类型感知的汉越跨语言事件检测方法
2022-10-26高盛祥余正涛陈瑞清
张 磊,高盛祥,余正涛,刘 畅,陈瑞清
(1.昆明理工大学 信息工程与自动化学院,昆明 650500;2.昆明理工大学 云南省人工智能重点实验室,昆明 650500)
0 引 言
事件检测是自然语言处理(natural language processing, NLP)的重要主题之一,目标是在纯文本中识别特定的事件类型。汉越跨语言事件检测就是在汉语和越南语上实现双语事件检测。
目前在汉越事件方面的跨语言工作还很有限,其涉及到跨语言语义表征问题。汉语语料丰富而越南语作为小语种语料稀缺、数据标注困难,且汉越同属孤立语系[1],既存在相似之处又存在明显的差异性,给汉越事件检测带来了挑战。跨语言事件检测方法目前还没有系统的分类,针对跨语言问题的解决大致有以下3类。
1)基于多语言多任务的方法。Alexis等[2]提出跨语言模型XLM-R,刷新了多个跨语言任务的记录包括跨语言事件检测,但是需要大量的语料,其中,越南语同样面临数据稀缺的问题,且模型较大需要很长的训练时间。Andrew[3]在多种语言上进行训练,利用依赖于语言的特征和不依赖于语言的特征提高跨语言事件抽取性能。
2)基于跨语言词向量映射的方法。Anders等[4]提出一个共享的、跨语言的向量空间,但仅仅只是跨语言词向量映射导致双语之间的语义粒度过大,在具体的任务上不能准确反映语言本身的层级语义特征。Ananya等[5]通过使用卷积神经网络(convolutional neural networks,CNN),将所有实体信息片段、事件触发词、事件背景放入一个复杂的、结构化的多语言公共空间,然后从源语言注释中训练一个事件抽取器,并将它应用于目标语言。
3)一般跨语言任务中还有翻译和对抗的方法。Guillaume[6]引入翻译系统桥接2种语言,但机器翻译模型需要大量的平行句对来训练,汉越上准确度还有待提升,且引入了噪声,如翻译错误和对齐错误等。Mei等[7]基于对抗学习自适应(adversarial based domain adaptation)通过判别器和生成器将源域和目标域数据在数据空间或者特征空间对齐,在目标域数据未标记的情况下学习域之间的映射,即学习语言不变性的特征,实现跨语言的域适应(domain adaptation)。而Yaroslav等[8]令对抗学习(adversarial learning)与领域自适应相结合,并提出了梯度反转概念[9],使得模型的训练不需要如同生成对抗网络(generative adversarial net,GAN)的复杂训练过程。
主流方法依赖人工标注数据和平行语料,对于越南语来说,只有少量汉-越平行语料,有标注数据稀缺,且人工标注代价昂贵。事件检测的许多先进模型严重依赖监督方法中的巨量有标签数据,由于没有足够的越南语数据作为统计学习模型的训练支撑,模型在越语上的性能往往不佳。
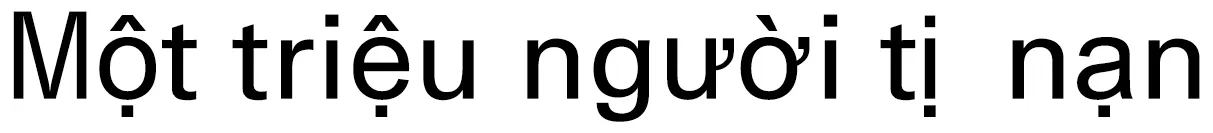
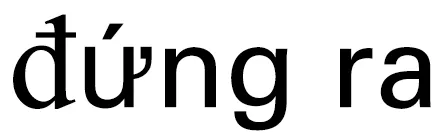
触发词被定义为词或短语,注释者需要从给定句子中严格标注“最清晰”的词,越南语由音节构词,音节可以独立使用,或组成多音节词,事件触发词的标注和识别存在歧义,使得越南语事件检测受限于多音节词歧义。
本文提出一种事件类型感知的汉越跨语言事件检测模型。采取语言对抗的方式训练大量有标注的汉语语料和无标注越南语语料,在汉语和越南语分布之间存在转移的情况下,训练语言鉴别器,迁移汉语中事件类型信息到共享的特征提取器中,因此,经汉语训练的分类器也可以用于越南语[10]。融合词位置、词性和命名实体信息,通过基于事件类型的注意力机制凸显事件相关词的语义贡献,探索在没有清晰定义触发词的情况下检测事件,模糊触发词对于事件类型的影响。
1 基于事件类型感知的特征提取网络F
每个事件类型都与某些词组相关联,准确捕获这些词的语义信息[11]就能更好地判断其到底更偏向哪种事件类型。本文任务中没有标注触发词,为了捕获这些词的语义信息,提出基于事件类型感知的特征提取网络,将词位置、词性和命名实体等信息与双语词向量拼接,即汉语和越南语的差异信息送入模型。通过多个二进制分类对该任务进行建模,给定一个句子,它将被放入所有候选事件类型的二进制分类器中,输入是
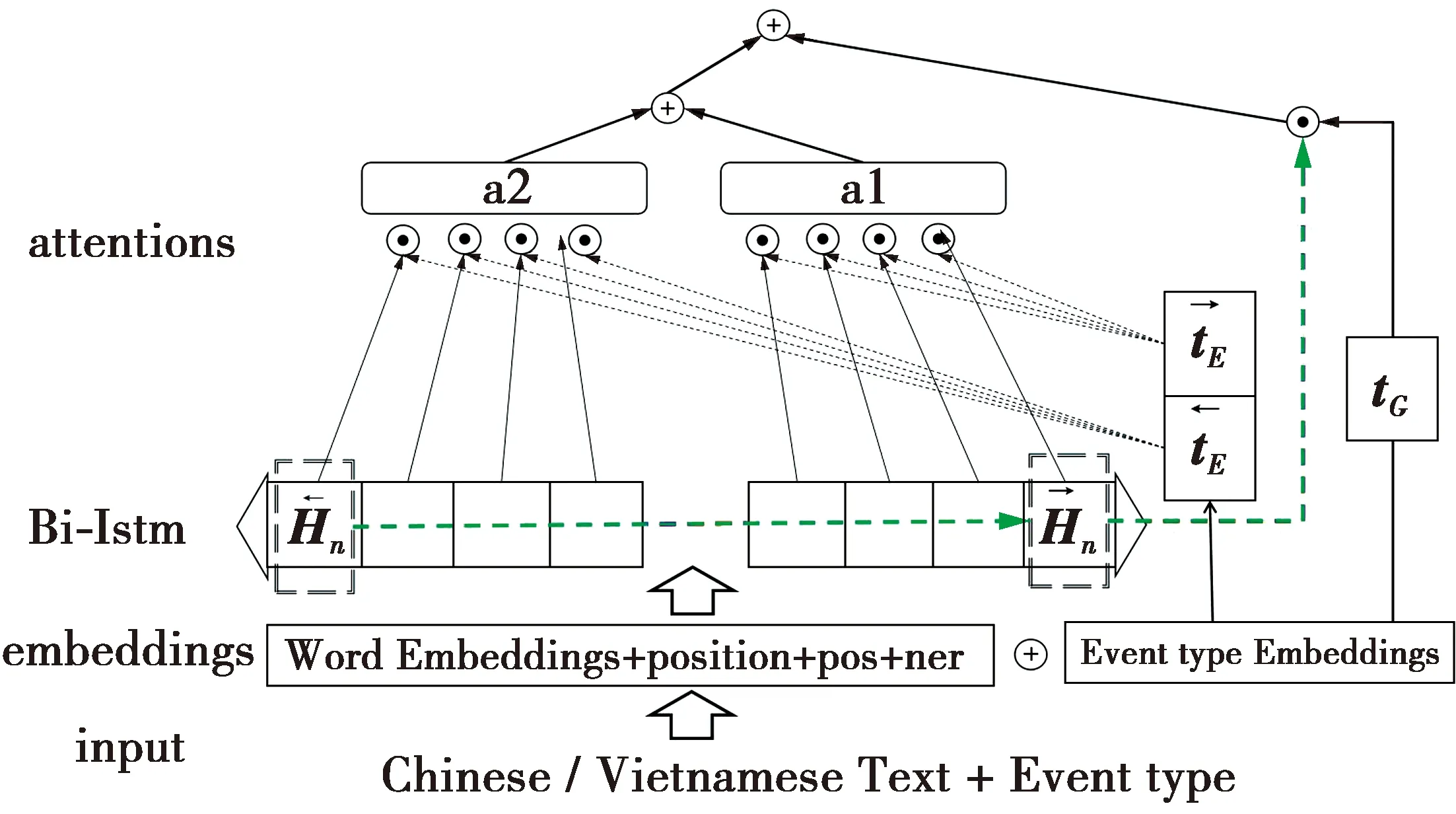
图1 事件类型感知的联合特征提取网络Fig.1 Joint feature extraction network for event type awareness
1.1 汉越双语词向量预训练
从大量未标记数据中学习的单词嵌入已经被证明能够捕获单词语义规则,本文中输入文档为单词序列X=w1…wn,其中每个wi由其词嵌入vi表示。由于汉越各自训练出的单语词嵌入向量矩阵C和V分布不同,需要找到最佳映射矩阵WC、WV,使CWC、VWV在同一语义空间下。使用Artetxe等[12]的无监督方法,结合自学习算法来逐渐优化映射矩阵W,将W约束为正交矩阵,即
WWT=WTW=I
(1)
在语义不变性情况下,汉越语义相同的词嵌入在公共语义空间中的距离更近,缓解汉语和越南语之间的差异,让跨语言模型更加健壮。并通过Stanford NLP得到汉越词位置、词性和名实体等信息扩充双语词向量。
1.2 基于Bi-LSTM的语义编码
长短时记忆网络(long short term memory,LSTM)[13]对依次输入的文本词嵌入,计算其上下文表示,使信息在其中持续保存,考虑词之间的依赖性,保留了诸如词顺序等重要信息,缓解了长期困扰循环神经网络的梯度消失或梯度爆炸问题[14-16]。而双向长短时记忆网络(Bi-LSTM)由一个前向LSTM与一个后向LSTM组成,某一时刻的输出由这两个方向上的状态共同决定,在具有记忆特性和顺序语义的基础上增加了捕捉逆序语义的能力,如图2所示。
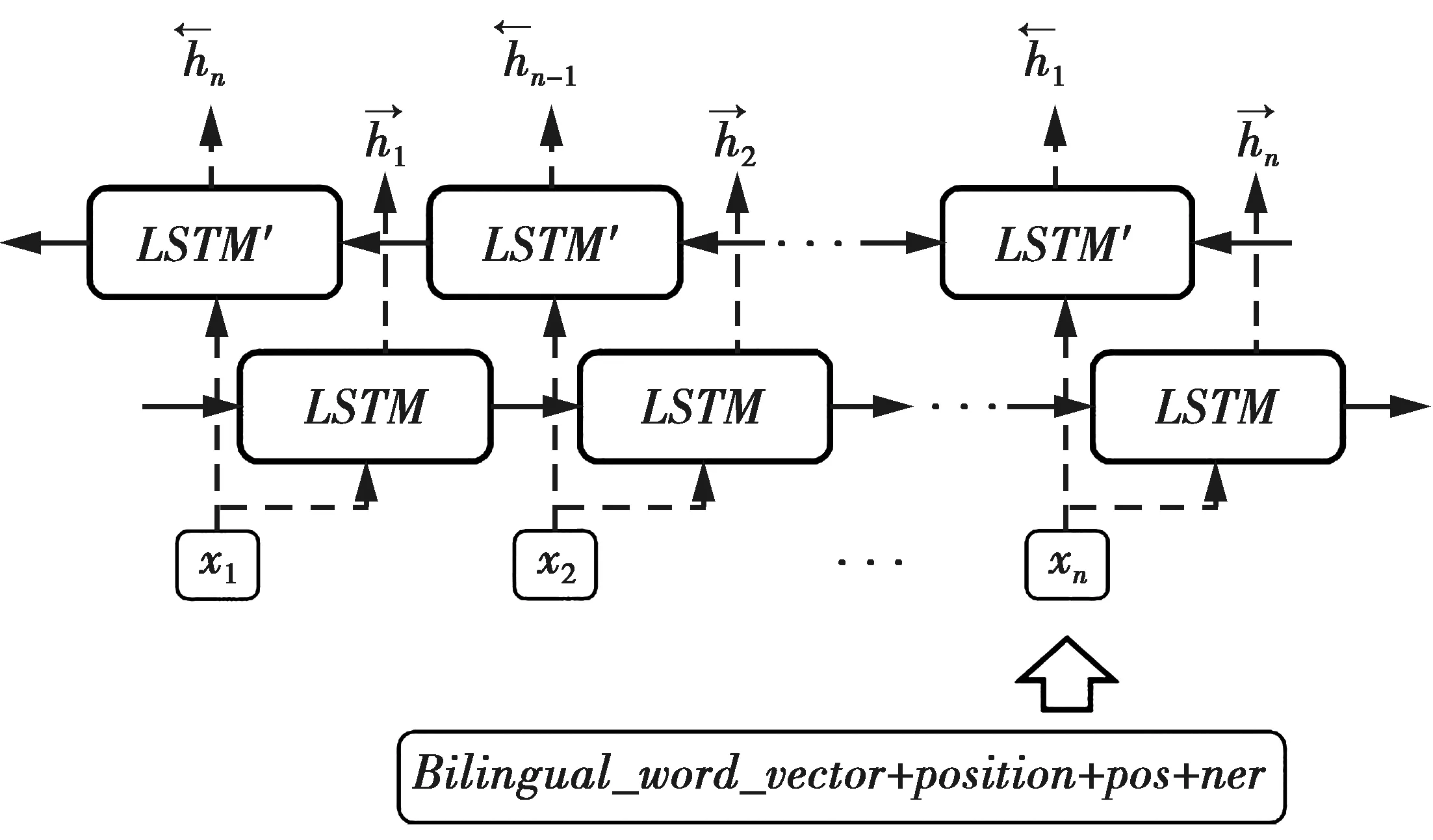
图2 Bi-LSTM结构图Fig.2 Bi-LSTM structure diagram
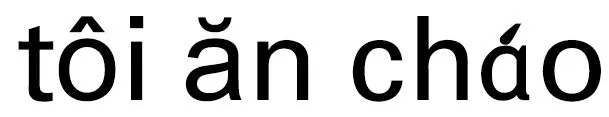
使用Bi-LSTM对输入的汉越词嵌入向量提取特征,输出2个方向的隐藏状态向量序列,越南语和汉语都存在与之相反的序列,不同于主流的正逆序列拼接再计算,注意力机制将分别依据2个事件类型嵌入矩阵对2个方向的隐藏状态序列计算注意力权重,减小2种语言的差异。
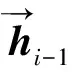
(2)
(3)
1.3 事件类型感知的注意力机制
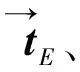
(4)
(5)
模型中,目标事件类型的相关词预计获得比其他词更高的注意力权重。句子的表示Satt为
(6)
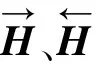
(7)
μ∈[0,1]是Satt和Sglobal之间权衡的超参数,输出定义为Satt和Sglobal的加权和:μ·Satt+(1-μ)·Sglobal。
2 汉越跨语言事件检测模型
模型由3部分构成:①前文构造的基于事件类型感知并融入词位置;②词性和命名实体等信息的汉越特征提取器F;③基于标准多层前馈网络的事件检测器P和语言鉴别器Q,如图3所示。
F旨在学习有助于预测事件分类器P的特征,并抑制语言鉴别器Q,而训练有素的Q无法分辨出F提取特征的语种,这个特征可以看作是2种语言共有的,即语言无关而事件类型相关的。在F和Q之间有一个梯度反转层,使F的参数在Q和P中都参与梯度更新,一个最小化P分类误差;一个是最大化Q分类误差。Q试图为汉语输出更高的分数,为越南语输出更低的分数,因此,Q是对抗性的。
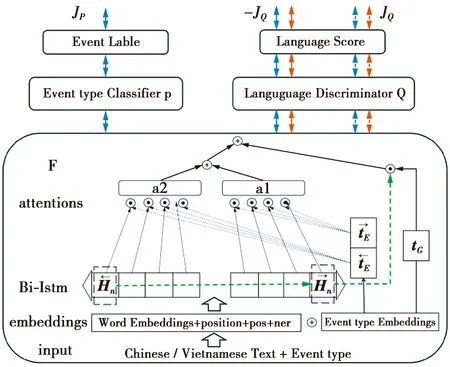
图3 越南语为目标语言的跨语言事件类型感知模型Fig.3 Cross-language event type awareness model with Vietnamese as the target language
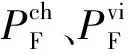
(8)
(9)
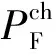
(10)
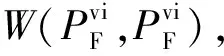
(11)
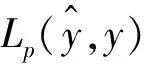
(1+y(i)·β)+δ‖θ‖
(12)
最后,由θf参数化的联合特征提取器F最小化事件检测器损失Jp和语言鉴别器损失Jq。
(13)
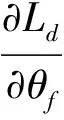
3 实验及结果分析
3.1 数据和模型参数
中国和越南新闻网站在2008—2020年,基于相似主题和板块爬取大量的汉越可比语料,汉语数据21万条,其中20万条为训练集,1万条为测试集。越南语数据143 061条为训练集,8 236条为测试集,对所有汉语语料和越南语测试集进行事件类型标注
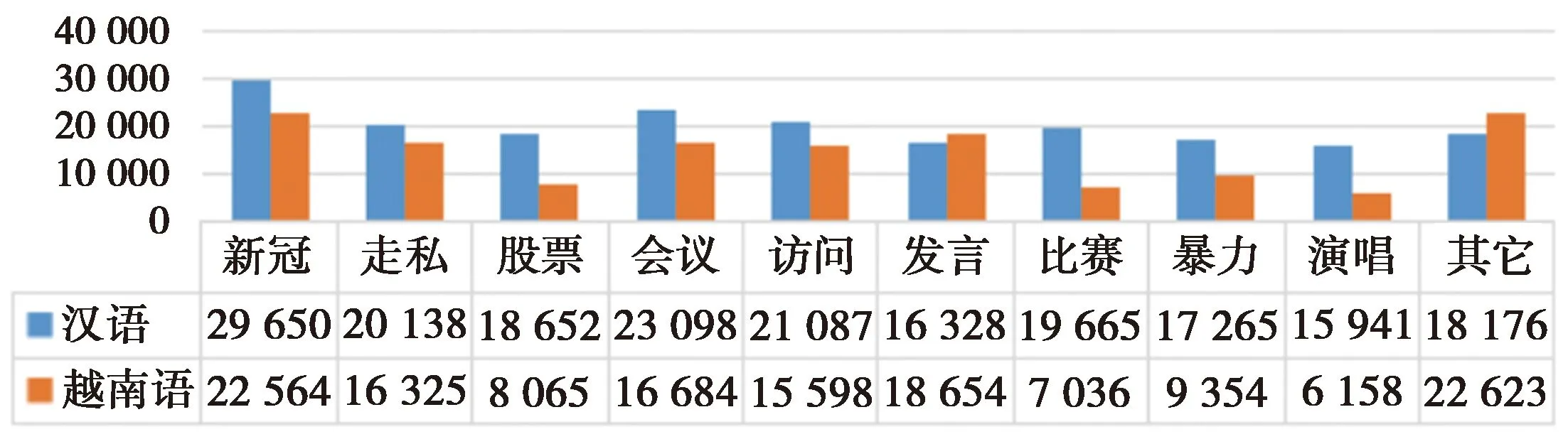
图4 汉越可比语料规模Fig.4 Chinese-Vietnamese comparable corpus scale
实验配置为window10、Python3.7、Pytorch0.4.0。本文汉语和越南语采用Pennington等[22]提出的Glove词向量初始化新闻文本,词向量维度L为 100,剔除词频小于5的词。为缓解过拟合现象,引入dropout用于事件检测器的全连接层。采用自适应矩估计Adam训练模型进行优化,它是一个基于随机梯度的优化器,具有自适应估计。
因为F和Q的训练可能不完全同步,在实践中观察到F比Q训练得更快,对模型的拟合速度和效果会产生一定影响[23]。所以每k轮训练将λ置为非零值一次。当λ=0时,Q的梯度不会反向传播到F,这允许Q在F进行一次更新之前进行更多的迭代次数以适应F。训练时设置了2个学习率:①Q的多次自迭代lr1;②Q和F的共同训练lr2。
3.2 评价指标
使用准确率P、召回率R和F1值衡量模型是否可以正确分类汉越双语新闻文本所属事件类型。TP是所有含事件的文本中被正确检测出数量,FP是检测出事件的文本中错误的和实际不含事件的数量,FN是检测出不含事件而实际含事件的数量。P是所有的文本中正确检测出事件类型的比例,R是正确检测出事件类型的占实际含有事件类型的文本的比例,F1是P值和R值的一个综合度量值。
(14)
(15)
(16)
3.3 对比模型实验
实验评估有7个模型,如表1所示。
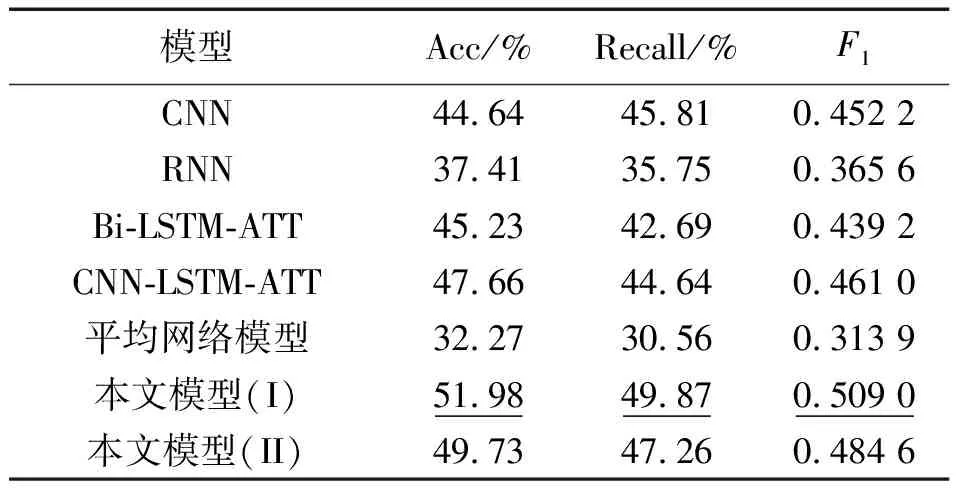
表1 不同联合特征提取网络对比实验结果Tab.1 Comparison of experimental results of different joint feature extraction networks
1)本文模型(I):本文提出的基于类型感知的汉越跨语言事件检测模型。
2)本文模型(II):本文提出的基于类型感知的汉越跨语言事件检测模型,未扩展融合位置、词性和命名实体信息。
3)平均网络模型:将事件类型感知的联合特征提取网络替换为平均网络。
4)Bi-LSTM-ATT:Zhou等[24]根据位置特征扩充字向量特征, 通过多层注意力机制, 提高LSTM模型输入与输出之间的相关性。
5)CNN:Zeng[25]首次提出用卷积神经网络从多个level提取词语和语句级别的特征,并进行了一层简单的卷积处理,来精简参数量并保留关键信息。
6)RNN:Wang[26]使用双向RNN网络,但两个方向的信息不是拼接,而是相加。
7)CNN-LSTM-ATT:吴汉瑜等[27]结合CNN与LSTM的优点,能够捕获不同层次的关键模式信息和全局结构信息并对它们进行融合。
由表1可知,平均网络就是对输入文本的向量序列各取平均,这是最基本的特征提取方式,由于不区分各词向量之间的重要程度,事件检测的准确率只有32.27%。RNN取得除平均网络外最低的准确率和F1,而CNN能捕捉局部相关的关键信息,同时不存在RNN的梯度消失和梯度爆炸问题,相比于RNN取得了6.23%的提升。Bi-LSTM-ATT解决了RNN存在的问题,加上使用了注意力机制为不同的信息分配不同权重,较CNN获得了1.59%的提升。CNN-LSTM-ATT同时具有循环神经网络可以提取文本的全局结构信息,卷积神经网络局部特征提取和注意力机制的优点,准确率达到了47.66%。
本文模型准确率相较于CNN-LSTM-ATT和Bi-LSTM-ATT得到了2.07%和4.5%的提升。分析原因,虽然CNN-LSTM-ATT和Bi-LSTM-ATT都使用了注意力机制,但都是无外部信息的自注意力,没有利用事件相关信息,输入文本的词向量之间的权重分配依据文本自身。而本文中基于事件类型信息的注意力机制根据重要的事件类型等外部信息,指导句子中的词获得占比权重,即结合事件任务特性学习句子向量特征。在扩展词位置、词性和命名实体信息后,准确率达到了51.98%,表明模型不仅可以获取句子内部特定事件和词之间的依赖关系,也可以捕获更多有利于检测事件的相关的特征信息。
为了验证在没有标注触发词下模型仍然能有效利用事件相关词的语义信息来检测事件类型,设置1个正类、3个负类事件类型标签(暴力、走私、会以、演唱),让模型输出如下2个例句的注意力权重热力图,如图5所示。
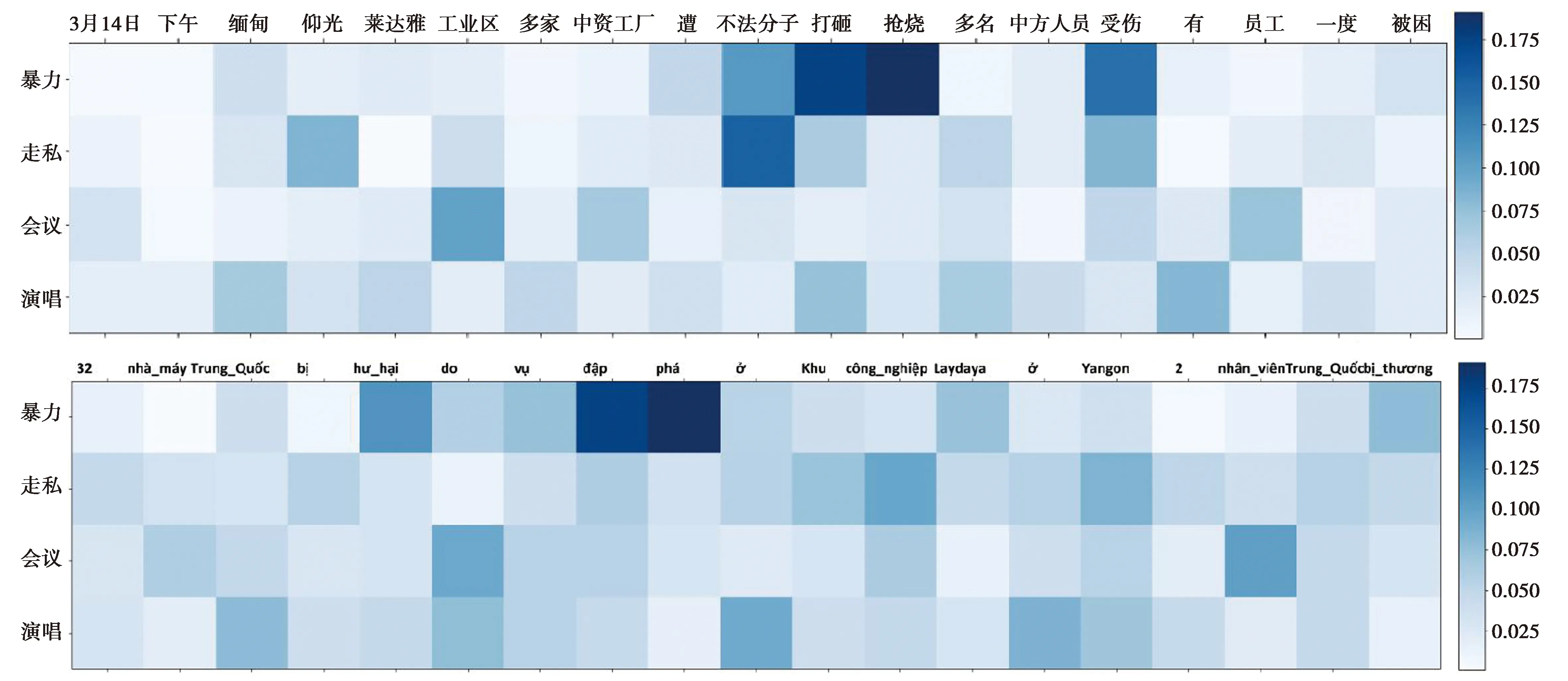
图5 例句中词的注意力权重Fig.5 Attention weight of words in example sentences
S2:3月14日下午,缅甸仰光莱达雅工业区多家中资工厂遭不法分子打砸抢烧,多名中方人员受伤,有员工一度被困。
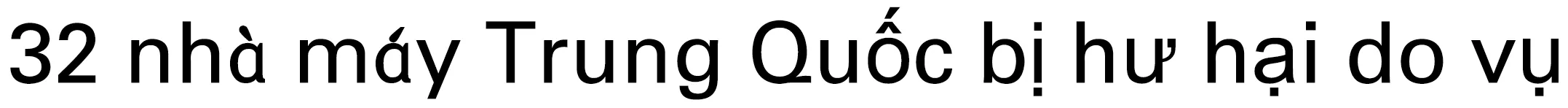
3.4 语言对抗训练的有效性
语言鉴别器的对抗训练实现了汉越的跨语言事件检测,为进一步验证模型跨语言的有效性,验证模型通过大量有标签汉语与无标签越南语对抗训练。
提升越南语事件检测准确率的效果,与去掉语言鉴别器的实验作对比,添加汉语验证集,从第5轮到第30轮的迭代次数中对比汉语事件检测和越南语事件检测准确度提升情况,结果如表2所示。
由表2可知,在没有语言对抗的实验中,应为训练集中有事件类型标注,汉语事件检测的准确率随着多轮迭代得到大幅提升,而越南语没有标注,事件检测准确率提升几乎没有。在语言对抗的实验中,通过汉越语言的对抗训练,越南语准确率得到明显提升,在30轮后较无语言鉴别器的情况提升0.319,证明语言鉴别器的对抗训练的确有助于无标签越南语事件检测的准确率提升。
同时在汉语语料规模不变的情况下,探究无标签越南语料规模对模型性能的影响,使越南语数据从5万到14万,每增加1万验证模型在越南语事件检测的准确率,如表3和图6所示。
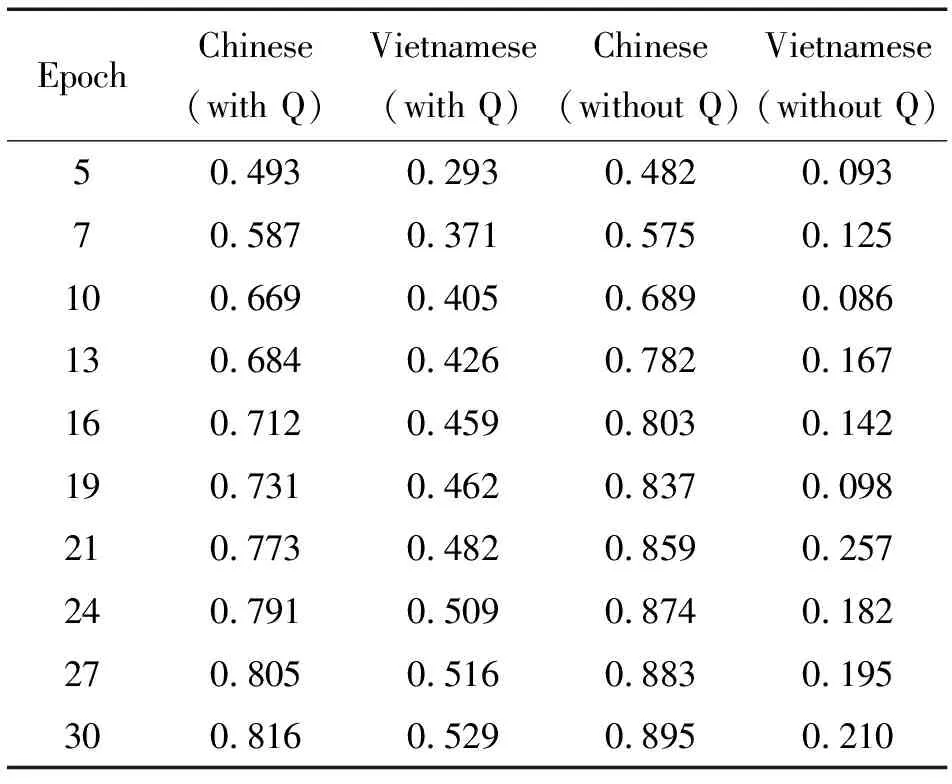
表2 语言对抗对准确率的影响Tab.2 Impact of language discriminator on accuracy

表3 无标注语料规模对准确率的影响Tab.3 Impact of unlabeled corpus size on accuracy
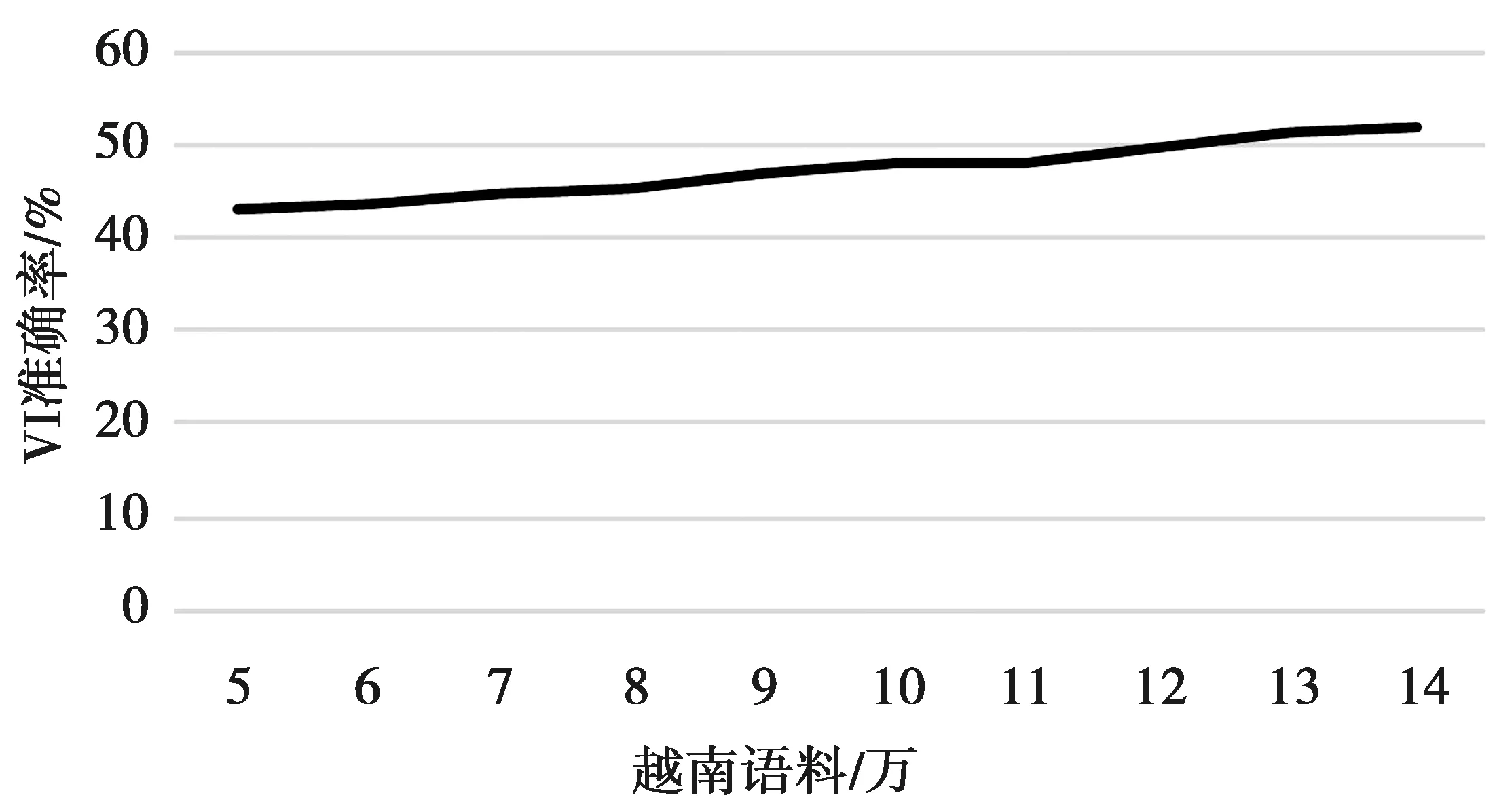
图6 越南可比语料规模与准确率Fig.6 Comparable corpus scale and accuracy rate in Vietnam
由表3可知,14万的越南语无标签语料比5万在准确率上提升了0.086 9,且由图6可知,在目前的10万级语料下,越南语料的规模与模型准确率呈正相关,而无标签的汉越可比语料获取相对容易,可以通过构建更多的汉越可比语料来显著提升跨语言事件检测模型的性能。
3.5 模型训练关键参数对性能的影响
本文模型中协调训练的参数k对实验结果影响较大。遂通过评估不同参数数值对越南语事件检测准确率的影响,分析参数特性以实现模型性能最好。实验中模型迭代至第30轮,其余参数相同。验证k与越南语事件检测准确率的关系,如图7所示。
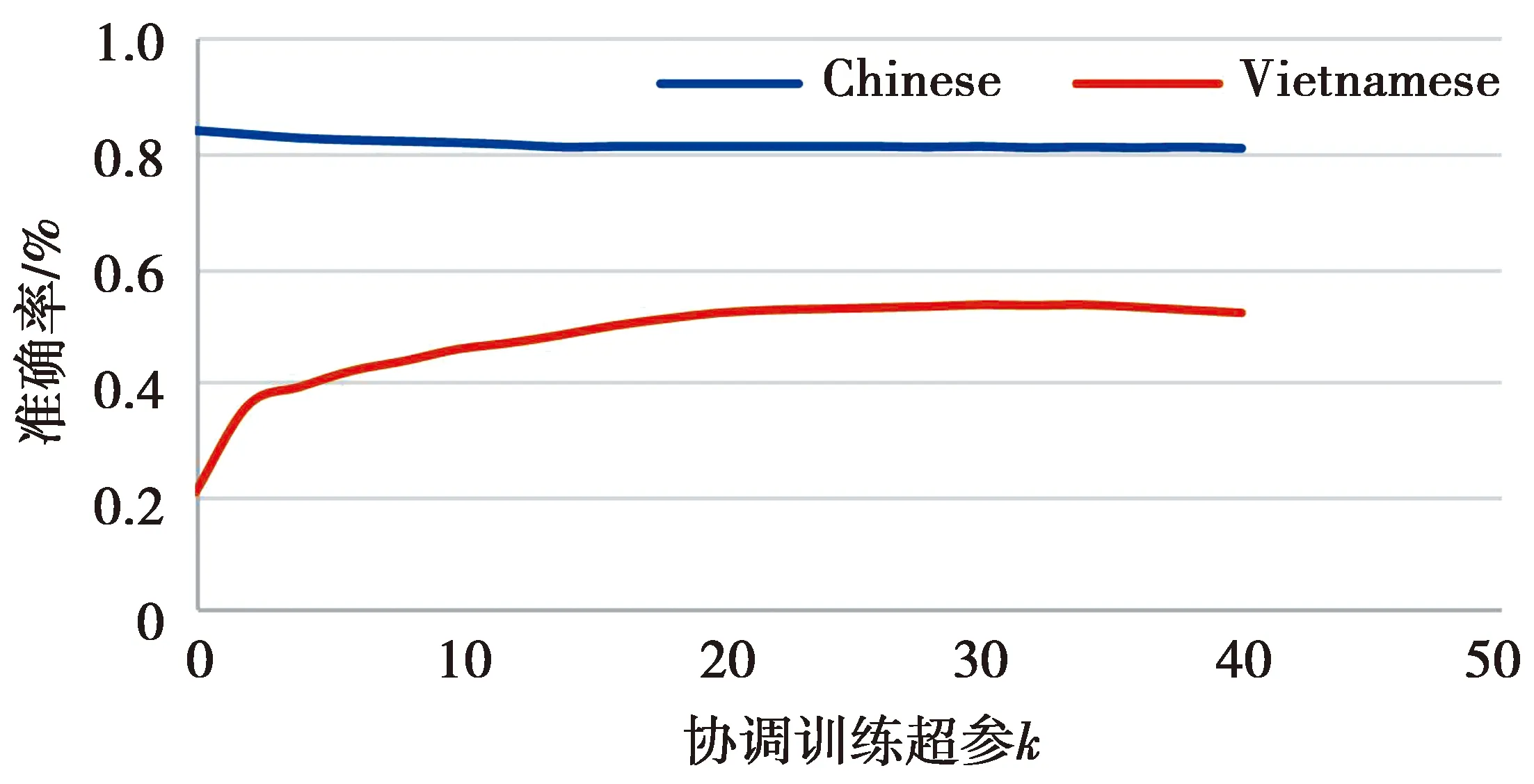
图7 参数k对汉越事件检测准确率的影响Fig.7 Influence of k on the accuracy of C-V incident detection
由图7分析可知,随着k的增大汉语的准确率几乎无变化,而越南语的准确率则提升明显。协调训练的参数k表示每k轮次训练中只有一次Q的梯度能反向传播到F,即模型中一条汉语有标签语料训练一次,相应就有k对汉越可比语料输入了语言鉴别器Q进行对抗训练。分析k变大对于每条汉语的有标签学习无影响,所以汉语准确率不受k影响,但同时让更多汉越可比语料进行了语言的对抗训练,加强了有标注汉语信息向越南语训练模型的参数迁移能力,使得无标注越南语的准确率提升。
但过大的k会让模型参数量翻倍,对模型收敛速度、内存和加速显卡的显存容量十分不友好,可以看到,当k值达到并超出[20,30]后出现了下降的趋势。所以本文将k置于一个既能使汉语标注信息充分向越南语训练模型传递,又能使模型收敛速度不太慢,同时目前硬件条件能满足的大小。模型中其余参数经过验证皆为最优,如表4所示。
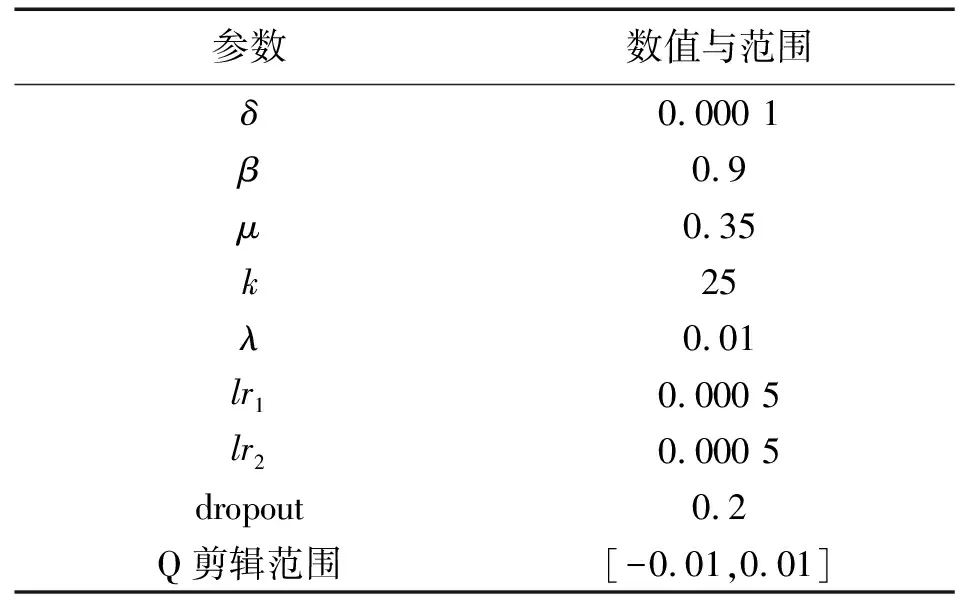
表4 模型的超参数Tab.4 Hyper parameters of the model
4 结束语
本文提出一种基于事件类型感知的汉语跨语言事件检测模型,利用丰富的汉语语言信息提高了越南语事件检测的准确性,缓解了越南语数据稀疏的问题,并通过基于事件类型感知的特征提取网络,模糊处理事件触发词,缓解了传统方法中单语歧义性和触发词局限性等问题。实验表明,将事件类型等语言无关而使事件相关的语义信息融入特征提取阶段会使跨语言事件检测性能有所提高。
