电动汽车目标客户销售策略研究
——以2021年华数杯全国大学生数学建模竞赛C题为例
2022-10-27四川信息职业技术学院
◇四川信息职业技术学院 文 阳 伍 星
2021年华数杯全国大学生数学建模C题要求分析目标客户对于不同品牌汽车满意度情况,以及不同汽车销售的影响因素,建立模型挖掘潜在客户。本文通过借助excel和spss软件做数据清洗,并对满意度评价做回归散点图分析,给出顾客最满意的汽车品牌;对目标客户是否购买电动车的影响因素进行正态分布线性回归分析,给出影响不同品牌电动汽车的销售的主要因素;利用相关性分析法,CART算法对找到最大意愿购买汽车的客户。
1 背景资料
随着全球能源与环境危机的不断加剧,世界各国将目光瞄准电动汽车领域,纷纷制定电动汽车发展规划,扶持电动汽车产业,推动电动汽车企业抢占市场,目前中国市场的电动汽车发展很大程度上依赖政府政策的支持,尤其在电动汽车推广初期,电动汽车作为一个新兴的事物,在电动汽车产业发展的过程中,仅仅依靠市场的自运行还很难达到产业化目标,与传统汽车相比,存在着很多干扰顾客对于电动汽车购买的问题。在产业化的进程上往往会遇到诸多困难和瓶颈。首先,在技术方面,电动汽车还面临电池续航不足的问题;其次,在投入回报方面,电池技术、电控系统等核心技术的研发需要大规模资金的投入,这些资金投入的规模大大超出了汽车企业的投资能力范围;而对于汽车制造企业而言,传统汽车仍具有较高的利润回报,改造现有生产线需要进行大规模资金的投入,且电动汽车自身存在高度的不确定性因素,多数汽车制造企业并不能积极地投身于电动汽车的产业化过程中。与此同时,公共基础设施是电动汽车是产业化发展的前提保障。所以在市场化进程中,电动汽车发展缓慢,市场自运行仍缺乏推动力。为了实现新能源汽车的市场优势,首先就要考虑的是顾客对产品的评价。在此背景下,需要解决如下问题。
(1)数据参照2021年华数杯数学建模竞赛C题的附件,下面对数据做清洗工作,指出异常值和缺失数据,对数据做描述性统计分析,分析目标客户对于不同品牌汽车满意度的比较。
(2)根据目标客户体验评价,结合附件信息,找出目标客户是否购买电动车的主要因素。并研究不同品牌电动汽车的销售影响因素。
(3)结合问题1和问题2的结果,建立不同品牌电动汽车的客户挖掘模型,并评价模型的优良性,并利用模型判断目标客户是否购买电动车。
(4)根据问题3的结论在附件3中每个品牌各挑选1名没有购买电动汽车的目标客户,实施销售策略,提高客户满意度,实现目标客户购买汽车的目的。
2 问题分析
某汽车公司最新推出了三款品牌电动汽车,为研究消费者对电动汽车的购买意愿,制定相应的销售策略,销售部门邀请了1964位目标客户对三款品牌电动汽车进行体验。通过研究数据,运用数学建模的知识实现销售的科学决策。
对于问题(1),由于附件给出的数据有大量的异常值和缺失数据,为了使数据对后面的判定有更准确的输出结果,我们根据附件所给的数据用SPSS软件进行数据清洗处理,并对满意度评价做回归散点图分析。对于附件1的数据利用excel筛选、分析、评价每种类型汽车的整体满意度,以及a1-a8各个性能在每类车型中的占比,确定汽车在哪方面满意度较高、哪些方面不足。
对于问题(2),决定目标客户是否购买电动车的影响因素有很多,有电动汽车本身的因素,也有目标客户个人特征的因素。为了突出某些因素对不同品牌电动汽车的销售影响,考虑到关联性,我们运用SPSS软件对目标客户是否购买电动车的影响因素进行正态分布线性回归分析。由于此题着重考虑的是因素对客户购买意愿的影响,以a1-a8,b1-b17为自变量,以购买意愿为因变量,计算它们的显著性。
对于问题(3),为了建立不同品牌电动汽车的客户挖掘模型,首要条件是对每个影响因素做决策分析,再用结果建立决策树模型。
对于问题(4),对于满意度而言,这是用户体验的一个感官表现,加大服务力度对于a1-a8满意度会有所提高,但是满意度增大,服务难度也会增大,为了刻画服务力度与满意程度之间的关系,我们采用kano模型。
3 解决问题
3.1 问题1的模型建立与求解
为了提高数据的正确性与合理性,我们利用SPSS软件对数据进行清洗。通过处理发现电动汽车本身因素数据的缺失规律相同,其中缺失占比最高的表现在客户是否有孩子这项数据。对于缺失值替换处理,用0替换。异常值占少数,比如1964名体验者对a3的满意度评价703显然是错误数据,我们用此列数据中的平均值代替。
为了分析目标客户对于不同品牌汽车满意度,我们针对1964位目标客户对3类汽车a1-a8满意度评价求了平均值,分析群体的整体满意度,如下表所示。
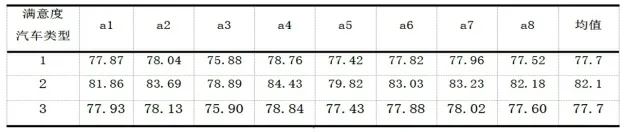
表1 满意度均值
可以看到3类汽车中,第2类汽车整体满意度最高,第一类和第三类汽车相当。三类汽车中,a3的评价整体偏低,在这一当面需要提高服务。
接下来,通过散点图分析顾客对不同品牌汽车的满意度统计如下图所示:
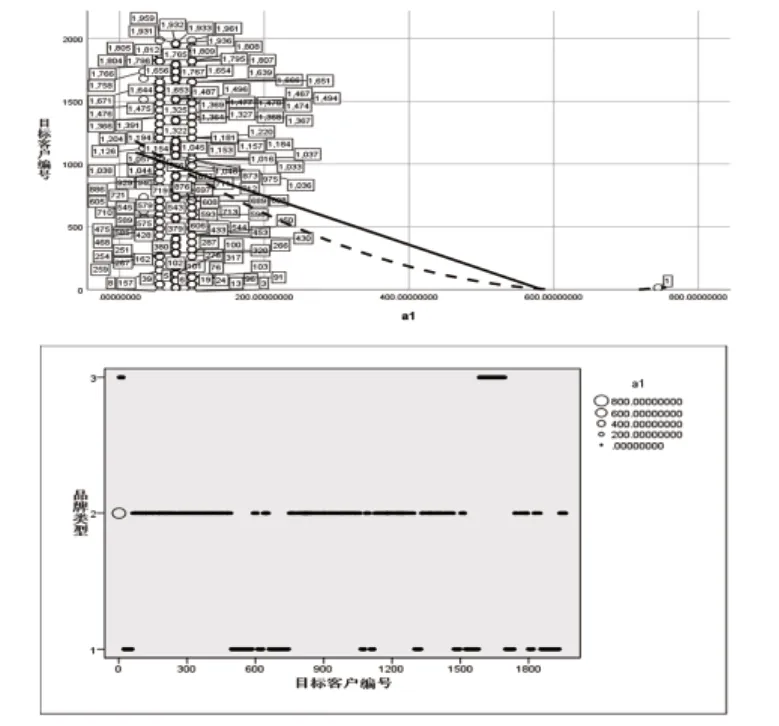
图1 满意度分析
从两个图中可以看出目标客户对于第2类汽车的满意度较为集中,对于第3类汽车的满意度较为稀疏,对于第1类汽车的满意度一般。
为了显示出各个满意度评价对不同电动汽车的具体影响,我们首先对品牌车进行排序,然后分类计算出各个满意度评价对不同产品汽车的所占比列效果如下所示。
从表2中可以看出在第1类汽车中,顾客对该车种的质量、外观满意度相对较高,第2类汽车中,顾客对该车种的经济、驾驶操控满意度较高,第3类汽车中,顾客对该车种的外观、质量满意度较高。由此可见顾客对汽车的经济、质量、外观、驾驶操控更在乎。

表2 客户对各个汽车满意度占比
3.2 问题2的模型建立与求解
我们发现决定目标客户是否购买电动车的影响因素有很多,而且每个影响因素之间有着密切的关系,所有考虑各因素的关联性。我们利用SPSS软件对目标客户是否购买电动车的影响因素进行正态分布线性回归分析。
为了更清楚的了解各个因素对顾客购买意愿的影响,本部分将以a1-a8,b1-b17为自变量对购买意愿为因变量进行回归分析,建立相应的回归方程模型。设被解释变量为,解释变量为中总因素按照自变量顺序,则多元线性回归理论模型为
本部分的回归分析将使用到以下统计量:F值、R2、DW值。其中F统计量是为了检验解释变量与被解释变量之间是否存在显著的线性关系;R2代表拟合优度,R2取值在0~1之间,R2越接近于1,说明回归方程对样本数据点的拟合优度越高,反之,R2越接近于0,说明回归方程对样本数据点的拟合优度越低;DW观测值是判断残差序列之间是否存在自相关,DW值在0~4之间,当残差序列不存在自相关时,DW≈2(1-ρ^2)。如果残差序列存在自相关,说明回归方程没能充分说明被解释变量的变化规律,还留有一些些规律性没有被解释。
接下来,利用spss26.0对数据进行处理其中结果如下所示。

表3 因变量模型摘要
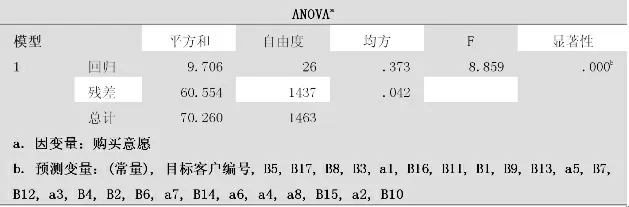
表4 ANOVAa 表
通过以上SPSS软件对顾客购买意愿的因素影响的分析结论如下所示。
(1)本次线性回归模型的拟合度比较良好,R2=0.138384>0.1,意味着本次运算结果在一定程度上真实可靠的反应出a1-a8,b1-b17对购买意愿的影响情况。
(2)25个自变量之间存在着少量共线性,总体上VIF都在1-10之间。
(3)回归方程显著,F=8.859,P<0.001,意味着四个变量中至少有一个可以显著影响因变量购买意愿。
(4)其中a3(经济),B13(家庭收入),B16(总收入占比),B17(车贷占比)可以显著正向影响购买意愿(a3中B=0.003>0,P<0.05;B13中B=0.002>0,P<0.01;B16中B=0.003>0,P<0.01;B17中B=0.003>0,P<0.01)其他影响因素均不能显著影响购买意愿因为大多P>0.05。
3.3 问题3的模型建立与求解
决策树模型中CART算法既是分类树,又是决策树,它的作用有两种,第一种是通过一个对象的特征来预测对象所属类别,第二种则是根据一个对象的信息预测该对象的属性习算法。该算法的优点是在学习过程中不需要使用者了解和 输入很多背景知识,只要训练样例能够用“属性.值”对的方式表达出来,就能使用该算法来进行学习。其中CART算法公式模型为:
其中CK是D中属于第K类的样本子集,K是类的个数。如果D被特征A划分为D1、D2两个部分这个时候就是统计均值,D的基尼系数:
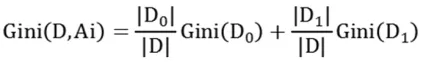
通过运算得出电动汽车品牌1与城市居住龄高度相关,但出来决策树效果不好,我们决定加上弱相关的因素(Person系数>0.17)。与房贷占比,车贷占比,经济型,城市居住年龄有一般线性关系。与电池之间有密切关系,并且模型评价精度94.5。

图2 电动汽车品牌1决策树模型

表5 电动汽车品牌1模型精度分析
同理,可知电动汽车品牌2与因素外观,动力,安全,经济,舒适,电池有一般正相关关系与房贷占比有一般负相关关系。与个人年收入和单位有非常紧密关系,与城市居住龄有紧密关系,模型评价精度92.86;电动汽车品牌3与电池,品质,外观,操控性,动力性,安全性,经济型,舒适性,具有一般线性关系,模型评价精度88.89。
为了验证孩子缺失会不会对结果有影响,因此用一般判断不容易发现,因此我们通过以下表格和散点图对数据分析,如下图所示。
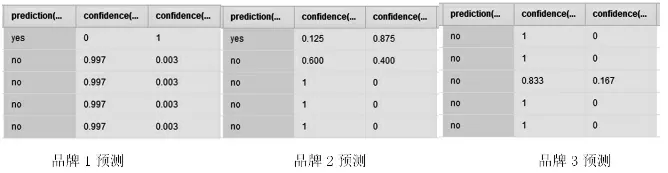
图3 电动汽车品牌1决策树模型
由分析可知,置信度均大于0.8,结果较为可信。从散点图分析,可以直观的看到孩子(B7)对于购买意愿之间关系影响不大,故不需要预测待测数据孩子数。
通过问题1和问题2的解答论证可以知道客户对与购车的可能性是:汽车品牌2的购买意愿>汽车品牌1的购买意愿>汽车品牌2的购买意愿。又因为品牌1与品牌3在质量问题上,品牌车2经济问题上。所以附件3中客户编号1.5.6.7.9.13购买意愿可能性最大。
3.4 模型4的建立与求解
kano模型主要用于客户需求分类和优先排序的工具,展示产品或服务与客户满意度之间的关系。为设计出顾客满意的产品和服务之间提供有效的方法。其模型公式如下:
(满意影响力)SJ=(A+O)/(A+O+M+I)
(非满意影响力)|DSJ|=-1*(O+M)/(A+O+M+I)
其中,A:魅力需求;O:期望型需求;M:基本需求;I:无差异需求。
由附件3中选出编号为2,8,15且没有购买意愿的顾客的评分结果如下表所示。

表6 附件客户选用
根据前面三个问题的选出决定因素的a3、a6、a7、a8,依次为M、A、O、I运算结果如下表所示。
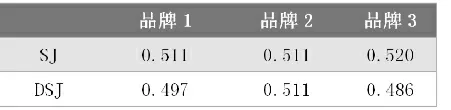
表7 影响力分析表
当SJ值和DSJ绝对值均>0.5时判定为期望质量(O),当SJ值和DSJ绝对值均<0.5时为无关质量(I),当SJ值>0.5、DSJ绝对值均<0.5时为魅力质量(A),当SJ值<0.5、DSJ绝对值>0.5时为必备质量(M),由上得出结论品牌1为魅力质量,品牌2期望质量,品牌3为期望质量,因为M(必备)>O(期望)>A(魅力)>I(无关),因此,对于品牌2,品牌3质量的提高5%对服务难度影响小,品牌1质量的提高5%对服务难度影响大,计算式子为:
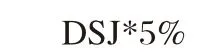
得出结论:加大力度对品牌2和品牌3推广。
