基于模态重构与多维评价的时间序列趋势提取
2022-10-26杜加础车文刚程文辉
杜加础,车文刚,程文辉
(昆明理工大学 信息工程与自动化学院,昆明 650500)
0 引 言
时间序列是按照时间顺序排列、随时间变化且相互关联的有序数据集合。随着信息技术的不断发展和进步,时间序列的数据量和复杂度与日俱增,并存在于社会经济生活的各个方面。时间序列的主要研究方向有数据预处理、数据分割、相似度度量、特征提取、维度规约、分类、聚类和规则识别等,对于时间序列的研究成果广泛运用于电信、网络安全、医疗卫生、电子商务和工业工程等领域。
趋势特征是时间序列的一个重要信息,它直观反映了时间序列的变化趋势和模式特征,对于时间序列的特征提取一直是时间序列研究的一个重要方向。为提取时间序列的趋势特征,人们提出了时间序列特征表示方法,能够实现对时间序列的降维,并保留其主要的趋势特征。目前已经提出的表示方法主要分为4类[1]:①基于频域变换的表示方法,主要有离散傅里叶变换[2-3]和离散小波变换[4-6];②基于模型的表示方法,主要有自回归模型[7]、隐马尔科夫模型[8]和核模型[9];③基于符号的表示方法,其中使用最广泛的是符号聚合近似方法[10-11];④基于分段的特征表示方法,主要有分段聚合近似(piecewise aggregate approximation, PAA)[12]和分段线性表示(piecewise linear representation, PLR)[13-14]。其中PLR方法因其具有简洁直观、处理效率较高、产生的表示结果更符合人类视觉体验等优点,得到了广泛的应用。传统的PLR方法主要有自顶向下(top-down, TD)的PLR-TD方法[15]、自底向上(bottom-up, BU)的PLR-BU方法[16]、基于滑动窗口(sliding window, SW)的PLR-SW方法[17]和基于重要点(important points segment, IPS)的PLR-IPS方法[18]。为了解决传统PLR方法分段拟合难以达到理想效果的问题,近年来出现了不少改进的PLR方法,例如文献[19]提出的基于转折点和趋势段(turning point and trend segment, TPTS)的分段线性表示方法(PLR-TPTS)、文献[20]提出的基于重要点双重评价(double Evaluation, DE)的分段线性表示方法(PLR-DE)等,但是,这些方法仍然存在错误提取分段点、拟合误差较大、难以反映整体趋势等问题。
文献[21]提出了经验模态分解(empirical mode decomposition, EMD),该方法主要用于处理非线性、非稳态的数据。近年来,EMD逐渐从信号分析处理领域被引入到对时间序列的分析中,但是EMD存在模态混叠的问题。文献[22]提出了集合经验模态分解(ensemble empirical mode decomposition, EEMD),通过对原始信号多次加入不同的白噪声来消除EMD出现的模态混叠现象。文献[23]提出了自适应噪声的完备经验模态分解(complete ensemble empirical mode decomposition with adaptive noise,CEEMDAN)方法,通过加入自适应噪声,解决了EEMD重构误差不为零、分解效率低等问题,且进一步减小了模态混叠效应。
本文在PLR-IPS的基础上,将模态分解方法和模态重构思想引入时间序列的分段线性表示研究中,提出一种基于CEEMDAN分解重构与多维评价的重要点评价策略,并结合智能寻优算法提出一种新的时间序列趋势提取算法。新方法从单点、局部和整体3个维度综合评价重要点,通过模态重构思想选取全局性分段点,克服了局部分析的缺陷;通过对重要点的分类讨论,使得对重要点的评价更为精准。同时,本文方法使用智能寻优算法,避免了基于经验选择参数而导致的拟合误差上下波动问题。
1 基于PLR-IPS的趋势提取方法
1997年,文献[14]将分段线性表示算法引入时间序列数据挖掘领域;2002年,文献[18]提出了基于重要点的PLR-IPS方法,它能够直观反映时间序列的变化趋势,且具有线性的时间复杂度和较高的精确度。
时间序列S是由n项数据值按照时间上的先后顺序组成的有限集合,可以表示为
S={(x1,t1),…,(xi,ti),…,(xn,tn)}
(1)
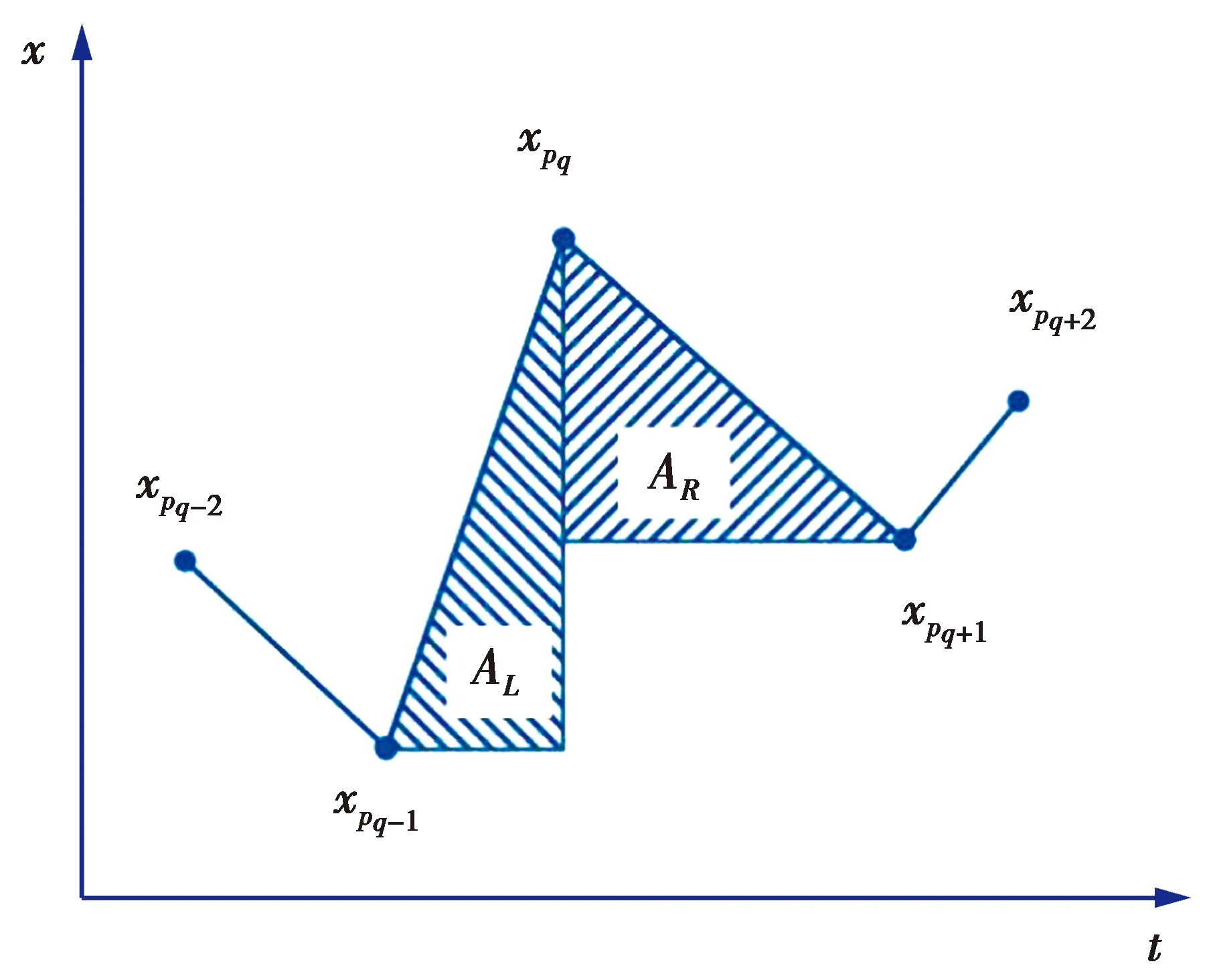
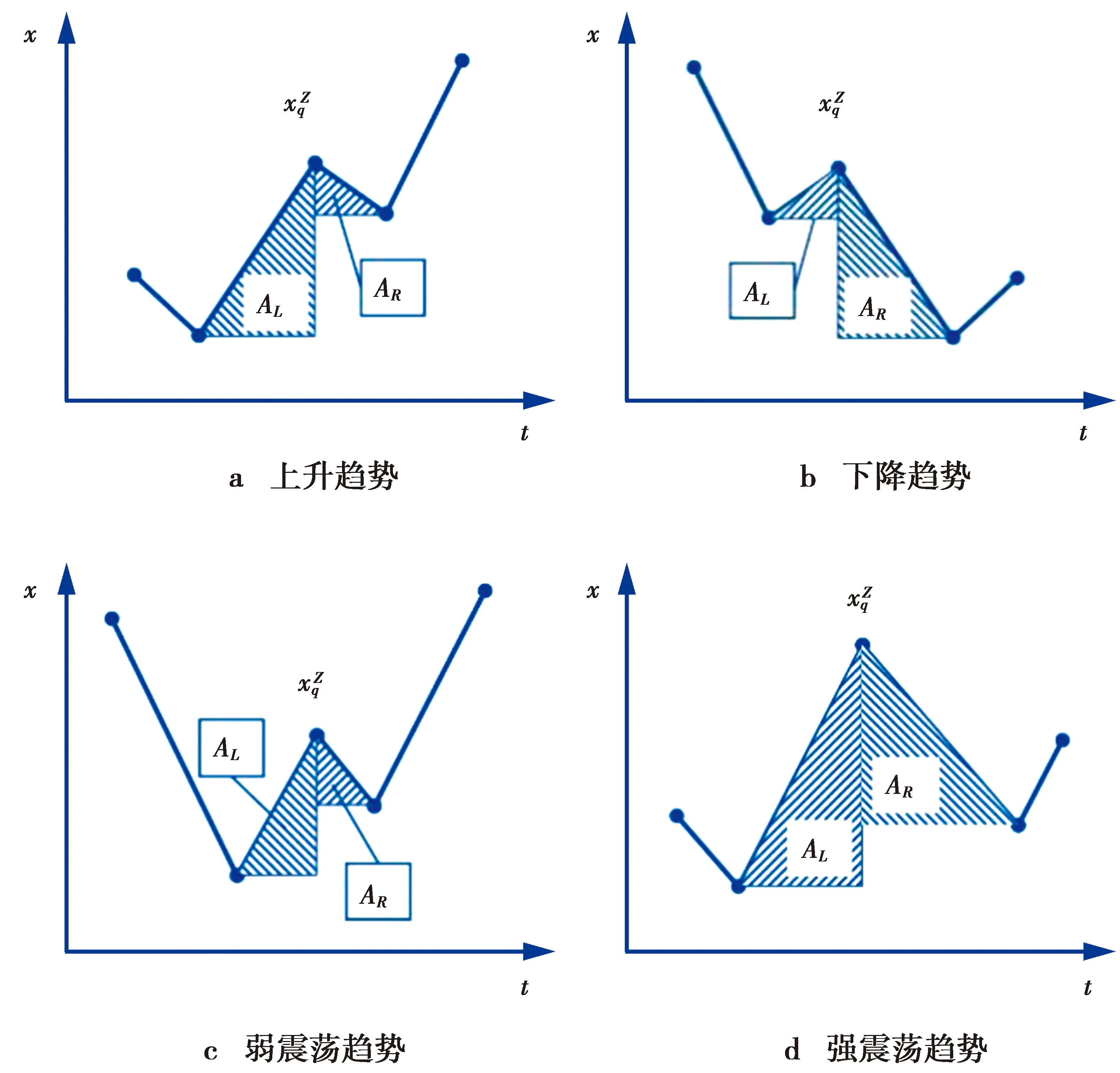
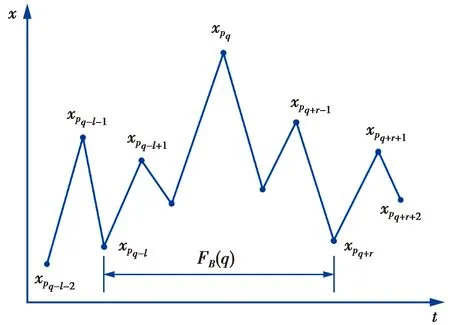
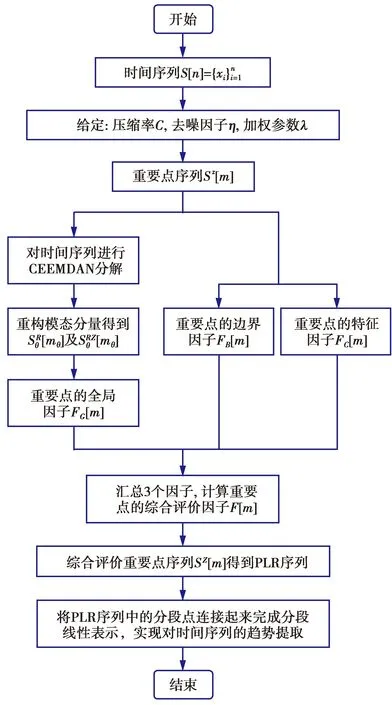
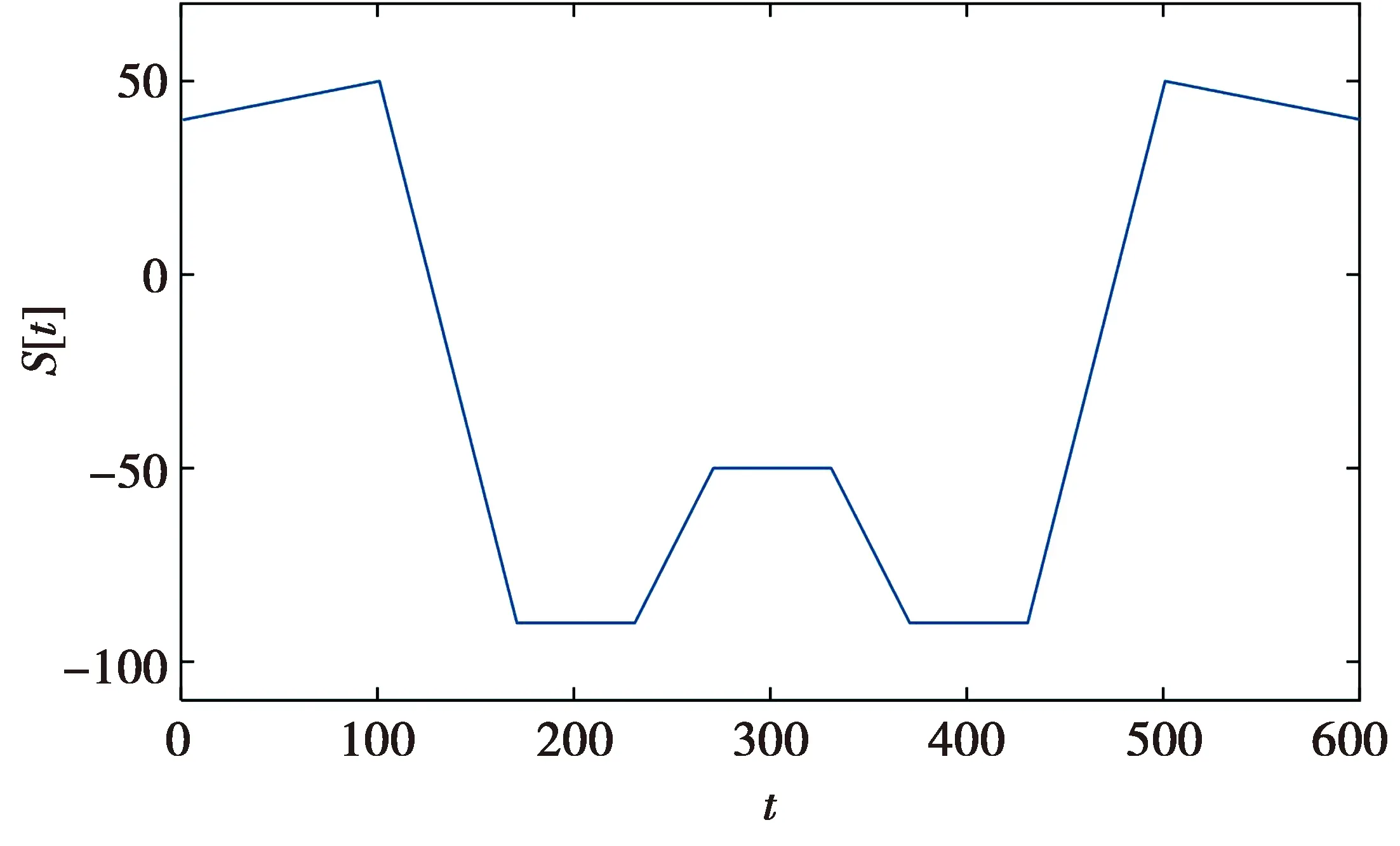
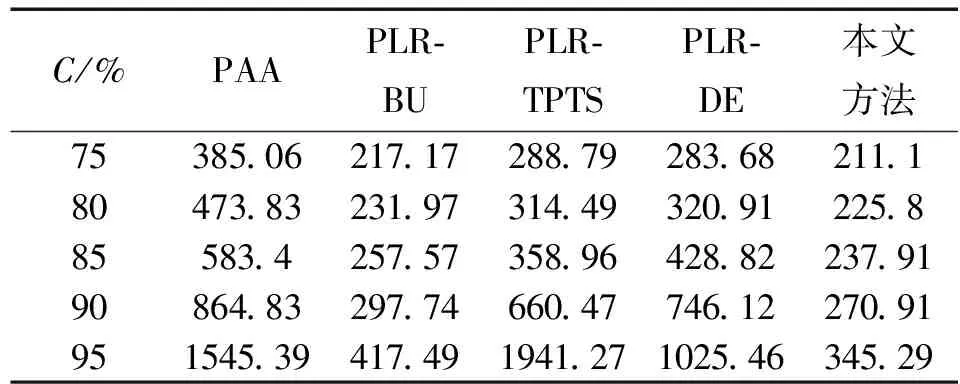
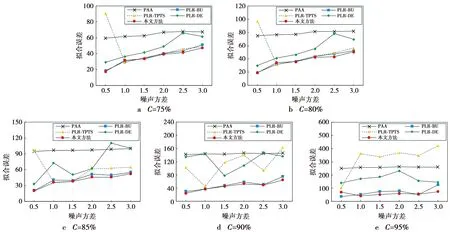
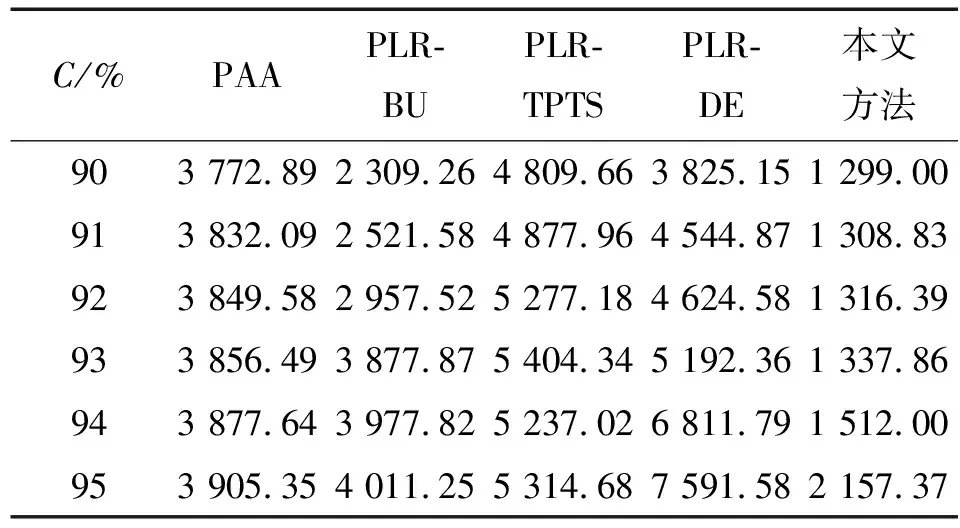
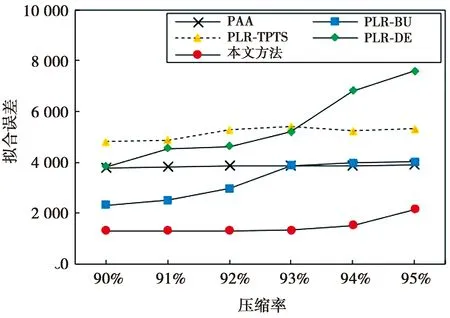
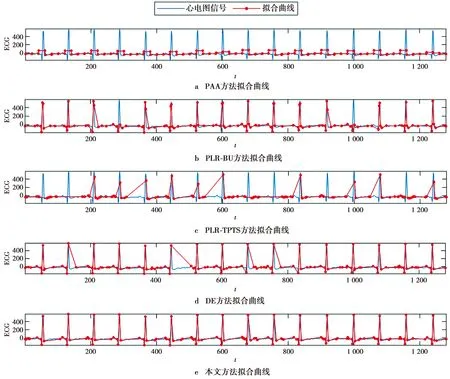
(1)式中,(xi,ti)为时间序列中的第i个元素,表示ti时刻的数据值为xi,且i (2) {xpq-1≤xpq}∩{xpq {xpq-1 {xpq-1≥xpq}∩{xpq>xpq+1}∪ {xpq-1>xpq}∩{xpq≥xpq+1} (3) 此外,规定时间序列的两个端点为重要点,由(3)式得到m个重要点,则重要点序列可以表示为 (4) 由上述的定义可知,本文的重要点序列由时间序列的端点和内部的离散局部极值点组成。 (5) (5)式中,d为分段点数量,且一般情况下有d 给定原始时间序列S[n]及其对应的PLR序列SP[d],则时间序列分段线性表示后的压缩率C可以表示为 (6) (7) 基于PLR-IPS的方法对时间序列趋势提取的目标就是在指定压缩率的情况下,使得分段表示后的拟合误差达到最低,减小拟合误差的关键在于采用合理的评价策略从重要点序列中选取分段点。 第1步使用EMD对S[n]+ε0ωi[n]进行I次分解得到I个模态分量,则CEEMDAN分解产生的第1个模态分量(k=1)可以表示为 (8) 第2步计算得到第1个残差为 (9) 第3步使用EMD对r1[n]+ε1E1(ωi[n])进行I次分解得到I个模态分量,则CEEMDAN分解产生的第2个模态分量(k=2)可以表示为 (10) 第4步同理,对于k=2,…,K,其对应的第k个残差可以表示为 (11) 第5步使用EMD对rk[n]+εkEk(ωi[n])进行I次分解得到I个模态分量,则CEEMDAN分解产生的第k+1个模态分量可以表示为 (12) 第6步重复执行第4步和第5步,直到得到的残差不能再被分解,则最终的残差可以表示为 (13) 在得到CEEMDAN方法的所有K个模态分量后,给定的原始时间序列可以表示为 (14) 算法实现中,每次实验中的系数εk能够允许在每一个模态分解阶段选择合适的信噪比。 实验表明,CEEMDAN能精确重构原始信号,在EEMD和EMD基础上重构误差显著减小,故本文选用CEEMDAN对时间序列进行分解和重构。 设置信噪比ε=0.2,噪声添加次数I=500,对含有400个数据的示例时间序列S[n]进行CEEMDAN分解后得到8个模态分量IMF和最终残差RES,CEEMDAN分解的结果如图1所示。 2007年,文献[24]在使用EEMD研究原油价格变化时,发现IMF重构后的序列能够反应原油价格的关键转折点和整体变化趋势。基于这个研究成果,本文使用CEEMDAN方法对时间序列进行分解,并探讨重构IMF数量对重构序列的影响。从低频到高频每次多加入一个IMF进行多次重构,可以得到多个重构的时间序列。IMF多次重构的结果如图2所示。 图1 CEEMDAN分解结果Fig.1 Results of CEEMDAN decomposition 图2表明,从低频IMF开始,每增加一个更高频的IMF参与重构,重构序列就能保留更多原始时间序列的细节;每减少一个高频的IMF,重构序列就能去除更多小幅波动而能够更加反映原始时间序列的整体变化趋势。将参与重构的IMF数量定义为重构参数θ,下面给出模态重构序列的定义。 (15) (16) 图2 IMF多次重构的结果Fig.2 Results of multiple IMFs reconstructions 但是CEEMDAN分解重构后会造成一些重要点的漂移,故需要进行漂移点修正。对比重构重要点序列SRZ[mθ]和原始时间序列重要点序列SZ[m],若重构重要点序列中的重要点不存在于重要点序列中,则进行漂移修正;若重构重要点为极大值重要点,则将此重构重要点修正为与其距离最近的SZ[m]中的极大值重要点;若为极小值重要点则修正为与其距离最近的SZ[m]中的极小值重要点。在对重构重要点序列进行漂移点修正后,所有重构重要点均能与原始时间序列重要点对应,所以有 (17) (18) (18)式中,当θ<⎣K/2」时,重构序列会过度损失时间序列的细节,故舍去。全局因子是侧重于时间序列整体维度的评价因子,随着重构参数θ的减小,参与重构的模态分量越少,出现的重构重要点越少,则重要点的全局因子越大。 根据定义4可知,全局因子只有K个值,只能将m个重要点评价为⎣K/2」个重要等级,无法精确评价各个重要点的重要程度,本文继续给出在单点和局部维度上对重要点进行评价的因子。 根据(3)式,重要点可以分为极大值重要点和极小值重要点。图3为极大值重要点的AL与AR示意图。图3中,xpq-1、xpq+1为极大值重要点xpq的相邻极小值重要点,xpq-2、xpq+2为相邻极大值重要点,AL与AR为重要点与其相邻2个重要点构成的三角形的面积。重要点对时间序列趋势的影响越大,其与相邻重要点的差异程度越大。即重要点xpq与左边的相邻重要点xpq-1差异越大,则AL越大;与右边的相邻重要点xpq+1差异越大,则AR越大,据此给出特征因子的定义。 图3 极大值重要点的AL与AR示意图Fig.3 Illustration for ALand ARof maximum important point 1)当q=1,m时有 FC(q)=max(FC) (19a) 2)当q=2时有 (19b) 3)当q=m-1时有 (19c) 4)当q=3,4,…,m-2时有 (19d) 特征因子是聚焦于重要点本身特征的因子,极大值重要点特征因子的4种类型如图4所示。 1)当q=1,m时有 FC(q)=max(FC) (20a) 2)当q=2时有 (20b) 3)当q=m-1时有 (20c) 4)当q=3,4,…,m-2时有 FC(q)= (20d) 本文特征因子参考了文献[25]中的三角形中心距离,但是上述方法均只采用了相邻两点来度量重要点的差异程度。文献[20]中的“距离因子”只考虑了相邻的2个重要点,本文的特征因子将其扩展到相邻2个极大值重要点和2个极小值重要点并进行分类讨论,对重要点的评价结果更为可靠。下面给出边界因子评价重要点对局部趋势的影响范围。 图4 极大值重要点特征因子的4种类型Fig.4 Four types of characteristic factor of maximum important point (21) (xpq-l (xpq+r 则有BL=pq-l,BR=pq+r,边界因子着重于重要点的局部影响力范围,可以理解为该重要点的“势力范围”。 图5为极大值重要点xpq的边界因子示意图,左边界点满足条件xpq-l+1 特征因子和边界因子分别反映了重要点在自身维度和在局部维度上的重要程度,下面结合全局因子给出综合评价因子的定义。 图5 极大值重要点的边界因子示意图Fig.5 Illustration for boundary factor of maximum important point (22) (22)式中:η为去噪阈值,表示去噪强度;λ为加权参数,表示边界因子与全局因子相加的权值;Mean(FC)为所有重要点特征因子的平均值。 1)获取重要点序列。根据定义1提取时间序列S[n]的重要点序列SZ[m]作为分段点的备选集。 3)计算3个评价因子。根据定义4,定义5和定义6计算得到时间序列所有m个重要点的全局因子FG[m],特征因子FC[m]和边界因子FB[m]。 5)提取时间序列趋势。将SP[d]中的所有分段点用直线段连接起来,得到时间序列的线性表示,完成对时间序列的特征趋势提取。 本文采用遗传算法结合十折交叉验证算法来确定综合评价模型的去噪阈值η和加权参数λ,选取使得拟合误差E最小的一组参数值作为最终模型参数,简要步骤如下。 1)进行数据预处理,将时间序列S[n]按照时间顺序平均分为10等份,轮流将其中的9份作为训练集数据,1份作为测试集数据。 2)按照本文时间序列趋势提取算法,分别计算得到各组训练集的全局因子FG、特征因子FC和边界因子FB,并根据(22)式将去噪阈值η和加权参数λ设为决策变量,以获取最优PLR序列使得拟合误差E最小化为最终目标构建适应度函数。 3)初始化遗传算法,设置种群大小为50,精英数目和交叉后代比例分别为30和0.75,最大进化代数、停止代数和适应度函数偏差分别为60、60和1e-6,使得算法能够在进化60代后停止。 本文趋势提取算法的流程如图6所示。 本文将选择上文介绍的4种时间序列的趋势提取方法作为比较对象。 1)PAA方法[12]。根据压缩率将时间序列分成等长的线性段,并获取每段内所有数据的均值。 2)PLR-BU方法[16]。先对时间序列上的所有数据点进行线性分割,依次对具有最小合并代价的相邻线性段合并直至满足要求。 3)PLR-TPTS方法[19]。先根据数据的角度变化值选择转折点,然后用转折点表征趋势段,通过寻找极值趋势段进而选择全局性的分段点。 4)PLR-DE方法[20]。先找到时间序列上所有重要点,并给出2个评价指标对重要点的重要程度进行评价,最后根据评价结果来选取分段点。 图6 本文趋势提取算法流程图Fig.6 Flow chart of the trend extraction algorithm 仿真实验序列为 (23) (23)式中,t为时间序列整数,共600个数据。该序列包含了平稳、不同趋势的上升和下降等模式,可以比较全面准确地测试算法性能。原始仿真数据示意图如图7所示。 图7 原始仿真数据示意图Fig.7 Illustration for raw simulation data 实验中对序列S[600]加上均值μ=0,方差σ为0.5、1.0、1.5、2.0、2.5、3.0的噪声,设定压缩率C要求分别为75%、80%、85%、95%,使用遗传寻优算法得到去噪阈值η和加权参数λ,考察不同方法趋势提取结果的拟合误差E。显然,分段表示序列越接近原始时间序列则其拟合误差越小,对应的算法性能也越好。不同压缩率下的拟合误差和如表1所示。由表1可知,随着压缩率的增加,各算法的拟合误差逐渐增大,在考虑所有压缩率的情况下,本文方法的拟合误差总和分别比PAA、PLR-BU、PLR-TPTS和PLR-DE减小了66%、9%、64%和54%。本文方法在不同的压缩率下都保持了最小的拟合误差。 表1 不同压缩率下的拟合误差和Tab.1 Sum of fitting errors under different compression rates 图8为各算法在不同压缩率下添加不同噪声的具体拟合误差。可以看出,在一定的压缩率情况下,各算法拟合误差会随着噪声的增大而增大,本文方法虽受到噪声的影响,但是拟合误差在大多数噪声下比其他方法小,去除噪声的能力更强。 PAA方法拟合误差虽然受到噪声的影响很小,但是整体的拟合误差较大,这是因为PAA方法的分段点是固定的,噪声的增加并不影响分段点的选择。PLR-TPTS方法由于其角度阈值是按照经验选取的,不同的角度阈值会造成拟合误差的大幅变化。PLR-DE方法由于重要点评价因子没有根据具体情况分类讨论,在面对复杂的时间序列时拟合误差会出现震荡上升的情况。这使得上述3种方法的拟合误差在压缩率和噪声的变化下出现了交叉。PLR-BU方法在低压缩率和低噪声时拟合误差较小,但是在高压缩率和高噪声情况下会出现较大拟合误差,这是因为PLR-BU方法只关注时间序列局部的信息而忽视了整体的趋势,在高压缩率高噪声情况下会错误提取重要点,出现与本文方法的拟合误差曲线出现交叉的情况。本文方法先考虑重要点在整体上的重要程度,并在考虑局部和单点情况时根据实际情况进行分类讨论,让评价因子更为精确,同时使用智能寻优算法确定最优参数,使得本文方法有效克服了上述方法存在的缺陷,在不同压缩率的情况下都能保持较小拟合误差,且在相同压缩率下随着噪声的增大拟合误差也比其他方法小。 图8 不同压缩率下的拟合误差Fig.8 Fitting errors under different compression rates 心电图(ECG)是临床上最常用的检查之一,也是时间序列挖掘和模式识别研究中的重要领域。但是心电时间序列是一种高维度的数据,为了方便存储、查询和挖掘,需要对其进行压缩表示。本文选用来自MIT-BIH正常窦性节律心电图的数据库,截取第1条通道的前10 s心电图数据作为本文实际应用验证的时间序列,此序列包含16个心跳周期,共1 280个数据值。 实验仍然采用上述4种方法作为本文方法的比较对象,考虑实际应用中高压缩率的需求,考察不同方法在压缩率C分别为90%、91%、92%、93%、94%、95%时的拟合误差E。 图9为不同方法在不同压缩率情况下对心电图序列进行趋势提取结果的拟合误差。可以看出,本文方法在不同压缩率情况下均保持了较小的拟合误差。PAA方法的拟合误差仍然对于压缩率的变化不敏感,PLR-DE方法由于其对于重要点的评价不够精准,在高噪声情况下随着压缩率增加,拟合误差有大幅度的增加并超过了PLR-TPTS。PLR-BU方法在高噪声情况下由于优先考虑局部趋势的缺陷,其拟合误差在压缩率增加下逐渐增加并在93%之后超过了PAA方法。拟合误差的具体数值如表2所示。 表2 不同压缩率下的拟合误差具体数值Tab.2 Specific value of fitting errors under different compression rates 图9 心电图序列趋势提取的拟合误差Fig.9 Fitting errors of ECG trend extraction 图10为在压缩率为90%的情况下,不同方法的拟合曲线对比。由图10可见,在对心电图这种高噪声的时间序列进行趋势提取时,其他方法都出现了错误的提取,而本文方法能够有效滤除干扰,准确提取了所有最关键的重要点,使得拟合曲线准确描述了原始时间序列的趋势特征,保持了较小的拟合误差。 图10 90%的压缩率下不同方法的拟合曲线对比Fig.10 Comparison of fitting curves of algorithms under 90% compression rate 本文在基于重要点的分段线性表示方法基础上,提出一种基于模态分量重构及多维评价的时间序列趋势提取算法。首先,使用CEEMDAN对原始时间序列进行分解,并进行多次模态重构;其次,基于模态重构序列组给出重要点的全局因子,在整体维度上对时间序列进行刻画;然后,使用特征因子结合去噪阈值滤除噪声的干扰,使用边界因子结合加权参数与全局因子进行运算得到综合评价因子;最后,根据压缩率的要求综合评价重要点序列确定分段点实现时间序列的趋势提取。仿真实验表明,本文方法的拟合误差分别比PAA、PLR-BU、PLR-TPTS和PLR-DE减小了66%、9%、64%和54%,其克服了现有趋势提取方法的缺陷,有效实现了去噪,能准确地提取时间序列的趋势。将本文方法应用于心电图序列趋势提取,其拟合误差分别比PAA、PLR-BU、PLR-TPTS和PLR-DE减小了61%、55%、71%和73%,这进一步表明,在高噪声情况下,本文所提方法具有良好的去噪能力,能够全面准确地提取时间序列的趋势特征。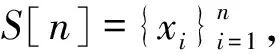
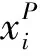
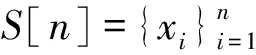
2 模态重构及多维评价
2.1 CEEMDAN分解与IMF重构
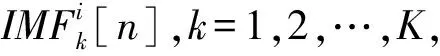
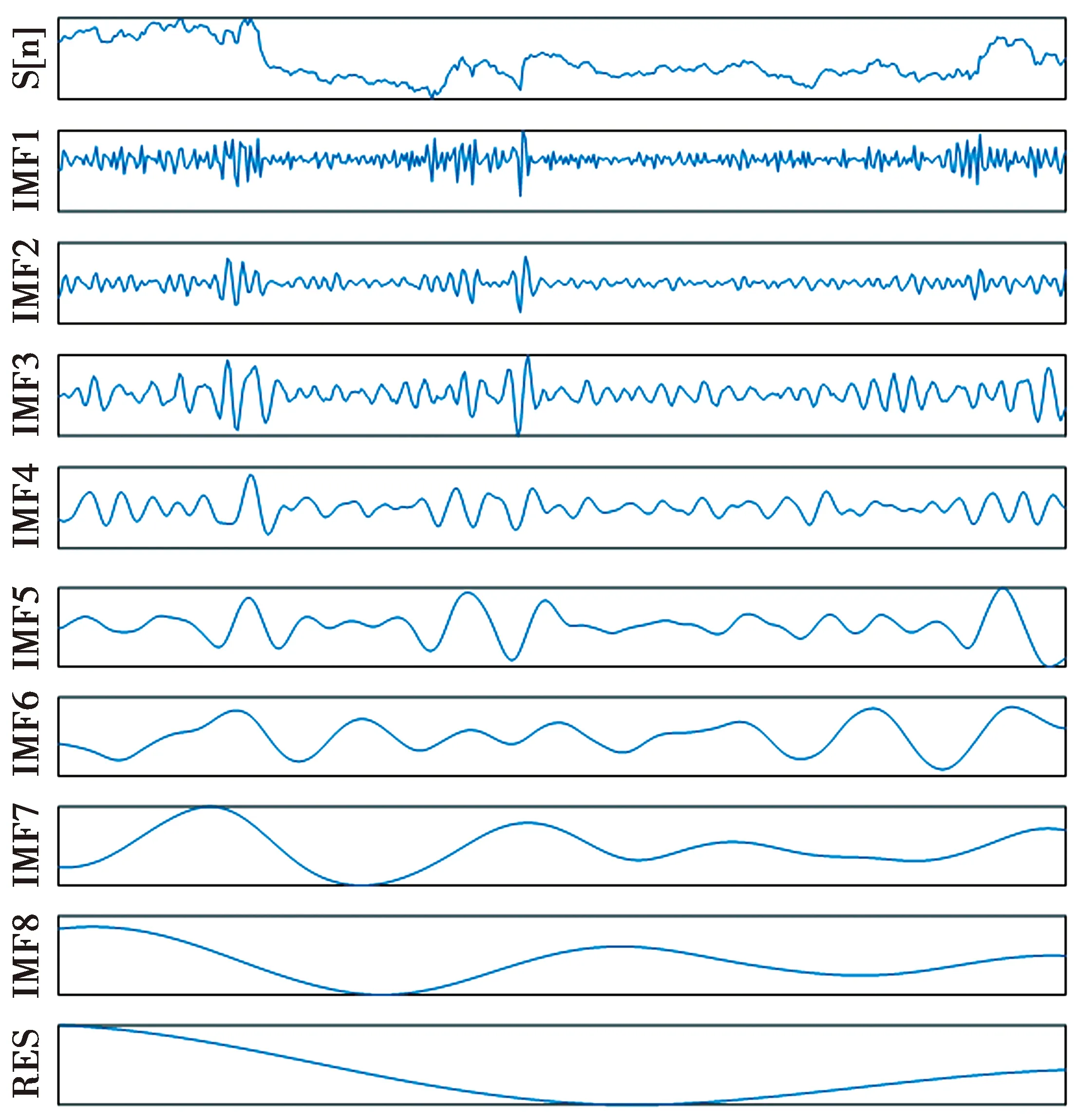
2.2 基于模态重构序列的整体评价因子
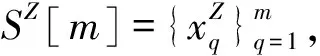
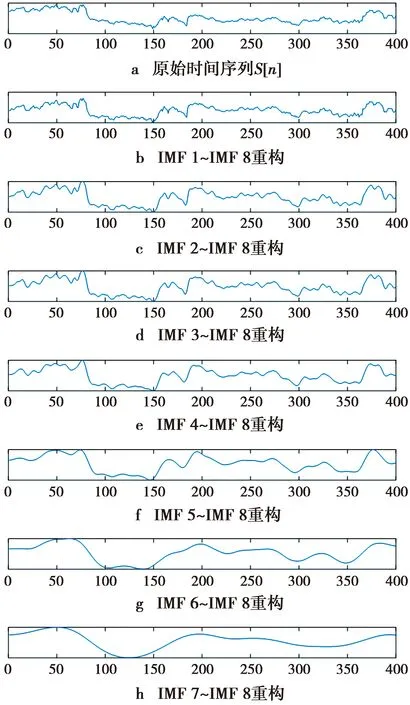
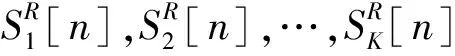
2.3 单点评价因子与局部评价因子
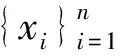
2.4 时间序列趋势提取算法
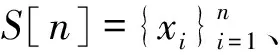
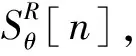
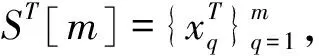
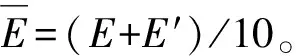
3 实验与分析
3.1 实验对比方法
3.2 数值仿真实验

3.3 实际应用实验
4 结 论
