省市县一体化森林碳储量估测技术体系
——以广东省为例
2022-10-17薛春泉陈振雄杨加志曾伟生林丽平刘紫薇张红爱苏志尧
薛春泉,陈振雄,杨加志,曾伟生,林丽平,刘紫薇,张红爱,苏志尧
(1.广东省林业调查规划院,广州 510520;2.国家林业和草原局中南调查规划院,长沙 410014;3.国家林业和草原局调查规划设计院,北京 100714;4.华南农业大学,广州 510510)
气候变化是当今国际社会的热点和焦点,随着全球二氧化碳排放量增加,温室气体严重影响地球气候以及整个地球生态系统,成为威胁人类生存和发展的全球性问题。世界各国以全球协约的方式减排温室气体,提出了自主减排和碳达峰碳中和目标,中国政府在2020年提出“2030年前碳达峰、2060年前碳中和”的双碳目标[1]。森林碳汇是实现碳中和进程的重要一环,林业活动产生的森林碳汇是降低大气温室气体增长的一个较好选择[2]。
广东省是碳排放大省,也是国家首批低碳试点省和国家7个碳排放权交易试点省之一,减排增汇的任务重大,研究掌握广东省森林生态系统的碳汇潜力,对于提升广东省森林经营质量和助力碳中和目标的实现具有重要意义。同时,实施双碳战略,对地方政府开展碳中和实施情况考核评价,需要掌握全省以及各市、县的森林碳储量本底。森林碳储量计量是碳汇核算的基础,建立科学的区域森林碳储量核算体系是准确评估一个地区森林碳汇作用的前提[3]。当前,区域森林碳储量的核算数据主要有3个来源:一是5年一次的国家森林资源连续清查数据,它具有涵盖面广、调查时间连续、具有可比性等特点[3],在监测和评价全国和各省(自治区、直辖市)森林碳汇中起到重要作用[4-9],但缺点是只在省域尺度上有统计精度,不能产出市级、县级的森林碳储量;二是10年一次的森林资源二类调查年度更新数据[10-15],其优点是数据比较全面、翔实,可产出省、市、县各级数据,缺点是数据缺乏精度、调查周期比较长;三是遥感监测数据,它对森林面积的判读具有省时省力的优势,在宏观尺度上对估测生物量也有一定应用,但数据估计精度有所欠缺,尤其对于小尺度生物量估测准确度不高。3种数据各有其优缺点,有必要建立科学合理的利用3种数据的省市县森林碳储量核算一体化技术体系。2021年起,国家林业和草原局构建了全国森林、草原、湿地调查监测评价体系,整合各类监测资源[16],通过森林样地调查产出以省为总体的森林蓄积量、生物量和碳储量等储量数据,通过图斑监测产出全省以图斑为基本单元的森林面积、林分因子等属性数据。
本研究以2017年广东省国家森林资源第九次连续清查产出的森林储量数据为依据,建立不同森林类型的林分储量模型,基于2018年广东省森林资源二类调查数据,以模型技术、数据耦合技术为支撑,把广东省样地调查的全省森林储量耦合到森林资源档案数据中的森林图斑,逐级汇总到村、镇、县、市、省,建立一个与当前森林资源监测相匹配的区域森林碳储量估测技术体系,实现省-市-县碳储量估计标准的统一,为地方各级政府提供不同层次、不同需求的森林碳储量估计结果。
1 材料与研究方法
1.1 数据来源
广东省国家森林资源连续清查体系建立于1978年,按公里网格6km×8km系统布设样地3 685个,每个样地为边长25.82m、面积666.67m2的正方形样地,自1983—2017年,每5年开展一次复查,产出以抽样调查统计为基础的全省森林蓄积量等储量数据。自2021年起,国家林业和草原局构建全国森林、草原、湿地调查监测评价体系,采取系统抽样的方法,按照5年一个调查周期,将全部样地均匀分成5组,每年调查其中1组,通过系统加密布设样地,构成广东省森林样地年度调查总体。森林样地主要调查因子包括胸径、树种名称等样木信息和起源,还包括郁闭度、平均胸径、平均树高等样地信息。其余4组样地的数据则通过联合估计的方法进行回归预测计算[16]。
本研究利用2017年广东省国家森林资源第九次连续清查乔木林样地数据,以不同森林类型的森林蓄积量、生物量和碳储量作为建模的目标变量,以林分断面积和林分平均高为解释变量,拟合不同森林类型的储量回归模型。剔除异常样地后,参与建模的样地数共有1 384个。建模样地的公顷蓄积量特征如表1所示。

表1 建模样地每公顷蓄积量的特征值
广东省在1983年、1993—1994年、2003—2004年、2015—2017年间分别开展了4次森林资源二类调查,产出以斑块为基础的森林面积等资源数据,且每年开展森林资源档案更新工作,产出年度森林资源数据。2021年,按照《自然资源调查监测体系构建总体方案》要求,森林资源档案数据与第三次全国国土调数据融合,且每年开展图斑监测,产出年度图斑数据。本研究利用的是2018年森林资源二类调查数据。
1.2 研究方法
1.2.1样地调查全省森林储量的计算
森林储量包括森林蓄积量、生物量和碳储量。根据2017年广东省国家森林资源第九次连续清查乔木林样地数据,统计获取不同森林类型的储量数据,具体计算方法参照《国家森林资源连续清查数据处理统计规范》(LY/T 1957—2011)的标准[17]。
1.2.2样地调查森林储量模型的拟合
1.2.2.1森林类型的划分
根据广东省森林主要优势树种情况,将广东省森林划分为9种类型(表2)。

表2 主要森林类型划分
1.2.2.2森林储量模型的拟合
联立模型由于其模型之间存在有机联系,模型的稳定性和评价指标要优于独立模型[18],因此,本研究通过建立三储量联立模型实现对森林蓄积量、生物量和碳储量的联合估计。
林分水平的单位面积蓄积量与断面积最大正相关,林分平均高等也是其主要决定因子;单位面积生物量与林分蓄积量最大正相关,林分平均高等因子也有相关性;单位面积碳储量主要与生物量和含碳系数有关[18-19]。因此,本研究以不同森林类型的单位面积蓄积量作为建模的目标变量,以林分断面积、林分平均树高为解释变量,拟合不同类型森林蓄积量二元估测模型;再以蓄积量为基础,建立林分生物量和林分碳储量估测模型。模型基本表达式如下:
(1)
G=1/4πD2N
(2)
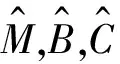
1.2.2.3模型评价
采用确定系数(R2)、估计值的标准差(SEE)、平均预估误差(MPE)、平均百分标准误差(MPSE)、总体相对误差(TRE)和平均系统误差(MSE)等6项指标,综合评价模型预估效果。对所拟合的模型,要求TRE在±5%以内,MPE小于5%,MPSE小于15%。
1.2.3森林储量数据耦合
以样地调查统计得到的全省森林碳储量估计值作为总体控制数,以森林资源二类调查的面积数据为基础,采用建立的不同森林类型的森林蓄积量、生物量和碳储量联立估测模型,根据各个森林图斑的林分断面积G、林分平均高H、图斑面积A,由公式(3)得出图斑i的森林储量模型估测值yi,再根据公式(4),将全省的森林储量数据耦合到图斑,并逐级汇总到县、市、省,从而实现储量数据的点面耦合。
yi=SiAi
(3)
(4)
式中:yi为图斑i的储量模型估测值,Si为图斑i的模型估测的单位面积储量(蓄积量、生物量、碳储量),Ai为图斑i的面积;yti为图斑i经过总控调整后的储量,Yz为样地调查得到的全省森林总储量。
2 结果与分析
2.1 森林储量
2017年广东省国家森林资源第九次连续清查乔木林样地数据统计得出的结果为:森林蓄积46 755.09万m3,森林生物量49 986.26万t,森林碳储量24 814.76万t。
2.2 林分储量模型
表3是对不同森林类型蓄积量、生物量和碳储量模型的拟合和检验评价结果。各模型的确定系数(R2)均在0.94以上,蓄积量、生物量和碳储量预估模型的确定系数(R2)分别在0.958~0.994,0.944~0.990和0.941~0.990之间,桉树和软阔类森林储量模型确定参数(R2)达到了0.98以上水平,各森林类型的储量模型具有较高的确定性,森林蓄积量与林分断面积、林分平均高相关性显著,森林生物量与森林蓄积量和树高也有很高的相关性,拟合模型的预测性能良好。

表3 森林储量模型的参数估计值及评价指标
平均预估误差MPE和平均百分标准误差MPSE是模型评价的核心误差指标[19-20],主要用于衡量模型的实用性。各储量模型的平均预估误差MPE最高为3.00%,表明各模型针对总体估计值的平均误差不超过3%;平均百分标准误差MPSE在3.95%~10.64%,仅有针阔混的生物量和碳储量模型分别为10.62%和10.64%,其余各模型的MPSE均低于10%,表明各模型针对图斑或林分的预估精度也具有较高水平,最低可达到89.36%以上,储量模型可以满足《森林资源规划设计调查技术规程》[21]对小班蓄积量调查的A级相对误差不超过15%的精度要求,模型可以在森林小班储量调查中推广应用。其它模型评价指标SEE,TRE和MSE也均在允许范围内,表明模型的预估精度可以达到预期要求。
2.3 森林储量数据耦合
基于2018年森林资源二类调查数据库,以2017年广东省国家森林资源第九次连续清查全省森林储量作为总体控制数,对森林图斑的蓄积量、生物量和碳储量进行更新计算,并逐级汇总,得出各村、镇、县区、地级市的森林储量。森林图斑模型估测值三储量数据与样地调查统计三储量数据的误差占比分别为8.4%,-0.4%,-0.8%。各地级市的森林储量如表4所示。
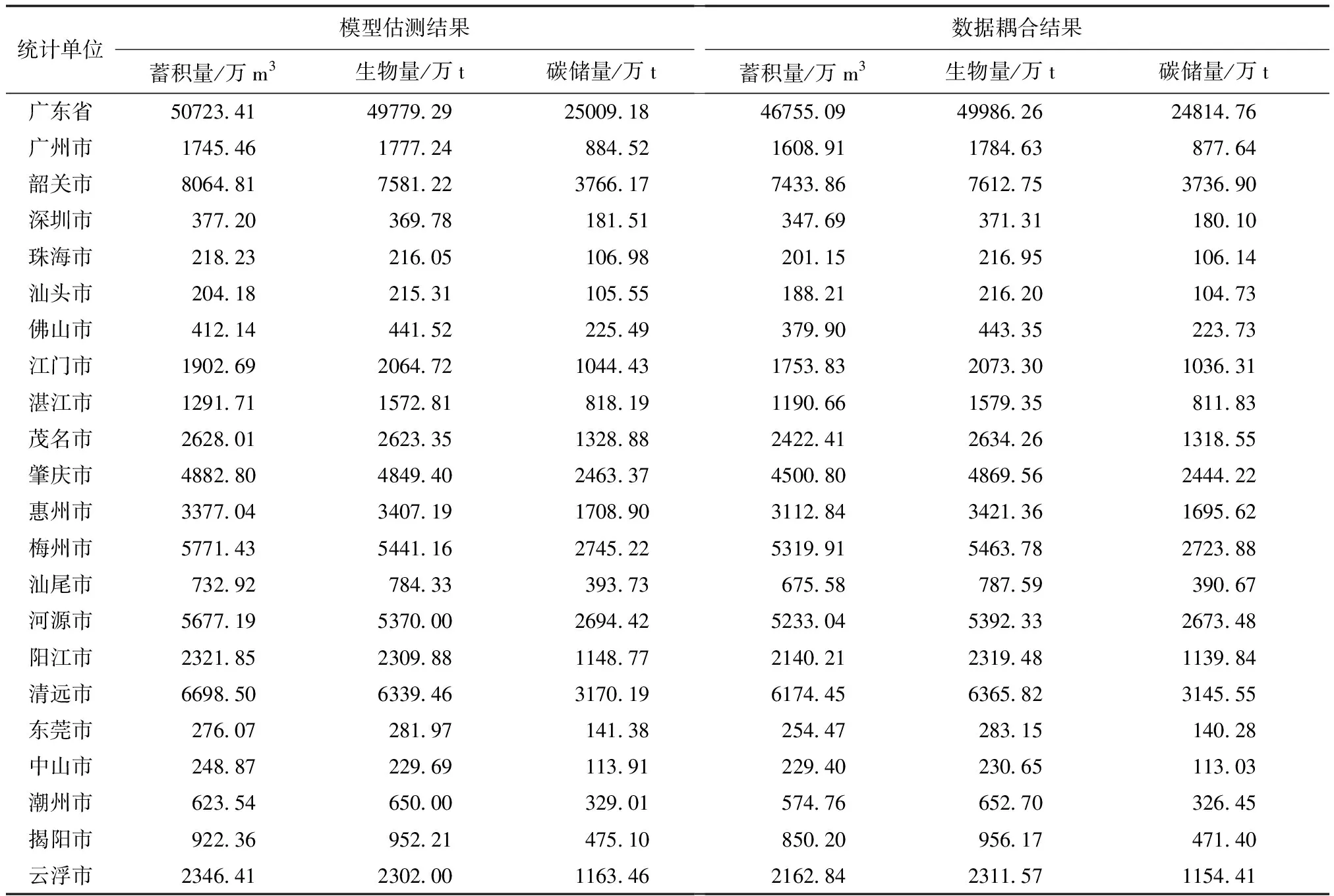
表4 基于数据耦合的广东省各地级市森林储量数据
3 结论与讨论
本研究利用2017年广东省国家森林资源第九次连续清查数据、2018年森林资源二类调查小班数据,针对不同森林类型,以森林储量为目标变量、以林分断面积和林分平均高为解释变量,构建了森林蓄积量、生物量和碳储量联立预估模型,各模型表现良好,确定系数R2均在0.94以上,平均预估误差MPE小于3%,平均百分标准误差MPSE均小于15%(大部分小于10%、最高不超过11%),各项评价指标表明模型具有较高的实用性。
利用拟合的模型,以广东省2018年森林资源二类调查小班数据为基础,估测了2018年广东全省及各地级市的森林蓄积量、生物量和碳储量,森林图斑模型估测值三储量数据与样地调查统计三储量数据的误差占比分别为8.4%,-0.4%,-0.8%。模型估测的蓄积量值偏大的原因是二类调查图斑统计中包括了部分非林地森林的蓄积。
本研究采用林分断面积、林分平均高作为解释变量进行蓄积量模型构建,虽然模型精度高,但其中林分断面积是小班调查中的间接计算因子,由林分平均胸径、林分株数决定,这两个因子可以在森林资源档案数据中直接获取,后续研究中可构建林分的平均胸径、株数、郁闭度等因子为解释变量的森林蓄积量、生物量和碳储量模型,作为在林分断面积、平均树高等因子缺失下的补充模型[20]。
本研究提出的以样地调查的储量和相关因子建立模型,结合模型技术、数据耦合技术,用样地调查的全省森林储量作为总体控制数,量化各市、县的森林储量,从而使国家—省—市—县的储量数据在该技术体系下得到统一。结果表明,通过利用森林、草原、湿地调查监测数据,建立碳储量核算技术体系,模型准确、精确度高,耦合的全省储量数据有精度保证。该技术体系可以在省、市、县碳中和目标实施情况的考核评价中推广应用。基于建立的模型,利用国家森林、草原、湿地年度调查监测产出年度森林样地调查和图斑监测数据,可以核算省、市、县森林储量,助力碳中和目标的实现。
