一种基于K-means 的雷达机动目标检测算法
2022-10-31程书慧陈凌珊杨军典
程书慧,陈凌珊,杨军典
(1.201620 上海市 上海工程技术大学 机械与汽车工程学院;2.213002 江苏省 常州市 德心智能科技(常州)有限公司)
0 引言
无人驾驶实现原理分为感知层、控制层和决策层,感知层为控制、决策规划层提供可靠基础数据。毫米波雷达具有抗干扰能力强、穿透性好、分辨率高、全天候工作等优点成为汽车高级辅助驾驶功能传感器首选[1]。毫米波雷达通过发射机发射特定频率信号,经过目标物反射,接收机接收信号。将发射信号与接收到的信号进行混频,得到中频信号。中频信号经过模数转换器数字采样后进行信号处理,包括一维(距离)快速傅里叶变换得到距离信息、二维(速度)快速傅里叶变换得到速度信息、动目标指示滤波器抑制杂波、恒虚警率(CFAR)过滤信号,得到有效目标点进行角度估计,得到目标的方位信息。将有效检测点进行聚类,完成目标检测后进行分类、追踪等数据处理[2]。雷达工作流程如图1 所示。
对于雷达机动目标检测,CFAR 检测算法是通过对速度FFT 后的信号处理,对检测单元进行噪声处理,再统计样本,设置阈值,剔除小于阈值的被测单元,提高了多目标等杂波较多场景下的检测性能[3]。而CAFR 目标检测缺少了后续的聚类步骤,不能够有效地将检测到的机动目标与反射的检测点融合,因而不便于后续的数据处理。基于密度的聚类算法(DBSCAN)是通过检测点密度间的关系,找到满足设置扫描半径与最小包含点数对数据样本迭代循环[4]。而DBSCAN 算法对样本质量要求较高,一般适用于密度较大的数据集,而毫米波雷达采集的是稀疏点云数据,其密度较小,使用DBSCAN算法聚类效果不佳。基于传统的K-means 算法机动目标的检测,通过样本间的距离作为目标函数进行迭代优化检测目标[5]。由于雷达对采集的虚假信号处理后,雷达有效点云数量较少,且K-means聚类为无监督学习,无法保证K 值的准确性,且聚类结果对K 值及初始化中心较为敏感,使用传统的K-means 聚类检测效果会很差[6]。
本文提出了一种改进的K-means 算法来实现雷达机动目标的检测。建立缓存区、速度预聚类及关联门,用于解决传统K-means 对雷达数据聚类中存在的问题。改进K-means 流程如图1 所示。
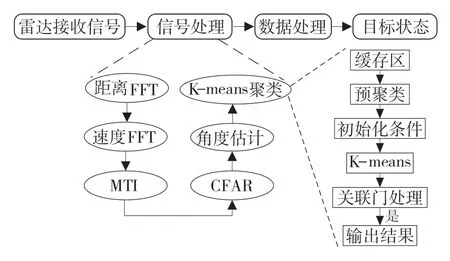
图1 雷达工作流程图Fig.1 Radar work flow chart
1 传统的K-means 聚类
K-means 将雷达接收到的稀疏数据聚类为不同的簇进行目标检测,聚类结果取决于参数K 值和初始化中心的选取。K 表示最终所聚类得到的类别,不同初始化聚类中心点和K 值会得到不同结果。每一轮迭代重新计算质心位置,直至质心不再变化。
假设输入已预处理的样本集 X={x1,x2,…,xn},输出类别 C={c1,c2,…,cm}。步骤:(1)随机指定m 个点作为初始化聚类中心μ0,μ1,…,μm;其次,计算各个样本点距聚类中心的距离样本距离dij最小,则该样本属于j 簇;(2)更新各簇的质心位置(Cj——j 簇中样本数;dj——j 簇中每个样本距离聚类中心的距离);(3)判断是否达到最大迭代次数T 或聚类中心不再发生改变,若否重复步骤2、步骤3;(4)输出集合C 中各个簇[7]。
传统K-means 聚类为无监督学习,而每个检测场景中毫米波雷达检测的目标数量是一定的。若K 值不准确,则聚类结果是错误的。传统的K-means通过肘部原则来确定K 值,将检测点与各簇的聚类中心的平方差和定义为畸变函数,如式(1)所示。该函数值会随着K 值的增大而降低,达到某个K值后,收敛速度放慢,该K 值则为K-means 中最佳初始化K 值[8]。

传统K-means 聚类算法的复杂度为O(nmT),n 为样本集的个数,m 为类别数,T 为最大迭代次数。若已知初始化中心和K 值,则不再进行最大次数与肘部原则选取K 值的迭代,此时复杂度为O(1),且正确的K 值将得到准确的检测结果。
2 改进的K-means 聚类
本文使用nuScenes 提供的开源数据由大陆ASR408 毫米波雷达采集,采样频率为13 Hz,视场角FOV=120°。采集的每一帧数据包括18 个目标物的属性信息,125 个有效目标检测点。雷达坐标系如图2 所示,X 轴为汽车前进方向,Y 为汽车侧向,Z 轴为汽车垂直方向,FOV 为视场角。毫米波雷达部分采集数据见表1,每个检测点属性具有序号、坐标位置(x,y)、雷达散射截面积RCS、目标的速度vx和vy。
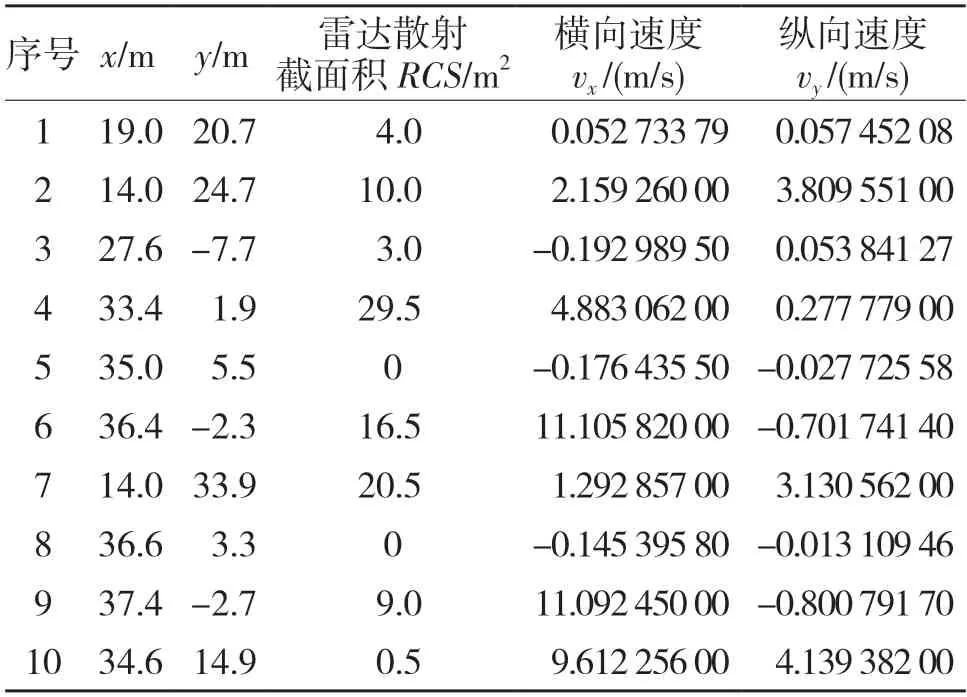
表1 毫米波雷达预处理数据Tab.1 Some data attributes of radar detection points
图2 车载毫米波雷达坐标系Fig.2 Coordinate system of vehicular millimeter wave radar
驾驶过程中通常只关心机动目标,可能对行车安全造成危险,需要知道机动目标的位置和速度等属性信息,便于控制汽车保证行车安全[9]。雷达接收到的反射波经过与发射波的混频等处理得到物体的状态信息。通过对目标点速度属性设置阈值,将静态目标过滤,得到有效的动目标点进行聚类。由于多普勒特性和雷达性能影响,存在部分静态目标带有微小速度噪声[10],本文设置的阈值为0.3 m/s。
2.1 缓存区的建立
车载毫米波雷达为77 GHz 发射信号频率高波长短,且雷达的回波信号往往是不稳定的,由于多路径效应和遮挡等环境因素,会大幅降低毫米波能量,且信号处理会过滤不可靠数据,造成雷达采集点云为稀疏数据。雷达每帧数据仅有125 个检测点,过滤静态目标后点的数量将减少,而K-means 聚类结果较为依赖样本数据数量与质量,在复杂的交通环境中数据样本较少,聚类得到的结果将不具备参考意义。如图3 所示,将雷达某一帧检测点映射到图像坐标系中,不同的颜色代表不同距离的检测点,可知每个目标上的检测点较少。

图3 将雷达检测点映射到图像空间Fig.3 Map radar detection points to image space
基于数据样本较少与质量较差的问题,提出缓存区以改进K-means 聚类算法。将当前帧与前4帧的检测点经运动补偿后缓存,对5 帧数据进行聚类。已知连续5 帧得到625 个样本点一同进行处理,过滤静态点,增加样本数量。雷达每一帧的采集间隔为77 ms,缓存5 帧的时间为0.3 s,该时间段内车辆自身运动需对前4 帧的检测结果进行运动补偿。假设物体在该0.3 s 内为匀速运动,对前4 帧的数据进行运动补偿,并对缓存区数据进行更新,每更新一帧,更新聚类结果达到实时性要求,此时可忽略运动方向改变所引起的误差,使用速度与时间差进行距离上的补偿。将缓存区数据按照式(2)进行运动补偿,结果如图4 所示。
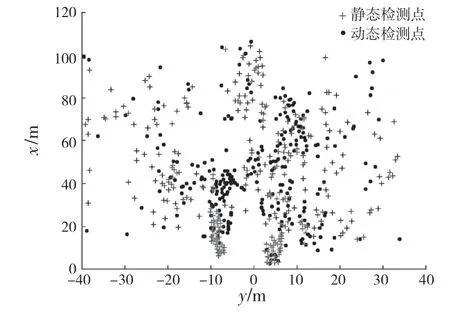
图4 缓存区建立后动态与静态检测点Fig.4 Dynamic and static detection points after the cache area is established

式中:t——每一帧数据间的时间差,t=77 ms;Δvij——第i 帧中第j 个目标与主车的相对速度;Δdij——目标所需要的补偿的距离。
2.2 预聚类处理
对检测点速度进行过滤筛选,由于同一个目标上对应的检测点应具有相同的速度,可得到物体个数确定K-means 所需K 值,并将预聚类得到的质心作为K-means 聚类的初始化中心,将在一定范围的点速度差值小于设定的阈值则认为是一个簇。本文设置在5 m 范围内速度相差±0.1 m/s 的检测点,将被认为同一个类的点即同一个目标,对所有动检测点遍历,K 值依次累加,此场景下的动目标个数为10。如图5 所示,利用肘部原则选取K 的最佳值应取3,通过速度预聚类K 取为10,预聚类得到的K 值较为接近真实情况。
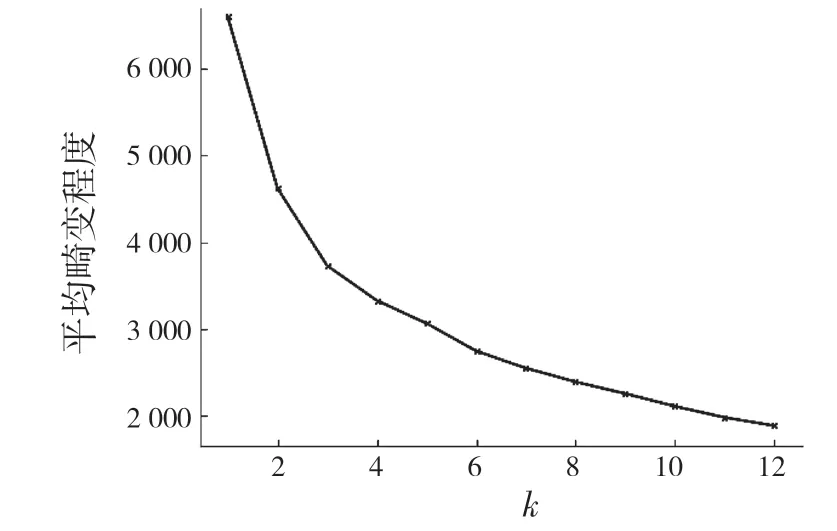
图5 肘部原则来确定初始K 值Fig.5 Elbow principle to determine initial K value
2.3 关联门的建立
关联门的大小取决于目标尺寸,通常基于速度大小判断认为,机动性大的目标(即速度较大的目标)尺寸较小;基于缓存区内点密度判断目标的大小,认为检测点密度较大,目标反射电磁波较多的目标尺寸较大。采用位置-速度关联,先进行位置关联,若位置关联成功则进行速度关联。所采用关联门方程如式(3)所示:
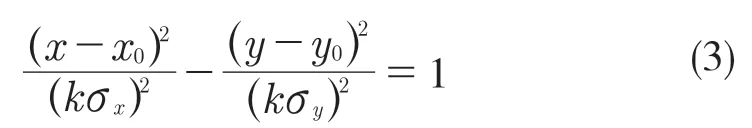
式中:x0,y0——椭圆中心;kσx,kσy——椭圆的2个半轴。
当σx=σy时,方程为圆的一般方程式即关联门为圆形。将检测点坐标代入方程中,x0,y0为椭圆中心,x,y 为待关联检测点,kσx,kσy为设定关联门大小。当满足方程左侧值≤1,则关联成功;当方程左侧值>1,则关联失败。
一次关联门使用较大的圆形关联门进行粗过滤。由于目标形状多为长方形,在进行二次关联门时使用椭圆形关联门,而当主车速度大于10 m/s时,主车机动性较强,造成缓存区建立时运动补偿误差累积,此时使用圆形关联门。
一次关联门利用圆形关联门过滤已知不属于目标的检测点,利用传统K-means 聚类中聚类中心的确定方法,对关联门内的检测点重新计算聚类中心,作为二次关联门的中心。二次关联门是由于毫米波雷达对金属反射的敏感性,易产生一些虚假检测点“鬼影”,缓存区的建立增加有效目标检测点的同时会增多虚假检测点。本文算法利用关联门以聚类中心为关联门中心,将一些虚假检测点过滤,使目标分离出来。
2.4 算法描述
改进后的K-means 算法流程图如图6 所示,其实现步骤为:
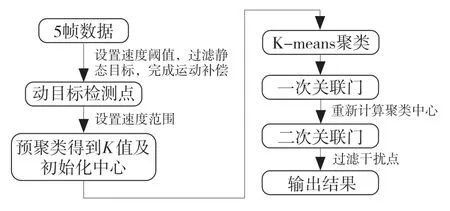
图6 算法流程图Fig.6 Algorithm flow chart
(1)完成缓存区的建立。将5 帧数据缓存到一起,经运动补偿后进行静态与动态检测点的过滤;
(2)速度预聚类。确定预聚类的位置范围值与速度差的值,经预聚类后得到K-means 聚类的初始化K 值,并在K 类中随机指定每个类内的检测点作为初始化聚类中心;
(3)K-means 聚类。给定K 值与初始化聚类中心的K-means 聚类,不再对K 值与初始化中心的选取进行循环迭代;
(4)一次关联门处理。对聚类得到的簇以步骤(3)的聚类中心作为关联门中心,使用圆形关联门,并重新计算关联门内的检测点,以确定类内中心;
(5)二次关联门处理。以步骤4 中得到的中心点作为关联门的中心点进行关联门处理,最终在检测点中区分各个目标。
3 实验结果与分析
实验使用设备为笔记本电脑i7-5600,显卡为GTX970M,PyCharm 软件,Python3.7.3 与PyTorch深度学习网络框架。由于毫米波雷达采集数据为点云,检测结果不能直观判断目标检测的准确性。利用nuScenes 提供的场景标注作对比,如图7 所示,主车雷达位于图中×位置,方框为所标注的目标,带有短线段的点表示毫米波雷达所采集的检测点,线段表示检测点的速度。利用图像检测算法YOLOv5 的检测结果与本文算法作为对比,图像检测算法结果如图8 所示。

图7 数据集标注图Fig.7 Data set annotation map

图8 YOLOv5 检测场景图Fig.8 YOLOv5 detection scene diagram
利用Python 实现算法,并将聚类结果在雷达坐标系中显示,图9 为传统K-means 算法检测结果,不同形状的点表示不同的簇。图10 为本文算法检测结果,星状表示一次关联门处理时的聚类中心,圆点表示重新计算后二次关联门的中心。其中,纵坐标x 轴为汽车前进的方向,横坐标y 轴为汽车横向的方向,坐标系的圆点为车载雷达的坐标原点。图9 中,传统K-means 中肘部原则所得K 值错误,且未经过关联门处理将5 帧中干扰点也进行聚类,而且不能确定目标的确定位置。对比图8 与图10可知,在护栏外的车辆及被树木遮挡的车辆,图像算法并未检测出,而毫米波雷达利用电磁波的特性可清晰看到目标存在。

图9 传统K-means 检测结果Fig.9 Traditional K-means detection results
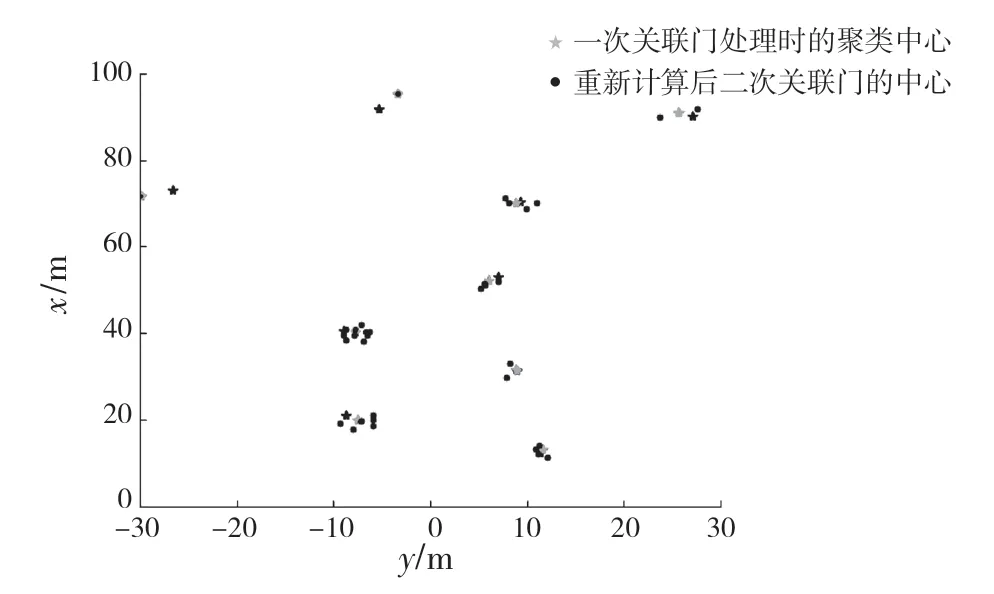
图10 本文算法检测结果Fig.10 Detection results of the algorithm
利用多帧数据进行检测并与场景中的真值标签进行对比,使用外部指标来评价模型在整个场景中的性能表现,对正确检测与错误检测进行统计,如表2 所示。将在相同设备下不同算法的代码运行时间来评判检测速度。经统计计算,文本算法的正确率达到92.04%,在相同的设备情况下相较于传统的K-means 准确率0.889 1 有较大提升,同时由于不再对K 值及初始化中心进行迭代,检测速度提高百分之36%。利用本文提出的算法进行检测,速度较传统的检测算法有很大提升,且检测精度较高,由此得出此算法模型可靠性较高,为控制层和决策层提供了有力保证。

表2 检测结果统计Tab.2 Test result evaluation index
4 结论
本文基于传统的K-means检测算法进行改进,不再对雷达的频域信号进行处理。基于雷达一次处理得到的点,对雷达点云的属性信息进行分析。通过预聚类的手段使算法自动获取最优解对应的k值,将K-means 由无监督学习变为监督学习。利用聚类结果进行一次关联门重新确定聚类中心,基于聚类中心进行二次关联门,分离出目标。进而提高了检测速度和精度。在相同的设备下,通过分别计算传统K-means 算法与本文算法对相同数据处理速度和精度,得到本文算法检测的准确率达到92.04%,高于传统的检测准确率,同时检测速度提高了36%,经验证该算法具有良好的检测性能。
