一种SAR 成像矩阵的高效存取方法
2022-11-05张伟达
张伟达
(中国电子科技集团公司第十研究所,四川成都 610036)
合成孔径雷达(SAR)因其高分辨的成像能力和穿透性强,具有全天时全天候的特点,被广泛应用于海洋、陆地、航空航天等领域[1-5]。而随着SAR 成像实时性、分辨率等要求越来越高,成像处理中的数据量和运算量也越来越大,此时多节点、多内核的并行处理架构常常被用来提高系统性能,以解决上述问题[6-7]。
SAR 成像功能中需要处理的复数点数据以二维数据矩阵的形式存储,且数据量规模庞大,而传统用于存储处理数据的DSP 芯片可使用的存储空间有限,同时若直接以线性方式存储二维数据(在存储介质中某一维度数据连续存储,另一维度跨越式存储),则会造成数据读写性能失衡,某一维度存取速率很高而另一维度却非常低。
该文基于某国产类TMS320C6678 芯片[8-13],针对大规模数据的存储和矩阵的二维高效传输,设计了一种将单片DSP 不足以容纳的数据存储于多片DSP中,并且DSP 间通过Serial RapidIO[14-16](SRIO)网络互联的系统方案,系统网络中的每一片DSP 都可以通过SRIO 接口访问到其他DSP 中的数据,同时制定数据矩阵在DSP 中的存储策略来替换线性存储方式,以达到网络中的DSP 都可以以任意维度高效访问完整矩阵空间数据的目的,为系统中多DSP 并行高效地完成成像运算提供支持。
1 系统组成
单片DSP 不足以存储完整的二维复数点数据矩阵,可以将数据矩阵分布式的存储在多片DSP存储介质中,多片DSP 通过SRIO 网络协同实现对完整数据矩阵的访问,该文设计的雷达信号数据处理板根据待处理的数据量,采用四片类6678 DSP并行工作的方式,提高运算效率的同时扩展了存储容量。
方案中使用的国产类TMS320C6678 DSP 芯片具有8 个内核,每个内核最高主频为1 GHz;具有两组SRIO 控制器,且全部接入SRIO 网络中,速率均使用4×3.125 Gbps 配置,在接入交换芯片的情况下,实际读写吞吐量分别可达到5.9 Gbps、8.6 Gbps;DSP 外部配有8 GB 容量的DDR(双倍速率同步动态随机存储器),内部配有4 MB 的MSMC(共享内存空间),其他存储能力与TMS320C6678 完全相同。
系统构成图如图1 所示,四片类6678 DSP 芯片通过1848 交换芯片接入共同的SRIO 网络,每片DSP与交换芯片间都有两组SRIO 相连接,传输数据时可独立并行传输。

图1 系统构成图
在该文方案中,可以处理的复数点(4 字节实部+4 字节虚部)上限为64k×64k 的二维矩阵(共32 GB数据),完整的待处理数据矩阵将被分成2×2个子矩阵(对应4 个DSP 组成的2×2 DSP 矩阵)分布式地保存在四片DSP 的DDR 中,(1,1)子矩阵被保存在(1,1)号DSP 中,(1,2)子矩阵被保存在(1,2)号DSP中,以此类推,数据矩阵分块方法如图2 所示。

图2 数据矩阵分块方法
考虑到可扩展性的需要,在其他应用场景中,可根据待处理矩阵数据量灵活地选择SRIO 网络中参与存取处理数据的DSP 矩阵规模,若选择的DSP 矩阵模型为m×n(共m×n片DSP),则数据矩阵也要相应的被分割成m×n个子矩阵,并依据编号对应的保存在相应的DSP 中,如图3 所示。

图3 规模为m×n的DSP矩阵架构图
2 二维矩阵在DDR中的排布策略
雷达成像数据一般以二维复数点矩阵形式排列,矩阵的行、列两个维度分别对应着方位向和距离向两类数据,在存储时,若单独地以某一个维度为单位将整个数据矩阵存入DDR 中,那么由于存储单位使用的维度对应的数据在DDR 中连续存储,其读写速度非常快,但另一维度的数据在DDR 中会以不连续的方式排列,且随着数据体量的增大间隔也越大,同时会频繁发生跨页(DDR 中的存储单位)读写数据的情况,此时,其对应的读写效率非常差。所以在DDR 中存写数据矩阵时,都应依据一定的存写策略平衡两个维度的速率,以提高整体效率。
该文方案中使用如下存储方法,以2×2 的DSP模型(共4 片)和64k×64k 的二维数据矩阵为例:
64k×64k 的二维数据矩阵会被分为2×2 个32k×32k 的子矩阵分别存储在每片DSP 的DDR 中,为均衡行数据和列数据在DDR 中的读写速率,将数据矩阵分解为两种规模的数据块Rank 和Block,划分规则如下:
原始数据矩阵(32k×32k)如图4 所示,每一个数据点由其在矩阵中的行序号和列序号表示,表示形式为(0,0)~(32k-1,32k-1):
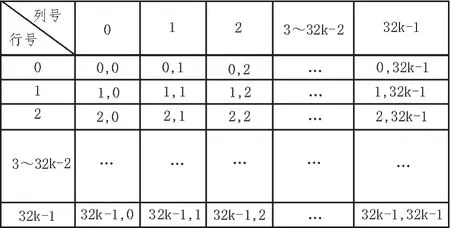
图4 原始数据矩阵
Rank:每一列中以h(以h为512 为例,可根据DDR 的具体类型选择最优的h值)个点为一组,定义为一个Rank,Rank 为存入ddr 中的基本单元,每一个Rank 中的数据按顺序写入ddr 的一段连续空间,如图5 所示。

图5 Rank在数据矩阵中的定义
Block:每一行Rank(以Rank为单位,包括Rank0~32k-1)为一个Block,如图6 所示,32k×32k 数据矩阵中存在64 个Block,同一个Block 内的不同Rank 之间依照序号顺序先后写入连续的DDR 空间,该例中写入Block0 数据块时,先写入Rank0,再写入Rank1,依次写入Block0 中的全部Rank。

图6 Block在数据矩阵中的定义
Block 之间同样依照序号顺序依次写入连续的DDR 空间,在DDR 中,用于存储数据矩阵的起始地址开始存写Block0 数据块,在Block0 数据块的下一个连续地址写入Block1 数据块,依次写入全部Block数据块。
3 二维矩阵的存取方法
由于图像处理的高效性要求,往往采用并行处理的方式,既包括8 核的并行数据处理,也包括同步进行的数据传输与数据处理。
利用芯片的集成外设DMA(Direct Memory Access)控制器[17],可以实现DMA 控制器进行数据搬移的同时使用CPU 并行执行数据处理;使用ping-pong 模式,CPU 处理ping 区数据时DMA 搬移数据至pong区,CPU 处理完ping 区数据后开始处理pong 区数据,此时DMA 开始搬移并更新ping 区数据。
数据传输部分包括两个环节:1)通过DMA 完成DDR 和本地MSMC 间的传输;2)通过SRIO 完成源DSP 与目标DSP 的MSMC 间传输。由于存储方案并没有线性地将数组数据存入DDR 中,需要使用DMA的多维传输和链式传输模式完成数据由DDR 到MSMC 的搬移,流程如下:
行读写时,DDR 中数据矩阵同一行数据的相邻两个数据点间隔h(即一个Rank 中的点数)个数据点(每个复数点占8 字节),行读写时,使用二维DMA 读写,即读取一个点后间隔h个点读取下一个点,为提高效率,在多行(设为g行,根据需要)读写中,一次读取g个数据点(g行数据中相同序号的数据点相邻,即存在于同一个Rank 中),间隔h个点后再读取下一组的g个点。
图7 以512 个点为一个Rank(h=512)、读写4 行数据(g=4)、以每行32k 个点为例,使用DMA 的二维传输模式(以固定间隔跨越式地多次传输),以4k Byte 为间隔每次搬移32 Byte,共搬移32k 次,阴影部分为待传输数据。

图7 行数据在DDR中分布及读写示例
列读写时,列数据在DDR 中被分为数个Rank 存储,Rank 中数据连续存储,同一列数据所属的两个Rank 间隔h(本例中h为512)×32k(32k×32k 矩阵中)个数据点,使用链式DMA 进行传输,每一个节点传输一个Rank,为提高效率,在多列(g列)传输中,一次节点传输g个Rank(同一个Block 内,相邻列数据的Rank 连续)。
图8 以512 个点为一个Rank(h=512)、读写4 列数据(g=4)、以每列32k 个点为例,使用DMA 的链式传输模式,每个DMA 节点传输2 048(512×4 列)个复数点,一次DMA 传输链包括64 个节点(32×1 024/512),阴影部分为待传输数据,每一段阴影部分都为一次DMA 传输节点待传输的数据。

图8 列数据在DDR中分布及读写示例
为了进一步提高数据传输的效率,同样使用ping-pong模式,使DDR 和本地MSMC间的DMA 传输、源DSP 与目标DSP 间的SRIO 传输两个环节同步执行,DMA 向ping 区搬移数据完成后,启动ping 区数据SRIO 传输,同时DMA 开始向pong 区搬移数据,通过并行运行减少数据读出DDR 的损耗。
4 性能评估
实验采用图1 所示的4 片DSP 模型,国产类6678 DSP 主频时钟使用1 GHz,DDR 工作时钟使用667 MHz,两组SRIO 设备都使用4 路3.125 Gbps 的配置(在通过交换芯片互连的情况下,实测SRIO 读模式可达2×8.503 Gbps,写模式可达2×5.915 Gbps)。
每次测试以读写4 条数据线为例,每条数据线分别访问64k 个复数点(共4(线数)×64×1 024(点数)×8(点字节数)=2 MB 数据)和32k 个复数点(共4(线数)×32×1 024(点数)×8(点字节数)=1 MB 数据),存储策略中Rank的h参数使用512。
该文方案实际传输带宽及与传统线性存储方案(以行为单位逐字节存入DDR 中)对比如表1 和表2。

表1 访问4线64k个复数点实验性能对比表

表2 访问4线32k个复数点实验性能对比表
由实验结果可以看出,由于采用了DMA 和SRIO并行工作的ping-pong 模式,完整流程的传输带宽会受到二者中速率较慢一方的限制。
传统线性存储方式中,若以行为单位逐字节地将数据存入DDR 中,由于行数据在DDR 中连续,DMA 对DDR 中行数据的写入、读出非常快速,此时数据传输的带宽仅受SRIO 带宽上限制约;但由于列数据在DDR 中不连续,且同一列中连续的两点之间间隔较大,实验中间隔32k 个复数点(即256 kB,一片DSP 中存有32k×32k 数据矩阵),DMA 对DDR 中列数据的写入读出效率非常低(由于DDR 中页属性的限制,两点间间隔越大,跨页越多,耗时越久),此时数据传输的带宽受DMA 对DDR 中数据读写速率的限制。
通过对比可以看出,使用该文方案后,列数据在DDR 中以Rank 的形式存储,Rank 内部连续存储,Rank 间离散分布,此时使用DMA 的链式传输模式,可以使列数据传输带宽得到大幅提高;同时,虽然行数据由连续分布变为了离散分布,但连续两点之间的存储间隔可控,且会被设置为较小值,以便增加单个DDR 页(DDR 中的存储单位)中的存储行点数,此时行数据读写时跨页的消耗会被大大减少,最后达到在提高列数据传输速率的同时有限地降低行数据获取性能的目的。
此方案中的读写性能同时也受访问数据线数的影响,访问的数据线数目越多,待操作的数据分布在同一个DDR 页中的部分就越多,性能便越高,反之性能则会有所下降,实验结果如表3 所示。
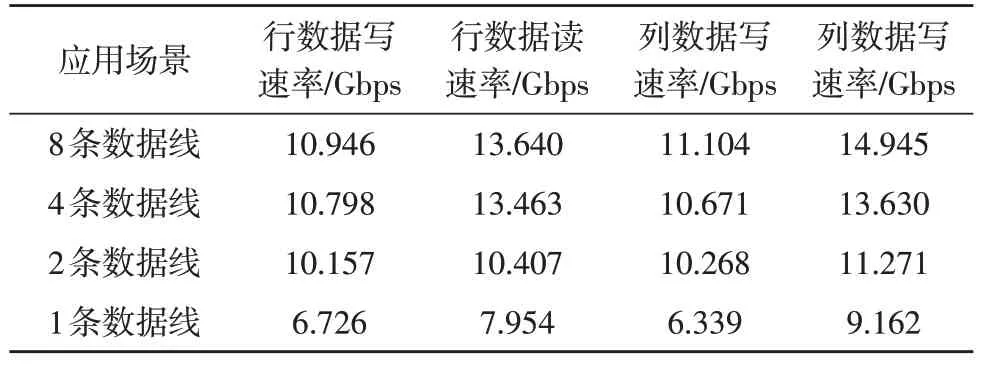
表3 访问线数不同时实验性能对比表
实验数据可以看出,几种访问方式下,随着访问数据线数的降低,数据存写效率也随之降低,常用的2 线和4 线存写和8 线相比性能分别下降了20%和10%,当只进行单线读写时速率达到最低,仅能达到8 线访问性能的60%,实际应用中可根据具体需求选择最合适的访问模式来完成二维矩阵的传输。
5 结束语
该文提出的基于SRIO 网络的多DSP 架构模式简单灵活易扩展,有效解决了存储数据量庞大及系统芯片间数据矩阵传输效率的问题,搭配文中阐述的二维矩阵存储方案,相较于线性存储,显著地提高了两个维度中较慢维度的传输速率,同时对另一维度数据的存取影响有限,使系统的综合效率得以提高。
