基于注意力融合的遥感滑坡目标识别
2022-11-02王煜张鹏孙恺悦孙学宏刘丽萍
王煜,张鹏,孙恺悦,孙学宏,刘丽萍*
(1.宁夏大学 物理与电子电气工程学院,宁夏 银川 750021;2.宁夏大学 信息工程学院,宁夏 银川 750021)
1 引言
随着遥感技术的发展,实现遥感滑坡区域的自动识别,对滑坡体监测、地质灾害预防具有重要现实意义[1-2]。滑坡识别作为其他研究工作的基础,主要分为人工目视解译、计算机识别两类[3-4]。人工目视解译依据遥感影像色彩、纹理等几何特征,与专家知识、非遥感数据相结合,识别准确度较高[5-6],但存在专家知识依赖性强、遥感信息利用不充分、人工成本高、效率低、定量描述不准确等局限[7]。
近年来,计算机识别方法取得长足进步。机器学习通过提取区域相关特征,使用多层感知机(MLP)[8]、支持向量机(SVM)[9]、人工神经网络(ANN)[10]等分类器进行遥感目标识别,自动化程度较高,但模型依赖手工设计,处理效率较低[11]。深度学习算法依托卷积神经网络(CNN)及大量训练样本,不用人工构建特征图,大幅提高了识别效率和精度[12]。深度学习的滑坡识别模型多聚焦于CNN[13-14],如赵福军等[15]提出的多尺度分割DCNN模型,利用全连接结构提高模型泛化能力,滑坡目标提取总体精度达到87.68%,显著优于传统机器学习方法。简小婷等[6]基于Faster R-CNN和高分1号卫星影像,实现了强特征滑坡目标的高识别率,但对形态残缺的滑坡区域提取有限。针对滑坡目标与地物背景容易混淆的问题,姜万冬等[16]提出基于模拟困难样本的Mask R-CNN滑坡提取方法,该方法检测精度达到94.0%,实现了低虚警率下的高性能滑坡分割。针对复杂场景下遥感目标边缘识别不佳的问题,王曦等[17]基于UNET模型框架,引入FPN结构和BLR损失函数,大幅改善了目标边缘识别结果。针对CNN局部感受野导致滑坡与地表背景难以区分的问题,许濒支等[18]通过引入金字塔结构和通道注意力机制,增强了模型的多尺度特征提取和全局感知能力,在滑坡的完整性保持和区分光谱信息混淆方面取得明显提升。此外,编码器-解码器结构在滑坡识别任务上表现优异,张蕴灵等[11]提出多尺度特征融合滑坡分割网络框架,通过稠密连接提取局部特征,利用跳跃连接融合多尺度语义特征。与经典分割方法相比,具有更高的检测精度,能够有效削弱遥感影像背景噪声。
基于卷积神经网络的滑坡识别方法利用多层卷积聚合局部特征,缺乏明确捕获长期(全局)特征间依赖关系的能力[19],对重点滑坡区域关注有限[20]。针对这些问题,本文提出一种基于注意力融合的遥感图像滑坡目标识别方法。首先,在浅层特征中引入通道注意力与空间注意力机制,增强滑坡区域的特征权重。其次,在深层特征层,采用改进自注意力(Self-attention,SA)编解码模块将上下文特征序列化,最大限度获取特征间相关关系。该方法利用CNN的图像归纳偏差有效避免了自注意力的大规模预训练。本文考虑到滑坡样本小的问题,选择扩充后的武汉大学滑坡检测数据集作为研究数据源,选择贵州省毕节市作为研究区,探索本文方法进行滑坡区域识别的可行性。
2 基于注意力融合的遥感滑坡识别
2.1 基于注意力融合的网络结构
基于注意力融合的滑坡识别网络结构如图1所示。该方法遵循编码器-解码器体系结构,使用深度可分离卷积替代普通卷积进行特征提取,使用卷积块注意力(Convolutional block attention,CBA)串联跳跃连接(Skip connection)进行滑坡关注区域提取,使浅层特征提取更具针对性,将自注意力编解码模块应用到模型的深层特征表示,捕获高级语义尺度下的全局依赖关系。

图1 基于注意力融合的滑坡识别网络结构Fig.1 Landslide identification network structure of attention fusion
2.2 改进自注意力机制
自注意力机制由Vaswani等[21]提出,其善于发现数据特征内部的相互关联性,能够捕获长期(全局)依赖关系。输入特征图X∈RC×H×W,其中C、H、W分别为通道维数、空间高度和宽度。首先,利用卷积将X映射到3个不同的特征空间Q、K、V∈Rd×H×W,其中d≤C,表示特征通道的维数。随后将Q、K、V中单一位置的全通道特征数据分别序列化为qi,ki,vi∈R1×d(i∈{1,…,n}),其中n=HW,将Q、K、V特征空间的序列化数据分别拼合为Q′,K′,V′∈Rn×d。自注意力输出fatt是一个可伸缩点积(Scaled dot-product):
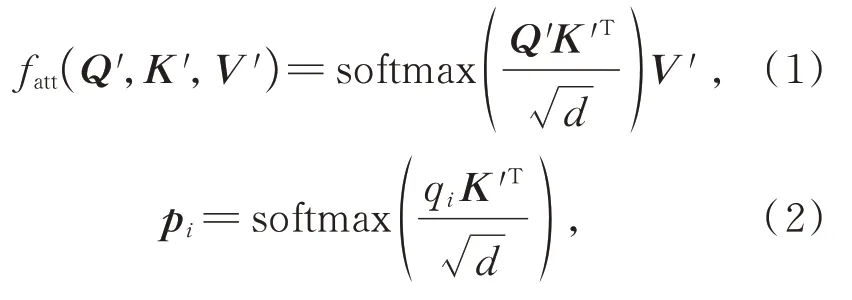
其中,softmax为归一化指数函数。具体来说,第i个查询的上下文映射矩阵pi用来计算qi和每个ki的相关联程度,以此作为权重,从vi中收集上下文信 息,qi、ki、vi分别为Q′、K′、V′的第i行序列数据。
在自注意力机制中,序列长度主导了自注意力计算。文献[22]从理论方面证明了由自注意力机制形成的特征空间矩阵Q、K、V是低秩的,因此我们提出一种改进自注意力机制,即将原序列化数据组合K′、V′线性映射为低秩矩阵K″,V″∈Rs×d,其中s≪n,自注意力输出变换为:

经过改进的自注意力能够缩短原序列化数据K′、V′的序列长度,从而达到减少模型参数,轻量化模型的目标。
2.2.1 改进自注意力编码模块
依照改进自注意力机制设计自注意力编码模块,结构如图2所示。该模块输入语义特征图X∈RC×H×W,生成3个空间矩阵Q、K、V,经过卷积操作得到Q′、K′、V′,再经过线性映射得到低秩矩阵K″、V″,利用Q′对K′进行查询,获取查询结果Q′K″T,将查询结果与随机位置矩阵(Positional Encoding)相加并进行softmax处理得到矩阵V″序列数据间的关联权重,其中随机位置矩阵经过模型训练可以获取序列数据间的位置相关信息,最后将关联权重矩阵与值矩阵V″相乘获取语义特征图的自注意力。该编码模块的本质是将特征图映射为多条序列数据,将与每条序列数据相关的其他序列数据按照相关性强弱进行加权求和,并利用加权结果替代原序列数据得到输出特征图。改进自注意力编码模块能够从通道和空间两方面缩减特征图尺度,减少了计算成本,实现了特征图内部的自注意力机制。
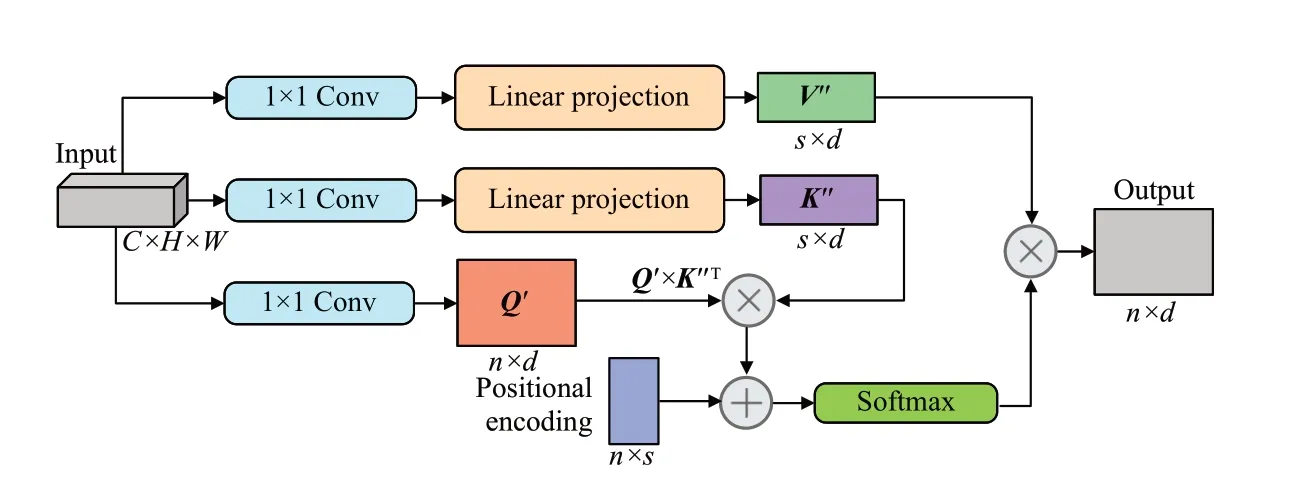
图2 改进自注意力编码模块Fig.2 Improved self-attention encoder module
2.2.2 改进自注意力解码模块
改进自注意力解码模块结构如图3所示,该模块利用低级语义特征X∈RC×H×W生成查询输入Q,利用高级语义特征Y∈RC×h×w生成键、值输入K和V,经过类似编码模块的卷积与线性映射得到Q′、K″、V″,通过查询结果Q′K″T获取两种语义尺度下序列数据间的相关性矩阵,加入位置信息和softmax处理后获取特征X反映在特征Y上的相关性权重,最后将相关性权重与值V″矩阵相乘获得自注意力特征图。该解码模块的本质是获得两种语义尺度间序列数据的相关性,选出与低级语义特征每条序列数据相关的高级语义序列,将这些高级语义序列按照相关性强弱进行加权求和并替换对应的低级语义特征序列,进而获得由高级语义序列线性表示的低级语义特征矩阵,即输出特征图。该解码模块在继承编码模块优势的基础上,能够捕获不同特征图不同空间位置特征的相关关系,实现了特征图间的自注意力机制。

图3 改进自注意力解码模块Fig.3 Improved self-attention decoder module
2.3 卷积块注意力机制
卷积块 注意力 机制由Woo等[20]提 出,分为通道注意力和空间注意力两部分,如图4所示。通道注意力利用特征的通道间关系,获取通道注意力图,进而赋予高相关性通道以高权重。空间注意力则与之互补,其利用特征间的空间关系生成空间注意力图,赋予通道内高相关区域以高权重。

图4 卷积块注意力模块Fig.4 Convolutional block attention module
以特征图X∈RC×H×W作为特征输入,通道注意力图为AC∈RC×1×1,空间注意力图为AS∈R1×H×W。卷积块注意力过程可以概括为

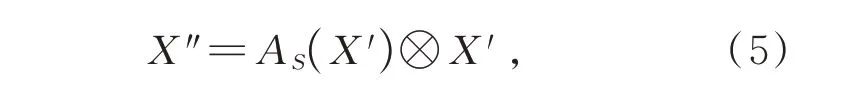
其中⊗表示逐元素乘法。在运算过程中,通道注意力值沿着空间维度进行传播,空间注意力值则沿着通道维度进行传播。
2.4 遥感图像滑坡识别方法
遥感图像滑坡识别方法包括3个阶段:数据准备阶段,在空间尺度上对遥感滑坡数据集进行扩充,保证数据的一致性和真实性;训练阶段,设置参数训练模型,直到损失收敛,最终得到模型的权重文件;验证阶段,输入待检测图片,加载已训练的模型权重,通过特征提取得到5种尺寸的特征图,尺寸分别为28×28、56×56、128×128、256×256、512×512,利用编解码得到预测滑坡区域,与真实滑坡区域进行比较,统计语义分割相关指标。
3 实验结果与分析
3.1 数据集
本次实验使用的遥感数据集来自Ji等[23]制作的贵州省毕节市滑坡数据集。该数据集是包含滑坡光学影像及对应数字高程的公开滑坡数据集。滑坡数据集中正样本数量为770,负样本数量为2003,其中光学影像分辨率为0.8 m,数字高程数据分辨率为2 m。本文选取770正样本与1000负样本进行扩充,扩充后正负样本比例基本持平,总样本数达到6083,具体类别如表1所示。
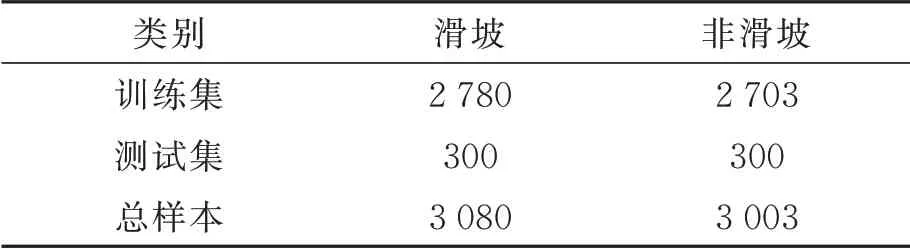
表1 数据集类别Tab.1 Dataset category
3.2 评价指标
对于滑坡识别效果的评价,通常选用平均像素精度(mean Pixel Accuracy,mPA)和平均交并比(mean Intersection over Union,mIoU)衡量样本分割结果;模型大小(Model size)、参数量(Parameter)和模型计算量(Giga Floating Point Operations,GFLOPs)用来衡量模型量级,模型越小,参数量越少,计算量越少,模型越轻量化,复杂度越低。本文针对两种类别的遥感图像数据集进行目标分割任务,选取mPA、mIoU、精准率(Precision)、召回率(Recall)、F1指数、参数量、模型大小和计算量作为模型的评价指标。

其中,TP为真正样本;TN为真负样本;FP为假正样本;TN为假负样本;CPA表示样本的类别像素精度,CPAP表示滑坡类像素精度,CPAN表示背景类像素精度;IoU表示样本的类别交并比,IoUP表示滑坡类交并比,IoUN表示背景类交并比。
3.3 实验结果与分析
3.3.1 实验环境
本文实验配置如下:操作系统为64位的Ubuntu系统,处理器为Intel Xeon Gold 6240,显卡为NVIDIA RTX TITAN,内存为128 GB。深度学习框架为PyTorch1.9.0,其他的主要辅助软件包括Anaconda4.9.2和Python3.9.7。
实验输入图像尺寸为512×512,epoch设置为100,学习率设置为0.0001。图5为模型训练Loss损失曲线图,可以看出在约65 epochs时,模型开始逐渐收敛,最终稳定在0.0048左右。
图5 模型训练loss变化曲线Fig.5 Loss curve during model training
3.3.2 实验分析
实验数据集大约按照9∶1划分训练集和测试集。本次实验测试一共为600张图片,其中包含300个滑坡正样本,300个滑坡负样本,模型的滑坡分割识别结果如图6所示。从图6可以看出,本文模型能够精确提取滑坡位置,但存在滑坡边界模糊的情况。造成的原因可能是由于植被区域光学影像与高程数据的光谱信息存在一致性,使模型无法分辨出精确的滑坡边界。

图6 滑坡分割结果Fig.6 Landslide detection and segmentation
为验证本文算法的有效性,使用本文遥感图像数据集进行对比实验,对比了本文算法与U-net[24]、DeeplabV3+[25]和FCN[26]算 法 在 遥 感图 像 测 试数据集上的各项分割指标,如表2所示。
通过对比各项分割指标可以发现,本文算法与U-net、DeeplabV3+相比,各项分割性能均有所提升,但相较FCN算法,本文算法略有不足,通过分析发现可能原因有两方面:一方面相比于本文的改进自注意力机制,FCN模型的全连接层对于全局特征提取更为彻底,因而像素的分类精度更高;另一方面,FCN采用跳跃结构(Skip architecture),即融合多个尺度特征图生成最终分割结果。相比于本文算法单一尺度下的特征拼接,这种多尺度特征图融合方式细节信息损失更少,整体信息获取维度更多,因而能够帮助FCN提升细节和整体两方面的性能。同时,上述原因也反映出FCN的模型量级可能远大于本文模型。因此,本文针对参数量、模型大小和计算量方面进行对比实验,结果如表3所示。虽然本文算法在计算量方面逊色于DeeplabV3+,但参数量和模型大小均有大幅削减,本文算法的模型大小和参数量仅是FCN的8.0%。

表3 模型复杂度对比Tab.3 Model complexity comparison
结合表2、3中的各项分割指标、参数量、模型大小、计算量的对比结果可得,本文算法的综合分割性能要优于U-net与DeeplabV3+。与FCN算法相比,本文算法虽在分割精度方面还有待提高,但模型大小与模型计算量方面均有大幅削减。

表2 分割结果对比Tab.2 Comparison of segmentation results
为了验证改进自注意力模块和卷积注意力模块的有效性,进行消融实验,如表4所示。添加改进自注意力机制后,平均像素识别精度提升明显,相比U-net提升了3.86%。改进自注意力处理前后的特征图如图7所示,可以看出经过改进自注意力模块后,滑坡与背景区域差异得到明显增强。

图7 改进自注意力处理前后对比图Fig.7 Comparison images before and after improved selfattentional processing
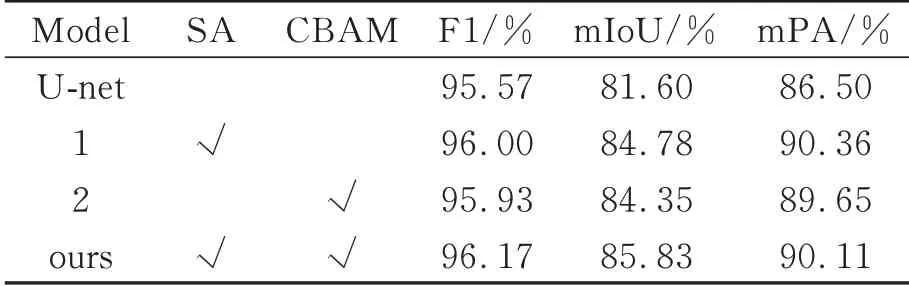
表4 不同改进策略性能评估Tab.4 Performance evaluation of different improvement strategies
在编码器-解码器框架上添加卷积块注意力之后,虽然F1指数提升较小,但mIoU和mPA均有较大提升,分别提升了2.75%和3.15%。图8(a)和图8(b)分别表示卷积块注意力处理前后各个通道的特征图,通过对比可以发现,经过卷积块注意力之后,特征图中滑坡与背景区域差异得到增强。图8(c)显示卷积块注意力中通道注意力的权重,可以看出区域差异明显的通道被赋予高权重,符合通道注意力的特点。图8(d)显示卷积块注意力中空间注意力的权重,滑坡与背景区域分别被赋予不同权重,明显增强了滑坡边缘区域。

图8 卷积块注意力处理前后对比图Fig.8 Comparison images before and after convolutional block attention processing
本文提出的滑坡分割模型融合了改进自注意力与卷积块注意力的优势,综合分割性能方面优于单一注意力模型,与U-net模型相比,mIoU与mPA分别提升了4.23%与3.61%。在实际工程应用中,滑坡分割模型作为辅助手段,通常搭配区域形变、降水、地形地貌等特征对滑坡区域进行综合识别,因而普遍认为模型识别精度达到80%以上已经能够满足实际工程需要[11,15-16,27]。本文模型识别精度为96.81%,能够有效区分滑坡区域。同时,随着深度学习技术发展,滑坡识别模型日趋小型化与轻量化,本文模型在保证同量级滑坡识别精度的基础上,大幅削减模型规模,有效减少了模型的训练成本。
4 结论
本文提出了基于注意力融合的遥感滑坡目标识别方法。首先,针对滑坡正负样本不均衡的问题,对滑坡数据集进行数据增强;其次,在浅层特征提取中引入卷积块注意力机制,增强模型对局部特征的关注程度,赋予局部特征不同权重,突出滑坡与背景区域的差异性;最后,在高级语义层引入改进自注意力机制,增强了全局尺度下区域特征间相关关系,进一步提升模型识别精度。实验结果表明,本文方法的滑坡识别准确率达到96.81%,像素分割平均准确率达到了90.11%,与DeeplabV3+、U-net方法相比在mIoU、mPA方面均有提升,证明了注意力融合方法在滑坡识别方面的有效性。
