基于回归和分类的混合线性模型研究
2022-10-23李玮琢
李玮琢
(华北电力大学 河北 保定 071000)
0 引言
随着互联网大数据时代的到来,各个领域每天都会产生海量的数据,为了对这些数据进行更好地处理,很多数据分析方法被提出。在经典的数据分析模型中,回归和分类是两大重要的分支,回归分析可以对已知数据进行拟合,从而更好地对未知的数据进行预测;而分类可以将所给数据进行有效分类,进而完成对一些信息的识别。二者对于数据分析和处理阶段都起着至关重要的作用,那么如果将二者进行结合,通过一个模型完成分类和回归的双重任务,就可以有效减少资源的使用,从而提升数据的分析效率。
1 研究背景
近年来,相关学者提出许多回归模型并将其应用于特征提取和分类之中。比如基于岭回归(ridge regression)和Lasso回归的线性回归模型在近年来被广泛应用于分类问题中。Naseem等[1]采用岭回归模型,将人脸识别问题转换为样本之间的线性表示问题。Wright等[2]提出了一种稀疏表示分类器(sparse representation based classifier,SRC),在人脸识别上取得了极大成功。SRC将所有训练样本作为字典,认为测试样本仅能由字典中的同类样本线性表示,而与其他类样本无关,从而该线性表示向量应当满足稀疏性质。因此,SRC将人脸识别问题转化为范数最小化问题,其本质上与Lasso回归是一致的。Zhang等[3]认为测试样本的正确表示关键在于训练样本之间的协同性而非稀疏性,其基于岭回归模型提出了协同表示分类器,取得了较SRC在计算效率上的大幅提升[4]。下面本研究就从基本原理入手,逐步完成一个基于回归和分类的混合模型建立。
2 模型原理
2.1 极大似然估计原理
本研究采用的拟合方式为极大似然估计,首先设似然函数为
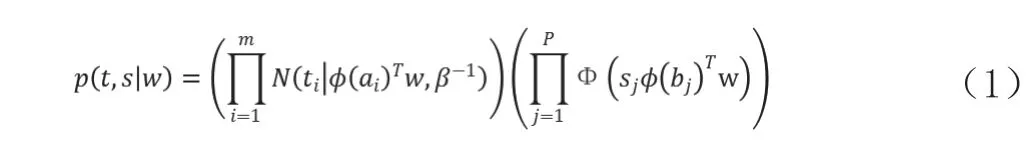
其中,m为训练数据集的个数,p为分类数据集的个数,即前半部分为训练数据部分,后半部分为测试数据部分;Φ(·)是标准高斯分布的分布函数,即probit函数;α和β为两个超参数。
根据最大似然估计的计算方法,需求出对数似然函数
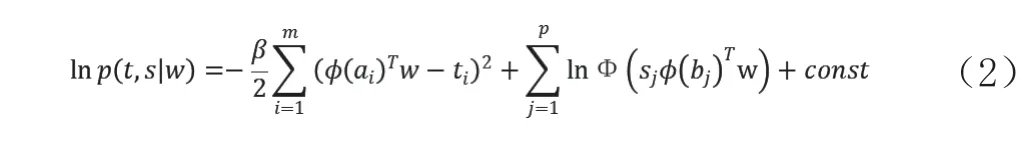
其中,const为与参数w无关的项,因为在后续对w求偏导过程中会将其舍去,所以这里不做详细阐述。再设先验
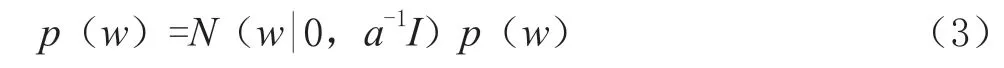
由于是将回归模型和分类模型合并为一个模型进行拟合,那么这里令
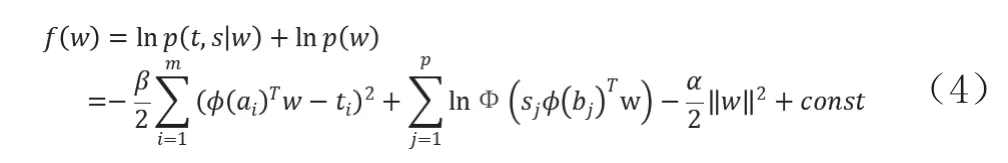
参数w可以通过最大后验法求出,即求解

具体方法是通过求f(w)对w的导数,即梯度▽f(w),再根据梯度上升法对w进行迭代,具体迭代公式如下

随着w的更新不断计算新的f(w)值,直到f(w)值收敛即达到最大值,此时的w值即为所求,然后根据所设的基函数以及训练数据,即可运用所训练的模型对函数进行拟合。具体的模型建立流程见图1。

图1 模型建立流程
2.2 训练集生成
首先设置训练集数据为定义域在[-1,1]范围内的函数

得到原函数之后,在此基础上运用如下公式[5],增加一个均值为0,方差为1的高斯噪声,在得到处理后的函数值后,从中取50个连续等间隔的点,将奇数位置上的设置为回归训练数据,横坐标用表示;偶数位置上的为分类训练数据,横坐标用表示。

其中ε为均值为0,方差为1的高斯噪声,ti为回归训练数据的目标函数值,si为分类数据的目标函数值,sign(·)是符号函数(取值范围为±1,正类为+1,负类为-1)。相应的回归训练集和分类训练集见图2。

图2 回归训练数据和分类训练数据
图中蓝色的点为回归训练数据集,黄色的点为分类训练数据集,由于高斯噪声的存在可能会导致部分分类数据集的点判断有误,由此也可以更好地体现研究中的随机性以及结论的普遍性。
2.3 基函数的选择
本文选择了两种基函数来对模型进行拟合,分别为多项式基函数以及高斯基函数,基函数的表示形式定义如下:

对于多项式曲线拟合,基函数为幂函数,即

这时

若选择的为高斯基函数,则

在这里μi是指每个高斯曲线的中心,可以在区间[-1,1]内等间隔,s是高斯曲线的尺度参数。
2.4 分布函数的选择
分布函数有probit函数和sigmoid函数两种,probit为实验中规定的分布函数,该分布函数服从正态分布,而sigmoid为常用的分布函数,两个模型都是离散选择模型的常用的模型,二者的区别就是在0左右的上升速度不同,一般情况下可以换用。而这里将sigmoid函数引入进行计算是因为该函数计算相对简单,可大大减少代码运行所需时间。两个分布函数的公式如下:
Probit

Probit函数的导数即为对x求均值为0,方差为1的正态分布。
Sigmoid
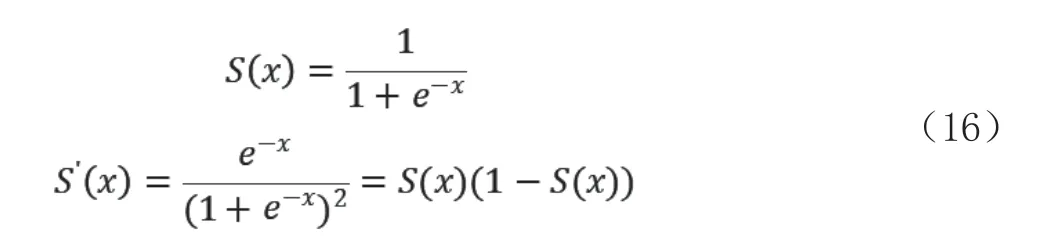
3 模型实现
3.1 模型训练
本文共选择两种基函数以及两种分布函数进行拟合计算,并对各种组合的效果进行对比。研究中相关参数自行设置,为保证后续各组之间的比较,要注意维持参数的同一。以下为对基函数与分布函数两两组合后的模型进行拟合的训练情况。
迭代1 000次的probit模型以及迭代5 000次的sigmoid模型训练过程中的误差函数f(w)变化情况见图3。

图3 基函数与分布函数组合的误差变化情况
随着4个训练过程的f(w)变化曲线可以看出,其绝对值在不断降低,最终达到一个平缓的阶段,即收敛,表明该参数下的模型训练已达到最优。图2(a)、图2(b)分别为迭代1 000次的probit模型以及迭代5 000次的sigmoid模型训练过程中的误差函数变化情况。在实验中测得迭代1 000次的probit模型训练的用时情况为720 s,而迭代5 000次的sigmoid模型的用时只有2.6 s,可见sigmoid函数在运行时间上的提升很大,有利于我们在研究中对模型进行优化,并通过增加迭代次数,来完成对曲线的更精确拟合。而图2(c)、图2(d)为高斯基函数分别在probit模型以及sigmoid模型中训练的情况,二者均选用500次迭代情况,通过两幅图可以看出,在高斯基函数下,两个分布函数的模型均很快就达到平稳状态。相比于之前的多项式基函数,其收敛速度有很大的提升,也表明模型训练能力得到了改善。为检验拟合的情况是否都理想,下面对各个模型曲线的拟合情况进行展示分析,见图4。
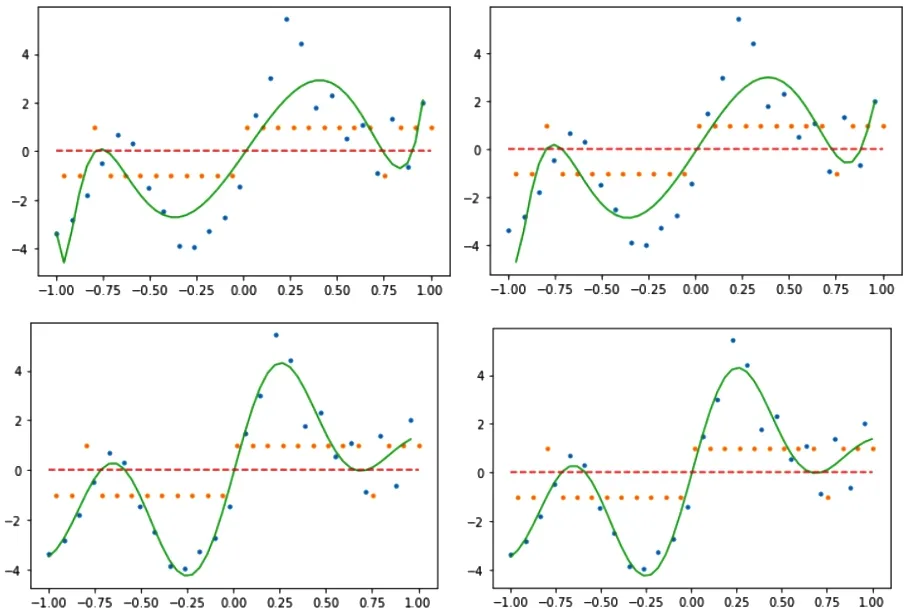
图4 基函数与分布函组合的拟合情况
图中黄点为分类数据,蓝点为回归数据。4幅图的模型分别与上文4幅f(w)曲线的模型相对应。通过对比可以看出,多项式基函数的二者拟合情况基本准确,大体上完成了对该曲线的拟合,但如果与后两幅高斯基函数进行对比,则显得不容乐观。4个模型的具体分类情况根据曲线相对于0的大小可以进行判断,分类情况稍有误差。
通过高斯基函数的图像可以看出,上述两个图都几乎很完美地完成了对于所给曲线的拟合,分类数据也相对较为准确,可以说是很好地完成了回归以及分类任务。相比于多项式基函数,高斯基函数的拟合情况要更好一些,分析其原因可能是因为多项式基函数变换相比于高斯基函数变化较为缓慢,不利于突出训练数据的特征,而高斯基函数更容易突出训练数据的特征,从而可以更好地完成对于模型的拟合。
若将上下两个基函数进行对比,那么由实验数据可知,多项式基函数运行时间相对较长,probit模型在曲线的开始阶段出现了一点过拟合的情况。由于迭代次数的增加,使得sigmoid模型在一些细节的处理上更为细致,因此sigmoid的拟合效果会优于probit函数的模型。所以在后面为了方便实验的进行,我们的测试样本部分以及参数改变的部分均使用sigmoid函数模型来执行。
3.2 测试误差
在上述4个实验过程中,高斯基函数的拟合效果更为平滑且精确度更高一些,并且sigmoid函数的运算效率较高,因此在这里本研究选用“sigmoid函数+高斯基函数”和“sigmoid函数+多项式基函数”的两个组合来进行误差的检测,对比它们的测试情况。该部分的测试数据为在[-1,1]区间内选用5个随机数据,下标为奇数的为回归测试数据,下标为偶数的为分类数据,即3个回归测试数据和2个分类测试数据。高斯基函数的测试的误差为-4.83,而多项式基函数的测试误差为-28.912,该数据的绝对值越小,则表明拟合的效果更好一些,与标准函数的相似程度越接近。由数据可以看出两者的误差均不是很大,但显然是高斯基函数的精确度更高一些。下面将测试数据放入到该误差函数中进行展示,见图5。
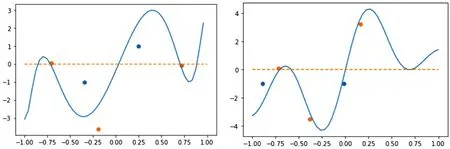
图5 “sigmoid与高斯基函数、多项式基函数”组合测试
该图中黄点表示回归测试数据,蓝点表示分类测试数据,左右两图分别为高斯基函数以及多项式基函数同sigmoid模型的组合,从两图中可以看出高斯基函数的回归测试数据均在拟合曲线的附近,而分类测试数据也与函数的正负一致,即分类正确。而多项式基函数的拟合效果整体不错,但部分回归测试点稍有一些误差。总体来讲,若要将两种基函数相比,高斯基函数的收敛速度更快,拟合效果更佳,结果显然是高斯基函数更胜一筹。
3.3 参数分析
改变参数,测试模型误差,本文选用“sigmoid函数+高斯基函数”的模型来测试参数对于模型的影响。共选用9组实验参数,来对比不同参数情况下,模型训练的误差情况。表格中9组实验使用的为同一套测试数据,随机生成的测试数据为(-0.946,0.037,-0.352,0.878,0.299),9组参数的实验结果展示见表1。

表1 不同参数对模型的影响
本部分采用对照实验方法,一组为实验组,后8组均为测试组。其中通过一、二、三组实验的对照,可以看出噪声方差会影响训练数据的混乱程度,方差较大会导致训练数据分布混乱程度较大,使得模型拟合的准确度下降,误差绝对值较大;方差取得小会使训练数据相比原函数变化不大,模型拟合相对容易,但无法体现出模型的整体拟合效果。
(1)四、五组是关于超参数α的对照实验,可以看出参数α在比较大的时候会对模型的拟合造成影响,容易造成欠拟合,误差绝对值增大;而α在小到一定程度后,再继续减小,将不会对结果造成什么影响,即使改变也是比较细微的变化,所以可以通过改变α来对模型的拟合情况进行微调。
(2)六、七组为关于超参数β的对照实验,可以看出超参数β对模型的训练情况影响比较明显。当β取值较大时,可以看出训练的误差收敛值绝对值上升,而测试误差绝对值下降了一些,说明参数值调大可以增大模型的训练精度,但本实验在这里又做了一组将β调整到100时的情况进行观察,发现如果将β调整到过于大的值会导致模型的过拟合;回到表格中数据,β的减小使得模型收敛值绝对值减小,而测试误差绝对值增大,通过实验时的图像观察,可得出结论,当β取值过于小时会造成模型的欠拟合,所以适当的β对模型的拟合情况影响比较明显。
(3)八、九组为关于步长h的对照实验,从表格中数据可以看出当步长取大值时,误差收敛值绝对值减小,测试误差绝对值减小,表明h增大,模型的学习速度增加,收敛速度增加,会改善模型的拟合情况;相反,如果h减小,误差收敛值以及测试误差的绝对值都会增大,表明模型训练速度减慢,拟合情况不佳。在这里本实验继续将h取得更大,发现当模型的步长h达到一定数值后,若继续增大,会使得模型无法收敛,即越过收敛值,在一定范围内不断震荡。而且h的取值应与超参数β相匹配,不然会导致模型在训练过程中出现溢出的情况。
综上所述,噪声方差c对于训练数据的混乱程度有关,适当的取值有利于模型的训练;超参数α适用于对模型的微调操作,不宜取值过大;超参数β与步长h对模型的拟合情况影响较大,并且二者需要相互配合调整,合适的取值对模型的拟合情况会有很大的提升。
4 库函数对比
由于未能找到具体同时实现回归和分类模型的库函数,但通过对该模型的分析,不难看出,具体的分类模型也应该是通过曲线的拟合来进行展示,根据曲线相对于零的大小位置即可完成分类,那么本研究就基于回归模型,调用库函数完成对该曲线的拟合,进而完成分类任务。
此部分,本文采用Python语言sklearn库中的linear_model.LinearRegression以及linear_model.Ridge模块来完成对回归曲线的拟合。主要思路为通过基函数对原始数据进行变换可以将变量间的线性回归模型转换为非线性模型,实现方法就是通过将一维的x投影到高维空间,以此通过线性模型拟合出x和y之间的复杂关系[6]。模型的具体实现步骤如下。
首先通过使用make_pipeline函数将PolynomialFeatures模块或高斯基函数转换器GaussianFeatures与线性模型LinearRegression或Ridge模块进行串联,然后将所给函数数据代入串联模型中进行训练,即可完成对模型的训练操作。最后画出该模型拟合的曲线,放回到原训练数据中观察回归以及分类效果,并完成对模型的测试。具体的拟合结果见图6。

图6 库函数拟合情况
图6中(a)、(b)、(c)分别为LinearRegression多项式拟合、LinearRegression高斯拟合、Ridge高斯拟合。由3幅图的拟合情况可以看出,在对多项式进行拟合时,普通的线性回归模块LinearRegression的拟合效果还算不错,但当对高斯基函数进行拟合的过程中,每个位置上的基函数系数变化幅度很大,即出现了过拟合的现象。此时本文采用了Ridge岭回归,该模块的处理方法与普通的有所不同,岭回归是通过对模型系数平方和即L2范数进行惩罚,从而抑制模型的剧烈波动,消除了过拟合的问题,其拟合结果为上图中的(c),可以看出比(b)的图像平滑了许多。调用库函数的3种方法所消耗的时间依次为:0.02、0019、0.012,可以看出运行时间是非常短的,相比于本实验的程序,库函数算法的不足在于只完成模型的回归操作,无法减少资源的使用,这也正是本文设计模型的优势所在,但是库函数的执行效率非常高效,并且代码简洁,拟合效果好。因此本实验的程序还需在代码复杂度方面进行进一步的优化,比如循环的使用情况、计算公式的执行情况等方面,以提升算法的效率。
5 结语
本文通过将传统的回归模型与分类模型进行结合,以极大似然估计为基础,运用梯度上升法进行迭代,完成对回归与分类混合模型的建立。并对两种基函数以及两种分布函数的不同选取情况进行了详细分析,比较不同模型之间的优劣。运用对照实验的方法,验证不同参数对于模型的影响并详细阐述了各个参数所代表的具体含义。最后将所设计的模型与回归模型的库函数进行对比分析,总结该混合模型的优势与不足,提出进一步的优化方向。
通过研究表明将回归与分类模型的结合可以有效增强模型的使用效率,并且减少相应的资源浪费,大大强化了模型的实用性,具备进一步研究的潜力。
