基于RL-DTW的智能手机身份认证机制研究与实现
2022-10-20刘聪李能能
刘聪,李能能
(潍坊职业学院,山东 潍坊 261041)
0 引 言
智能手机的本地加密作为用户个人隐私数据保密中非常重要的一环,发展出了多种加密方式,现应用最多的主要有数字密码认证、图形密码认证、指纹识别认证和人脸识别认证四种方式。其中数字密码认证、图形密码认证两种方式虽然准确度较高,但操作时间较长,解锁效率低,且非常容易被窃取和破解。指纹识别认证和人脸识别认证作为当前十分受用户欢迎的身份认证方式,具有解锁操作便捷等多种优点,但手机倒模、硅胶套就能够轻易复制一个人的指纹,2D 图像识别技术的活体检测准确率以及人脸识别准确率较低,容易被模型或者照片破解等安全问题也存在一定隐患。
为此,本文提出了一种基于RL-DTW 算法的生物特征身份认证,利用智能手机的触摸屏采集用户执行滑动手势的数据对DTW 算法的阈值和匹配模板进行不断优化,目的是在保证滑屏解锁匹配精度的同时,降低误识率(FAR),提高拒识率(FRR),最终判定滑屏加速度是否在一定的阈值接受范围内来决定是否解锁成功。
1 总体设计
基于滑动手势的身份认证锁屏系统主要包括三大模块,分别为锁屏与解锁系统、滑动手势身份认证系统以及数字密码认证系统。系统总体框架如图1所示。

图1 滑动手势的身份认证锁屏系统总体框架
1.1 滑动手势数据采集
在滑动手势数据采集的功能中,通过移动终端的触摸屏来对用户滑动手势的数据进行采集。对锁屏页面的VIEW绑定OnTouchListener(),重写Acitivity 的onTouchEvent()方法,当屏幕上产生触摸事件时,将动作ACTION_DOWN、ACTION_MOVE、ACTION_UP 所获得的数据提取出来作为初始数据,此时所获得的数据形式是坐标与时间的有序数据集合。
1.2 滑动手势数据预处理
在数据采集的过程中,在每次手势滑动的速度快慢不同,用户在执行滑动手势的时候可能会在起点或终点有停顿等原因的影响下,采集到的数据可能会有一些无效信息。在数据处理中需要对比数据中的坐标点,将距离太近的坐标点舍弃。数据处理所做的另一个工作是将数据集合中的时间序列,以第一个点为起始时间进行转换。
1.3 滑动手势特征提取
在基于滑动手势的身份认证算法中使用的特征为手势滑动过程中的加速度变化。在数据收集和预处理中的数据序列形式为(,,),…,(xyt,其中为横坐标,为纵坐标,为时间。加速度的计算方式如式(1)所示:

1.4 滑动手势模板训练
手势模板训练包括模板训练与阈值确定两个部分。手势模板训练需要用户本人执行10 次滑动手势,用采集的滑动手势数据对手势模板和阈值进行训练。训练流程图如图2所示。

图2 模板训练流程图
1.5 模板匹配认证
将待测手势与模板手势进行对比,用DTW 算法计算出两者之间的加速度差值,若<th,则身份匹配成功,否则身份匹配失败。匹配成功后,返回一个回报值=0.85th-。模板匹配流程图如图3所示。

图3 模板匹配流程图
1.6 阈值与模板优化
在手势模板训练的过程中,保存了模板和训练用的10个滑动手势数据,并以此来确定阈值th。在实际的应用中,每次解锁成功都会得到一个回报,回报的计算方式如式(2)所示:

为每次解锁成功获得的回报,若当前滑动手势与手势模板的距离小于th 的0.85 倍,值为正;反之,值为负。
设置一个累积回报。每当累积回报大于th,则将置零并按比例缩小th 值。的计算方式如式(3)所示:

为累积回报,初始值为0,在此处设置的取值范围为-th <<th,当>th 时,对进行置零;当<-th时,=-th。式中为衰减因子,的作用是减少一个手势回报值对累积回报的长远影响,使累积回报的值尽可能取决于近期的执行的解锁操作。
当进行一次置零,对th 值进行一次缩减,缩减公式如式(4)所示:

对th 按比例缩减,为缩减因子。
当进行两次置零,对手势模板和阈值th 进行重新计算。基于最近10 次解锁成功的手势数据,训练新的手势模板,并计算该模板的阈值。
2 基于滑动手势的身份认证算法RL-DTW
2.1 动态时间规整算法的基本原理
DTW 算法作为一种非线性规划方法,将时间规整和距离测度结合起来,能对时间序列不完全一致的两个序列进行最优匹配,匹配的主要思想是在需要匹配的两个序列之间建立一条最优匹配的路径。
假设有两个单位时间特征序列和:

当我们要对和这两个特征序列进行匹配时,首先需要进行时间规整,是和的时间尺度保持一致,时间规整函数如式(7)所示:

其中,()=((),()),()为序列中第个元素,()为序列中第个元素,()即将()与()进行比较。连接点() 形成的曲线即为特征序列和的最优匹配路径。
2.2 强化学习模型
强化学习(RL-reinforcement learning)的基本原理是,把学习看作一个试探评价的过程,构造一个智能体(Agent),Agent 可以从环境中获取信息作为动作的反馈。这个反馈作为奖赏值,可以为正(奖励)或负(惩罚)。Agent 通过不断地做出动作,获得奖赏,根据获得的奖赏信息来决定接下来的动作,以此来不断优化原有的策略,最终得到能够达到预期目标的最优动作。强化学习的基本模型如图4所示。

图4 强化学习的基本模型
RL-DTW 算法在经典DTW 算法的基础上,根据身份认证的匹配结果,以强化学习的方式设置回报,使每次解锁成功都能对算法的调整产生影响,通过这样不断地学习,可以对DTW 算法的匹配模板和阈值进行优化,在使用过程中不断提高DTW 算法的匹配性能。
3 实验与结果分析
本文研究基于Android 系统,使用JDK+Eclipse+Android SDK 作为Android 开发环境。在开发过程中,对应用程序进行测试运行时,操作系统为基于Android 的one UI、EMUI、ColorOS、MIUI 等;设备类型主要包括三星、华为、OPPO、vivo、小米等品牌。
参与到手势滑动解锁实验的实验人员共50 名,依次对类“S”字形、类“C”字形和类“L”字形三种解锁手势进行了详细测试。分别进行基于DTW 算法的解锁测试阶段和基于RL-DTW 算法的解锁测试阶段,在一周内至少完成解锁成功的解锁实验500 次,累积执行滑动手势超过30 000次。其中根据本人的训练测试数据建立标准加速度数据模型,其他模仿训练的人群根据获取坐标数据进行加速度求值,测试数据视图如图5至图10所示。

图5 类“S”字形DWT 算法加速度模仿辨别分布图

图6 类“S”字形RL-DWT 算法加速度模仿辨别分布图

图7 类“C”字形DWT 算法加速度模仿辨别分布图
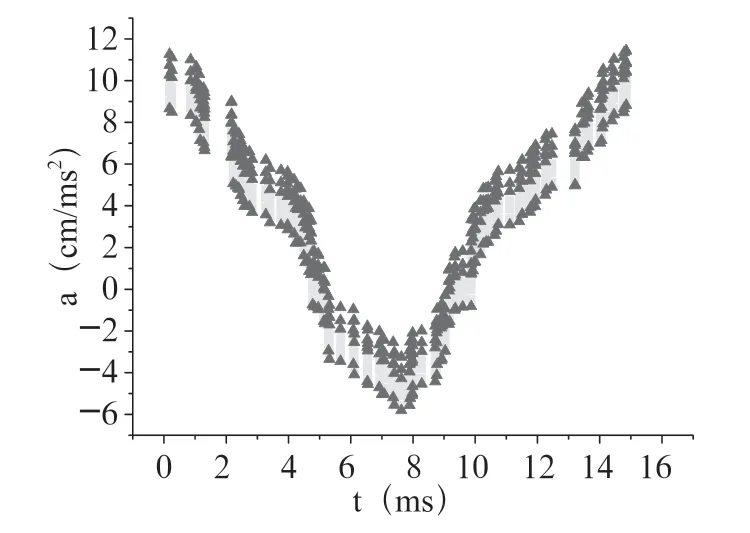
图8 类“C”字形RL-DWT 算法加速度模仿辨别分布图
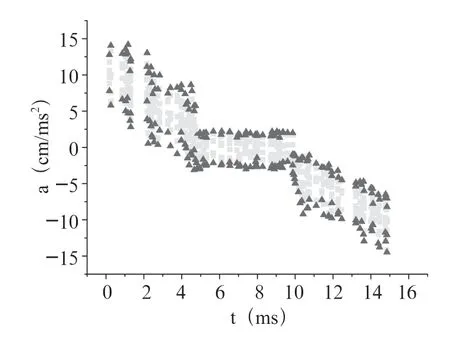
图9 类“L”字形DWT 算法加速度模仿辨别分布图

图10 类“L”字形RL-DWT 算法加速度模仿辨别分布图
其中中心隐藏线段为本人解锁屏幕标准加速度数据线,黄点和红点为模仿者根据本人解锁手势进行解锁的加速度分布(黄点代表辨别出是模仿者操作的确定概率值的范围为30%~60%,红点代表辨别出是模仿者操作的确定概率值的范围为60%~90%左右),从以上三个类型图的对比中可以看出,基于RL-DTW 算法的模仿解锁手势的识别准确率明显高于基于DTW 算法。
3.1 DTW 算法性能测试
在DTW 算法性能阶段的测试中,初始手势模板的选择是由10 个训练的滑动手势以最小二乘法训练所得,在确定手势模板后,用DTW 算法计算10 个训练手势与模板之间的距离,阈值th 初始设定为训练手势与模板的最大距离的1.5 倍。


表1 不同手势的认证性能比较
由表1中的数据可以得知,手势一的FRR 较低,可以满足解锁系统的需求;手势二和手势三的FRR 值偏高。三种手势的FAR 值普遍偏高,都处于10%左右。在当前的DTW 算法性能测试中,没有取得良好的实验效果,认证系统不适合应用于实际。
在基于DTW 算法的手势熟练度训练阶段的测试中,用户本人向其他实验人员不断演示滑动手势解锁过程,其他实验者在观察用户本人解锁的基础上,不断进行解锁练习,在进行过50 次练习之后,用户本人和其他实验者各进行了50次解锁实验。认证系统的FAR、FRR 值如表2所示。

表2 经过练习之后不同手势的认证性能比较
由表2中的数据可以看出,对比表1中的数据,经过观察和练习,三种手势的FAR 值都有了大幅提高,手势一的FAR 值甚至达到了30%以上。三种手势的FRR 值也有的变化但幅度不大,其中手势二和手势三的FRR 值略有降低。
3.2 RL-DTW 算法性能测试
在基于RL-DTW 算法的手势熟练度训练阶段中,在第二个阶段练习的基础上,为使用户对解锁手势养成习惯,提高熟练度从而在解锁手势执行时的动作稳定。在7 天内每天多次进行解锁,实验者对单个手势总的练习次数高于100 次,训练使解锁系统的阈值或手势模板至少更新了一次。
在基于RL-DTW 算法的解锁测试阶段中,以第三阶段的熟练度练习和更新后的手势模板与阈值为基础,用户本人和其他实验者各进行了50 次解锁实验。认证系统的FAR、FRR 值如表3所示。

表3 不同手势的认证性能比较
对比表1和表2中的数据,表3中的数据显示,经过熟练度训练的RL-DTW 算法性能较DTW 算法有了较大的提高,三种手势的FRR 值略有降低,但差别不明显,三种手势的FAR 值有了大幅降低,FAR 值都不高于6%。算法性能有了极大的提高。
为与第二阶段的手势熟练度训练相比较,在基于RLDTW 算法的解锁测试阶段,同样进行一次手势熟练度训练。用户本人向其他实验人员不断演示滑动手势解锁过程,其他实验者在观察用户本人解锁的基础上,不断进行解锁练习,在进行过50 次练习之后,用户本人和其他实验者各进行了50 次解锁实验。认证系统的FAR、FRR 值如表4所示。
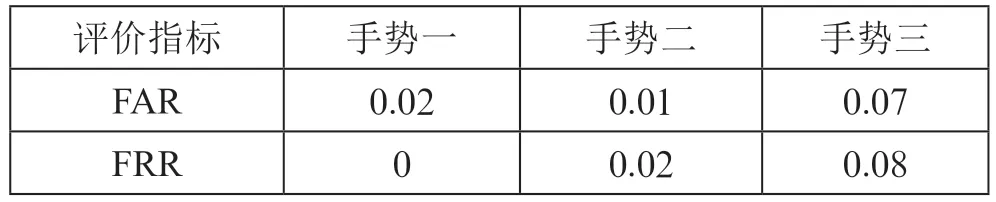
表4 经过练习之后不同手势的认证性能比较
由表4中的数据与表3中的数据对比可知,经过手势熟练度训练后,三种手势的FRR 值并没有明显的变化规律,FAR 值略有提高,但提高幅度不明显。三种手势的FAR 值和FRR 值都低于10%,实验取得了良好的结果,RL-DTW算法经过训练后,性能较DTW 算法有了极大的提高。
3.3 主要参数设置
本文所研究的基于滑动手势的身份认证锁屏系统涉及的主要参数有回报值(式(2))、衰减因子(式(3))、阈值th(式(4))三个。
其中的作用是减少一个手势回报值对累积回报的长远影响,使累积回报的值尽可能取决于近期的执行的解锁操作。∈(0,1),值越大,对阈值和模板的更新越快。这里的值设置为0.85。在经过15 次解锁成功后,15 次之前的回报值变为不足原来的10%。
阈值th 的作用是用于判断解锁是否成功,th 值过大会使FRR 值降低,FAR 值提高;th 值过小,会使FRR 值提高,FAR 值降低;本文中的初始th 值设置为th=1.2(为训练手势与模板的最大距离)。当th进行更新使,缩减因子(式(4))的值设置为0.9,当值太小,th 值一次缩减的比例过大,会导致FRR 突然增大。阈值的影响曲线如图11所示。其中红色曲线反应的是FRR 的变化,蓝色曲线反映的是FAR 的变化,横坐标是阈值th 相对于最大距离的倍率。

图11 阈值变化对FAR 和FRR 的影响
回报是影响算法对于阈值和模板的调整的主要原因,本文中的值设置为=0.85th-,为解锁手势与th 的距离。当值低于th 的85%,回报值才是正数,当多次的回报值为正,就会导致th 值进行一次更新。
3.4 实验结果分析
在3.1 和3.2 中对DTW 和RL-DTW 算法的实验数据进行了展示,从实验数据对比如表5、表6所示。

表5 训练前后FAR 数据对比

表6 训练前后FRR 数据对比
由对比数据发现,经过训练后的RL-DTW 算法对比DTW算法,在性能方面有了极大的提高,FAR和FRR值较低,能满足实际应用需求,最终传统DTW 算法和优化RL-DTW算法的识别解锁的数据准确变化情况如图12所示。

图12 传统DTW 算法和优化RL-DTW 算法数据变化对比图
通过数据对比可明显发现,优化的RL-DTW 算法在准确识别范围内的概率较大接近93%,而传统RL-DTW 算法只有72%。显而易见,本文通过优化的RL-DTW 算法在解锁智能手机方面具有较高的准确辨识度,能够在保证安全的前提下满足用户对智能手机随意形状滑屏解锁的需求。
4 结 论
本文在研究当前多种基于生物特征的识别方法的基础上,针对移动终端的特点和存在的问题,提出了一种基于RL-DTW 的滑动手势认证方法,并在Android 系统上进行实现。但仍有改进的余地,下一步的研究工作主要有以下几个方面:(1)本文的身份认证系统不适用与过于简单或过于复杂的手势,进一步对用户执行简单或复杂手势的特点进行研究,提取更有代表性的特征,以适应更加多样性的手势。(2)对算法进一步优化,减少在使用过程中算法训练所需的次数,使精度的提高更快。(3)通过更多的实验,进一步精确算法的主要参数值,以尽可能提高算法性能。
