基于Retinex理论的全卷积网络低光图像增强方法
2022-11-03余雅琪杨梦龙
余雅琪,杨梦龙
(四川大学 空天科学与工程学院,四川 成都 610065)
0 引 言
在图像拍摄过程中所存在的光照不足会严重影响图像的对比度和亮度,并且会有一定的噪声和伪像存在;解决低光图像的这一系列降质现象并将低光图像转变为高质量的普通光图像有助于一些高层视觉任务的执行,如:图像识别、目标检测、语义分割等;同时能够在一些实际应用中提升智能系统的性能,如:自动驾驶、视觉导航等,因此解决低光图像增强的问题十分有必要。
过去的几十年里,众多学者已经做了大量关于低光图像增强的研究,这些研究主要可以分为两种类型:传统方法和基于深度学习的方法。其中传统方法主要包括基于直方图均衡化的方法和基于Retinex 理论的方法。基于直方图均衡化的方法通过改变图像的直方图来改变图像中各像素的灰度来增强图像的对比度,例如亮度保持直方图均衡化(BBHE)、对比度限制自适应直方图均衡化(CLAHE)等;Retinex理论假定人类观察到的彩色图像可以分解为照度图(I)和反射图(R),其中反射图是图像的内在属性,不可更改;Retinex 理论通过更改照度图中像素的动态范围以达到增强对比度的目的,如单尺度Retinex(SSR)利用高斯滤波器来平滑生成的照度图;多尺度Retinex(MSRCR)在单尺度Retinex 的基础上进行改进,利用了多尺度高斯滤波器并对色彩进行了恢复;SRIE提出一种加权变分模型以同时估计反射图和照度图;LIME通过一种加权振动模型来获得所估计的具有先验假设的照度图,并利用BM3D作为后续的去噪操作。虽然这些方法能够在一定程度上增强图像对比度,但是受到模型分解能力的限制,增强后的结果往往不尽人意。
近十年来,深度学习在计算机视觉领域得到了广泛应用,并取得了非常优异的效果;众多优异的方法,如深度卷积神经网络、GAN 等,已经被广泛应用于各种场景,包括图像去雾、图像超分辨率、图像去噪等;同样,这些方法也大量应用于解决低光图像增强问题。LLNet提出了一种堆叠稀疏自编码器用于增强图像对比度并进行去噪;Retinex-Net将Retinex 理论与深度卷积神经网络相结合来估计和调整照度图,以提升图像对比度,并利用BM3D进行后处理以实现去噪;KinD同样基于Retinex理论设计了一个用于解决低光图像增强问题的深度卷积神经网络,并设置了Restoration-Net 作为网络的去噪后处理部分;Wang等人设计了一种新的深度增亮网络(DLN)来将低光图像增强问题转化为残差问题;Guo等人提出了一种轻量级的图像增强网络Zero-DCE,将图像增强问题转换为曲线估计问题;除了深度卷积神经网络,还有一些基GAN 的方法,Jiang等人提出了用于低光图像增强的网络EnlightenGAN,并且第一次采用了不成对图像进行训练;Chen等人也提出了一种改进双向GANs 的非配对学习图像增强方法。总的来说,先前的低光图像增强方法大多只关注于对比度增强方面,受到模型性能的影响没有很恰当地提升图像的对比度,会造成一定的过增强/欠增强现象,而且没有考虑增强后的噪声放大问题,或者是采用后处理操作来实现去噪,最终没有得到令人满意的增强效果。
本文提出一种全新的低光图像增强网络,包含DecomNet、DenoiseNet 和RelightNet 三个子网络;DecomNet引入残差模块,将输入的图像分解为光照图和反射图;DenoiseNet 将DecomNet 所分解得到的照度图和反射图作为输入,将图像进行傅里叶变换,得到去噪后的反射图;RelightNet将光照图和去噪后的反射图作为输入,通过全卷积神经网络得到最终的增强结果。通过精心的网络设计和损失函数配置,该方法不仅能恰当地增强图像的对比度,同时还能实现噪声抑制。
在低光图像增强任务中的另一个难点在于缺少大规模的真实低光/普通光图像对数据集,为了解决这个问题,收集了公开可用的低光/普通光图像对数据集组合成一个大规模数据集用作网络训练。
1 方法介绍
在这一部分,基于Retinex 图像分解理论提出了一种全新的全卷积网络用于解决低光图像增强问题,很大程度解决了先前的过增强、欠增强和增强后的噪声放大问题。本节将会介绍提出的方法的具体细节,包括整体网络结构、子网络(DecomNet、DenoiseNet、RelightNet)结构、损失函数设置以及实验细节,构、损失函数设置以及实验细节。
1.1 网络结构
提出了一种全新的全卷积网络,包含三个子网络,DecomNet、DenoiseNet 和RelightNet,如图1所示,展示了提出的全卷积网络架构,其中DecomNet 基于Retinex 理论将输入图像分解为光照图和反射图;DenoiseNet 用于抑制反射图中的噪声;RelightNet 将DecomNet 和DenoiseNet 的输出结果作为网络输入,增强分解后所得到的光照图的对比度和亮度,以解决低光条件下所造成的低对比度、低亮度问题,最后根据Retinex 理论,将去噪后的反射图和增强后的光照图相乘得到最终的处理结果。
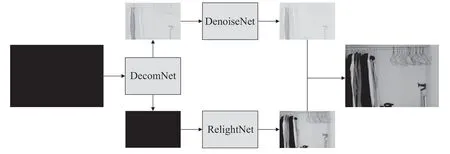
图1 网络结构
1.1.1 分解网络
残差组件已经在众多计算机视觉任务中得到广泛应用,且取得了非常优异的成果;得益于其跳跃连接结构,残差组件可以使深度神经网络在训练中更容易优化,并且在训练过程中不会产生梯度消失现象,因此受到残差学习的启发,使用了多个残差组件构成DecomNet,防止网络过拟合,得到更好的分解结果。
DecomNet 包含6 个步长为1 的3×3 卷积层,且每个卷积层的输入输出特征图大小保持一致;利用跳跃连接结构,将第-1 个卷积层和第个卷积层的输出结果结合起来作为第+1 个卷积层的输入(=2,…,5),每个卷积层后都跟随着LeakyReLU 激活函数,DecomNet 的具体网络结构如图2所示。
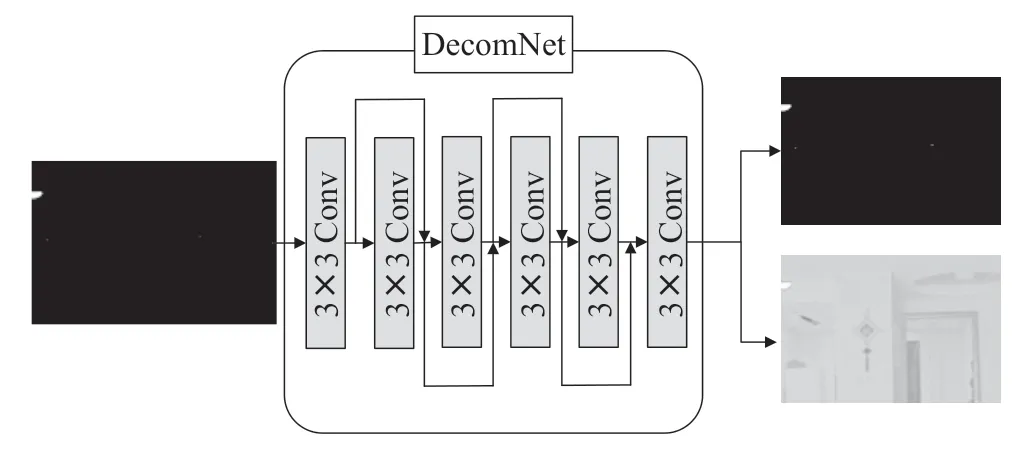
图2 DecomNet 网络结构
DecomNet 的输入为低光图像和普通光图像,输出结果分别是低光图像和普通光图像的照度图(/)和反射图(/),但是其他基于Retinex 理论的方法在分解过程中并没有抑制反射图中所包含的噪声,这会使得最后的增强结果受到反射图中存在的噪声的影响(如图4中LIME和Retinex-Net的增强结果)。DecomNet对普通光图像分解后得到的照度图和反射图并不参与后续的训练,仅仅只是为低光图像的分解提供参考。
1.1.2 去噪网络
为了抑制分解后的照度图和反射图噪声,DenoiseNet 将DecomNet 对低光图像分解后得到反射图作为输入,基于傅里叶变换,用Complex conv 构建了一个ResUnet 结构,在频域内对噪声进行抑制。DenoiseNet 先将输入图像进行两个步长为1 的3×3 卷积操作,经过特征提取后,再将图像进行傅里叶变换与逆变换来达到噪声抑制的效果,最终得到去噪后的分解结果图。
1.1.3 增强网络
U-Net网络得益于其出色的结构设计,在大量的计算机视觉任务中取得了非常优异的成绩;在低光图像处理领域,也有大量的网络都采用了U-Net 网络作为其网络主体或其中的一部分。但是U-Net 在特征提取阶段用了多个最大池化层,但是最大池化层并不具备平移不变性,并会导致大量的特征信息丢失,因此该作者采用了跨步卷积来代替池化层,虽然会略微增加网络参数,但也使得精度有所提升。受到这一点的启发,文章采用了跨步为2的2×2卷积层来代替U-Net网络中的最大池化层,这样有利于网络学习到更丰富的特征信息并保持平移不变性,可以使得网络能更好地提升反射图的对比度;还充分结合了多尺度融合的思想,将扩展阶段中每个反卷积层的输出相融合以减少特征信息的丢失;在表3中也验证了RelightNet 结构设置的优越性。
RelightNet 基于ResUnet 构建,采用了deep-narrow 结构,提升了原始ResUnet 的网络深度。RelightNet 中包含7 个卷积模块,每个卷积模块包含4 个步长为1 的3×3 卷积层以保持前后特征图大小一致;前三个卷积模块后都跟随一个步长为2 的2×2 卷积层以执行下采样操作;后三个卷积模块后都跟随一个步长为2 的2×2 反卷积层以执行上采样操作;随后利用多尺度融合的思想,将第7 个卷积模块的输出与前三个反卷积层的输出相结合作为下一层卷积层的输入,这样能够最大程度的结合上下文信息,减少特征信息的丢失;最后经过一个步长为1 的3×3 卷积层来得到增强后的照度图,RelightNet 中每个卷积模块后都跟随着ReLU 激活函数。RelightNet 结构如图3所示。

图3 RelighNet 网络结构

1.2 损失函数
由于DecomNet、DenoiseNet和RelightNet是分别训练的,因此整个损失函数包含三个部分:分解损失ℒ、去噪损失ℒ和增强损失ℒ。
分解损失:与Retinex-Net相似,分解损失包含四个组成部分:重构损失ℒ、反射一致性损失ℒ、照度平滑损失ℒ和感知损失ℒ,如公式(1),其中λ和为平衡反射一致性和照度平滑度的系数;

由于普通光照图像所分解出的光照图和反射图可以用作训练过程中低光图像分解的参考,因此利用ℒ损失函数来表示重构损失,使模型分解出来的反射分量和光照分量能够尽可能重建出对应的原图,如公式(3);
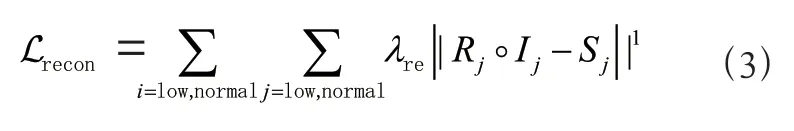
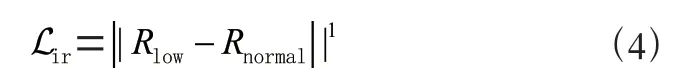
根据Retinex 图像分解理论,反射分量与光照无关,因此成对的低光图像和正常光照图像的反射分量应该尽可能一致,所以引入反射一致性损失来实现这一目的,如公式(4);由光照的先验知识可知,自然图像的光照应该是平滑的,属于低频信息,这一点在数学上反映为图像中每个像素点的横向与纵向梯度都不能过大。所以对反射分量求梯度来给光照分量的梯度图分配权重,使得反射分量上较为平滑的区域对应到光照分量上同样也应该尽可能平滑。因此引入照度平滑损失ℒ来保证和对应的分量相匹配,如公式(5);

感知损失将真实图片卷积得到的feature 与生成图片卷积得到的feature 做比较,使得高层信息(内容和全局结构)接近,以便分解出的结果更加符合人眼视觉,如公式(6),其中,表示损失网络,C、H、W表示第层的特征图的大小。

去噪损失:为了使去噪后的图像更加接近原图,在去噪过程中,采用了傅里叶变换损失ℒ和细节表达损失ℒ来获取更多的图像细节,如公式(7);

其中,傅里叶变换损失采用了ℒ损失,在保证傅里叶变换前后图像结构不变的同时获得尽可能好的噪声抑制效果;细节表达损失采用了SSIM 损失以获得更好的细节表达能力,尽可能地使得去噪后和反射图和DecomNet 分解出的网络图在结构上保持一致,如公式(8),SSIM 损失的作用也在表3中得以体现;
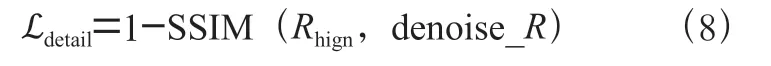
增强损失:为了使得增强结果更加逼近普通光图像,在增强损失中也采用了重构损失ℒ、和结构相似度损失ℒ来获得更好的细节表达能力,如公式(9),其中重构损失去噪损失中保持一致,都是为了保证反射图R 和照度图I 能够重建出相应的原图;
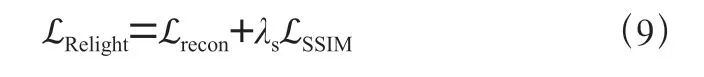
由于人眼对于图像的视觉认知是从图像的整体结构出发的,所以引入了结构相似度损失,使得增强后的图像在视觉效果上更为真实自然,如公式(10)。

2 实验结果与分析
为了验证所提出方法的优越性,通过大量的实验来评估所提出的方法,并与现存的方法进行比较,包括:MF、Dong、NPE、MSRCR、SRIE、Retinex-Net、Lighten-Net以及EnlightenGAN。总的来说,共进行了三个部分的实验:
(1)在一些公开的低光图像数据集上对所提出的方法与一些现存的state-of-the-art 方法进行了定性与定量比较;
(2)展示了对真实的低光照图像的增强结果,并进行了主观视觉评价实验;
(3)进行了一系列的消融实验来验证所提出的方法的优越性。
2.1 训练数据集与评估度量
训练数据集:由于在真实条件下拍摄成对的低光/普通光图像对十分困难,现存的真实低光/普通光图像对数据集包括LOL 数据集和SID 数据集,但是这两个数据集所包含的数量不足以支持深度神经网络的训练,因此,实验的训练集采用的是用华为P40 Pro 手机拍摄的真实场景下的图像,通过调整手机拍摄参数,总共拍摄了2 450 对图片,拍摄场景包含学校、宿舍、建筑物、餐厅、球场等多种场地。
评估度量:为了更好地定量评估所提出方法的性能,采用峰值信噪比(PSNR)、结构相似性(SSIM)以及自然图像质量评估(NIQE)来进行定量评估。
2.2 实验实施细节
网络是基于PyTorch 实现的,使用提出的合成图像数据集在一个Nvidia GTX1080Ti GPU 上训练了50 个周期;使用ADAM 优化器进行训练,初始学习率设置为ℒ=0.000 1,在训练过程中所使用的batch size=4,patch size=96×96,实验中设置的λ、和均为0.1,和为3。
2.3 真实图像数据集对比实验
为验证所提出的方法,在六个公开数据集上进行性能评估,包括:LOL、LIME、DICM、NPE、MEF、VV2。
LOL 数据集通过改变相机的曝光时间以及ISO 捕获了500 对真实低光/普通光图像对,是现存的仅有的两个真实低光/普通光图像对数据集,在LOL 数据集训练集的500对图像上将该方法与其他现存方法进行了比较,结果如表1所示。
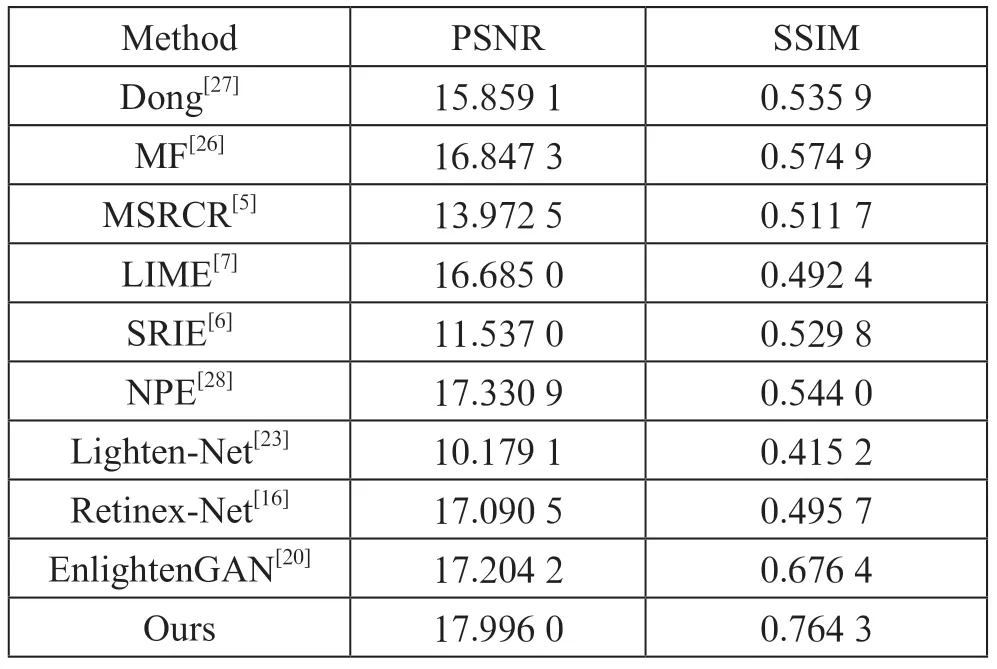
表1 在LOL 数据集上的PSNR/SSIM 对比
从表1可以看出,该方法相较于现存的State-of-art 方法在LOL 数据集上的性能表现更加优异,相较于监督学习中的最优方法Retinex-Net(PSNR 提升了0.791 8 dB,SSIM提升了0.268 6)以及无监督学习中的最优方法EnlightenGAN(PSNR 提升了0.791 8 dB,SSIM 提升了0.087 9)。
此外,该结果具有更好的对比度、更清晰的细节以及更好的噪声抑制能力,视觉效果如图4所示,前两行为LOL数据集上的测试结果,其中(a)为输入低光图像,(b)至(h)为不同方法的处理结果;后两行为VV 数据集上的测试结果;


图4 不同方法在LOL 数据集和VV 数据集上的增强结果
从图4中可以看出,一些传统的方法(如SRIE、NPE等)会有一定程度的增强不足,其他基于Retinex 理论的方法(如LIME、Retinex-Net等)会模糊细节并放大噪声,该方法所生成的增强结果不仅能增强局部和全局对比度、有更好的细节展示并且能很好地抑制噪声。
LIME、DICM、NPE、MEF、VV2 是常用的低光图像增强方法测试基准数据集,其中仅包含低光图像,无法使用PSNR 和SSIM 来对增强结果进行定量评估;因此采用无参考图像质量评估NIQE 来对增强后的结果进行定量评估,对比结果如表2所示。
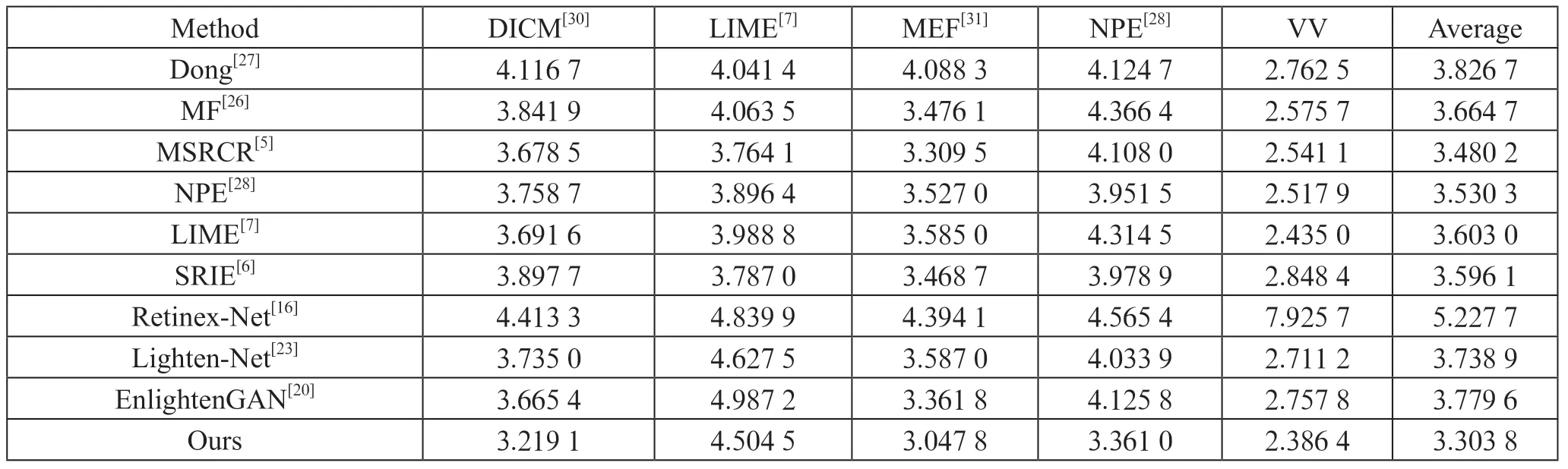
表2 在MEF,LIME,NPE,VV,DICM 数据集上的NIQE 对比
2.4 真实低光图像对比实验
真实低光图像增强:使用HUAWEI P40 Pro 手机专业拍照功能拍摄了10 张真实的低光图像并在收集的真实低光图像上进行评估;利用该方法和现存的方法对所收集的低光图像进行增强,视觉效果如图5所示,其中(a)为输入低光图像,(b)至(h)为不同方法的处理结果。
从图5中可以看出,该方法不仅能够更好地增强图像的对比度,并且在噪声抑制与细节保留上有更好的效果,增强后的结果更加真实,相比之下,其他基于Retinex 理论的方法(如LIME、Retinex-Net)会产生不同程度的噪声放大与细节模糊,其他基于深度学习的方法(如Lighten-Net、EnlightenGAN)会生成过增强或欠增强的结果。


图5 不同方法对真实低光图像的增强结果
主观视觉评价:邀请了20 位在参与者对所收集的真实低光图像利用不同方法增强后的结果进行评价,并要求他们对增强后的图像的对比度、细节保留、噪声抑制以及色彩方面进行综合打分,分数从1(最差)-5(最好),如图6所示,展示了分数的分布,该方法获得了更优秀的分数,由此证明该方法能够获得更令人满意的人眼视觉效果。
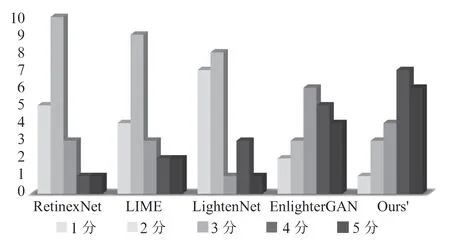
图6 主观视觉评价分数分布结果
2.5 消融实验
在这一部分,在LOL 数据集上对方法中的不同组成部分进行了定量评估,如表3所示。

表3 模型不同组成部分在LOL 数据集上的性能评估
Decom-Net 卷积层数量:当DecomNet 的卷积层数量减少时会获得更高的PSNR 值,但SSIM 值会有所降低(如表3第1 行);卷积层数量逐渐增加时,PSNR 值和SSIM 值都会有所下降,模型性能将会降低(如表3第2、3 行);有研究表明,SSIM 值越高的模型能够在去噪和对比度增强上取得更好的均衡,因此选择8 层卷积层做为DecomNet的默认设置。
损失函数:将DecomNet 的损失函数换为MSE 损失后整体性能将会降低,将RelightNet 中的SSIM 损失函数去掉后,SSIM 值也会有所降低(如表3第4、5 行);这证明了在损失函数设置方面的合理性。
DenoiseNet 网络合理性:将DenoiseNet 去掉后,整体性能明显下降(如表3第7 行),证明了DenoiseNet 的必要性和合理性。
RelightNet网络架构:将RelightNet换为U-Net网络后,整体性能有明显下降(如表3第6 行),证明了RelightNet的优越性。
3 结 论
本文提出了一种全新的全卷积网络用于解决低光图像增强问题;所提出的网络包含DecomNet、DenoiseNet 和RelightNet 三个子网络,DecomNet 能够将低光图像分解为光照图和反射图,DecomNet 能够抑制反射图中的噪声,RelightNet 能够恰当地提升光照图的对比度,最后的增强结果在对比度、亮度、色彩、噪声和伪像抑制上表现十分优异。在多个真实低光图像数据集上的实验结果也表明该方法能够恰当地提升图像对比度并抑制噪声,取得了最优的PSNR 和SSIM 值,相较于其他State-of-art 的方法有很大优势;同时在真实世界低光图像上的增强结果也表明,该方法能够生成更真实、更自然的增强结果;通过主观视觉评价实验也说明该方法所生成的增强图像更符合人类的视觉感知,获得了最高的参与者评分;在消融实验中也充分表明网络结构设置的合理性与优越性。未来的研究中,将进一步从网络结构、损失函数等方面进行优化,探索效果更好的低光图像增强方法,并将该方法运用于更高层的视觉任务中,如低光环境下的目标检测、人脸识别等。
