卷积目标分类网络的可信评估建模方法
2022-10-28曹恩龙刘赫炎孙智孝刘环宇
曹恩龙, 刘赫炎, 孙智孝, 罗 庆, 刘环宇
1.航空工业沈阳飞机设计研究所,辽宁 沈阳 110000; 2.哈尔滨工业大学 电子与信息工程学院 自动化测试与控制研究所,黑龙江 哈尔滨 150001; 3.哈尔滨工业大学 计算学部 信息对抗技术研究所,黑龙江 哈尔滨 150001)
目标分类系统相比于传统计算系统而言,系统结构复杂、具有自主学习能力且对数据的应用更为多元化,例如智能识别网络的“数据驱动”“不可测”“难评估”的“黑盒”特性,给可信性评估带来极大困难。实测数据难以完全获得,严重制约着智能目标分类系统的完备性测试。采用目前现有的样本扩充和样本构建方法,难以保证系统可信性评估效果。目前,对可信性评估的方法较为单一,缺少专门的可信性评估技术规范和标准,一般只采用简单的准确率作为评估依据,指标单一,无法作为可信性评估的完备指标,需要同时考虑系统泛化性、鲁棒性和自主能力等级的问题。因此,依托现有的可信性评估方法不能满足目标分类系统的评估要求。目标分类系统是复杂的系统工程,如果对其工作状态不能进行评估,就无法从根本上保证智能系统的可靠性。
目标分类系统的泛化性评估模型依赖于训练和测试数据独立分布[1],鲁棒性评估依赖于不同类型和强度的输入扰动[2-3]。对于微小的扰动,虽然人类视觉不可分辨,但是对于卷积目标分类网络来说,可能会带来巨大的波动变化,从而导致分类错误,这给卷积目标分类网络的可信性带来了巨大的隐患[4-6]。
近年来,美国、欧盟等高度关注人工智能可信评估技术的发展。美国对智能系统可信评估技术领域的研发战略、国际基准、关键技术和评测标准等四个方面均进行了规划与研究。美国《国家人工智能研发战略计划》在2016年6月发布[7]。2019年6月,美国《国家人工智能研发战略计划:2019年更新版》提出“确保人工智能系统可靠”的战略发展目标,指出在广泛使用人工智能系统前,需要创建可靠、可信赖的人工智能系统,同时需要提高可信性、透明度并建立信任等[8]。同年,美国国防创新委员会在2019年10月提出“加强人工智能测试和评估技术”,在美国发展测试和评估办公室(ODT)的领导下,建立人工智能技术测试和评估基准。美国国防高级研究计划局(DARPA)重点支持了“可信性的人工智能”“确保人工智能对抗欺骗的可信性”等项目,将可信赖作为确保自主系统可靠性的重要手段,在此基础上再将自主系统推广到军事领域应用[9]。2019年3月,欧盟委员会公布了《可信赖的人工智能道德准则草案》,构建了“可信赖人工智能”框架,为部署、开发和使用人工智能的企业、政府、研究机构、社会组织和个人提供了实现“可信赖人工智能”的指南[10]。2019年9月,国际测试委员会(BenchCouncil)发布了人工智能测试标准、HPC AI500测试基准等五项新人工智能装备评测标准[11]。
在标准化方面,国际标准组织人工智能分委会(ISO/IEC JTC1 SC42)于2020年11月成立了WG3可信赖工作组,开展算法可信性、神经网络鲁棒性评估、伦理关切等标准和报告的研制。我国国家人工智能标准化总体组、全国信标委人工智能分委会也在组织开展可信赖等标准研究工作。2021年3月,给出了评估神经网络鲁棒性的流程,并列举了3种理论评估方法:基于统计的评估方法、基于形式化理论证明的评估方法和基于经验的评估方法。
基于以上的研究可知,建立可靠的目标分类系统可信性评估体系是必不可少的,同时为了方便用户,可以搭建集数据、算法、指标于一体的目标分类系统可信性评估软件平台。
1 目标分类系统性能评估模型
1.1 基于黑盒的目标分类性能评估模型
针对目标分类网络的结果,可以使用基于黑盒的目标分类性能评估模型。针对数据生成系统产生的目标数据,构建训练集和测试集,从样本稀疏性、均衡性来实现泛化能力的评估,对于稀疏性的样本,采用等价类划分、成对边界划分质心定位方法、样本边界评估方法,对稀疏性进行定义;采用正负样本均衡性、类别样本均衡性、场景/目标均衡性分布评估方法,实现对均衡性进行评价,采用不同的均衡性和平衡性的测试样本集,对分类决策系统进行目标准确率等10种表征指标的计算,最后对性能指标进行融合,生成对泛化能力和鲁棒能力的评价以及最终评价。
基于黑盒的目标分类性能评估模型包括以下10个评价指标。其中TP表示预测为1,实际为1,预测正确;FP表示预测为1,实际为0,预测错误;FN表示预测为0,实际为1,预测错误;TN表示预测为0,实际为0,预测正确。
① 准确率(ACC)。准确率是指预测正确的样本数与样本总数之比。
(1)
② 精确率(P)。精确率是指所有被判别为正的样本中,真正为正的样本所占的比例。
(2)
③ 召回率(R)。召回率是覆盖面的度量,度量有多个正例被分为正例。
(3)
④ F1值。F1值是统计学中用于衡量二分类模型精确度的一种指标,用于测量不均衡数据的精度。它的最大值是1,最小值是0。
(4)
⑤ 混淆矩阵。混淆矩阵可以反映类别之间相互误分的情况。对于包含多个类别的任务,混淆矩阵能很清晰地反映出各类别之间的错分概率。
⑥ 受试者操作特性曲线(Receiver Operating Characteristics Curve,ROC)。ROC是反映敏感性和特异性连续变量的综合指标。
⑦ AUC(Area Under Curve,曲线下面积)。 AUC的值就是处于ROC曲线下方的那部分面积的大小。通常,AUC的值介于0.5~1.0之间,AUC值越大的分类器,判断准确性越高。
⑧ Kappa系数(k)。Kappa系数是一种度量分类结果一致性的统计量,是度量分类器性能稳定性的依据,Kappa系数值越大,分类器性能越稳定。
(5)
式中:po为每一类正确分类的样本数量之和除以总样本数,也就是总体分类精度。假设每一类真实样本个数为a1,a2,…,ac,而预测出来的每一类的样本个数为b1,b2,…,bc,总样本个数为n,则有
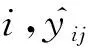
(6)
(7)
1.2 基于白盒的目标分类性能评估模型
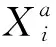
① 神经元覆盖率(Neuron Coverage,NC)。
神经元覆盖率是所有测试输入中唯一激活的神经元数量与深度神经网络(Deep Neural Networks,DNN)中神经元总数的比值。
② 神经元边界覆盖(Neuron Boundary Coverage,NBC)。
神经元边界覆盖度量了给定的测试输入集T覆盖了多少个拐角区域,包括上边界和下边界值。
③ 噪声容量估计(Noise Tolerance Estimation,NTE)。
噪声容量估计反映了对抗样本在保持分类类别不变的情况下可容忍的噪声量,计算公式为

(8)
④ 对图像压缩鲁棒性(Robustness to Image Compression,RIC)。
对图像压缩鲁棒性常被用于评价计算机视觉算法中的图像去噪情况。正常情况下,一个高鲁棒性的对抗样本在进行图像压缩后应保持其误分类效果,计算公式为
(9)
式中:UA表示非定向攻击;TA表示定向攻击;函数IC表示图像压缩处理。
⑤ 对高斯模糊鲁棒性(Robustness to Gaussian Blur,RGB)。
对高斯模糊鲁棒性常被用于评价计算机视觉算法中的图像去噪情况。正常情况下,一个高鲁棒性的对抗样本在高斯模糊后应保持其误分类效果,计算公式为
(10)
式中:UA表示非定向攻击;TA表示定向攻击;函数GB表示高斯模糊处理。
⑥ 最大边界距离(Worst Case Boundary Distance,BD)。
最大边界距离表示数据点之间到决策边界的距离,用于衡量模型在最坏情况下的稳定性和鲁棒性,计算公式为
(11)
式中:V为一个随机生成的集合;φi(V)为到模型决策边界的RMS距离;di为到决策边界距离的最大值。
⑦ 平均置信度(Average Confidence of Adversarial Class,ACAC)。
平均置信度表示对错误类别的平均预测置信度为经过对抗攻击后,对于所有攻击成功对抗样本,所有误分类类别的平均概率,计算公式为
(12)
⑧ 正确类别平均置信度(Average Confidence of True Class,ACTC)。
正确类别平均置信度通过对对抗攻击样本的真实类计算预测可信度的平均值来评估攻击在多大程度上偏离真实值,计算公式为
(13)

⑨ 对抗攻击失真度(Average Lp Distortion,ALDp)。
对抗攻击失真度为所有攻击成功的对抗样本的平均归一化Lp失真度,计算公式为
(14)
⑩ 平均结构相似性(Average Structural Similarity,ASS)。
平均结构相似性为所有攻击成功对抗样本与其原始样本间的平均相似性,计算公式为
(15)
式中:SSIM表示结构相似度。
扰动敏感距离用于评测人类对扰动的感知能力,计算公式为
(16)
式中:m为像素点总数;δi,j为第i个样例的第j个像素点;R(xi,j)为xi,j附近平方区域;std为标准偏差函数。
K-多节神经元覆盖表示给定一个神经元n,K个多段神经元覆盖度量给定的测试输入集合T覆盖范围[lown,highn]的彻底程度。
强神经元激活覆盖度量了给定的测试输入集合T覆盖了多少个角落情况。
经验噪声敏感性表示综合对抗攻击和自然噪音的一个测试集。
Top-k神经元覆盖表示前k个神经元的覆盖测量了每层上曾经最活跃的k个神经元的数量,定义为每一层的Top-k神经元总数与DNN中神经元总数的比值。
Top-k神经元模式代表了每一层顶层过度活跃神经元的不同激活场景。
2 目标分类系统可信性评估方法
2.1 目标分类系统测试用例生成
2.1.1 泛化性测试用例生成
为了测试分类任务的泛化能力,需要根据任务需求生成测试用例。首先要选择原始数据集,其次在关键参数处设置抽取比例参数,从原始数据集中每一个图像类别抽取相应比例的图像作为测试集,对训练样本进行分布调整,从而使数据具有较好的均衡性和稀疏性,将测试集样本存放在指定的文件夹下,并且测试图像的类别和数量应与所设置参数一致。
2.1.2 鲁棒性测试用例生成
为了测试分类任务的鲁棒能力,需要根据任务需求生成测试用例。首先选取已经具有较好的均衡性和稀疏性的泛化性数据的测试集,对其进行加噪处理,随机将图像中的像素点置白或者置黑,或者随机在图像上加入不同面积的黑块对目标进行遮挡,从而测试不同强度噪声下分类网络的鲁棒性。
2.2 目标分类系统可信性评估过程
2.2.1 泛化性评估过程
将测试用例生成得到的泛化性测试集作为分类算法的输入。再使用分类网络将测试集中的每一张图像进行分类得到测试解和对应的标准解。将测试解和标准解作为评估模型的输入,设置评估指标对应参数,进而得到目标分类系统各个指标的计算结果,将每个指标的计算结果进行融合分析得到最终结论,在可视化平台上进行显示。目标分类泛化性能力评估流程如图1所示。

图1 目标分类系统泛化能力评估流程
在进行泛化性评估时选择基于黑盒的目标分类性能评估模型,其中包括准确率、精确率、召回率、F1值、混淆矩阵、ROC曲线、AUC面积、Kappa系数、海明距离、杰卡德相似系数10个指标。
2.2.2 鲁棒性评估过程
将生成的鲁棒性测试用例作为分类算法的输入,不同噪声强度的测试集经过分类网络可以分别得到对应的测试解和标准解。将多组测试解和标准解作为鲁棒能力评估模型的输入,经计算可以得到每种噪声强度下不同指标对应的值,同时可以得到评价指标随噪声强度变化的曲线,针对以上结果进行综合分析得到最终结论,显示在可信性评估平台上。目标分类系统鲁棒能力评估流程如图2所示。

图2 目标分类系统鲁棒能力评估流程
除此之外,基于白盒的目标分类性能评估模型也可以用于评估目标分类系统的鲁棒能力,其中KMNC、NBC、SNAC、ALDp、ASS、PSD是基于数据层面进行评估的,ACAC、ACTC、NTE、ENI是基于模型层面的。
2.3 目标分类系统评估结果评价
2.3.1 泛化性结果评价
在进行目标分类系统泛化性评估结果的评价时,对泛化能力评价体系中的10个指标进行了综合分析,得到了每一个指标的具体评价标准,具体如表1所示。其中,准确率、精确率、召回率、F1值、AUC面积、Kappa系数、杰卡德相似系数是极大型指标,海明距离是极小型指标,可将算法评价划分为四挡。

表1 泛化性结果评价
2.3.2 鲁棒性结果评价
在进行目标分类系统鲁棒性评估结果的评价时,对鲁棒能力评价体系中的3个指标进行了综合分析,同时设置了可用阈值和失效阈值,认为指标数值高于可用阈值所对应的噪声强度为可忽略噪声,指标数值低于失效阈值所对应的噪声强度为彻底失效噪声,鲁棒性结果评价可划分四挡,具体如表2所示。

表2 鲁棒性结果评价
3 仿真实验及评估
3.1 数据集及分类网络选取
本次实验选取了NWPU-RESISC45数据集,该数据集包含分辨率为256像素×256像素的图像共计31500张,涵盖45个场景类别,其中每个类别有700张图像。分类网络选取了ResNet50进行仿真实验。
3.2 可信性评估结果及结论分析
为了方便用户进行可视化使用,搭建了目标分类系统可信性评估软件平台。图3为目标分类系统可信性评估软件平台界面图。左侧部分为泛化性评估模块,中间部分为鲁棒性评估模块,右侧部分上方为测试用例生成模块,右侧下方为特异性鲁棒评估指标模块。软件界面图中为选取NWPU-RESISC45数据集和ResNet50网络的可信性评估结果。具体的泛化性指标实验结果和鲁棒性指标实验结果分别如表3和表4所示。鲁棒性数据选取的是随机遮挡作为噪声进行实验。
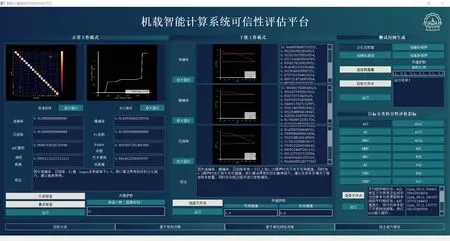
图3 目标分类系统可信性评估软件平台界面图

表3 泛化性指标实验结果

表4 鲁棒性指标实验结果
4 结束语
本文开发了一套目标分类系统可信性评估软件平台,提供测试用例生成、泛化性指标分析、鲁棒性指标分析等功能。针对目标分类系统的泛化性指标主要包含10个,鲁棒性指标主要包含16个,自主能力等级评估指标主要包含5个。所开发的目标分类系统可信性评估系统集成了测试用例生成、泛化性指标、鲁棒性指标等功能,提供了便捷的测试用例生成、指标评估等接口,方便用户对目标分类系统进行全面评估,为使用目标分类系统的军工武器产品提高可信性、可靠性和安全性提供了支持。
