基于参数优化的KELM 和GRU 的短期电力负荷预测*
2022-10-22雪鲍龚顺琦
周 雪鲍 刚 龚顺琦
(1.三峡大学电气与新能源学院,湖北 宜昌 443002;2.三峡大学梯级水电站运行与控制湖北省重点实验室,湖北 宜昌 443002)
短期电力负荷预测指的是对短期负荷时序数据内在规律的研究,以便探索未来的负荷变化,并进行电力需求初步估计和预测[1-3]。由于短期负荷时间序列的强非线性,实现高精度预测具有一定的挑战[4-5]。目前,一些智能算法(如人工神经网络和支持向量机)在非线性时间序列的预测中能够取得较高精度,因此在负荷预测研究中占有很大的比重[6-8]。文献[9]为了提高预测精度,利用人工神经网络理论和方法,对日最大、最小负荷时刻进行负荷模型预测,分析了预测负荷值和预测模型参数值之间的灵敏度。文献[10]在负荷预测中使用了BP 神经网络,虽然BP 神经网络优异的自我学习能力和自适应能力可以提高预测精度,但初始阈值和权重的选择对网络训练的速度和精度有很大影响。文献[11]提出了一种基于改进经验模态分解(IEMD)和支持向量机(SVM)的风电信号组合预测方法。该模型能够较好地表现原信号的整体趋势,并通过实例验证了该模型具有较强的泛化能力。文献[12]采用改进蜻蜓算法优化自适应噪声的完全集合经验模态分解(CEEMDAN)与支持向量回归(Support Vector Regression,SVR)模型,有效提高了负荷的预测精度。为了削弱负荷序列的非线性,文献[13]将经验模态分解(Empirical Mode Decomposition,EMD)与粒子群优化(PSO)以及遗传算法(GA)相结合,改进了负荷预测中传统支持向量回归(Support Vector Regression,SVR)模型的预测性能。虽然基于EMD的分解方法可以有效地执行原始负荷数据的分解,能够将平稳序列与非平稳序列有效地分离,以提高预测精度。但是采用EMD 算法进行分解,可能会产生虚假IMF 分量,影响整体分解性能和预测精度。为获得更好的预测效果,文献[14]建立经验小波变换(Empirical Wavelet Transform,EWT)与小波核极限学习机(WKELM)的组合预测方法,与EMD 相比,EWT 算法能够更好地处理数据,进一步提升了模型的预测性能。对于核极限学习机而言,其正则化系数和核函数参数需要合理设定,两者的设定对模型预测性能具有一定影响[15]。
由于短期负荷时间序列的复杂性及其非平稳性,一些学者将组合模型预测方法应用于短期负荷预测。其中,应用时频分解技术处理后再对各子序列分别预测的方法得到了广泛的应用。上述方法虽然削弱了原始数据的非平稳性,较显著地提升了预测精度。然而,对于不同复杂度的子序列,应用同一种预测模型并不能充分发挥模型性能。因此,提出了一种基于经验小波变换(EWT)、样本熵(Sample Entropy,SampEn)、门控循环单元(Gated Recurrent Unit,GRU)和基于鲸鱼优化算法(Whale Optimization Algorithm,WOA)参数寻优的核极限学习机(Kernel Extreme Learning Machine,KELM)[15]的混合预测方法。通过对不同预测模型的比较,验证了文章提出的模型在电力系统短期负荷预测中的应用具有高效性和准确性。
1 基于EWT 和样本熵的数据预处理
1.1 EWT 算法
文章采用一种新的自适应信号处理方法即EMT算法[16],对原始电力负荷数据进行预处理。该方法的核心思想是基于尺度空间的频谱分离技术,自适应划分信号频谱,然后构造一组合适的小波滤波器,提取具有频谱特征的调幅-调频分量(AM-FM),对提取的AM-FM 分量进行Hilbert 变换,得到有意义的瞬时频率和瞬时振幅,进而得到Hilbert 谱。EWT 的理论完备且计算量远小于EMD 和集成经验模态分解(EEMD),有效消除了模态混叠现象[17]。
由EWT 变换之后,原始信号f(t)可表示如下:

经过上述转换后的经验尺度分量f0(t)包含原始信号的整体变化特征,fk(t)包含不同频域具有差异的特征,即实现了原始序列中固有模态分量的有效分离。其中,EWT 分解信号的主要过程如图1 所示:
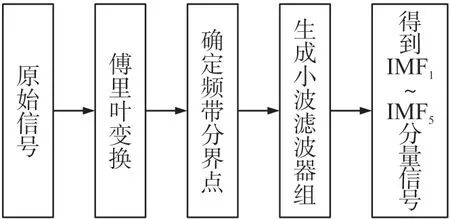
图1 数据预处理流程图
1.2 样本熵
为了定量评估各分解序列时序特征以分配适宜预测模型,文章采用样本熵对各子序列内部混乱程度进行定量分析,样本熵(Sample Entropy,SampEn)与近似熵的物理意义相似,都是通过度量信号中产生新模式的概率大小来衡量时间序列复杂性,新模式产生的概率越大,序列的复杂性就越大。其中样本熵的基本原理可参见文献[18]。文章中序列样本熵复杂度以原始序列的样本熵值为评价标准,当子序列的样本熵值大于原始序列样本熵值时,则说明此子序列更为复杂。
2 基于GRU 和WOA-KELM 的混合预测方法
2.1 GRU
GRU(Gate recurrent unit,GRU)是在人工神经网络基础上发展起来的一种具有较强时序预测性能的新型深度网络,其通过引入各类门控算子对输入变量进行选择性操作,不仅能够减少梯度消失问题,还可以实现长期记忆信息的保存与更新[19]。其网络结构如图2 所示:

图2 深度门控单元结构
假设xt为输入,ht为隐藏层的输出,GRU 单元通过以下公式计算得到ht:

式中:σ为sigmoid 函数,xt为t时刻输入张量,ht-1为t-1 时刻隐含状态,rt和zt分别为重置门和更新门,wxr和br表示权重参数和偏移参数为候选隐藏状态,⊙为Hadamard 积。
2.2 基于WOA 算优化的KELM 预测原理
核极限学习机(KELM)是一种特殊的前向神经网络[20],它只需要设置隐藏层的节点个数,然后使用最小二乘法即可计算出权重。核极限学习机由于其输入权重与偏置项随机产生并在计算过程中不再改变,因此其模型结果会更加随机,能够避免传统神经网络容易产生局部最优解的问题。
对于含有L个隐藏层节点的KELM,给定N组训练样本数据,输入样本集为X={x1,x2,x3,…,xN},此时输出的样本集为Y={y1,y2,y3,…,yN},其中KELM 的输出表达式为:
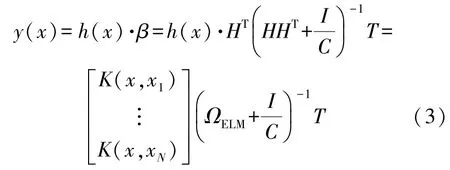
式中:C为正则化参数;ΩELM为核函数,表达式为ΩELM=HHT;H为隐含层输出函数,H=[h(x1),…,h(xn)]T,h(xi)为样本xi的非线性映射;β为隐含层与输出层的权值向量。
由于KELM 是在ELM 基础上通过引入核函数来获得更好的应用潜力,核函数ΩELMi,j表达式如下,其中g为KELM 的核参数:

为优化KELM 预测模型的内部正则化系数c和核函数参数g,文中使用鲸鱼优化算法(Whale Optimization Algorithm,WOA),并基于核极限学习机的理论基础优化KELM 的超参数。WOA 算法为一种模仿座头鲸狩猎行为的元启发式优化算法,使用随机或最佳搜索代理来模拟狩猎行为,以及使用螺旋式位置更新来模拟座头鲸的泡泡网攻击机制[21],算法的求解步骤可简要描述如下:
(1)环绕式捕猎。座头鲸根据猎物的位置不断调整自身位置进行狩猎,以获得最佳捕食策略。这种优化搜索策略可以描述为:
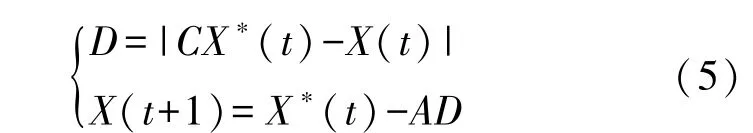
式中:D为当前座头鲸和猎物之间的距离;X*(t)为目前得到最优解的位置向量;X(t)为当前的位置向量;X(t+1)为下一次迭代后的目标向量;A和C为系数向量,可由公式(6)计算得到:

式中:A∈[-1,1];r1和r2是(0,1)中的随机向量;常数a在迭代过程中线性递减;t表示当前的迭代次数;Tmax为迭代的最大次数。此过程模仿狩猎时座头鲸的螺旋运动以实现位置更新。
(2)基于泡泡网的狩猎行为。座头鲸在对猎物进行搜索包围后,采用螺旋方程来更新座头鲸的位置:

式中:Di表示第i条座头鲸到猎物的距离(目前可以得到的最佳解);b为对数螺线形状常数;l为[-1,1]之间的随机数。
在进行优化的过程中,我们采用50%的概率控制鲸群的搜索范围(P为[0,1]之间的随机数),在缩小的包围机制和螺旋模型之间做出选择,其中进行螺旋式位置更新的公式如下:

(3)猎物搜寻过程。座头鲸在实际猎捕中会将螺旋式搜索和随机搜索两种搜索模式相结合,即在|A|>1 范围内进行随机搜索,以便寻找其他合适的食物,这将增强WOA 优化算法的全局搜索捕食能力:

式中:Xrand为鲸群中随机选择的位置。
在优化过程中,将负荷序列的均方根误差作为适应度函数,适应度函数表达式如公式(10)所示:
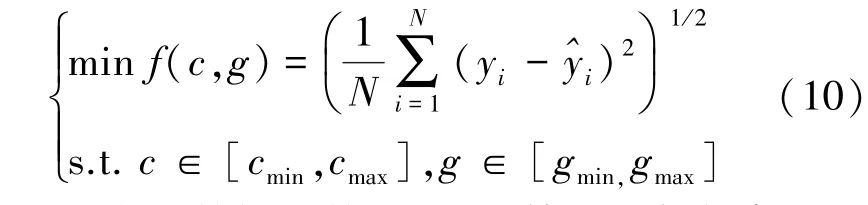
式中:N为实验数据个数,yi表示第i个负荷序列的实际值为第i个负荷序列预测值。
当适应度值f取最小时,预测值与真实值之间误差也最小,说明此时预测精度较高。在当前适应度下,通过WOA 算法寻找的最佳鲸鱼位置坐标即为KELM 内部的c,g参数。
3 短期负荷预测模型框架
3.1 预测模型整体框架
为充分削弱短期负荷序列的非平稳性和非线性,减小预测误差以提升预测模型的预测精度,文章提出基于GRU 算法和WOA 算法优化的KELM 混合预测模型来预测未来的负荷变化情况,并引入EWT 算法和样本熵对原始负荷数据进行预处理。其中文章提出的EWT-WOA-KELM-GRU 短期负荷预测模型整体框架如图3 所示。

图3 基于GRU 和WOA-KELM 的混合预测模型
3.2 WOA-KELM 预测模型构建
对经过EWT 分解后得到的IMF1和IMF2序列分量,由于其样本熵值高于原始序列,其混乱程度更高,因此采用WOA-KELM 预测模型进行预测。WOA-KELM 预测步骤如下:
步骤一:将IMF1和IMF2序列分量分别重构为六维特征矩阵和目标向量,并依次划分为训练集、验证集和测试集;
步骤二:输入训练集数据,构建KELM 整体框架,并得到验证集下的预测误差;
步骤三:将验证集预测结果的均方根误差作为适应度函数,利用WOA 算法进行优化,使预测误差最小;
步骤四:对所有序列样本进行归一化处理,初始化鲸鱼种群个数,确定迭代次数以及c,g参数的搜索范围;
步骤五:随机产生鲸鱼种群位置x(c,g),计算各个鲸鱼种群对应的适应度值,选取适应度最优的鲸鱼个体位置,记为x*(c,g),并更新当前鲸鱼位置;
步骤六:重复步骤五直至到达最大迭代次数,记录最佳位置为x*(c,g),此时的c,g为通过WOA 优化算法得到的最佳参数;
步骤七:将优化好的c,g参数代入KELM 预测模型,输入测试集的数据,最后得到预测结果。
3.3 GRU 预测模型构建
对EWT 分解后得到的IMF3~IMF5负荷序列,由于其样本熵值低于原始序列,因此通过GRU 网络得到预测输出序列。GRU 预测步骤如下:
步骤一:将IMF3、IMF4和IMF5序列分量分别重构为六维特征矩阵和目标向量,并依次划分为训练集、验证集和测试集;
步骤二:利用验证集获得对应GRU 网络模型,并使用测试集得到IMF3、IMF4和IMF5序列分量预测结果,对预测结果进行叠加重构后得到归一化预测数据;
步骤三:将预测数据进行反归一化,得到预测结果。
3.4 预测误差评价指标
为了验证文中所提模型的预测性能,采用平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Square Error,RMSE)、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)来评估模型优劣,采用拟合优度检验R2评价指标来反映模型拟合的精密度,通过以上评价指标检验各模型的预测性能,其计算方法如下所示:

4 实验及结果分析
文章采用比利时某地区2020 年1 月1 日至1 月30 日内的实测负荷数据,数据采集间隔为15 min,累计包含2 880 个样本。将数据集分为以下几部分:前1 822 个样本为训练集,之后的456 个样本用作验证集,最后596 个样本用作测试集。为了避免迭代过程中学习时间过长,同时考虑到负荷数据的时间序列特性,文章利用历史负荷数据中前6 个时刻的负荷预测第7 时刻的负荷,其中映射函数可以表示为=f(xt+5,xt+4,xt+3,xt+2,xt+1,xt)。在预测过程中,前1 822个样本为训练集用于搭建KELM 和GRU 的负荷预测模型;之后的456 个样本用作验证集选取最优参数,其中采用WOA 算法优化KELM 内部的超参数,c、g参数的范围均设置为[2-10,210];最后将596 个样本用作测试集,分别经过WOA 算法优化的KELM 模型和GRU 模型预测,最终得到精度较高的预测结果。
此外,为了保障种群多样性,WOA 优化算法种群规模设定为30,迭代次数设定为50 次。GRU 的隐藏神经元个数为32 个,隐藏层数为1。在预测过程中,考虑训练速度与梯度下降的因素,GRU 的batchsize为128,epochs 为500,同时在训练过程中,为了可以有效缓解过拟合的发生,在一定程度上达到正则化的效果,Dropout 设置为0.2,最终得到GRU 预测模型的预测结果。各算法具体参数设置如表1 所示。

表1 所提模型参数设置
4.1 分解结果
采用EWT 算法对原始负荷序列进行分解,最终原始负荷序列和EWT 分解结果如图4 和图5 所示,图4 为比利时某地区2020 年1 月1 日至1 月30 日内实测负荷数据,其中纵坐标为每15 min 采样一次的负荷量;图5 为经过EWT 分解后的5 个模态分量,累计包含2 880 个样本数据;各子序列样本熵值如图6所示,图中虚线为原始序列对应的样本熵值。

图4 原始负荷序列

图5 EWT 分解结果
由图4 可以看出,原始负荷序列具有很强的不稳定性和非线性,从图5 可以看出,在经过EWT 分解之后,原始负荷序列可以分解为5 个模态分量,并且显现出从高频到低频的变化特征。其中高频分量IMF1、IMF2波形变化剧烈,难以在预测模型中实现较高精度,IMF3、IMF4分量的变化规律比较明显,低频分量IMF5的预测结果与实际数据误差较小,能够在预测模型中实现较高精度。由此可以看出,EWT方法可以对负荷序列进行有效分解。
从图6 可以看出,EWT 分解子序列对应的样本熵呈现下降趋势。从图5 和图6 的比较可以看出,IMF1和IMF2序列信号的频率越大,其相应的样本熵值就越大,因此表明它们具有较高的复杂度,与之相应的是较高的预测难度。而IMF3、IMF4、IMF5序列波形曲线相对平稳,样本熵值小于原始序列,更易于预测。

图6 各子序列样本熵值
4.2 对比分析
为了验证EWT-WOA-KELM-GRU 混合预测模型的准确性,选取SVR、KELM、EMD-KELM、EWTKELM、EWT-WOA-KELM 预测模型作为对比模型将EWT-WOA-KELM-GRU 的性能与对比模型进行了比较,充分验证所提预测模型的精度。所提模型和对比模型在测试集上的预测效果见图7,各模型的预测误差和拟合效果数据见表2。

表2 各模型在测试集上的预测误差
从表2 和图7 的预测误差和拟合结果来看,所提出的EWT-WOA-KELM-GRU 模型取得了最好的预测效果。该预测模型在测试集上的预测误差最小,预测精度最高,且拟合效果优于其他比较模型。其中MAE 为18.295 1 MW,RMSE 为23.896 6 MW,MAPE 为0.17%,R2为99.98%。以MAPE 为例,该模型优于传统的SVR 和KELM 模型,预测误差比单一的KELM 预测模型降低了0.74%;同时,该模型优于采用其他分解技术的EMD-KELM 模型,预测误差比EMD-KELM 模型降低了0.64%,充分显现了EWT分解的效率,与EMD 分解技术相比有了很大的提高。与未采用WOA 算法优化的EWT-KELM 模型相比,该模型的MAPE 指数降低了0.23%,验证了该模型的有效性。在充分分解非线性负荷序列数据的同时,使用WOA 算法可以有效改善模型的训练速度和求解性能,在一定程度上提高短期负荷预测的准确性。与EWT-WOA-KELM 预测模型相比,采用样本熵评估经EWT 分解后的子序列复杂度,并使用EWT-WOA-KELM-GRU 混合预测模型对子序列分别进行预测,预测误差更低,拟合度更优。
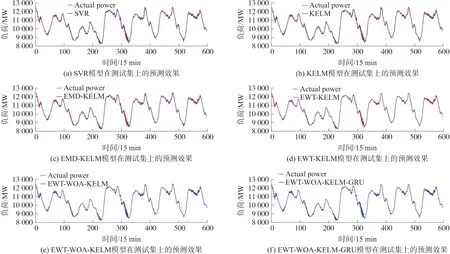
图7 所提模型以及对比模型在测试集上的预测效果
为了可视化所提模型的预测性能,测试集上所有模型的具体预测误差指标如图8 所示。

图8 所提模型以及对比模型的预测误差情况比较
对所提出的EWT-WOA-KELM-GRU 模型进行实例计算和结果分析可得,所提混合模型具有更加高效的拟合能力,经过模态分解之后,对于传统的KELM 具有较大的提升,并且所提出的EWT 分解效果要优于EMD 分解方法,有效缓解模态混叠的情况,提升了非线性负荷序列的分解效率;在进行模态分解预处理之后,采用样本熵度量各个子序列的复杂度,并为不同子序列分配适宜的预测模型;为进一步提升KELM 的预测性能,提出采用WOA 算法优化选取和搜索KELM 的内部超参数,从而有效提升了EWT-KELM 模型的预测效果,非线性拟合能力在此基础上提升0.12%,达到99.98%的高水平。
5 结论
为获得更高的短期负荷预测精度,文章采用EWT 算法对短期电力负荷的原始数据序列进行分解,获得多组平稳的模态分量序列,然后对各子序列应用样本熵分析其内在复杂度,并依次建立GRU 和WOA 算法优化的KELM 预测模型,并通过累加所有模型的预测值得到最终预测结果。实验结果表明,所提出的EWT-WOA-KELM-GRU 模型在短期负荷预测中精度较高,预测速度更快,拟合度更优。在今后的研究中,可以考虑短期电力负荷预测在更复杂的环境下的应用,例如气候等因素的影响,进一步提高预测模型的通用性和数据处理能力。
