基于层次异构混合GNN模型的多视角头盔佩戴鲁棒检测方法
2022-10-25卢建刚李波林玥廷赵瑞锋李德忠吴迪
卢建刚,李波,林玥廷,赵瑞锋,李德忠,吴迪
(1.广东电网有限责任公司电力调度控制中心,广东 广州 510600;2.湖南大唐先一科技有限公司,湖南 长沙 410000;3.同济大学 电子信息与工程学院,上海 201804)
在工程类作业中,工作事故通常是由作业人员未执行有效防护措施导致的,其中包括未正确佩戴防护设备[1-2]。对建筑、电力等行业而言,安全头盔对施工人员头部起到重要防护作用[3-4];然而,由于头盔佩戴不正确引发的安全事故屡见不鲜。为预防此类安全事故,保障从业人员的人身安全,开发一种自动识别作业人员头盔佩戴不当的系统具有重大意义[5]。
近年来,深度学习领域研究发展迅速,已被广泛应用于生产生活各个领域,例如医学图像、人脸识别等。在工程类安全防护领域,一些专家学者研究头盔佩戴识别技术,如利用反向传播神经网络和小波变换方法识别头盔,依靠头部与脸部位置关系提取特征[6];但此类方法难以保证复杂环境下的检测效率,因此部分学者研究基于目标检测像素的颜色来识别头盔[7]。最近,大量研究开始采用卷积神经网络进行头盔识别,但图像特征仅可识别头盔形状和颜色,对磨损头盔的识别精度低。为解决此类问题,研究者尝试将深度学习和目标检测结合,如区域卷积神经网络(R-CNN)[8],通过分层提取图像特征,实现高精度目标分类,由此可极大降低时间和空间复杂度。然而,该方法仍存在问题:对于同来源图像样本,可有效进行识别;但对于不同来源的图像样本,其训练和检测性能较差。该方法忽略了多视角图像间的相关信息,不能准确估计多源样本的视觉相似度[9]。在施工和供电作业中,管理人员通常将监控摄像机以不同的视角布置于不同的方位,即针对同一作业区域,从不同监控视角拍摄不同画面。为提高识别效果,一些研究通过学习区分特征或不同图像标志距离测量,测量不同视角图像间的相似度[10];但此类研究仅考虑不同图像表面的整体相似度,忽略了内部相似度[11]。例如在估计探测图像和目标图像间相似性时,大多数特征学习和深度学习方法仅训练和检验单个图像对的成对关系,而忽略了来自不同图像源之间的关系。为解决该问题,需从高价值的图片中寻找差别[12]。
头盔检测场景多是基于视频检测来实现的,较静态图像目标检测而言,由于目标运动,其外观、形状、尺度等属性处于不断变化的状态。在视频检测过程中,如何保持目标在时间序列上的一致性,避免目标在帧中丢失,是视频目标检测任务的难点,具体包括运动模糊、虚焦点、遮挡、外观变化、尺度变化等相关挑战[13]。在计算机视觉领域中,高斯混合模型(Gaussian mixture model,GMM)的首要应用就是前景检测[14-16],其既具良好稳定性,又可自主学习;因此,首先选择工人工作环境背景图像,然后利用GMM对背景图像中的每个背景进行仿真。在实验过程中,对新图像进行GMM匹配,当图像像素值达到匹配要求后,由计算机区分出背景和前景图像。GMM通过属性概率分类不断更新,保证在动态背景下的鲁棒性。需注意的是,在监控视频中连续使用前景分割方法,通常存在部分噪声;因此,本研究采用形态学操作函数[17]以消除噪声,弥补检测对象的不足。
针对监控视频中因维数变化导致的目标识别与跟踪困难,本研究采用目前使用最为广泛的GMM[12]对工人作业过程的视频图像进行前景分割,提取复杂背景下的目标。为有效检测不同视角下工作人员的头盔佩戴情况,采用分层神经网络,具体包括基本序列编码器、层次注意力模型和最终预测层3个部分,其中:基本序列编码器致力于不同视角下各图像关键特征的获取,通过连接问题标签和各个图像节点标签,将问题和图像表示为1个序列;层次注意力模型用于完成图形构造任务,包括基于不同层次节点间的不同连接,设置不同选项来表示图像检测结果;最终预测层用于执行非监督预训练,可有效关联不同视角图像的结构信息,从而学习多视角图像中的增强特征,提高算法鲁棒性。
1 HGNN模型
本章阐述不同视角下头盔佩戴检测的层次图神经网络(hierarchical graph neural network,HGNN)。所提出的HGNN由3个模块组成:基本序列编码器、层次注意力模型和最终预测层,其体系结构如图1所示。
图1展示了如何用图像表示2个不同视角下的图像(s1、s2)和1个特殊的图像节点(h1),将图像数据输入到第i个节点Ni,其上标为该节点上的图像数。将目标图像(ground truth)表示为Nq中的特殊节点,q为特殊节点的标识。图1中左边部分为改进的注意力机制,用于获取每个图像的结构信息内容(即图像的标签)。设置一些特殊的标记来表示识别任务()。中间部分为HGNN块,利用图像间连接和所有视角的图像连接来构建图像的图层次结构,并对图像节点(绿色)和待检测图像节点(紫色)进行预测。右边部分为连接掩码矩阵(在GNN中称为相邻矩阵),表示连接图中的不同标签。
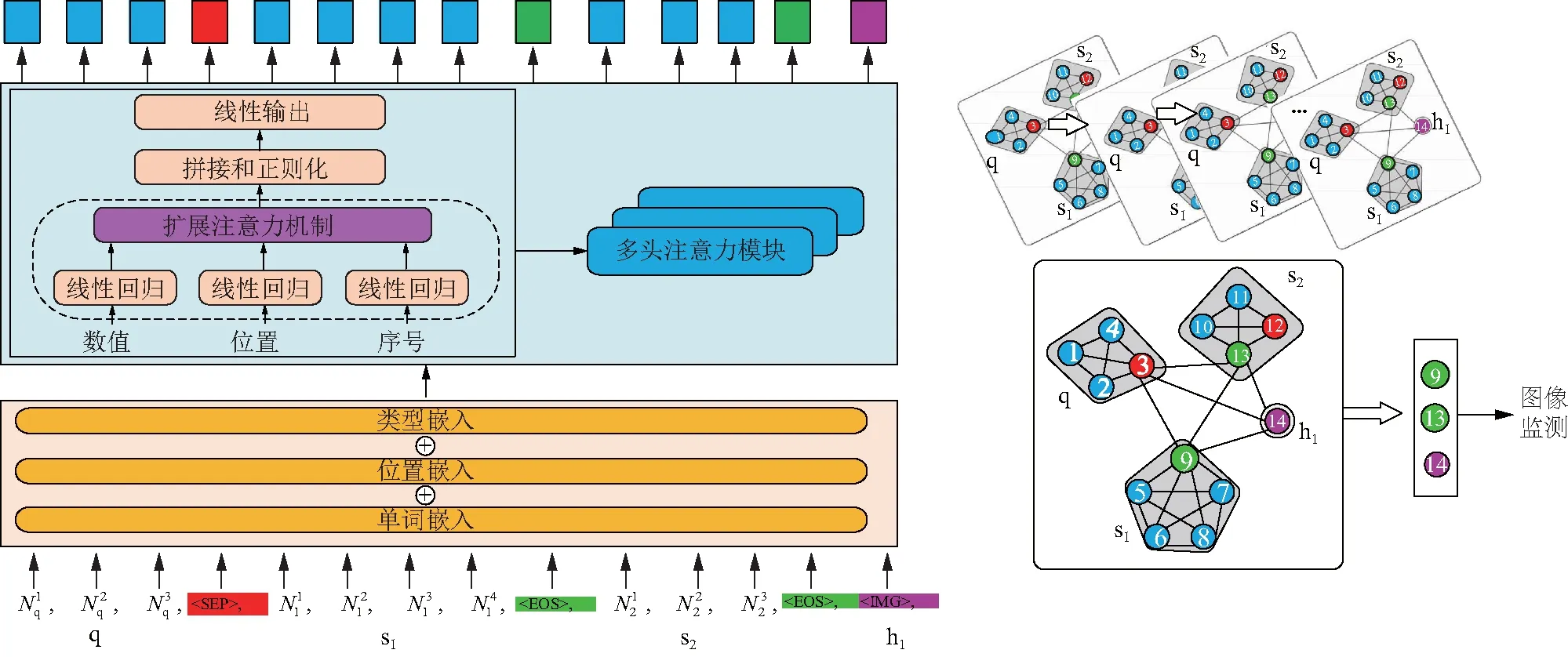
图1 所提出的HGNN
1.1 基本序列编码器
基于基本序列编码器获取不同视角图像的关键特征,通过结合问题标记与图像节点标记,将问题和图像表示为序列。对每张图片添加1个特殊的特殊标记来表示[18]。
1.1.1 嵌入层
采用字节对编码将图像作为序列片段进行平铺[19]。设序列长度为M,维度为D,对序列中每个词块,使用转换方式得到词层嵌入Hs∈RM×D,其中下标s表示嵌入的大小。采用位置嵌入法得到序列的位置嵌入Hr∈RM×D,其中下标r表示位置的不同。使用生成方式得到图像序列中的类型嵌入Ht∈RM×D,其中下标t表示它是否存在于噪声图像中。最终嵌入式的输出为3个嵌入式的总和H0,即
H0=Hs+Hr+Ht.
(1)
1.1.2 自注意力层
将Transformer[20]层基于自我注意的方式应用于输入,Transformer块列表用来将输入内容嵌入到不同视角的图像结构信息中[21]。
1.2 层次图神经网络
设置不同的图像节点嵌入在HGNN中,以序列编码器的最后一层输出对其进行初始化,并以层次图表示。从形式上讲,HGNN是以通用消息传递架构为基础,即
Hk=f(A,Hk-1;Wk).
(2)
式中:Hk∈RM×D、Hk-1∈RM×D分别为第k、k-1次迭代后层次图中的节点嵌入;A∈RM×M为表示图结构的相邻矩阵;Wk∈RD×D为第k次迭代后不同图层的可训练参数;f(·)为信息聚合的消息传播函数。本研究中,HGNN的逐层传播规则为
(3)

1.2.1 图形构造
图形构造是HGNN取得良好性能的重要因素之一[23-24],本研究讨论2种图形连接,即同视角图像连接与不同视角图像连接。
a)同视角图像连接:相同视角图像中的每一幅影像均连接在一起。具体地,
(4)
b)不同视角图像连接:为每幅图像都添加特殊标记,以作为高级节点标识,继而为图像中的这些特殊标记添加异视景图像连接。若节点的相应注释属于
(5)
在多视角的图像识别中,精确的目标检测非常重要。但是,在这种链接中,图像之间的交互都是基于节点标记的,仅使用不同视角的图像链接,会加重基于注意力模型的建模负担[25]。建立图像识别
(6)
1.2.2 信息汇总
完成图的构造过程后,根据式(3)建立图的结构形式。由于GNN中图是分层的,且包含了具有不同连接的、不同层次的节点,因此使用如下2种方式。
a)管线式聚合:用于在管线中构造层次,先构造低级句内内容,再构造高层句间内容和全局信息,即
(7)
式中:各变量符号下标intra、inter、global分别表示外部嵌入、内部嵌入和全局的节点,上标“~”表示矩阵与单位矩阵I相加,例如Hk,intra、Hk,inter分别为第k次迭代后的外部、内部嵌入,Wk,global为第k次迭代后的全局模型参数,其他符号的含义以此类推。
b)融合式聚合:管线式聚合以层次化的方式构造图形,同时可通过将3层相邻矩阵融合成1个矩阵(此矩阵包含了A及Aij等)来对其进行操作,矩阵中元素
(8)
在融合相邻矩阵基础上,建立式(3)的图像结构信息。
1.3 预训练层
用HGNN表示不同视角的图像后,收集相同视角的图像节点并进行预测。其中包括
Pi=σ(Hk,iWo),i∈S.
(9)
式中:Hk,i为第k次迭代后节点i的嵌入;σ为Sigmoid函数;Wo为将HGNN的最后一层信息投影为标量值的权重向量。
该模型的目标是最小化预测与实际标签之间的二元交叉熵,即
LBCE=-li∈SPlg(Pi∈SP)-li∈SNlg(1-Pi∈SN).
(10)
式中:LBCE为HGNN模型损失函数;SP为图像中正常节点集,SN为图像中异常节点集,SP∪SN=S;Pi∈SP、li∈SP分别为属于SP的节点i的概率、损失函数;Pi∈SN、li∈SN分别为属于SN的节点i的概率、损失函数。
近年来对图像检测的研究表明,大规模预训练有很大优势[26-27];然而,与以往基于图像为输入的预训练方法不同,本研究所讨论的是在不同视角下的图像结构信息。
2 实验
2.1 数据集与设置
本研究使用的数据集为Datafountain数据集中的头盔分类数据集[28](下载地址https://www.datafountain.cn/competitions/304/datasets),包含头盔的地面真值标签。数据集包含所有正样本和负样本,其中训练数据集9 800张,测试数据集9 000张,均为摄相机采集。
实验同时采用了DenseNet[29]模型、R-CNN和Fast R-CNN等方法检测并与本研究所提方法进行结果对比。
实验平台采用Intel Core i7-8750h处理器、NVIDIA Geforce GTX 3080显卡、16 GB内存,操作系统为ubuntu18.04,编程语言为Python,深度学习框架采用Tensorflow2.0gpu版本[30]。
2.2 回归分析
2.2.1 关系分析
对于检测到的人脸位置与对应的头盔位置,随机选择1 000个样本,绘制如图2所示散点图,并探究二者之间的相关性。图2中:x为边界框在x轴方向的位置;y为边界框在y轴方向的位置;w为边界框的宽度;h为边界框的高度;用下标D表示检验人脸边界框,G表示头盔边界框。这些图叠加后呈现光滑的线性拟合曲线,表明人脸边界框的平滑参数与头盔边界框的平滑参数之间存在线性相关性,特别是在相同检测条件下的参数,例如人脸边界框、头盔边界框在x轴方向的位置xD和xG。

图2 边界框平滑参数散点图
此外,利用多元线性回归来探讨头盔边界框平滑参数与被检测人脸边界框平滑参数之间的关系(包括xD),然后用F检验、t检验和R2相关检验来检验这些回归函数。其中,F检验反映总体显著性,t检验反映各自变量的显著性。这2个测试通常依据所得到的样本观察极端结果出现概率(p值)进行判断:如果p值小于0.01,表示头盔边界框平滑参数与检测到的人脸边界框平滑参数之间存在显著关系。R2相关检验用于判断回归方程的拟合程度,其值在0~1之间,越接近1,拟合度越好。针对上述1 000个数据,构造多元线性回归模型,验证头盔边界框平滑参数与被检测人脸边界框平滑参数之间的关系。平滑参数的相关性见表1,表中的p值和R2值表明,人脸边界框和相应头盔边界框之间,不同图形平滑参数的线性相关关系的假设是可行的。

表1 人脸与头盔边界框平滑参数的相关性
2.2.2 交并比性能
使用交并比(intersection-over-union,IOU)指标[31]来演示头盔检测的模型性能,检查推理结果与真实值之间的IOU值是否大于给定的阈值:如果大于阈值,则头盔将被识别为“未正确佩戴”。通常,当头盔的预测边界框和它的地面真值框重叠不小于0.5时,IOU被认为是“检测成功”。
以IOU指标为基础,从公开数据中随机选取若干头盔佩戴者,并对这些头盔的所有IOU值进行计算。
如图3所示,选取不同视角拍摄获得的测试图像,其检测结果会显示基于回归分析的头盔边界框和精确值。所提模型在检测头盔边界上的平均成功率为96.41%,表明该模型能够准确地计算头盔边界框,为头盔检测提供了良好的参考范围。如图3中左图所示,当识别精确值为0.08时(白框所示),则识别为“头盔未正确佩戴”。精确值越小通常意味着佩戴头盔的旋转角度大,表明工人未正确佩戴。

图3 测试图像准确值
2.3 模型训练
此节讨论如何通过所提模型获得网络参数的实现过程。配置超参量和训练网络通常是复杂且耗时的,为提高检测精度,采用dropout、自适应学习率、正则化和提前停止法等方法对所提模型进行训练。
在对模型进行训练时,首先加载权重参数,然后按照模型初始化方法,初始化模型中最后一层参数。模型训练的参数设置为:优化器分别采用随机梯度下降法和Nesterov法,学习率初始值设置为0.01,批处理设定为128。图4展示了所提模型的损失函数曲线,随着迭代数的增加,训练集中损失值开始迅速减小,并且逐渐收敛。

图4 损失曲线
2.4 鲁棒性
利用图像特征在多层网络中的可视化应用来评价模型鲁棒性,并将所提模型和DenseNet模型中的第1层和第2层的特征图进行了比较。图5显示了不同佩戴角度的头盔图像的详细结果,图中每幅特征图的图像包含64个特征点,与DenseNet模型相比,所提模型的大部分特征点(如图5中第1行第1层的前2个特征点)清晰度更高,包含的特征点更多(如图5中第1行第2层的22个特征点)。可视化结果表明,2个模型之间的特征区分有助于提高模型鲁棒性。进一步采用方差和熵对2种模型在不同视角下对图像的鲁棒性进行定量评价。通过区分图5中所有特征映射计算的方差和熵值,可清楚看到所提模型对图像的区分特征更加清晰,表明所提模型在不同视角图像的处理上具有鲁棒性。

图5 模型不同网络层特征图
2.5 检测效果
不同视角下拍摄的图像存在相互融合、尺度变化、透视畸变和小目标检测等问题;因此,对源自公共测试数据集的大量图像进行不同模型的测试,为头盔检测提供可信度(例如置信度0.8表示边框中头盔的概率是80%)。在头盔的置信度大于置信度阈值的情况下,可以对其进行识别,从而确定头盔与非头盔的等级。对正、负样本分别采用不同的置信度阈值进行分类,其分类效果可以使用精准率-召回率曲线(PR曲线)进行评估。所提模型的PR曲线如图6所示(其中包括Densenet、R-CNN、Fast R-CNN的PR曲线)。通过图6的基本阈值线判断出,所提模型平均检测精准率最高,为0.985。为达到精准率和召回率的双赢效果,可以选取图6中PR曲线和基本阈值线的交点作为置信度阈值,则召回率为0.962。与Fast R-CNN相比,所提模型精准率提高了0.8%,召回率提高了2.8%。

图6 不同模型的PR曲线
2.6 模型可解释
模型的可解释性有助于了解其决策过程,为此使用类激活映射(class activation mapping,CAM)方法生成图7。本研究仅选择了模型中第1个节点(Node 1)和随机选择的节点(Nodei),并展示它们的关联效果(第1行)。图7竖行中,第1列显示的是头盔图像的CAM图,第2列(Colored CAM)显示的是彩色CAM图,第3列(CAM+original)显示的是带彩色CAM图的原始图像,其中最右边的色条表示模型所检测到的头盔差异程度,即暖色表示差异大,便于区分头盔边界。
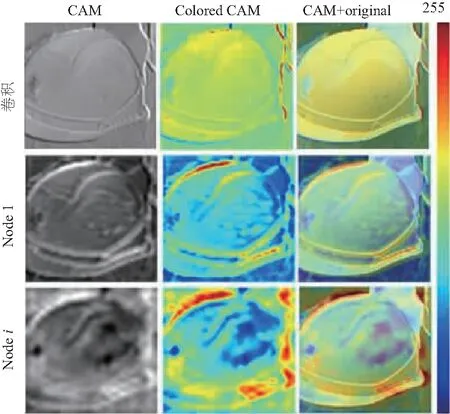
图7 CAM可视化
3 结束语
本研究提出了一种基于层次异构GNN模型的多视角头盔佩戴的鲁棒检测,它由基本序列编码器、层次注意力模型层组成。基本顺序编码器用于获取不同视角图像的关键特征;层次注意力模型层主要用于图形构建过程,通过选项来表示图像检测结果。多个评价指标结果表明,所设计的模型能够显著提高检测头盔佩戴的准确性。未来可对所提模型的网络结构进行进一步优化,以提高检测性能,同时可细化考虑施工人员(前景)与背景颜色相似时数据分布的差异性,使模型鲁棒性能更优。
