基于卷积神经网络的环状CFRP图像缺陷检测研究
2022-10-19章栩苓周正东张灵维魏士松
章栩苓,周正东,毛 玲,张灵维,魏士松,2
(1.南京航空航天大学机械结构力学及控制国家重点实验室,江苏 南京 210016)(2.上海航天精密机械研究所,上海 201600)
随着高速加工、安全保障和节能需求的日益增长,复合材料的应用领域不断扩大。其中,碳纤维增强复合材料(carbon fiber reinforced plastic, CFRP)由于其具有质量轻、比强度高等突出的力学性能,已成为最常用的复合材料之一,广泛应用于航空航天、交通运输等行业。然而,复合材料的成形工艺和使用条件极其复杂,制造工艺、运输和操作等都可能在复合材料的表面或内部形成微小的变形或缺陷(如夹杂、裂纹、空洞、分层等),进而导致严重后果[1]。
目前常用的复合材料无损检测方法主要有超声检测、红外热成像检测、X射线检测等[2-3]。超声检测适用于检测内部缺陷,但需使用耦合剂且对不同缺陷的专业度要求高;红外热成像检测速度较快,但检测深度小;X射线检测能较好地解决材料内部密度分布不均的问题,可用于检测大部分的缺陷类型,检测效率较高。虽然上述无损检测方法可以提供CFRP缺陷的信息和图像,但后续的缺陷或可疑位置的检测和定位通常依赖人工处理,其工作量大、效率低,且仅凭人眼进行判别不客观。因此,亟需一种自动且准确可靠的方法对CFRP缺陷进行检测。
传统的图像处理可作为一种对图像中的缺陷进行分类和检测的有效方法。闫俊红等[4]在对钢板缺陷图像滤波去噪的基础上,采用Otsu阈值法进行图像分割,对缺陷的周长、面积及宽度等几何特征进行提取并识别。王子冠等[5]用传统的图像处理对轨道进行识别检测,提出利用Sobel算子提取图像边缘特征,再用Hough变换识别图像中的轨道,算法简单且速度快,但在有光照和遮挡的复杂环境下,识别性能受到明显影响。
近年来,机器学习在图像处理、计算机视觉等领域表现出了强大的潜力,使之在缺陷分类和检测领域的应用成为可能[6]。越来越多的机器学习模型被用于缺陷的分类和检测[7-9],如深度神经网络[10-14]、多层感知器[15]等。Wei等[16]用改进的SIFT算法对图像进行特征提取,并用VGG16对图像进行分类和识别;王鸣霄等[17]设计了一个分层的分类体系结构,首先利用二分类模型将输入图像分为有缺陷和无缺陷两类,再利用多分类模型对预测为缺陷的图像进一步细分类,缓解了数据不平衡的问题。
本文针对环状CFRP的X射线图像中的背景给缺陷分类和检测带来干扰的问题,利用图像变换有效减少了图像中的黑色背景部分。实验结果表明,与原始图像训练LeNet-5相比,利用变换后的图像训练LeNet-5能够使缺陷的召回率、查准率和F1值得到显著提高。
1 图像预处理
1.1 图像扩增
在工业生产中,CFRP缺陷图像数据集规模小,而卷积神经网络的训练需要大量的图像数据,为此本文采用增加或降低对比度以及翻转、旋转90°和180°的方法进行图像扩增。本文数据的缺陷类别分别是聚胶、夹杂、气孔和裂纹,共4类。把这4类的数据共同作为含有缺陷的数据集,与不含有缺陷的数据一起输入LeNet-5网络进行二分类训练。
1.2 图像变换
本文利用X射线数字摄影技术对环状CFRP零件进行成像,图像大小为1 024像素×1 024像素,而缺陷尺寸比图像小很多。为了确保分类性能并减少计算量,根据CFRP缺陷尺寸的统计参数将原图像裁剪为64像素×64像素大小的图像块。然而原始环状CFRP图像中存在大量的背景,致使神经网络的分类性能下降。为此,本文运用极坐标图像变换对环状CFRP图像进行处理,将其变换为矩形。首先,对图中的环状目标进行轮廓跟踪,根据提取的轮廓数据进行圆环拟合,得到环状目标的圆心坐标;然后运用极坐标变换将原始环状图像变换为矩形;最后在变换后的图像中提取感兴趣区域并进行分块构成数据集。
1.2.1圆环拟合
为了验证算法的性能,仿照环状CFRP的X射线图像,制作了圆心坐标为(700, 700)、半径分别为450和600的同心圆环状仿真图,并用Otsu法得到其二值图像,如图1(a)所示。对二值图像进行轮廓跟踪得到轮廓上每个点的坐标,如图1(b)所示,进一步得到轮廓点横、纵坐标值的分布曲线,如图1(c)和图1(d)所示,从图中可以观察到图像中存在明显的直线段,表明该范围轮廓点的横、纵坐标保持不变。结合图1(b)可知,直线段的起点和终点对应圆弧的起点和终点。利用差分法对轮廓点的横、纵坐标求微分,找到圆弧的起点和终点。根据起点和终点分离轮廓,可得到两段圆弧的轮廓,如图1(e)所示。运用最小二乘法分别对两段圆弧进行拟合,拟合结果如图1(f)所示。对内环轮廓点进行拟合得到的圆心坐标为(700.45, 700.30),半径为449.83,圆心横坐标的误差为0.064%,圆心纵坐标的误差为0.043%,半径的误差为0.038%。对外环轮廓点进行拟合得到的圆心坐标为(700.23, 700.10),半径为598.89,圆心横坐标的误差为0.033%,圆心纵坐标的误差为0.014%,半径的误差为0.185%。从仿真结果可以看出,圆心坐标和半径的误差都在0.2%以下,表明该方法性能优良。对内外两个圆弧拟合得到的圆心坐标取平均值作为最终的圆心坐标拟合结果。
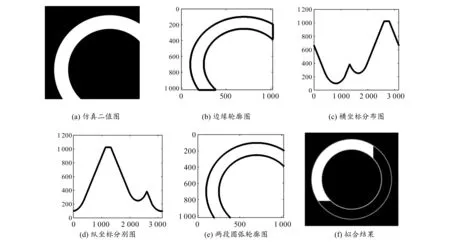
图1 仿真圆环拟合过程图
1.2.2坐标系转换
以图像中各个点到拟合圆心的距离为半径,根据极坐标变换公式,将原图直角坐标系下的坐标(x,y)变换为极坐标系下的(r,θ),如式(1)和(2)。将原图中每个坐标的像素值放置在变换图像的对应位置,得到坐标系转换后的图像。
x=cx+rcosθ
(1)
y=cy+rsinθ
(2)
式中:cx和cy为圆心的横坐标和纵坐标;r为半径;θ为按逆时针方向坐标距离极轴的角度。在实际环状CFRP的X射线图像上的变换过程如图2所示。

图2 坐标系转换过程图
1.2.3感兴趣区域提取
对图像进行极坐标变换后,进一步通过边界跟踪算法提取目标区域。然后根据目标轮廓找到其最小外接矩形,将其中的图像裁剪出来作为感兴趣区域,如图3(a)所示。本文将感兴趣区域统一按照从上到下、从左到右的顺序依次分为64像素×64像素大小的图像块,再缩小为32像素×32像素大小的图像以符合LeNet-5网络输入的要求,并把分块的图像按顺序标上序号,筛选出图中含有缺陷的部分构成有缺陷的数据集,不含有缺陷的部分构成无缺陷的数据集。本文数据集的分配见表1。从变换图像中裁剪得到的缺陷图如图3(b)所示,与从原图像中裁剪的样本(图3(c))相比,在图3(b)中黑色背景部分基本被消除。

图3 感兴趣区域提取及裁剪过程图
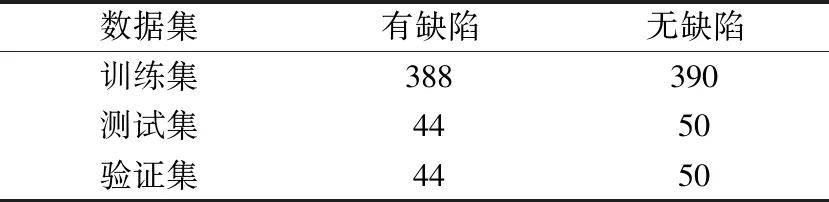
表1 数据集分配表
2 网络结构
LeNet-5是由Lecun等[18]提出的一种卷积神经网络。它涵盖了深度学习的基本模块,包括卷积层、池化层和全连接层。在LeNet-5中,卷积核大小设置为5像素×5像素,步幅为1,最大池化层的过滤器都设置为2像素×2像素,步幅为2。LeNet-5网络的结构如图4所示。
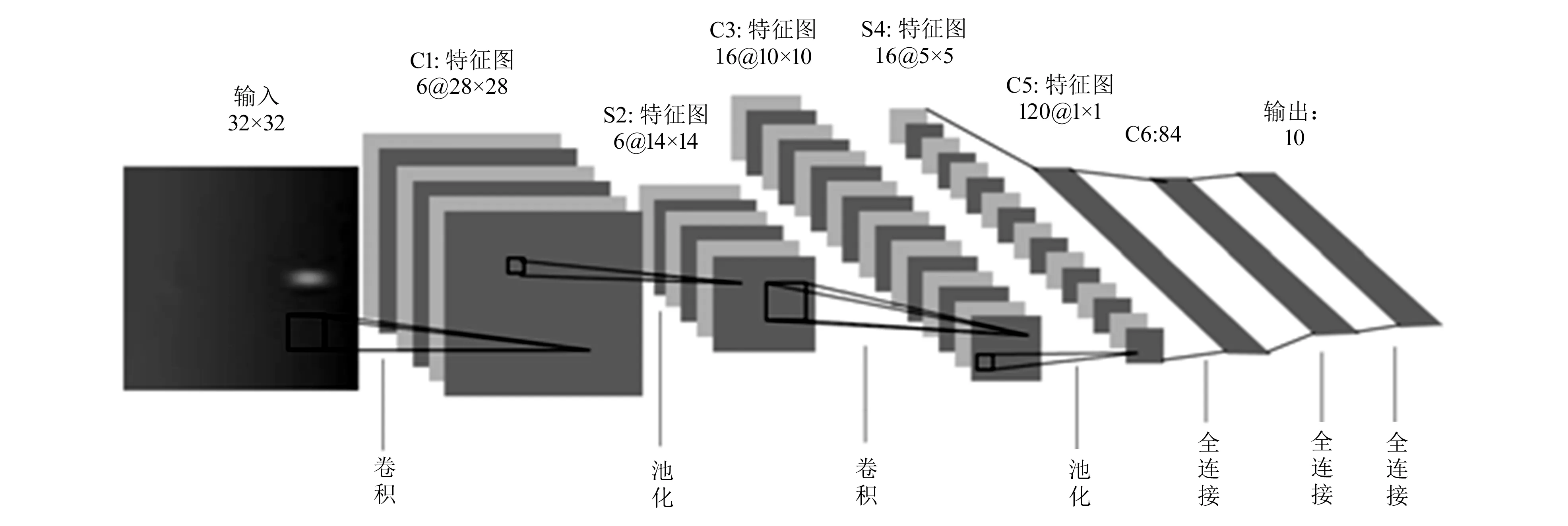
图4 LeNet-5网络结构图
图4中,C1是卷积层,可以提取6张28像素×28像素的特征图;S2是池化层,可以提取6张尺寸为14像素×14像素的特征图;C3是卷积层,可以提取16张尺寸为10像素×10像素的特征图;S4是池化层,可以提取16张尺寸为5像素×5像素的特征图;C5是卷积层,使用的卷积核为1像素×1像素,相当于做了全连接的操作,最终输出120个1像素×1像素的特征向量;C6表示84个神经元的全连接层,输出层有10个神经元。
3 实验结果与分析
本文采用Tensorflow-Slim框架在NVIDIA Quadro P2000显卡上进行训练,编程语言为python 3.5.2,运行环境配置包括Tensorflow-GPU 1.11.0、NVIDIA CUDA toolkit 9.0、NVIDIA CUDA deep neural network library (cuDNN) 7.6.4。网络的性能评价指标为召回率(Recall)、查准率(Precision)和F1值。召回率是指预测正确的正例与总预测正确的样本的比率,查准率是指预测正确的正例与所有正例的比率,F1值是基于召回率和查准率的调和平均定义的,可以对召回率和查准率进行整体评价。召回率、查准率和F1值分别由式(3)、(4)和(5)计算[19]。
(3)
(4)
(5)
式中:R为召回率;P为查准率;TP为真正例;FN为假反例;FP为假正例。
实验中,初始学习率设置为0.01,衰减方式为多项式衰减,最终学习率设置为0.000 1,批尺寸设置为16,迭代次数设置为100 000。利用原始样本和图像变换后的样本对LeNet-5进行训练,选用原始样本训练InceptionV3和InceptionResNetV2作为对比网络,得到的缺陷召回率、查准率和F1值见表2。
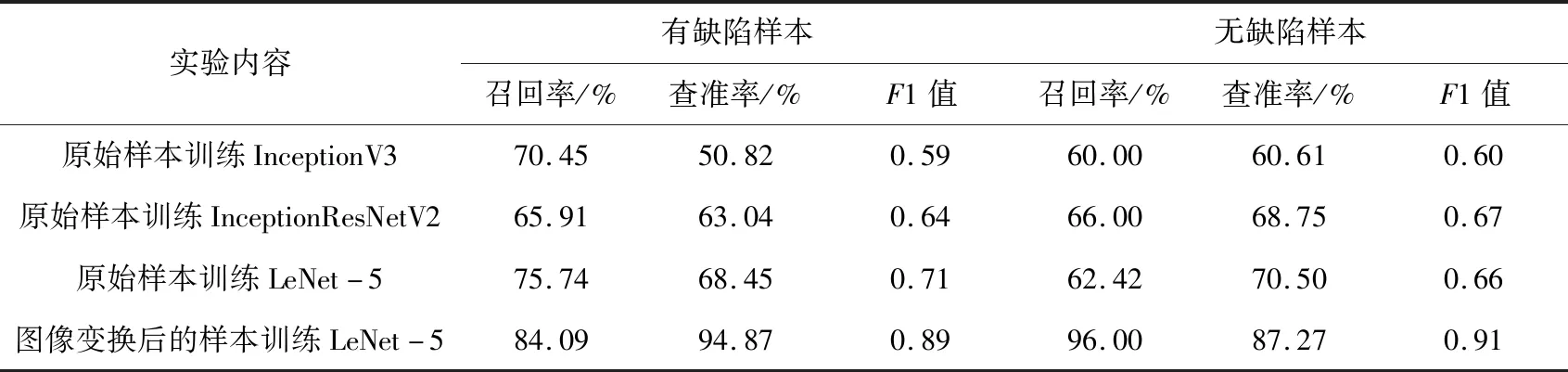
表2 图像分类的召回率、查准率和F1值
从表2中可以看出,与利用原始样本训练InceptionV3和InceptionResNetV2相比,LeNet-5网络能获得更优的性能。原始样本训练LeNet-5网络得到的有缺陷样本召回率、查准率、F1值和无缺陷样本查准率均能达到最优,但是无缺陷样本召回率和F1值略低于InceptionResNetV2。与利用原始样本训练LeNet-5相比,对于有缺陷样本,利用图像变换后的样本训练LeNet-5得到的召回率、查准率和F1值分别提高了11.02%、38.6%和25.02%;对于无缺陷样本,利用图像变换后的样本训练LeNet-5得到的召回率、查准率和F1值分别提高了53.8%、23.8%和38.1%。
4 结束语
针对环状CFRP图像,本文提出了一种结合LeNet-5和图像变换的缺陷检测新方法。该方法运用图像分割、目标轮廓跟踪、圆环拟合等技术得到环状目标的圆心,然后对原始图像进行极坐标变换,将环状目标拉直,再提取变换后图像中的感兴趣区域并进行分块,构成LeNet-5网络训练和测试的数据集,根据分块图像的二分类结果得知缺陷的局部位置,实现对缺陷的检测。实验结果表明,所提出的方法能有效减少背景图像的干扰,降低背景对网络性能的影响,显著提高缺陷检测的召回率、查准率和F1值。
