基于语义分割和卷积神经网络的数显表识别算法研究
2022-11-05陈霄王黎明张法业张艺蓝姜明顺张雷
陈霄,王黎明,张法业,张艺蓝,姜明顺,张雷
(1.国网江苏省电力有限公司,江苏 南京 210024;2.江苏方天电力技术有限公司,江苏南京 211100;3.山东大学控制科学与工程学院,山东济南 250061)
随着工业4.0 战略的实施,在工业智能化、数字智慧小区建设背景下,自动抄表及远程读表技术已成为当前工程实践应用及研究的热点。目前,大部分地区的水表是传统机械式水表,随着智能化技术的发展,人工抄表方式人力成本高昂,实时性差,缺乏统一化、标准化管理等缺点日益凸显,因此,亟需一种自动化数显表识别系统。
针对以上问题,提出了一种基于语义分割和卷积神经网络的数显表读数识别算法,并对利用实际水表构建数据集验证了算法的准确性。
1 数显表读数识别系统总体设计
传统的数显表识别方法的流程是数字区域提取、倾斜校正、字符分割、数字识别[1],常用方法有边缘检测算法[2-3]、Hough 变换[4-5]、模板匹配[6-7]等。以上方法均需要按使用环境调整参数,难以全面推广应用。家用水、气、电、暖等数显表在不同家庭环境下,数显表种类、表盘清洁程度以及环境背景均有明显差异,传统方法难以采用一个通用算法解决这些问题。近年来,人工智能机器视觉感知技术发展迅速,并在理论与实际应用两大方面均取得了卓越发展成果[8]。目前基于深度学习的机器视觉研究有图片分类[9]、目标检测[10]、语义分割[11]等,分别满足不同的任务需要。对于数显表数字识别系统,语义分割模型可以有效地提取数字所在位置,图片分类模型可以精准识别图片数字,为数显表数字识别算法提供一种有效技术手段。
针对传统数显表读数识别算法适用性差、抗噪能力弱等问题,提出了一种基于语义分割和卷积神经网络的数显表读数识别算法。通过语义分割实现数显表数字识别,使用数据增强和迁移学习方法降低数据获取成本,并结合自适应区域二值化,降低噪声的干扰。
基于语义分割和卷积神经网络的数显表识别系统总体方案如图1 所示。
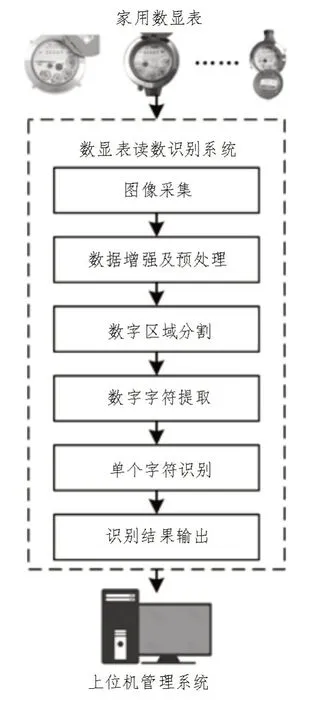
图1 总体设计框图
2 硬件设计
数显表读数识别系统由图像采集模块、控制器模块和远程传输模块组成,系统硬件原理图如图2所示。
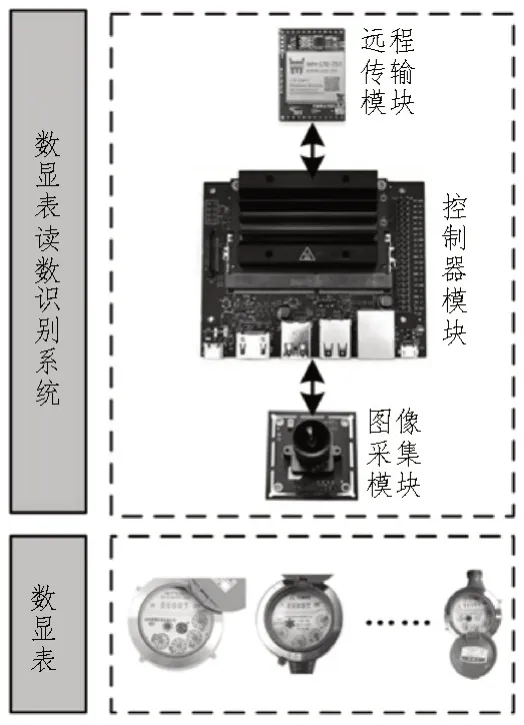
图2 硬件原理图
图像采集模块采用索尼IMX290 摄像头,实现了在100°视角内数显表的200 万像素图像的实时采集;控制器模块基于Jetson Nano AI 核心板设计,该核心板搭载四核Cortex-A57 处理器,128 核Maxwell GPU,2GB LPDDR内存,支持TensorFlow、PyThon、Caffe 等AI 框架和算法,实现了基于语义分割和卷积神经网络的数显表识别算法的稳定运行;远程传输模块基于4G 通信芯片WH-LTE-7S1 设计,具备10 MB/s 下载速度、5 MB/s 上传速度,兼容2G/4G/NB-IoT 等多种网络制式,实现了数字表读数的快速准确传输。
系统工作时,图像采集模块接收控制器模块采集指令后,采集数显表表盘图像并通过USB 总线发送给控制器模块,控制器模块将接收到的图像数据输入数显表读数识别算法中,得到数显表读数,并通过4G 网络传输给上位机管理系统,经用能费用计算后,向用户发出缴费提醒。
3 软件算法设计
3.1 数据增强及预处理
深度学习作为一种数据驱动算法,数据需求量大。有监督的深度学习算法不仅需要数显表图片数据,同时还需要相应的标签辅助训练。在标注数据有限的情况下,数据增强(Data Augmentation)是一种增加训练样本的多样性的有效手段。按照变化方法,数据增强方法分为几何变换类、颜色变换类和生成式数据增强。该文进行数据增强及预处理时,选用几何变换类和颜色变换类进行数据增强。
几何变换类方法是指在不改变图像相应像素值的条件下,通过改变像素值的位置以及改变图片尺寸的方法实现数据增强。常见的几何变换类方法有镜像、旋转、缩放、裁剪等操作。镜像和旋转不改变图像的尺寸,而裁剪会改变图像的尺寸,缩放会产生图像失真。由于几何变换类操作会影响到图片相应的Ground Truth,因此在进行上述操作时,要对Image和Ground Truth 同时进行操作。
颜色变换类可以改变图像的像素值实现数据增强,如噪声叠加、图像模糊、颜色改变、亮度值调整等。基于噪声的数据增强是在原来图片的基础上,随机叠加一些噪声,如高斯噪声。改变色调是在一定的色彩空间中,通过增加或减少一些色彩成分,或改变色彩通道的顺序来完成。调整亮度值可以模拟现实中不同光线强度的情况。
针对家用水表图像底噪高、角度不正等特点,在保留原图的基础上,对原图进行添加高斯噪声、随机改变图像色调、随机调整图像亮度以及以上方式的组合变换,得到七种数据增强图片。针对不同设备分辨率和拍摄角度不同的问题,采用随机裁剪、缩放、翻转+裁剪三种方法,将原图和数据增强图片进行规范,得到尺寸为256×256 的增强图片,使得原始数据集扩充为24 倍。具体数据增强方法编号如表1所示。

表1 数据增强方法编号
3.2 数字区域分割算法设计
基于U-net 模型进行数字区域分割算法设计。U-net 模型[12]的优势在于它不需要繁琐的图像与处理和特征工程,且能够以端到端的方式进行应用。此外通过使用数据增强技术,U-net 在小数据集上可以实现良好的预测性能。基于标准U-net 网络,利用调整参数和模型层数,结合跨步卷积的下采样实现方法,构建数字区域分割网络,并通过引入残差结构解决由于模型层数过深而产生的梯度消失问题,提升模型性能。
跨步卷积是指步长大于1 的卷积,可以作为一种下采样方法。其与最大池化法不同的是对于一定范围的特征信号,传递到下一层的权重是模型学习出来的,因此可以更有效地提取特征。
残差是指实际测量值与回归预测值的差。在表盘区域识别任务中,深度残差网络通过使用残差模块参考己知的浅层映射获取数据特征,这比直接拟合深层映射更容易[13],从而提升模型准确性。残差模块是在两个卷积层的基础上添加了一个捷径连接(Shortcut connections)。残差模块的一般表达形式如下:

其中,x是恒等映射;H(x)是期望的基础映射;F(x)是残差映射。期望的基础映射H(x)可以被重写为F(x)+x。随着深度学习网络模型层数的增加,会出现梯度消失、梯度爆炸等网络退化问题,使用残差方法打破U-net 网络对称性,进而有效改善层数过多引起的网络退化问题[14]。模块结构如图3,参数如表2 所示。

表2 改进U-net模型参数

图3 改进U-net模型及残差模块结构
3.3 数字字符提取方法设计
通过分割算法,可以得到数字表盘的预测Ground Truth,然而由于模型准确度、图片拍摄角度问题,分割结果通常为不规则矩形,需进一步处理才能正确提取表盘区域。
采用扫描检测法,通过依次扫描x轴和y轴,确定表盘所在最小矩形区域。同时,加入连通性判定条件,降低小区域分割误差对提取结果的影响。扫描前,首先使用Ground Truth 提取原图表盘识别区域。

然后依次扫描x轴和y轴,在表盘识别区域附近,将连续5 个非表盘区域作为边界,其内部即为矩形表盘区域。
为提升字符识别效率,对图片进行灰度化和二值化处理。采用自适应阈值法选择二值化阈值。首先计算r×r领域内的灰度均值n(x,y)与标准方差s(x,y)。

然后,计算领域内像素点对应高斯权重、像素点(x,y)的阈值T(x,y)。

其中,(i,j)是领域内像素点与(x,y)相对的坐标。
最后,进行二值化,如式(7)所示:

对于后续数字识别功,采取单个字符提取识别并组合的方法来识别表盘数字。以5 位数字的数显表为例,如图4 所示,将表盘区域分为5 份,每个区域左右部分各留出5%的重叠部分,避免分割导致数字不完整。

图4 字符提取示意图
3.4 数字识别算法设计
考虑到数显表盘数字为规范印刷体,风格差异较小,对大量数据进行标注构建数据集时间成本极高,但若仅使用少量数据构建数据集,深度学习模型易陷入过拟合[15]。因此,基于CNN 模型LeNet-5 网络框架构建数字识别算法,利用mnist 手写数据集,实现迁移学习,提升所设计算法在小样本图像识别数据库上的准确度[16]。具体流程如图5 所示。
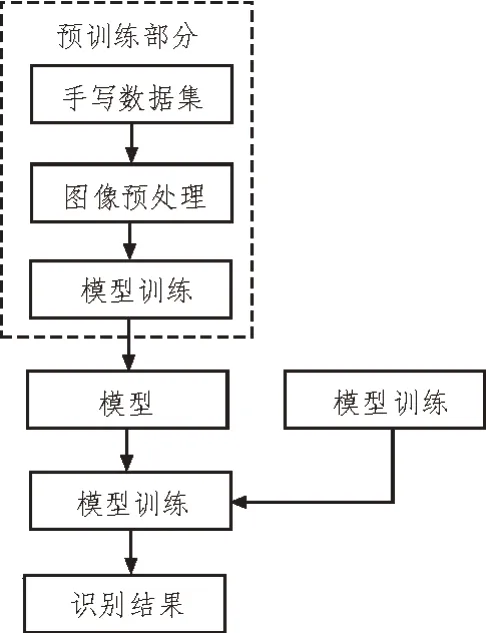
图5 数字识别算法流程
首先,预训练基于LeNet-5 网络结构CNN 模型,其网络结构和参数分别如图6、表3 所示。

表3 CNN模型参数
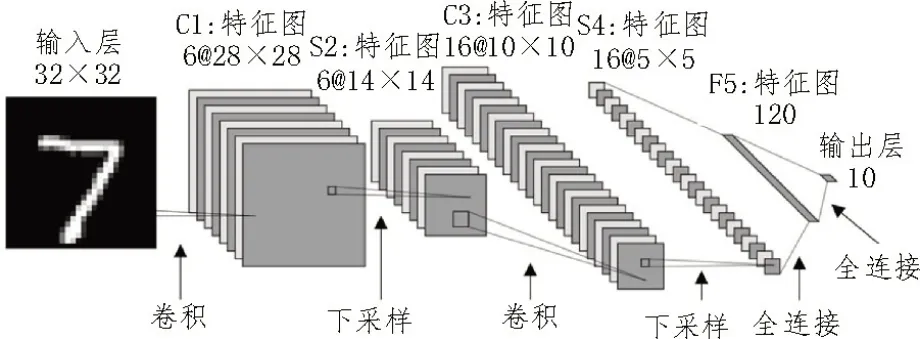
图6 CNN网络结构
预训练完成后,将构建的真实表盘数据集分为训练集和测试集,利用训练集进一步训练模型,最后使用测试集验证模型性能。
4 实验结果
4.1 数据增强及预处理结果
以不同厂家、不同采集角度、不同使用环境下获取的19 张水表图片构成数据集,并对其进行人工标注。通过数据增强,得到共456 张水表图片,构建实验数据集。
4.2 数字区域分割
采用交并比(Intersection over Union,IoU)评价数字区域分割模型性能。IoU 表示系统预测出来的框与原来图片中标记的框的重合程度,分割结果最好时,值为1;最差时,值为0。其计算方法为:

图7 为IoU 数字区域分割评价指标参考图,其中,矩形A代表标签,矩形B代表模型预测分割的数字区域,矩形C是A与B的交集。
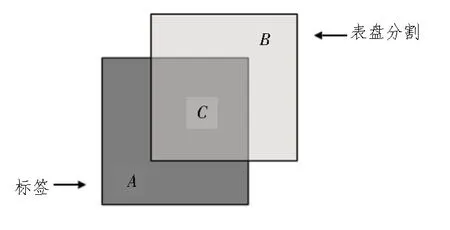
图7 IoU数字区域分割评价指标参考图
使用数据增强后的图片训练语义分割模型,历经100次训练后,IoU数字区域分割准确率为99.76%。
4.3 数字字符提取
首先,提取表盘图片数字区域并进行二值化处理,部分提取结果如图8 所示。

图8 部分数字区域提取结果
然后,提取单个字符,按数字命名保存,得到数字字符数据集,共获得了760 张数字图片。
4.4 数字识别
首先,使用mnist 数据集训练数字识别模型。为降低二值化后表盘框对识别结果的影响,在mnist 数据集上,添加宽度为1、像素尺寸为20×20、位置随机的矩形框,经网络训练后,测试集准确率为99.46%,图8 中的数字识别结果分别为00189、00152、04371、00252。可以看出,训练网络对完整数字识别准确,但部分被分成半截的数字出现了错误识别。
然后,再使用4.3 节提取600 张数字字符图片作为训练集对网络进一步调整训练,获得最终数字识别模型。
最后,使用4.3 节提取160 张数字字符图片作为测试集对数字识别模型进行验证,测试准确率为100%,图8 中对应的数字识别结果为00180、00152、04321、00252,满足工程应用需求。
4.5 算法用时测试
利用i5-9500 CPU &TensorFlow 2.3.0 构建算法用时测试平台,记录从获取到50 张水表照片到返回识别结果所用的时间,计算平均用时,以此作为单张照片识别时间。连续进行五次实验,求取平均值和方差,50 张水表图片总用时平均为17.53 s,单水表识别平均用时为350.59 ms,满足工程应用需求。
5 结束语
针对工程应用中数显表识别算法适用性差、抗噪能力弱等问题,设计了一种基于语义分割和卷积神经网络的数显表读数识别算法。利用较低成本的小数据集对模型进行训练,并通过数据增强降低了污渍、光线等因素对识别效果的影响,实现批量自动快速识别。实验表明,所设计算法具有成本低、用时短和准确率高等特点,满足工程化需求。
未来将基于该模型继续研究数显表读数算法,探索多种类数显表读数算法的可能性,实现用户侧居民水、电、气、暖数显表一体化识别。
