基于二阶段网络的起重机小样本图像锈蚀检测
2022-11-05张燕超翟象平魏明强
王 华 张燕超 吴 波 翟象平 魏明强
1江苏省特种设备安全监督检验研究院 南京 210036 2南京航空航天大学计算机科学与技术学院 南京 211106
0 引言
起重机械作为我国国民经济建设中的重要基础设施,在重大工程建设和重大战略规划的落实上均发挥了重要的支撑作用。由于其广泛分布在各种工业生产场所,长期处于高强度、重载荷的运行状态,工作环境复杂多变,特别是高温高压的易爆环境或强风高湿的露天沿海场所,且作业人员长期暴露在其周围,导致安全事故频发,给人民群众的生命财产安全构成极大威胁[1]。
为了降低起重机设备发生事故风险,起重机损伤检测已是特种设备的监管的一项重要工作。起重机的损伤主要包含锈蚀、断裂、裂纹等[2],本文只关注起重机的锈蚀损伤检测工作。
起重机损伤检测的主流方法为人工检测,这种方式劳动强度大,高空作业存在危险性,且成本昂贵、误检率高、效率低下。为了解决上述问题,自动化的表面缺陷检测法逐步引入到了实际应用中。与人工检测方法相比,基于计算机视觉的检测方法具有高鲁棒性、高效率等特点[3-5]。
目前,基于计算机视觉的缺陷检测方法可分为传统检测方法和深度学习检测方法2类。传统检测方法依赖手工设计的特征提取算子[6-8],针对特定情境的缺陷进行检测,无法适用于复杂的场景变化,鲁棒性较差。深度学习方法则利用卷积深网络层[9,10]从输入的大量缺陷数据中抽象出高维特征,通过多次迭代训练检测缺陷。与传统检测算法相比,深度学习方法对缺陷特征描述更贴近真实情况,鲁棒性较好,识别率高,在工业场景下得到了越来越广泛的应用。
本文所涉及的起重机械金属结构形状复杂,包含箱形梁、工字梁、桁架等多维度平面和三维曲面检测,不同表面光照差异大、反光强、对比度低、锈蚀形态多变(见图1),同时也存在物体阴影、黑色背景物等与锈蚀颜色非常相似的特征干扰。另一方面,目前尚无起重机锈蚀损伤相关的公开数据集,收集大量的锈蚀损伤相关图片并标注,特别是标注需要细粒度分割的损伤部位,需要耗费大量的人力,进一步加大了起重机锈蚀检测的难度。

图1 起重机表面锈蚀情况
为解决以上问题,本文提出了一种适应起重机械金属结构复杂背景和复杂表面特征的小样本锈蚀损伤检测算法,旨在对起重机金属结构表面锈蚀损伤进行自动识别。对基于Mixed Supervision For Surface-defect Detection(以下简称MSFSD)的小样本缺陷检测算法进行改进,在MSFSD的卷积层的Block中引入残差结构,解决深层网络中的梯度消失的问题,使网络更易于收敛。实验结果表明,在自建的起重机小样本图像锈蚀数据集上,改进后的MSFSD算法将模型的平均精度由94.2%提升到了98.1%,检测性能得到了有效提升。
1 相关工作
1.1 缺陷检测
随着深度学习技术的广泛应用,缺陷检测任务中出现了一批基于卷积神经网络的深度学习方法。Shang L D等[11]提出了一种需要预处理的二阶段铁轨缺陷识别算法,首先使用Canny算子结合直线拟合算法定位铁轨区域并裁剪原始图像,然后使用Inception V3[12]网络对缺陷图片进行特征提取和分类。为了同时检测多种损伤,Cha Y J等[13]提出一种基于Faster R-CNN的检测方法。与传统的卷积神经网络相比在检测速度上占有很大优势。Huang Y B等[14]提出MCue Push Unet对磁瓦表面缺陷进行显著性检测。MCue模块将原始图像处理为三通道图像输入Unet,提升了预测结果的存储效率。
虽然上述各种深度学习方法的缺陷检测效果较好,但是需要大量的训练样本更新网络参数,而在工业界实际应用场景中大部分缺陷样本属于少量样本,无法满足上述网络需要大量样本的训练要求。
1.2 小样本学习
样本增广和数据合成是小样本学习常用的2个手段。样本扩增指的是对训练样本采用镜像、旋转、平移、裁剪、滤波、对比度调整等基础的图像处理方式增加样本数量[15]。在缺陷检测领域,数据合成是指将单独缺陷部分叠加至无缺陷的负样本上构成缺陷样本。由于在图像生成工作中展现出了卓越的性能,Goodfellow I等[16]、Zhang H D 等[17]和 Chou Y C等[18]也被应用到了缺陷样本生成任务中。除了以上2种常见的解决方案,Karlinsky L等[19]提出一种基于代表性的度量学习 (Representative-Based Metric Learning,RepMet) 网络,通过衡量输入图像的嵌入特征向量与目标类别表征向量之间的相似性实现小样本的检测识别。另外,优化网络结构也可达到减少训练样本的目的。Božič J等[20]设计了一个融合分类和分割的多任务缺陷检测网络MSFSD,2个分支共享Backbone提取的特征,在分割网络中输入图像的每个像素都被看作训练样本进行训练,故该方式大大增加了有效样本数量。在不进行预训练的情况下,在KolektorSDD数据集上,整个网络能够仅利用33张带有分割标签的缺陷样本实现有效训练,并取得了平均精度(Average Precision,AP)100%的缺陷检测效果。
鉴于MSFSD网络在小样本缺陷检测上取得的显著效果,本文通过将MSFSD二阶段网络由类似于VGGNet的结构提升到为类似于ResNet的残差结构来实现起重机锈蚀检测,提升其在起重机小样本锈蚀损伤中的检测性能。
2 基于MSFSD二阶段网络的检测原理及优化
2.1 MSFSD二阶段网络算法原理
MSFSD是一种二阶段的小样本的表面缺陷检测网络,具有精度高、训练样本少、无需预训练、计算量小的特性,能在KolektorSDD数据集上仅用33张带有分割标签训练样本进行有效训练,并取得了AP100%的缺陷检测效果。
整个网络分为分割网络(Segmentation Network)和决策网络(Decision Network)2个部分。其中,分割网络提取图片特征,输出标记缺陷区域的二元分割图;决策网络对分割网络得到的高维特征做进一步提取,最终输出图片中是否存在缺陷的判断结果。具体网络结构如图2所示。

图2 MSFSD算法原理及改进示意图
在分割网络中,输入图像经过多组卷积进行特征提取,每2个卷积组之间包含1个2h2的池化层,将特征尺寸压缩至原来的1/2。分割网络的前3层采用5h5的卷积核,而最后一层采用15h15卷积核。大尺寸的卷积核能有效增加模型的感受野,适合检测高分辨率的输入图像。分割网络会对缺陷图片进行逐像素定位,使用像素级的Loss有效地将每个像素视为一个单独的训练样本,从而增加训练样本的有效数量,防止模型出现过拟合现象。因此,为了有效应对小样本检测问题,可提高输入图片的分辨率以丰富模型的样本数。
分割网络的输出为2个分支,1个分支通过1h1的卷积层将1 024个通道的特征图压缩为1个通道,得到1张只有原图尺寸1/8大小的分割图;另一个分支则直接输出1 024维的特征图。
随后将这2个分支输入决策网络,并级联起来使用卷积操作进一步提取丰富特征,最终得到1个32通道的特征图。将该特征图分别经过全局最大值池化和全局平均池化转化为2个32维的向量,同时上一阶段分割网络输出的分割图也经过全局最大值池化和全局平均池化成2个标量值。将这66个值级联起来作为最终提取的特征,再送入全连接层得到1个标量,使用Sigmoid激活函数将该标量转成0~1范围内的数值表示缺陷出现的可能性,靠近0表示没有缺陷,靠近1表示有缺陷。
MSFSD的分割网络输出的预测图片分辨率是输入图片分辨率的1/8,只能预测出缺陷的大致位置与轮廓。MSFSD更关注的是图像是否含有缺陷,而不是缺陷的具体大小,这种方式能够满足很多工业实际场景要求,也让MSFSD对标注的精度没有较高的要求,极大地减少了标注的工作量,有利于数据集的构建。
2.2 RepVGG网络
VGGNet是深度卷积神经网络,其结构非常简洁,通过反复堆叠3h3的小型卷积核和2h2的最大池化层,在当时取得了较好的性能,引起了广泛的关注。然而,VGGNet不能很好地扩展网络深度,随着层数不断加深会出现深层网络梯度消失现象,导致分类预测性能的下降。
ResNet的提出成功地解决了上述问题,ResNet使用了一种残差结构解决了深层网络中的梯度消失问题,使得网络更易于收敛,突破了VGGNet不能扩展到更深层次的限制。借助这些优势ResNet在ImageNet数据集上取得了比VGGNet更高的性能,在当前很多场景下基于残差结构的ResNet已经代替VGGNet成为计算机视觉领域中的基础特征提取网络。
RepVGG[21]在VGGNet的基础上结合了ResNet网络的优势对VGGNet加以改进,在VGGNet的Block中加入Identity和Conv1h1残差分支,使RepVGG-B2在ImageNet上的准确率比VGG16提升了6.57%。
图3a为原始的ResNet网络结构,该网络中包含Conv1h1和Identity的残差结构,正是这些残差结构解决了深层网络中的梯度消失问题,使得网络更加易于收敛。图3b为RepVGG训练阶段的网络结构,整个网络的主体结构和ResNet网络类似,均包含了残差结构。2个网络中的主要差异为:1)ResNet中的残差块跨越了多层,而RepVGG没有;2)RepVGG包含2种残差结构,在Stride为2对特征图下采样的Block中仅包含一个Conv1h1残差分支,而在特征图尺寸不变的Block中同时包含Conv1h1和Identity残差分支。由于残差结构具有多个分支,相当于给网络增加了多条梯度流动的路径,能更好地处理网络深层的梯度消失问题。训练1个RepVGG结构的网络,相当于同时训练了多个网络,这种类似模型集成的思想在众多的模型竞赛中被广泛使用,有效地提升了模型的性能。
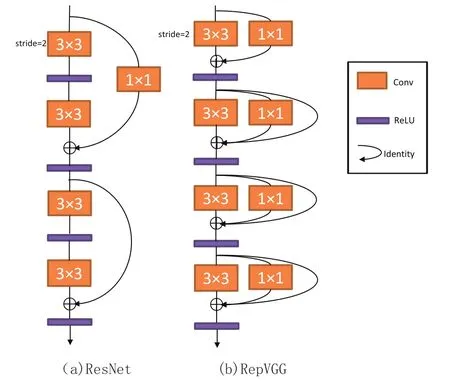
图3 RepVGG卷积层部分结构图
2.3 MSFSD二阶段网络的改进
在MSFSD中的分割和决策网络都采用类似于VGGNet的Plain结构,借鉴RepVGG的思想,本文通过引入多分支结构对MSFSD进行改进,其结构如图4所示,在每个卷积层的Block中引入了Conv1h1和Identity残差结构分支,与RepVGG不同的是,实验中发现使用Maxpool2h2的方式对特征图进行下采样比使用卷积步长为2的下采样方式更优,原因是Maxpool能在下采样过程中更有效地保留小而重要的细节,更有利于小目标的特征提取。另外,发现在决策网络最后一层保持原来的Plain结构效果会更好,故对除该层以外的其他每个卷积层的Block使用上面的残差结构,其具体改进如图2中的红色虚线框所示,通过在MSFSD的卷积层中引入Conv1h1和Identity残差结构分支有效地提升MSFSD的损伤检测性能。
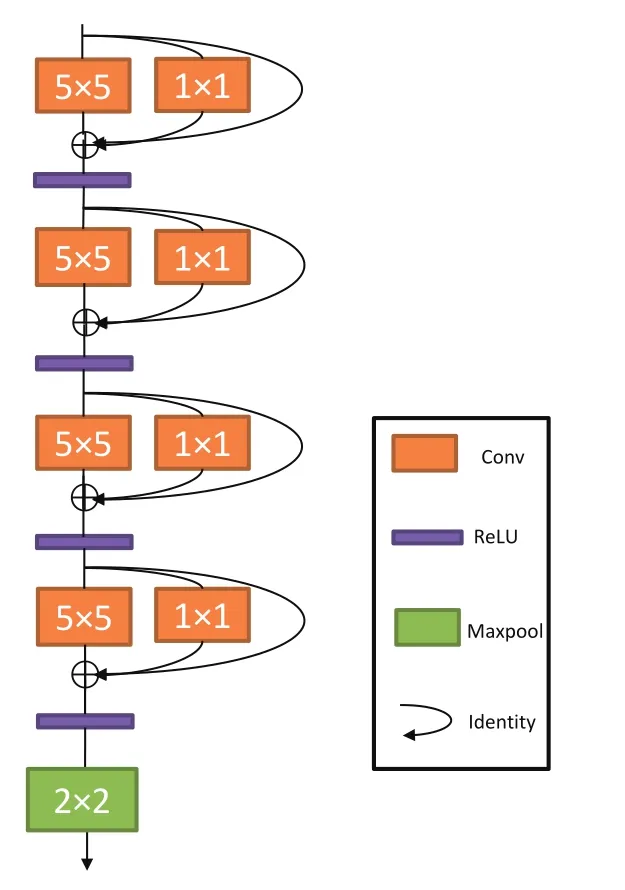
图4 改进后的MSFSD卷积层部分结构图
3 实验
3.1 数据集
由于目前没有公开的起重机锈蚀损伤图片数据集,本文采用现场拍摄的起重机锈蚀损伤照片作为正样本,不含锈蚀损伤的起重机表面图片为负样本。该数据集图片包含起重机不同部位的锈蚀特征,锈蚀大小与锈蚀程度不一。
数据集图片统一像素大小为768h1 000,对于带有锈蚀损伤的正样本图像,需要使用Labelme软件进行分割标注。起重机锈蚀损伤通常伴随着起重机表面涂层破损,锈蚀部位往往会呈现黑色或红棕色,且锈蚀表面较为粗糙。按照该经验标注结果如图5所示。其中图5a为原始的锈蚀图片,图5b为最终的标签图片,锈蚀区域用白色标注,其像素值为255,背景区域用黑色标注,其像素值为0。在完成所有图像数据的标注工作后,将数据集划分为训练集64张,其中正样本21张,负样本43张;验证集80张,其中正负样本各40张。只有训练集中的21张正样本需要做分割标注,验证集中的正样本只需进行简单的类别标注,所有负样本都无需标注,且分割标签也无需精细标注,极大地降低了标注难度,减少了标注成本。

图5 起重机锈蚀损伤情况
3.2 训练策略
本文所涉及的二阶段网络分为分割网络和决策网络。其中,分割网络采用逐像素的二元交叉熵损失函数,决策网络采用交叉熵损失函数。
为了使二阶段网络实现端到端的学习,MSFSD融合了2种Loss,允许进行联合训练。
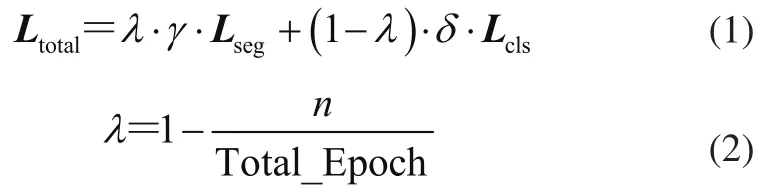
式中:Lseg和Lcls为分割网络和决策网络的Loss;δ为超参数,用来调节决策网络的Loss比重,在本实验中δ被设为0.1。
由于决策网络依赖于分割网络提取的特征,故在训练时需要一个已经相对稳定的分割网络。因此,在训练的前期阶段加大分割网络训练的比重,在训练中期逐渐减少分割网络比重同时增加决策网络的比重,形成一个动态平衡的过程。式(2)中λ为混合因子,用来平衡2个网络在训练过程中Loss的比重,这里的n为当前已训练的Epoch次数,Total_Epoch表示设定的整个训练的Epoch次数。在训练的开始阶段λ值较大,代表此时网络会着重关注分割部分的训练。随着已训练次数n的增加,决策网络的Loss所占比重也会增加,此时会逐渐关注决策网络的训练。通过这种方式可实现二阶段网络端到端的训练。
3.3 模型训练
为了对所提方法进行合理评估,所有模型均在Ubu ntu18.04+Python3.6.9+Pytorch1.6.0环境下训练和测试,使用显存为11 G的GeForce GTX 1080Ti显卡进行加速。
本文实验训练使用SGD算法对网络进行迭代优化。训练输入批次为1,决策网络的Loss权重为0.1,学习率为0.2,迭代次数为120次。选取平均精度AP来衡量算法检测精度。
3.4 实验结果分析
3.4.1 对比实验
为了验证对MSFSD模型改进的有效性,本文在自建的起重机表面锈蚀损伤的小样本数据集上进行训练和评估。本文实验模型没有经过预训练,所有参数都采用Xavier方式随机初始化。为了进一步排除由于随机初始化因素对性能比对的影响,本实验将随机数种固定为1 337,使得模型在同样的初始化参数下对模型改进前后的结果进行比较。
本文实验选择了Chen W Y等[22]提出的Baseline、Baseline ++小样本学习模型和U-Net语义分割模型与改进后的MSFSD性能进行对比。其中,Baseline、Baseline++是小样本学习领域具有较高影响力的模型,虽然采用基于预训练加微调的学习方法,但性能却超越了元学习、度量学习等复杂的小样本学习方法中众多先进的模型,开启了该领域对小样本学习方法的重新思考。本文实验在这2个模型中使用ResNet12作为主干特征提取网络,在自建的起重机表面锈蚀损伤小样本数据集上训练验证。U-Net模型具有非常出色的语义分割性能,在医疗领域得到了广泛的应用。使用U-Net能充分利用自建的起重机表面锈蚀损伤小样本数据集的分割标签对网络进行训练。本文实验将改进后的MSFSD的分割网络替换为U-Net,其他部分不变,以此作性能对比,模型均选取了测试最好结果。表1为各模型的性能对比数据,Baseline、Baseline ++在自建起重机表面锈蚀数据集下AP分别为62.4%和72.6%,由于这2个小样本学习模型只能利用分类标签进行训练,故在少量样本下分类性能较低。使用U-Net作为分割网络的AP为71.1%,这说明U-Net在训练集样本较少的情况下无法学习到损伤的有效特征,无法达到很好的性能,与改进后的MSFSD有较大差距。
3.4.2 消融实验
为了验证本文提出方法的效果,在MSFSD基础上逐步加入了Identity和Conv1h1残差分支进行消融实验,结果如表1所示。在MSFSD基线上检测出的AP为94.2%,此时FP(被错误的标记为正样本的负样本数)=7,FN(被错误的标记为负样本的正样本数)=1。在加入Identity残差分支后AP提升了2%,达到了96.2%,此时FP=3,FN=5。在同时加入了Identity和Conv1h1残差分支后AP提升了3.9%,达到了98.1%,此时FP=2,FN=1。实验结果表明改进后的算法能够有效提升起重机锈蚀损伤的检测性能。
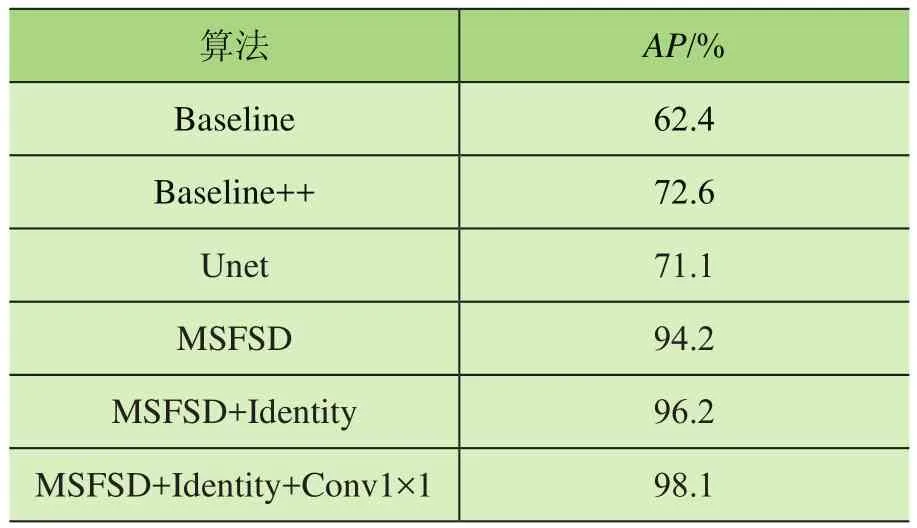
表1 起重机锈蚀损伤检测实验结果对比
3.4.3 MSFSD算法改进前后的Loss及AP曲线
图6为MSFSD算法改进前后的Loss及AP曲线,其中,Seg Loss为分割网络损失曲线,Dec Loss为决策网络损失曲线,Total Loss为二阶段网络总损失曲线。图6a为MSFSD基线Loss及AP曲线,图6b为改进后的MSFSD Loss及AP曲线,可以看到,改进后的MSFSD二阶段网络总损失收敛速度更快,Loss曲线更平滑,模型收敛后AP曲线更接近于1.0。
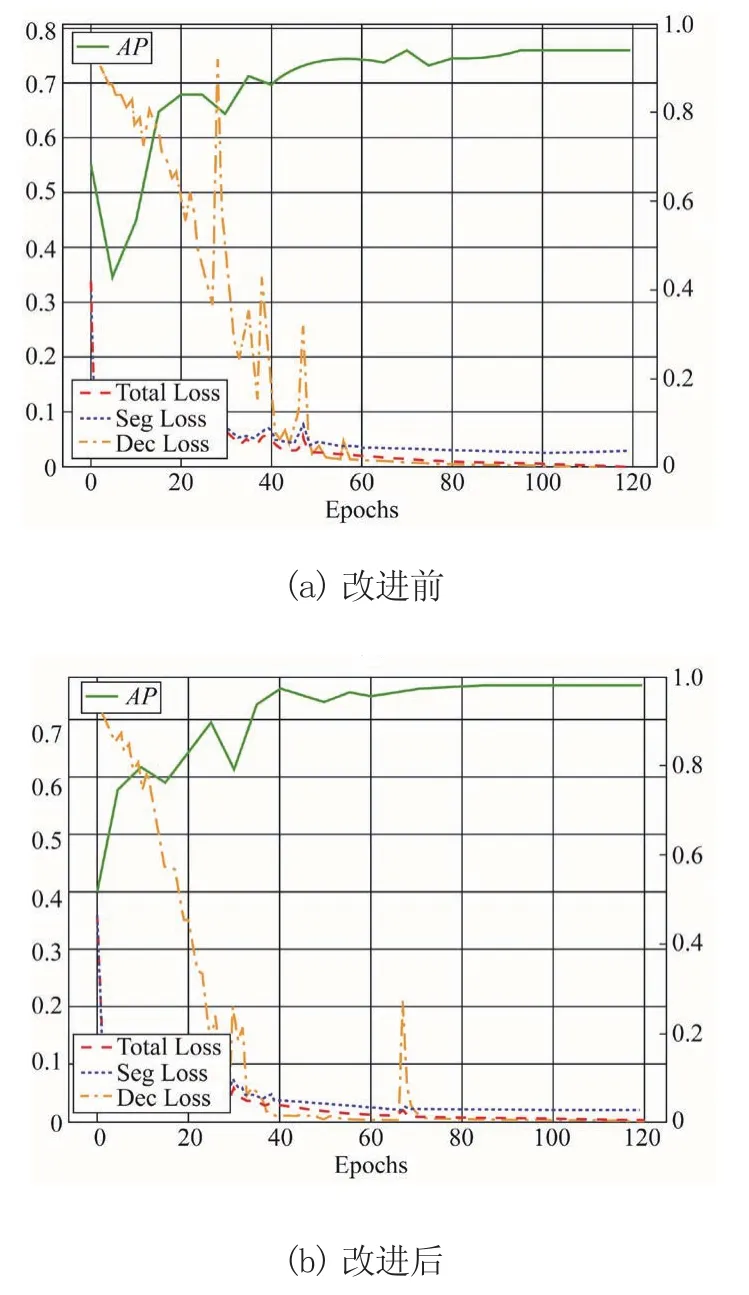
图6 改进前后的MSFSD算法Loss及AP曲线
3.4.4 MSFSD改进算法预测结果分析
图7为模型检测正确的样本,图中每张图片的左边为输入的图片,右边为分割网络输出的分割图,分割图中高亮部分代表输入图片中相应部位有较高的概率含有锈蚀损伤,分割图上Output后面的数值代表决策网络预测输入图片是否含有锈蚀的概率。图7a是模型预测正确的正样本,此时决策网络输出的概率值都较大,模型输出的分割图中高亮处对应了输入图片的锈蚀部位。图7b是模型预测正确的负样本,此时决策网络输出的概率值都较小,模型输出的分割图中无明显高亮部位。另外,从图7b中看到一些图片中存在物体的阴影与锈蚀颜色比较接近,但模型未将物体的阴影误预测为锈蚀,说明模型对物体的阴影有较强抵干扰能力。


图7 模型检测正确的样本
为了进一步检验模型的抗干扰能力,本文实验在验证集中加入了一些干扰性很强的难例样本。图8展示了模型检测出错的样本,图8a是模型误将负样本分类成了正样本,该输入图片中包含了黑色的钢架,此时模型输出的概率值为0.908 53,模型输出的分割图中黑色钢架对应的位置被高亮了,模型误认为这里包含锈蚀损伤。其原因是该输入图片中黑色钢架结构与起重机锈蚀损伤的颜色非常相似,模型不能从语义的角度去理解和区分这2种特征,故模型错误地认为该图片中包含了锈蚀损伤。图8b是模型误将正样本分类成了负样本,此时模型输出的概率值为0.112 97,原因是该样本中包含的锈蚀损伤面积较小,模型的卷积核都较大,小目标在特征提取过程中容易丢失,故图中的锈蚀损伤没有被检测到。

图8 模型检测出错的样本
4 结语
本文采用二阶段网络MSFSD的改进算法对起重机锈蚀损伤进行检测,设计了高效的检测系统。在MSFSD模型基础上通过在MSFSD每个卷积层的Block中引入了Conv1h1和Identity残差结构分支提升了MSFSD的检测性能。最终使改进后的模型在自建起重机锈蚀损伤检测中测数据集上AP达到了98.1%,较基线算法提升了3.9%。本实验数据集中的样本都是在自然环境下对起重机各个部位复杂表面进行采集,对光照、相机等没有特别的限制,在小样本数据集下取得了较高的精度,故算法可进一步应用到其他工业检测领域。
