一种对年龄变化鲁棒的人脸识别方法
2022-10-22张春永徐一得
张春永徐一得
(1.盐城工学院信息工程学院,江苏 盐城 224051;2.东南大学信息科学与工程学院,江苏 南京 210096)
人脸识别从上世纪60 年代被提出,经过半个多世纪的发展与迭代,其相关技术和性能指标也开始投入市场,并且产生了很大的经济效益。相对于传统的方法[1,5],最近的基于深度学习的算法[2]例如Google 的faceNet 都使用深度学习网络如深度卷积神经网络[3],取得了优异的性能。在一般场景下,这些模型对图像的判别甚至比人类更精确。然而,在年龄不变人脸识别(Age Invariant face Recognition,AIFR)场景下,这些方法通常缺乏人脸识别的判别能力。查阅可知,人体随着年龄的增长,身体机能和指标都会发生很大的改变,这一点在人的面部特征上有着明显的表现。一般情况下,老年人的脸上都会有一些抬头纹,眼角会下垂,口角脂肪松垂,具体就是嘴角两边的皮肤和脂肪会出现松弛的情况,脸部的苹果肌区域会出现明显的凹凸,鼻唇沟和下颌边缘都会丧失弹性,大量的脂肪流失。还有就是绝大多数老年人的皮肤失去了原有的弹性,色素开始堆积在皮肤底层,毛细孔变大,皱纹增加。AIFR 面临的关键挑战是由于年龄老化过程造成的面部特征显著差异。这一问题在当前还不是突出问题,主要是因为当前人脸识别在市场上得到运用的时间还很短,数据库并没有过于庞大,但是随着人脸识别的广泛使用和使用时间的加长,这将成为一个制约人脸识别可持续发展的关键因素。如若无法解决年龄不变人脸识别问题,那么就会需要供应商或者第三方机构定期地重新去获取当前的人脸图片,以确保算法的高准确性,这会增加大量的额外成本,也不利于人脸识别的推广。
1 年龄变化鲁棒人脸识别的特征分析与建模
1.1 年龄变化鲁棒的人脸特征学习
在之前的相关研究中,研究人员[8-9,11-12,17-20]采用启发式的方法提取手工特征。例如,林玲等人[18]开发了一种带有局部特征描述的多特征判别分析方法。Gong D 等[9]提出了隐藏因子分析(HFA)来建模特征因子分解,减少身份相关特征的年龄变化。林玲等[15]为AIFR 引入了有效的最大熵特征描述符和鲁棒性的身份匹配框架。最近的几种方法[7,13-14]主要基于深度神经网络。Wen Y 等[13]开发了潜因子引导卷积神经网络(LF-CNN)来改进HFA。郑涛等[14]介绍了AIFR 的年龄估计引导CNN(AE-CNN)方法。Wang Y 等人[7]提出正交嵌入分解,将身份信息编码在角空间,年龄信息在径向表示。我们提出了一种带有线性残差分解的DAL 算法。
1.2 人脸对抗网络的建模方针
生成对抗网络(GAN)[21]在不同的生成任务中显示了卓越的性能,如人脸老化、人脸超分辨等。此外,当前的研究还探讨了对抗性网络对判别模型的改进。Wen Y 等人[9]利用GAN 生成高分辨率的小人脸,以提高人脸检测。Lanitis A 等人[23]开发了一个对抗UV 完井框架(UV-GAN)来解决姿态不变人脸识别问题。Liu Y 等人提出在一个对抗的自编码器框架中学习身份提取特征和身份消除特征。Zhao Y 等人[24]提出了一种对抗网络来生成硬三元组特征示例。在本研究中,我们提出了一种去相关对抗学习方法,以显著减少身份和年龄之间的相关性,从而使得身份依赖的特征是年龄不变的。
2 年龄变化鲁棒人脸识别方法
在本文中,我们引入了一个深度特征分解学习框架,将混合人脸特征分解为两个不相关的部分:身份相关部分(Xid)和年龄相关部分(Xage)。图2 展示了我们的特征分解模式。我们采用文献[4]中的残差映射模块实现这种分解。这意味着,年龄相关的嵌入是通过残差映射函数Xage=R(x)编码的。我们有下面的公式:X=Xid+R(x),其中X是初始人脸特征,Xid是身份相关特征。

图1 我们以AIFR 为例,由于年龄差异较大,身份内的距离大于身份间距离。因此,许多当前的人脸识别系统无法识别年龄差距较大的人脸。

图2 将人脸特征分解为身份依赖分量和年龄依赖分量。只有身份特征参与人脸识别的测试。
为了减少分解成分之间的相互差异,我们提出了一种新的去相关对抗学习(Decorrelated Adversarial Learning,DAL)算法,该算法可以最大程度地减少身份和年龄之间的相关性。具体来说,引入典型映射模块来寻找身份和年龄之间的最大相关性,而主干网络和分解模块旨在降低相关性。身份和年龄分类信号进行学习。通过对抗训练,我们希望身份和年龄能够充分的不相关,并且在身份特征空间中的年龄信息可以大大减少。
2.1 特征分解
由于人脸包含内在的身份信息和年龄信息,所以它们可以由身份相关特征和年龄相关特征共同表示。受此启发,我们设计了一个线性分解模块,将初始特征分解成身份相关特征和年龄相关特征这两个不相关的部分。形式上,给定由主干CNNF(即,x=F(p))从输入图像p中提取的初始特征向量x∈Rd,我们将线性因子分解定义如下:

我们设计了一个类似于文献[4]的深度残差映射模块来实现这一点。具体来说,我们通过一个映射函数R获得年龄相关的特征,剩余部分作为身份相关的特征。我们称之为残差因子分解模块(Residual Factorization Module,RFM),其公式如下,Xid表示身份依赖成分,Xage表示年龄依赖成分:
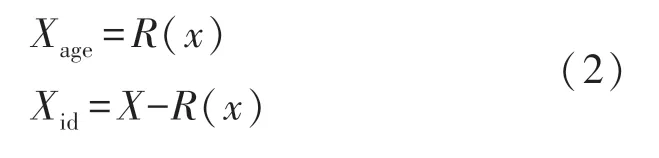
在测试阶段,只有身份相关特征用于人脸识别。希望Xid编码身份信息,而Xage绘制年龄变化。我们同时将身份识别信号和年龄识别信号放在这两个解耦的特征上,分别监督这两个部分的多任务学习。图3 显示了我们工作的总体框架。网状主干提取初始特征,并在此基础上建立残差模块进行特征分解。基于这种因式分解,我们提出了去相关对抗学习,将在下一节中介绍。

图3 提出的方法的概述
2.2 去相关对抗学习
通过特征因式分解,对于年龄不变人脸识别(Age Invariant face Recognition,AIFR)场景来说,Xid应该是只保留了身份信息,并且与年龄信息不相干的,这一点是至关重要的。不幸的是,Xid和Xage在实际上还是有深层的相关性,无法实现两者完全不相干。例如,Xid和Xage彼此具有高线性相关性,导致Xid可能会影响Xage,这一现实会对年龄不变人脸识别产生负面影响。为此,我们设计了一种有助于降低分解特征之间相关性的正则化算法,即去相关对抗学习(Decorrelated Adversarial Learning,DAL)。DAL 基本上计算分解分量的成对特征之间的典型相关。
首先通过骨干网提取初始特征,然后进行残差分解。然后利用两个已经分解的Xid和Xage进行分类和DAL 正则化。
形式上,给定成对的特征Xid,Xage,我们设计映射的线性规范映射模块(Canonical Mapping Module,CMM)Xid,Xage到规范变量vid,vage:

式中:Wid、Wage是正则映射的学习参数。之后,我们将经典相关性定义为:

基于这样的定义,首先通过更新CMM 中模型参数Wid,Wage来求得|ρ|的最大值然后去减少Vid和Vage的相关性,主要是通过训练模型残差因子分解模块(Residual Factorization Module,RFM)。从公式角度来看,一方面,在求取|ρ|的最大值中,我们要固定模型F,R,来训练C。另一方面,在减少Vid和Vage相关性的训练中,我们要固定C,来训练F,R。这两个需求是相互矛盾的,相互对抗的,这对抗的最终结果是Xid与Xage的相关性不断减小,最终实现不相干。
总体而言,DAL 的目标函数表述为:

我们相信DAL 增强的强去相关性将鼓励Xid和Xage彼此足够不变。重要的是,这将提高Xid对年龄不变的人脸识别的鲁棒性。
2.3 批量典型相关分析
与典型相关分析(Canonical Correlation Analysis,CCA)方法相比,我们的工作引入了基于随机梯度下降优化的典型相关分析(Batch Canonical Correlation Analysis,BCCA)。由于对整个数据集的相关统计实际上是不可能的,我们遵循类似的批量标准化策略[6]来计算基于小批量的相关统计。因此,它自然适合深度学习框架。

在这里,μid和分别是vid的均值和方差,对于μage和也是一样的。ξ是数值稳定性的恒定参数。
公式(6)作为BCCA 的目标函数,我们利用基于SGD 的算法来优化它。注意,规范相关数|ρ|在更新ξ时,要求必须最大化,同时在训练F,R时最小化。渐变的推导如下:

因此,优化由输出ρ值的前向传播和计算更新梯度的后向传播组成。算法1 描述了BCCA 的详细学习算法。

2.4 多任务训练
在这一部分,我们描述了多任务训练策略来监督分解特征的学习。如图3 所示,主要是有三个基本的监督模块:年龄鉴别器、身份鉴别器和DAL 正则化器。
年龄/身份判断:为了学习年龄信息,我们将Xage输入到一个投影字典对中,以便进行快速而准确的分类。顾书航[25]提出了投影字典对学习(Dictionary Pair Learning,DPL)框架。在他们的方法中,分析和合成词典的联合学习以通过线性投影的方式来学习表示形式,而无需使用非线性稀疏编码。他们的模型如下:
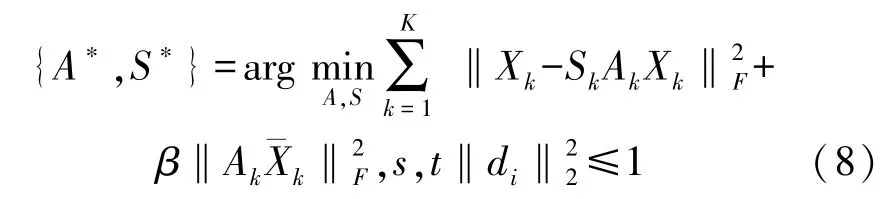
式中:S表示用于重构X的合成字典;A代表用于对X进行编码的分析字典;Ak和Sk代表对应于类别k的子字典对代表训练集中Xk的补充数据矩阵;β>0 是一个标量常数,表示控制A的判别性质的正则化参数,以及di表示合成字典S的第i个元素。
分析字典A在区分过程中发挥作用,在这过程中子字典 可以投射i类的样本(i不等于k)到空的空间去。合成字典S的作用是使重构误差最小。使用先前获取的Xid和Xage来分别学习两个单独的成对字典Did={Sid,Aid}和Dage={Sage,Aage}。然后将这些词典用于分类。这个DPL 框架的优点在于其计算时间,因为该框架在判断应用中只含有若干个字典对,没有太多的模型参数。所以这种方法是快速计算和适用于实际应用的。
使用字典Did来判断人脸图像的标签。令y为测试图像,Yid和Yage分别指字典Did和Dage的类别预测标签。可以使用以下分类方案来计算非相关身份年龄面孔的检测:

DAL 正则化器:本文所提出的DAL 正则化还参与联合监督来指导特征学习,使得成对分解特征之间的相关性可以显著降低。通过联合监督,模型同时学习鼓励Xid、Xage的区分能力和这两个分解成分之间的去相关信息。总之,在训练过程中,目标函数受以下组合多任务损失的监督:

式中:LID是Cos-Face 损失函数,LSM带有交叉熵损失的softmax,λ1与λ2是用来平衡这三种损失的超参数。在测试阶段,我们为AIFR 评估提取身份相关特征Xid。
2.5 分析讨论
该方法具有以下优点。首先,特征的DAL 正则化有助于鼓励分解后的分量之间的不相关和共不变信息。其次,BCCA 提供了CCA 的扩展插入到深度学习框架中,以便整个模型可以在端到端的过程中进行训练。最后,我们的方法可以很容易地推广到其他组件分解模型,如姿态,光照,情感等。
3 实验
3.1 实验方法与实验条件
网络架构:(1)主干网:我们的主干网是类似于[11]的64 层卷积神经网络(Convolutional Neural Networks,CNN)。它由4 个阶段组成,分别有3 个、4个、10 个和3 个堆叠的残余块。每个剩余块有3 个“3×3 conv+BN+ReLu”的堆叠单元。最后,FC 层输出512 维的初始人脸特征。(2)残差因子分解模块(Residual Factorization Module,RFM):通 过2 个“FC+ReLu”将初始人脸特征映射形成年龄相关特征,其中残差部分作为身份相关特征。(3)年龄鉴别器/身份鉴别器:使用DPL 框架快速计算分类。(4)DAL 正则化器:我们将Xage和Xid分别馈入FC 层,并输出它们的线性组合,然后用于BCCA 计算和优化。
数据预处理:我们根据5 个面部关键点(两个眼睛、两个鼻子和两个嘴角)进行相似性变换,以将人脸面片裁剪为112×96。最后,裁剪后的面片的每个像素([0,255])通过减去127.5 然后除以128 进行归一化。
测试细节:我们在著名的公共AIFR 人脸数据集FG-NET、MORPH Album 2 上进行了评价实验。在测试过程中,我们提取了身份相关的特征,并将原始图像和翻转图像的特征串联起来,形成最终的表示。然后利用这些表示的余弦相似度进行人脸验证和识别。
3.2 消耦研究
在本小节中,我们研究了模型的不同变体,以显示我们的方法的有效性。
3.2.1 余弦相似度的可视化
为了更好地理解DAL 及其改善身份保存信息的能力,我们进行了一个实验来可视化不同年龄组的余弦相似性。对于已学习的身份特征Xid,我们首先通过群集身份特征空间中的每个标识来计算其类中心,然后计算每个样本和其类中心之间的余弦相似性。之后,我们绘制了不同年龄组间余弦相似度的分布。在本研究中,我们对小型训练数据集进行这种可视化分析,该数据集包含覆盖各种年龄差异的50 万个面部图像。图4 显示了该数据集的年龄分布。
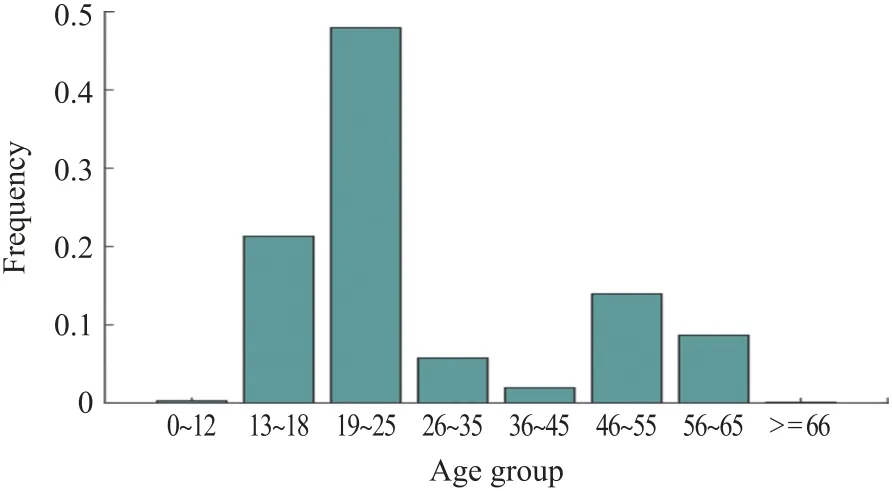
图4 小型数据集的年龄分布。该数据集包含了50 万个数据覆盖大部分年龄的人脸图像
3.2.2 定量评价
为了展示联合学习框架与DAL 方法相结合的优秀性能,我们对包括FG-NET、MORPH Album 2 在内的几个公共AIFR 数据集进行了消耦评估。此外,我们还在遵循MF1 和MF2 协议下的FG-NET 上对模型进行了测试。无论是MF1 和MF2 都有一个包含100 万个面部干扰物的额外干扰物集,使基准测试变得更加困难。MF2 提供了一个训练数据集,所有的评估方法都应该在相同的数据集上进行训练,而不需要任何额外的训练数据。在本研究中,我们考虑以下消耦比较模型:(1)基线模型:基线模型仅通过识别损失进行训练,没有任何额外的年龄监督。(2)+年龄:该模型由识别信号和年龄分类信号联合监督训练。(3)+Age+DAL:我们提出的模型,通过DAL 正则化和联合监督信号同时进行训练。
如表1 所示,在没有DAL 的情况下,联合监督模型获得了与基线模型可比较的结果。相反,我们的“+Age+DAL”模型提高了FG-NET 在所有方案上的性能。与MF1 方案相比,MF2 方案对FG-NET 的改进相对有限,主要原因是MF2 训练数据集的老化变化较小。然而,性能的持续改进证明了我们的方法的有效性。外,我们的方法在MORPH Album 2 上改进了0.7%以上的基线模型,使得在98%和99%以上的高精度水平上有显著提高。

表1 我们的方法与基准方法进行比较,在MF1,MF2 协议下,评价结果是FG_NET 上的rank_1 人脸的识别率。
3.3 在MORPH Album 2 数据集进行实验
MORPH Album 2 数据集包含了20 000 个不同年龄的人的7.8 万张人脸图像。为了进行公平比较,我们遵循[7]并在两个基准方案下进行评估,其中测试集分别由10 000 名受试者和3 000 名受试者组成。在测试集中,每个受测人员的年龄差距最大的两张人脸图像被选择组成探针集和图库集。我们使用我们提出的DAL 在大的训练数据集(1.7M 图像)上训练模型。请注意,我们没有对原有数据集进行任何微调。
在这个实验中,我们将我们的DAL 模型与文献中最新的AIFR 算法进行了比较。如表2 所示,本文所提方法有效提高了rank-1 识别性能。特别是,我们的方法比当前表现最好的AIFR 方法明显优胜,在MORPH Album 2 数据库上变成了最先进的方法。

表2 MORPH Album 2 数据集评价结果
3.4 在通用的人脸识别数据集进行实验
为了与通用人脸识别(General Face Recognition,GFR)中的最新方法进行比较,我们进一步在LFW数据集上进行了实验评估。LFW[18]是GFR 的一个公共基准,有来自5 749 名受试者的13 233 张人脸图像。我们严格遵循与OE-CNNs[7]相同的培训和评估程序。也就是说,我们的训练数据包含了与OE-CNNS[7]相同的0.5M 图像。表3 报告了LFW 的验证率。在LFW 数据集上,我们的模型都优于文献[7]的模型和最先进的通用人脸识别(GFR)模型[15-16],这表明我们提出的方法具有很强的泛化能力。

表3 LFW 数据评估结果。报告结果为LFW 的验证率
4 结论
本文提出了AIFR 的去相关对抗学习方法。我们的模型学会在对抗过程中最小化身份和年龄的成对分解特征之间的相关性。我们提出了批量典型相关分析算法,作为深度学习中典型相关分析的扩展。除了DAL 之外,我们同时在身份识别和年龄分类的联合监督下训练模型。在测试中,只有身份特征用于人脸识别。在AIFR 基准上进行的评估证明了我们提出的方法的优越性。我们的主要贡献总结如下:(1)为了规范分解特征的学习,提出了一种新的基于线性特征分解的去相关对抗学习算法。通过这种方式我们希望捕获在场景(Age Invariant Face Recognition,AIFR)下的人脸图像的身份的特征,这种特征不会随着年龄的改变而有所变化。(2)我们提出了批量典型相关分析(BCCA),一个随机梯度下降优化方式的扩展。本文所提出的BCCA 可以集成到深度神经网络中用于相关正则化。
