基于无人机多光谱遥感的冬小麦叶片含水量反演
2022-10-19芮婷婷徐云飞冯志军张世文
芮婷婷,徐云飞,程 琦,杨 斌,冯志军,周 涛,张世文
(1.安徽理工大学空间信息与测绘工程学院,安徽淮南 232001;2.安徽理工大学矿山采动灾害空天地协同监测与预警安徽普通高校重点实验室,安徽淮南 232001;3.安徽理工大学矿区环境与灾害协同监测煤炭行业工程研究中心,安徽淮南 232001;4.安徽理工大学地球与环境学院,安徽淮南 232001)
冬小麦在我国是人们日常生活中主要的粮食作物,快速、准确地获取冬小麦水分含量对农田灌溉管理、旱情状况监测、作物长势监测等具有重要的科学意义。含水量影响着作物的生理特征和健康状况,在缺水时作物叶片颜色、纹理特征和形态结构等会发生变化,如叶片出现蜷缩、枯黄和色斑等,进而影响作物的生长和产量。作物水分含量可以由根、枝、叶、冠层的生理特性来反映,其中作物叶片的新陈代谢最旺盛,生理特性最敏感,可以通过监测作物叶片水分含量来评估作物整体水分状况。
近年来,国内外学者基于遥感技术对作物水分含量的快速监测进行了广泛探讨和深入研究。遥感技术主要分为卫星遥感、地物光谱仪和无人机遥感。大多数研究结合卫星遥感影像监测作物水分含量,但是卫星运行时会受到云层的影响,使得利用卫星遥感监测精度受限。利用地物光谱仪可以获取作物的冠层光谱信息,但所得信息是点状的,难以用于区域性水分含量的动态监测。而无人机遥感平台具有移动性强、运营成本低、获取影像分辨率高、作业周期短等优点,可快速地获取农田高精度影像,更好地满足农田尺度上精准监测的要求。胡珍珠等筛选了与叶片含水量相关的光谱水分指数,构建了核桃果实不同生育时期的叶片含水量反演模型。吾木提·艾山江等通过灰色关联度分析,选择与叶片含水量关联度较高的5种植被指数,构建了春小麦叶片含水量的偏最小二乘模型和BP神经网络反演模型。彭要奇等采用改进的神经网络模型对玉米叶片含水量进行反演。陈秀青等在叶片和冠层两个尺度上,采用两波段植被指数,构建冬小麦叶片含水量的偏最小二乘回归和竞争自适应重加权采样-偏最小二乘回归模型。Wang等分析了不同水分胁迫条件下春小麦冠层反射率与冠层含水量的关系。Chen等利用无人机数据,构建了植被补给水指数,筛选出棉花不同部位的敏感波段。以上研究大多基于单一的敏感波段或高光谱植被指数监测作物含水量,而将无人机多光谱数据与敏感波段、植被指数结合反演作物叶片含水量的研究尚未见报道。
本研究利用无人机获得多光谱影像,同步采集了冬小麦叶片含水量数据,分析了叶片含水量与光谱反射率和植被指数之间的相关性,进而筛选出与叶片含水量相关的敏感波段组及植被指数组,再利用得到的敏感波段组和植被指数组分别构建了冬小麦叶片含水量的PLS、ELM和PSO-ELM预测模型,通过选定模型评价指标比较3种模型的预测精度,最后将最优反演模型应用于研究区,获得研究区冬小麦叶片含水量的空间分布图,以期为作物叶片水分含量的快速监测和田间管理提供科学依据和理论支持。
1 材料与方法
1.1 研究区概况
研究区位于安徽省淮北市杜集区和烈山区的交界区域(116.85°E,33.97°N),地处中纬度地区,属于暖温带半湿润季风气候,全年平均温度为17 ℃,平均降水量为849.6 mm,日照时数为 4 430.2 h,雨水多集中于6-8月,土壤类型为壤土。研究区采取冬小麦和夏玉米轮作的种植方式,灌溉方式为雨养。供试小麦品种为淮麦22,小麦实行机播,行距15 cm,播种密度约为每公顷100万株。研究区位置和采样点分布情况如图1所示。

图1 研究区位置和采样点分布图
1.2 数据采集
1.2.1 无人机多光谱数据
本研究使用的无人机为大疆精灵4多光谱版植保无人机,其光谱相机配备6个1/2.9英寸CMOS影像传感器,其中1个彩色传感器用于常规可见光(RGB)成像,5个单色传感器用于包含蓝光波段(中心波长450 nm,带宽32 nm)、绿光波段(中心波长560 nm,带宽32 nm)、红光波段(中心波长650 nm,带宽32 nm)、红边波段(中心波长730 nm,带宽32 nm)和近红外波段(中心波长840 nm,带宽52 nm)的多光谱成像。
无人机多光谱影像的采集时间为2021年1月7日,冬小麦处于越冬期,飞行时间为11:00-14:00,飞行时天空晴朗无云,风力较小。起飞前手动控制无人机飞行至校准白板的正上方约1 m处,采用相机单摄模式来拍摄标准白板。本次飞行设置航线为S型,飞行高度为100 m,航向和旁向重叠度分别设置为70%和60%,相机镜头与地面呈90°,拍照模式为等时间间隔。
1.2.2 地面实测数据
根据研究区范围及冬小麦种植面积,利用均匀布点原则布设采样点,并利用GPS记录每个采样点的位置信息。冬小麦叶片样品均采用五点法混合采集,然后用密封袋对冬小麦叶片样品进行密封保存并放置于阴凉处,以此来保证叶片水分不受到损失。实验室处理时,冬小麦叶片含水量的测定采用烘干法,将冬小麦植株的叶片和茎分离后称取每一个样品的叶片鲜重,然后将所有样品放入烘箱中,在105 ℃下杀青30 min,再在 80 ℃下烘干至恒重,称取叶片干重。冬小麦叶片含水量(LWC)按公式“LWC=(鲜重-干重)/鲜重×100%”进行计算。
1.3 多光谱影像处理
利用Pix4Dmapper软件对无人机获取的多光谱影像进行拼接处理。拼接后多光谱影像的主要预处理包括几何校正和辐射校正。结合ArcMap 10.6软件,以无人机高清数码正射影像为参考影像,分别在5个单波段影像上均匀选取30个参考点进行几何校正,几何校正误差在0.5个像元之内。在多光谱影像中计算标准白板在各波段的DN值,利用公式“=DN/DN×”进行多光谱影像的辐射校正,其中为目标地物的反射率,DN为目标地物的DN均值,DN为标准白板的DN均值,为标准白板的反射率值。
2) 当不确定加箱或减箱事件发生时见图2b),进入下一阶段t=t+1,更新集装箱序列和船舶贝内箱位序列,减箱事件对应的集装箱c4和箱位p6从序列中被删除,加箱事件对应的集装箱c7被添加到集装箱序列。
将预处理后的无人机多光谱影像及采样点的GPS点位信息导入到ENVI 5.3软件中。以地面实测取样点为中心,在图像上裁剪出200×200(像素)的光谱影像,将感兴趣区域(ROI)范围内冬小麦叶片样本的平均反射光谱作为该取样点的光谱反射率,获得不同波段的光谱反射率数据。
1.4 植被指数选取
作物因其内在生化参数存在差异而表现出不同的光谱反射率。在可见光波段内,健康绿色作物的主要吸收峰在红光波段和蓝光波段的附近形成,主要反射峰在绿光波段形成;而在近红外波段,作物的光谱特征为高反射率和低吸收率;在红边波段,作物的光谱反射率增长较快。将这些特征波段范围内的光谱反射率通过线性或非线性的组合构成植被指数,可用来诊断作物生长状态以及反演各种作物参数。通过以上对植被光谱特征的分析,本研究获取的多光谱影像波段特征,从现有的多光谱植被指数中选取了20个多光谱植被指数用于模型构建(表1)。

表1 植被指数及其相关计算公式Table 1 Vegetation index and its related calculation formula
1.5 模型的构建
偏最小二乘模型是一种具有广泛适用性的线性多元统计数据分析方法,具有主成分分析、典型相关分析和多元线性回归分析的特点,可以有效地解决变量之间存在多重共线性或者样本量较少的问题。因此,其在处理因变量较多或者因变量内部信息高度线性相关,而样本量较少的数据时具有明显的优势,具有简化数据结构、降低数据维度、减少噪声干扰等特点。
极限学习机是一种针对单隐含层前馈神经网络的学习算法。该算法随机产生输入层与隐含层的连接权值和隐含层神经元的阈值,且在训练过程中无需调整,只需要设置隐含层神经元个数,便可以得到全局最优解。与传统的训练方法相比,极限学习机具有学习速度快和训练误差小等优点。ELM模型的主要步骤为:①确定样本集;②确定隐含层神经元个数,随机生成输入层与隐含层的连接权值和隐含层神经元阈值;③确定隐含层神经元的激活函数,计算隐含层输出矩阵和输出层权值矩阵,根据权值矩阵和激活函数,最终计算极限学习机模型的预测值。
粒子群算法是模拟群体智能所建立的一种优化算法,是基于鸟类的觅食行为而提出的全局寻优的一种方法。粒子群算法具有收敛速度快、可调参数少等优点,广泛应用于神经网络的优化。为了提高模型的预测精度,可用粒子群算法优化极限学习机的初始输入权值和阈值,其优化流程如图2所示。
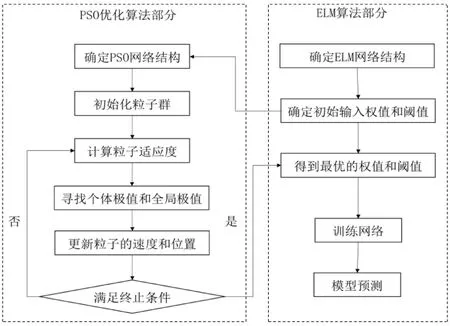
图2 PSO-ELM算法流程图
1.6 模型的验证
采用决定系数()和均方根误差(RMSE)两个指标来评价模型的精度。表示了预测值与实测值的拟合程度,其值越接近1,表明该模型的拟合效果越高;RMSE反映了预测值与实测值的偏离程度,其值越小,表明该模型的预测精度 越高。


2 结果与分析
2.1 光谱反射率与叶片含水量的相关性
2.2 植被指数与叶片含水量的相关性
经皮尔逊相关性分析,选取的20个植被指数与冬小麦叶片含水量之间的相关程度不同,其中GNDVI、EVI、NRBDI与叶片水分含量的相关性达到显著水平 (<0.05),其余植被指数与叶片水分含量的相关性达到极显著水平(<0.01)(表2)。根据植被指数与叶片水分含量相关的显著性原则,同时考虑模型的简洁性,选取EXG、EXR、NGRDI、GI和TVI等5个相关性较高的植被指数作为模型的输入变量。

表2 植被指数与叶片含水量的相关性Table 2 Correlation between vegetation index and leaf water content
*:<0.05; **:<0.01.
2.3 冬小麦叶片含水量的反演模型
为方便模型分析,将选取的红、蓝和近红外波段作为第1组的模型输入变量,记为敏感波段组;将选取的EXG、EXR、NGRDI、GI和TVI5个相关性较高的植被指数作为第2组的模型输入变量,记为植被指数组。利用IBM SPSS Statistics 26软件进行随机抽样,将获得的46个样本数据分为建模集和验证集,70%的样本数据(33个)用于建模,30%的样本数据(13个)用于验证,以此来构建冬小麦叶片含水量估算模型。
2.3.1 偏最小二乘(PLS)模型
采用敏感波段组和植被指数组通Origin 2021分析软件分别建立的冬小麦叶片水分含量PLS模型的分别为0.65和0.80,RMSE分别为1.11%和0.82%(图3),说明采用植被指数组所建的PLS模型的预测精度高。

图3 冬小麦叶片水分含量的PLS预测结果
2.3.2 极限学习机(ELM)模型
通过MatlabR2020b编程软件,利用两组输入变量分别建立基于ELM的冬小麦叶片水分含量反演模型,并对模型进行精度验证。通过“试凑法”逐一实验,最终确定隐含层神经元的个数为7,隐含层激活函数为“sigmoidal”函数。从图4可以看出,采用敏感波段组和植被指数组建立的ELM模型的分别为0.79和0.84,RMSE分别为0.84%和0.74%,说明采用植被指数组所建模型的预测精度也较高。
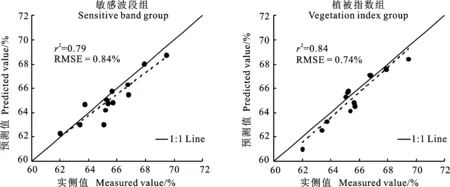
图4 冬小麦叶片水分含量的ELM预测结果
2.3.3 粒子群优化极限学习机(PSO-ELM) 模型
通过MatlabR2020b编程软件,用两组输入变量分别构建冬小麦叶片水分含量的PSO-ELM模型。为使得模型结果具有可比性,PSO-ELM模型的隐含层节点数与ELM模型保持一致。经过反复测试确定粒子群算法的参数:最大迭代次数为100次,种群规模为20,学习因子和均为1.494 45,粒子速度范围为[-1,1]。采用敏感波段组和植被指数组建立的PSO-ELM模型的分别为0.92和0.98,RMSE分别为0.53%和0.26%(图5),说明采用植被指数组建立的PSO-ELM模型的预测精度更高。
综合来看,以上所有模型的均大于0.60,RMSE都小于1.12%,模型均能在一定程度上反映冬小麦农田光谱数据与实测叶片含水量之间的关系,且基于植被指数组构建的叶片水分含量预测模型的反演精度均高于基于敏感波段组构建的预测模型,其中基于植被指数组的PSO-ELM模型精度最高。
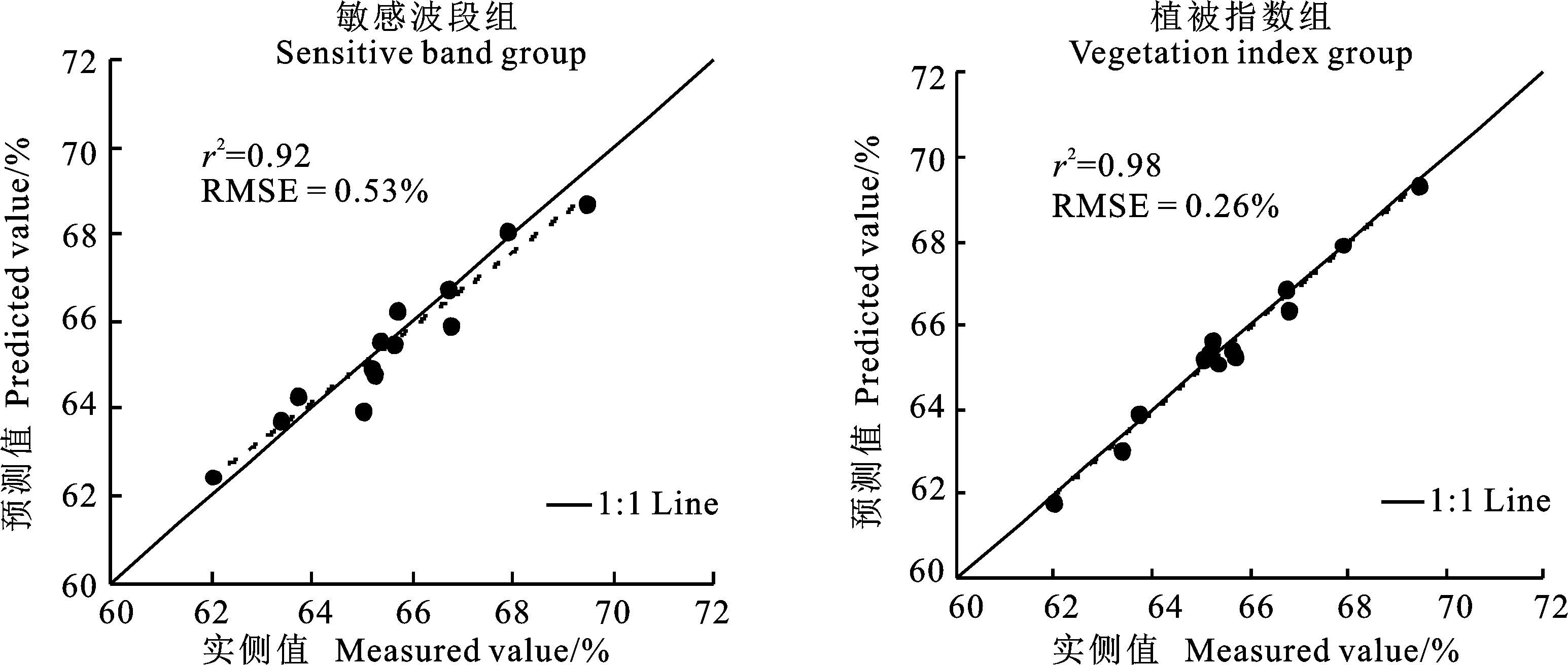
图5 冬小麦叶片水分含量的PSO-ELM预测结果
2.4 研究区冬小麦叶片含水量的空间分布特征
为获得整个研究区内冬小麦叶片含水量分布信息,将最优反演模型应用于研究区,绘制了研究区冬小麦叶片含水量的空间分布图(图6)。由图6可知,研究区冬小麦叶片水分含量分布范围为45%~75%,平均值为64.57%;地面实测冬小麦叶片水分含量分布范围为50%~72%,平均值为64.55%。因此,基于无人机多光谱影像反演冬小麦叶片含水量的分布范围与地面实际情况较为相符,研究结果可为农田尺度上冬小麦叶片含水量的空间反演和精准灌溉提供科学依据和技术 支持。
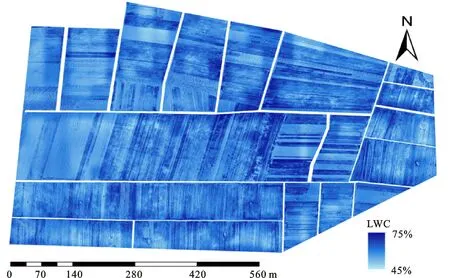
图6 基于PSO-ELM模型的冬小麦叶片水分含量空间分布图
3 讨 论
作物水分含量的快速监测对于旱情监测和灌溉管理具有重要的现实意义。波段的光谱反射率和构建的植被指数均能与地面实测的叶片含水量有较好的相关性,因此基于多光谱各波段光谱反射率和植被指数构建的模型均可定量估算作物的叶片含水量。针对无人机多光谱数据估算冬小麦叶片含水量,本研究选取了20个植被指数和5个波段反射率,分别作为植被指数组和敏感波段组分析其与冬小麦叶片含水量的相关关系,确定的敏感波段为红光波段、蓝光波段和近红外波段,这与Chen等的研究结果一致。本研究筛选的植被指数组为绿度指数、过红指数、归一化绿红差值指数、三角形植被指数和过绿指数。同时发现,相关性较高的植被指数主要是红波段、蓝波段和近红外波段的组合,这与相关性分析选取的敏感波段结果基本一致,并且与单波段相比,植被指数的相关系数有所提高。
作物冠层反射率主要受土壤背景、作物成分(如叶片含水量)和冠层结构(如叶倾角)三大因素影响。在不同的环境条件下,作物冠层结构也有所不同,从而引起波段或者植被指数对作物叶片含水量的敏感程度存在一定的差异,使得作物叶片含水量预测模型的普适性和估算精度降低。本研究对植被指数组和敏感波段组的建模预测效果进行对比发现,利用植被指数组构建的模型的精度和稳定性均优于敏感波段组。这主要是因为冬小麦在越冬期的田间覆盖度较低,光谱反射率容易受到土壤等背景因素的影响,导致冠层光谱反射率噪音比较大,而植被指数具有较多的波段光谱信息,考虑了多光谱数据的敏感波段又剔除了信息冗余,能够去除或者降低土壤背景等对植被光谱信息的影响,增强植被指数与叶片含水量之间的敏感性,以此提高了叶片含水量的估算精度。
本研究基于PLS、ELM和PSO-ELM的3种建模方法建立冬小麦叶片水分含量反演模型。PSO-ELM模型和ELM模型的反演精度均优于PLS模型,原因在于线性关系描述叶片含水量与植被光谱信息存在一些欠缺,难以精准解释植被光谱构建叶片含水量之间的相关性;而PSO-ELM模型和 ELM 模型均用非线性函数来输入输出数据进行神经网络的训练,使训练后的网络能够预测非线性函数输出,可以有效解释非线性的问题。PSO-ELM 模型的反演精度优于ELM模型,是因为ELM的初始输入权值和阈值是随机产生的,所以初始值会影响模型的训练效果,导致基本粒子群陷入局部最优;而PSO算法优化了ELM的输入权值和阈值,提高了模型的反演精度和稳定性。将构建的最优冬小麦叶片含水量模型应用于整个研究区后,预测结果较为准确,但本研究仅以越冬期冬小麦为研究对象,从敏感波段和植被指数出发构建了叶片含水量模型,未来需要结合冬小麦多个生育时期建立冬小麦叶片水分含量模型。
4 结 论
通过对5个多光谱波段和20个多光谱植被指数分别与地面实测冬小麦叶片含水量进行相关性分析,最终确定敏感波段为红光、蓝光和近红外波段,敏感植被指数为EXG、EXR、NGRDI、GI和TVI。利用所选敏感波段、植被指数,建立冬小麦叶片含水量的 PLS、ELM、PSO-ELM模型并进行验证,基于植被指数组构建的三种模型预测精度和稳定性均优于敏感波段组,其中基于植被指数组的PSO-ELM模型精度最高,其和RMSE分别为0.98和0.26%。利用植被指数组构建的PSO-ELM模型绘制冬小麦叶片含水量的分布图,得到研究区冬小麦叶片水分含量与地面实测值较相符。
