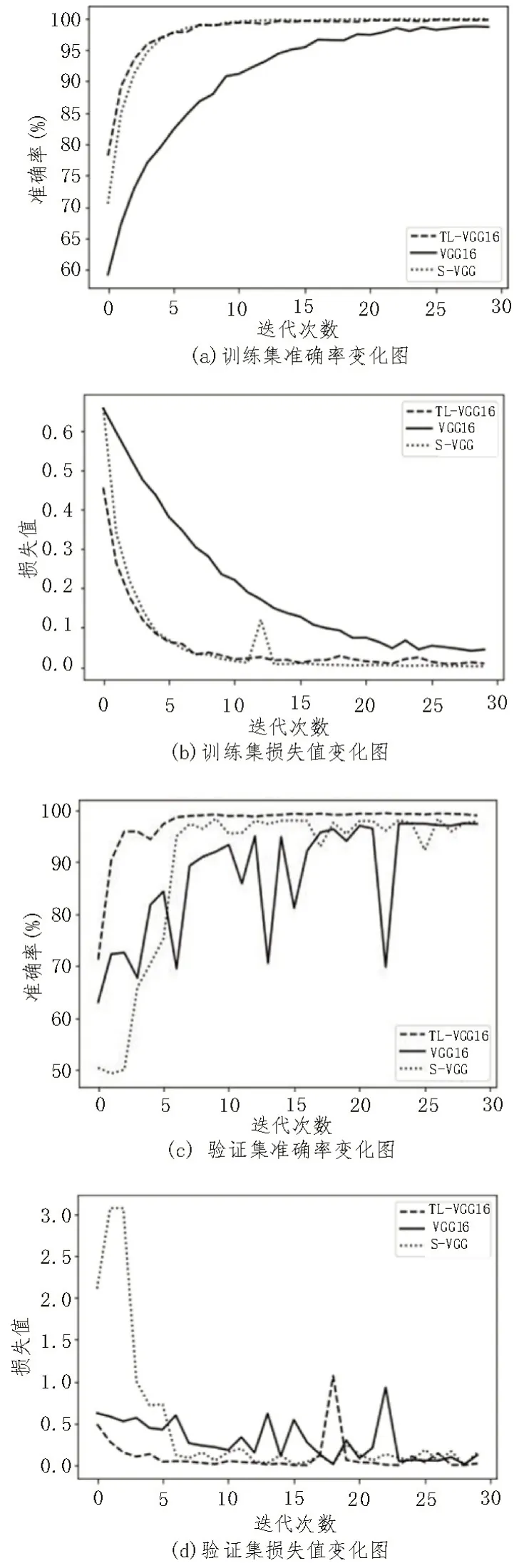
图5 模型准确率和损失函数曲线图
3 结束语
该文利用Luna16 数据集,研究了基于CNN 的肺部CT 图像分类算法。文中分析了模型原理,在VGG16 模型的框架下构建了一个S-VGG 神经网络模型,并通过参数的调整使模型达到了较理想的分类结果,与迁移学习的VGG16 模型以及未预训练的VGG16 模型进行了分类结果比较。构建的S-VGG模型相较于VGG16 模型,结构更加精简,解决了在CT 图像肺结节分类实验中深度卷积网络中大量参数与网络结构设计调试时间长的问题,实验准确率和预训练的VGG16 模型相当,且训练时间较短,更适合CT 图像肺结节的快速高效分类。此外,该模型可推广到医学图像中的各类CT 病灶诊断,对医学影像智能辅助诊断的完善有着实际意义。
