基于深度注意力模型的个体出行多步预测研究
2022-11-02翁小雄覃镇林罗瑞发
翁小雄,任 杰,覃镇林,罗瑞发
(1.华南理工大学 土木与交通学院,广东 广州 510640;2.深圳市金溢科技股份有限公司,广东 深圳 518000)
0 引 言
最近几年,随着智慧交通的不断发展,越来越多可被用于预测个体出行的数据被采集。个体出行预测对城市发展具有十分重要的意义。从宏观层面来看,政府可以根据出行预测设计更好的交通规划和调度策略,以缓解交通拥堵并处理人群聚集问题;从微观层面来看,通过对个体的出行预测,乘车共享平台可以更好地估计其客户的出行需求并调度资源相应地满足这些要求。
目前对个体出行预测的研究主要是对个体出行进行单步预测,即基于个体历史出行数据对接下来的一次出行进行预测,如基于马尔可夫模型进行优化的MMC模型[1],n-MMC模型[2],隐马尔可夫模型[3]等,基于机器学习的贝叶斯模型[4],随机森林模型[5],BP神经网络模型[6]等,而这些传统模型难以提取到个体出行中较为复杂周期性规律,在特征提取方面具有较大的局限性,难以用于多步预测研究。此外,很多交通场景需要基于个体未来一段时间的出行进行规划和调度,而单步预测难以满足这些场景的需要,如公交调度、交通规划等;最后,这些研究大多使用个体出行的GPS数据[7-8]进行预测,而由于GPS等非交通系统采集到的数据质量和情况不同,这些个体出行数据多是低采样的,且通常将所有个体的出行特征融合在一起,数据通常具有较强的稀疏性和异构性,因此这类研究的预测精度一般不高。
针对当前个体出行研究的局限性, 设计了3种基于序列到序列(sequence to sequence, Seq2Seq)并结合注意力学习机制的深度学习模型,对个体出行进行多步预测。个体的多步预测即使用个体过去一段时间的历史出行数据,对其未来一段时间的多次出行进行预测,如图1。
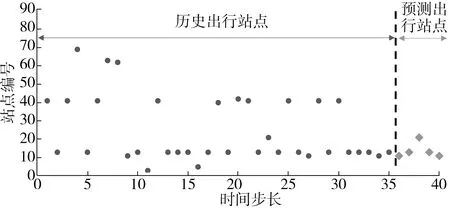
图1 多步预测
首先采用词嵌入的方法对数据进行特征映射,通过嵌入层提取出行特征,由于提取到的出行特征可以随着模型的训练不断更新和优化,因此相较于传统模型更能提取出包含复杂的周期性出行规律的语义信息;然后采用门控循环单元(GRU)来实现Seq2Seq深度学习模型,并引入注意力机制来增强模型对周期性规律的捕捉能力,以提高准确率,以此完成对个体出行的单步预测。进一步地,为了尽可能地减少多步误差,提高模型预测精度,笔者设计了3种多步预测模型:①整体输出式多步预测模型;②步进输出式多步预测模型;③多模型组合式多步预测模型来完成对个体出行的多步预测。笔者针对地铁系统的个体出行场景,使用AFC数据对地铁乘客进行多步预测研究,从而填补了单步预测难以满足预测需求的场景。使用地铁羊城通数据对提出的模型进行验证,其主要网络结构如图2。
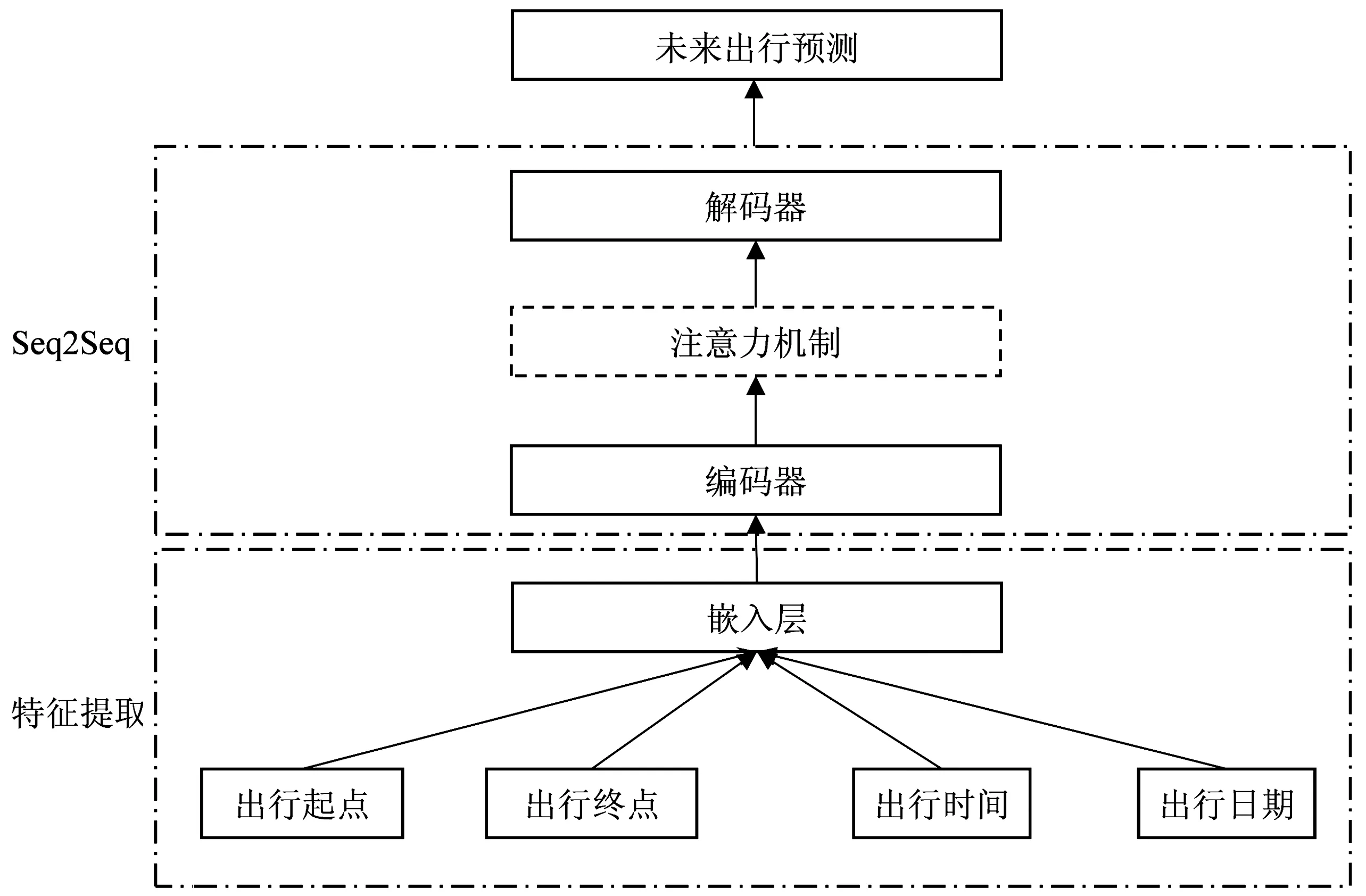
图2 模型架构
1 模型介绍
1.1 个体出行多步预测的问题描述
对个体的多步预测即使用个体过去一段时间的历史出行数据,对其未来一段时间内的出行进行预测。为了定义个体出行多步预测的任务,笔者首先引入两个定义。
1)出行元组(trip tuple)。通过一个元组来描述一次出行:
Q=(o,d,t,w)
(1)
式中:o,d,t,w分别为一次出行的出行起点、出行终点、出行时间和出行日期(星期几)。由于出站时间主要由较为复杂的地铁系统来决定,受到较多非出行因素的干扰,如地铁客流等,因此笔者没有考虑出站时间。
2)出行序列(trip sequence)。单个个体的出行序列为可以用一个有向序列来表示。根据出行元组的定义,可以进一步定义出行序列为:
Sm=(Q1,Q2,…,Qm)
(2)
基于以上两个定义,对个体出行的多步预测问题进行数学描述。对于给定的出行序列Sm和已知最后一次的出行信息(om,dm),对个体出行进行多步预测的任务可以转化成对映射F建模以实现输入这些信息到输出最后k次出行的目的站点的预测,其数学定义为:
dm+1,dm+2, …, …,dm+k=F(Sm-1;om,dm)
(3)
1.2 嵌入层
由于用于表示出行的4个属性具有离散的特性,难以直接作为神经网络模型的输入,因此笔者引入词嵌入(word embedding)的方法对出行属性进行处理[9]。词嵌入方法可以把一个维数为所有词的高维空间嵌入到一个低维连续空间中,每个单词或词组被映射为一个向量,目前该方法在NLP领域已广泛使用。
通过搭建嵌入层(embedding)实现个体出行数据的向量转换,把个体出行属性转换为包含更多出行特征信息的低维稠密向量,使得模型更容易学到个体出行规律,该嵌入层的输入为用于表示出行的4种属性数据,输出为各属性的映射向量。
1.3 Seq2Seq模型
循环神经网络(recurrent neural network, RNN)是一种具有循环性和内部存储单元的神经网络,因此常被用于处理序列数据,其中长短期记忆网络(long short-term memory, LSTM)[10]和门控循环单元(gated recurrent neural network, GRU)是广泛使用的两种循环神经网络。LSTM包含一个单元状态和3个控制门以保持和更新单元状态。GRU是LSTM的一种变体,它将忘记门和输入门合并成一个单一的更新门,因此GRU只包含重置门和更新门两个门。同时还混合了细胞状态和隐藏状态,加诸其他一些改动,使得最终的模型比标准的 LSTM 模型要简单,是当下非常流行的变体。GRU模型如图3。
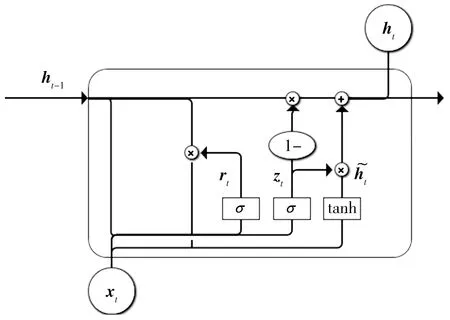
图3 GRU原理
zt=σ(Wz[ht-1,xt])
(4)
rt=σ(Wr[ht-1,xt])
(5)
(6)
(7)
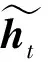
基于Seq2Seq模型对个体出行进行多步预测,Seq2Seq模型由解码器和编码器两部分构成,而编码器和解码器通常通过RNN结构实现。首先将输入序列输入到编码器,编码器对输入序列进行编码,其最后一个隐状态即为上下文向量。然后解码器将上下文向量进行解码,生成目标序列。
笔者将经过特征提取和特征融合的个体历史出行特征数据作为输入序列,经过Seq2Seq模型得到下次出行中各个站点的出现概率,选择概率最大的站点作为下一次的出行预测,然后将该次预测结果重新嵌入、编码和解码,并对该过程进行迭代,以此来生成个体的多步出行预测结果。
1.4 注意力机制
由于Seq2Seq模型具有无法包含输入序列的所有信息,从而限制了解码器的解码能力,因此笔者引入了注意力机制。引入注意力机制是为了计算查询向量与候选向量之间的相似度,得到候选向量的权重系数,以生成上下文向量。该过程可以认为是计算历史出行与当前出行的相关程度,越相关的出行越可能为该模型准确预测下次出行提供有效信息。注意力机制被参数化为可以与整个神经网络一起训练的前馈神经网络。注意力机制的计算公式为:
ct=∑αisi
(8)
αi=softmax[f(ht,si)]
(9)
f(ht,s)=tanh(ht,Ws)
(10)
式中:s为历史特征;Ws为tanh的可学习参数;f为score函数;ct为当前状态下的上下文向量;αi为中间问题。
1.5 带注意力机制的Seq2Seq多步预测模型
在设计多步预测方法之前,首先介绍带注意力机制的Seq2Seq单步预测模型,该模型首先根据个体出行数据对出行特征进行提取和融合,通过编码器将历史出行数据进行编码,得到编码器的输出向量和隐状态向量;然后通过解码器对最近一次的出行数据进行嵌入并编码,将解码器输出的隐状态向量作为查询向量,通过注意力机制计算查询向量与编码器输出的隐状态向量的注意力权重,以此来计算上下文向量;上下文向量可以表示当前向量与历史向量的相关出行信息,通过上下文向量即可预测个体下一次出行的站点,计算过程如表1。

表1 带注意力机制的Seq2Seq预测模型
多步预测场景与单步预测场景有很大不同,主要在于如何设计多步预测的建模策略。在多步预测过程中,第t+k步的预测准确性直接影响了第t+k+1及之后时间窗的预测准确性,因此多步预测任务不可避免地会产生多步误差,我们需要针对多步预测场景设计不同的建模策略以减少多步误差带来的影响。也就是说,对于单步预测,基于上述模型即可直接进行预测,而多步预测则需要考虑如何使多步预测误差最小。因此,笔者针对地铁系统AFC数据的个体出行多步预测的场景,设计了3种多步预测模型。
1)整体输出式多步预测模型。该方法即在单步预测的基础上,重复编码解码过程,直至预测出所有时间步的出行,直接输出对个体未来一段时间出行行为的预测,从而实现个体出行的多步预测。
2)步进输出式多步预测模型。该方法在单步预测的基础上,将未来一次出行的预测结果与历史出行数据拼接起来,滑动时间窗对模型的输入进行更新,从而实现对个体出行行为进行持续的步进式输出,最终实现个体出行的多步预测。
3)多模型组合的多步预测模型。该方法即训练出多个单步预测模型,使其能够对未来不同时间步的出行进行预测,然后将多个模型的输出结果拼接起来获得个体出行的多步预测结果。
2 案例分析
2.1 数据处理
由于地铁系统刷卡数据记录了每次出行的进站和出站及出行属性,与出行直接相关,因此笔者选择了广州地铁羊城通的刷卡数据作为案例进行分析。该数据集的时间跨度为2017年3月1日—2017年5月31日,该地铁系统包含9条地铁线路和157个地铁站。
基于深度学习的多步预测算法需要足够的历史出行记录,因此仅关注在研究的时间段内至少出行90次(即3个月内至少平均每天出行一次)的乘客。在清理完原始数据之后,随机选择20 000名乘客,并使用他们的交易记录构建数据集。笔者使用进站站点o,出站站点d,进站时间t和星期几w作为出行属性来构造每次出行的出行元组。其中,o,t和w是可以通过进站记录获得,因此为进站属性,d为出站属性。其中o∈[0,90],d∈[0,90],w∈[0,6]表示为分类变量。每个乘客的前80%序列样本都用作训练集,其余20%是测试集。
使用宽度为n的滑动窗口从每个个体的整个行程序列中生成行程序列样本作为模型输入。令Tr表示研究时间范围内个体r的整个行程序列。出行序列样本Ssample则可表示为:
Ssample=[Qp,Qp+1,…,Qp+n-1] (1≤p≤N-n+1)
(11)
因此,具有N次出行记录的个体可以提供N-n+1 个出行序列样本。为了使模型覆盖到数据集中的绝大多数乘客,将宽度n设置为70,覆盖了95.2%的个体。我们从整个数据集中获得了1 386 872个样本序列。
2.2 实验及实验配置
2.2.1 评价指标
平均相对误差[11](MRE)是平均绝对误差与真值的比值,常用百分数来表示,可以用来反映预测值与真值的偏离程度,是交通预测中常用的评价指标之一,因此笔者采用MRE来评估各模型的预测性能。在MRE的计算中,使用编辑距离(levenshtein distance)来测量预测位置序列与目标位置序列之间的误差。编辑距离在自然语言处理中有着广泛的应用,是指由一个转换成另一个所需的最少编辑操作次数。MRE的公式定义为:
(12)
式中:v为序列数;E(Mu,Ru)为第u个预测序列与其对应的目标序列的编辑距离;L(Mu,Ru)为第u个预测序列与其对应的目标序列的长度。分母将误差归一化,使MRE值处于[0,1]之间。
此外,准确率[11]已广泛应用于评估分类任务的模型性能,准确率Acc的公式如下,其中为Pu序列中正确预测位置的个数。
(13)
2.2.2 对比实验设置及实验参数设置
构建了基于带注意力机制的Seq2Seq模型的3种深度学习实验模型进行多步预测,其中包括整体输出式多步预测模型、步进输出式多步预测模型、多模型组合的多步预测模型, 并构建了两种传统模型作为基准模型。所有实验均在windows服务器上进行,该服务器配置为Intel©Xeon©CPU E5-2696 v4 2.20GHz,GPU的配置为NVIDIA GeForce RTX 2080 Ti。
另外,为了验证模型的预测效果,将基于带注意力机制的Seq2Seq模型的3种多步预测模型与以下基准模型进行比较。
1)MC:马尔可夫模型是一种传统的统计学方法,是一种根据上一时刻状态对下一时刻状态进行预测的方法。
2)SVC:支持向量分类器是支持向量机模型的一种变体方法,其本质是对距离进行度量,经常用于时间序列预测。
3)Seq2Seq模型:序列到序列模型是近年来NLP领域的一种常见模型,主要用于序列的预测问题。
多步预测模型的参数设置如表2。
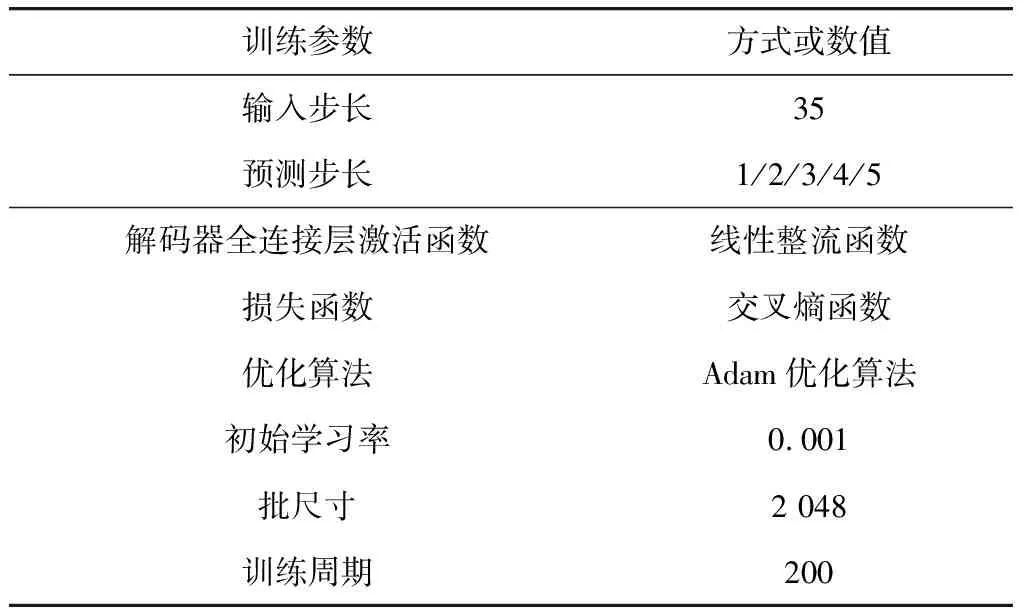
表2 实验参数
2.3 实验结果分析
首先设定输入步长为35,输出步长为5,选择马尔可夫模型、支持向量分类器模型和没有注意力机制的Seq2Seq模型作为对照实验,观察不同多步预测模型的预测效果,实验结果如表3。
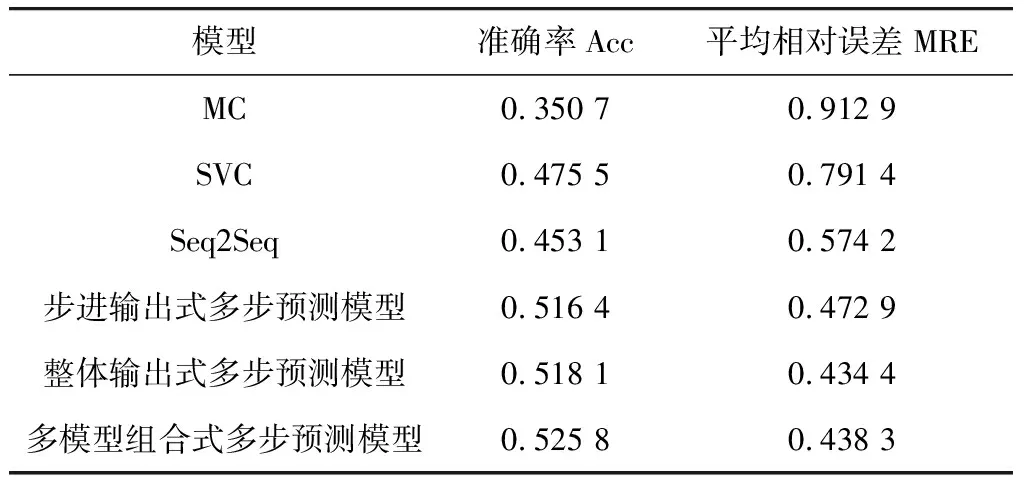
表3 实验结果对比
通过表3可以得出以下结论:①在基于AFC数据的地铁系统个体出行多步预测的场景下,Seq2Seq深度学习模型能够获得相比于传统的机器学习模型更高的预测准确率和更低的预测误差,这是由于深度学习模型能够从个体出行的历史序列中提取到更多复杂的出行信息,从而提高模型的学习能力;②引入注意力机制的多步预测模型可以获得相比于没有注意力机制的Seq2Seq模型更高的预测准确率和更低的预测误差,这是由于注意力机制可以提高解码器的解码能力,加快模型的迭代,能够为预测提供更多的有效信息;③针对研究场景,设计的3种多步预测模型中,多模型组合式多步预测模型相比于步进输出式多步预测模型和整体输出式多步预测模型可以获得更高的准确率和更低的误差,这是由于在个体出行的场景下,分别基于个体的历史出行序列对未来某次的出行进行模型训练,然后将预测结果结合起来,更能提取到个体历史出行对该次出行产生影响的特征,从而获得更高的预测精度;而步进输出式多步预测模型预测精度最低,是由于该模型直接将单步预测结果与历史出行数据结合起来,然后滑动时间窗作为下一次单步预测的输入,没有在模型训练阶段引入多步预测机制,无法减少多步误差对模型的干扰;整体输出式多步预测模型预测精度居中,是由于该模型虽然在训练过程中引入了多步预测的机制,将单步预测结果进行重新编码并嵌入,模型可以在一定程度上学习多步预测的规律,但该模型并不能针对未来特定步长的规律进行学习,对未来固定步长出行预测规律的提取存在一定局限性。
为了进一步探究预测步长给实验结果带来的影响,针对多模型组合式多步预测模型,在固定输入步长的基础上,改变输出步长设置了5个对比试验。实验将输入步长设置为35,输出步长分别设置为1、2、3、4、5进行探究。实验结果如表4,其中ΔAcc为准确率变化量,ΔMRE为MRE变化量,R1、R2分别为准确量变化率、MRE变化率。
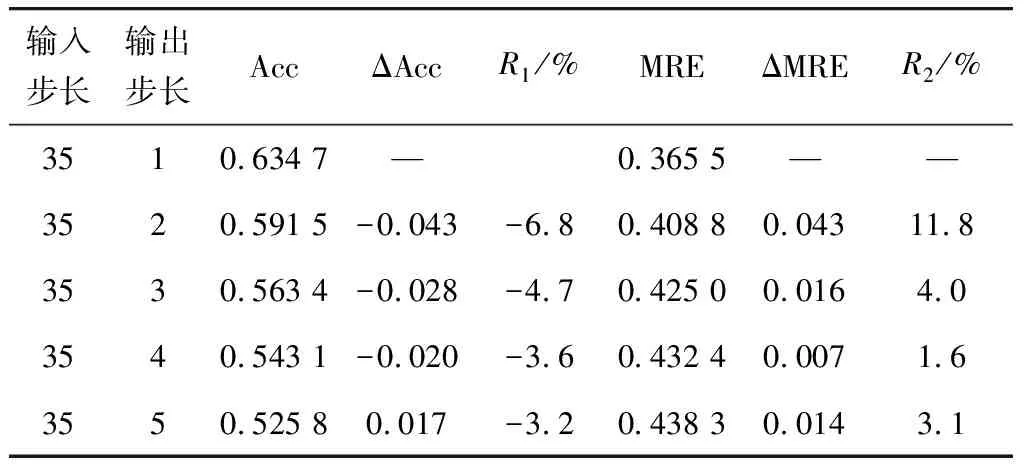
表4 改变输出步长的结果对比
通过表4可以看出:①在固定输入步长的情况下,随着预测步长的增长,预测准确率降低,MRE升高,这是由于在输入步长一定的情况下,提取到的有效特征不能维持无限长的多步预测;②准确率的变化量随着输出步长的增加不断均趋向于0,可以看出当模型的输入步长一定时,模型不会随着预测步长的增加而导致性能大幅降低,鲁棒性较强。
3 结 论
随着智能交通的发展,交通出行不断向着个性化、智能化的方向发展,个体出行的多步预测研究对于交通出行的发展具有重要意义。
使用广州地铁羊城通的刷卡数据,通过建立包含注意力机制的序列到序列模型对个体出行的多步预测进行了研究和实验。首先对个体出行特征进行了提取和融合,然后基于包含注意力机制的序列到序列模型设计了3种多步预测模型,并与传统出行预测模型进行对比,进一步地,通过改变预测步长,探究了不同预测步长对实验结果带来的影响。得出以下结论:
1)注意力机制可以提高解码器的解码能力,加快模型的迭代,能够为预测提供更多的有效信息,因此包含注意力机制的序列到序列模型能够比传统模型(如马尔可夫模型、支持向量分类器模型)更适用于多步预测的场景。
2)包含注意力机制序列到序列模型更适合对长序列的处理,能够从长序列中提取到更多的有效信息,从而获得更好的预测结果。
3)在基于AFC数据的地铁系统个体出行多步预测的场景下,多模型组合的多步预测方法更能提取到个体历史出行对该次出行产生影响的特征,能够获得更好的预测结果;当模型的输入步长一定时,模型不会随着预测步长的增加而导致性能大幅降低,具有较强的鲁棒性。
综上,笔者证实了包含注意力机制的序列到序列模型在个体出行多步预测中的实用性和优越性,并进一步对多步预测模型进行了设计和探究,最后说明了输出步长对多步预测结果的影响。
