基于C3D和CBAM-ConvLSTM的犯罪事件视频场景分类
2022-10-17李燕,何敏
李 燕,何 敏
(甘肃政法大学,兰州 730070)
近年来,随着我国安防领域的不断发展,安防相关技术也越来越成熟,例如人脸识别技术、大数据技术、合成作战系统以及视频监控系统等,其中视频监控系统作为安防工作的核心,在城市安全以及案件侦破等方面起着至关重要的作用。不仅如此,在雪亮工程、天网工程、平安城市等城市建设工程中也都强调了视频监控在安防工作中的重要性[1]。目前,我国大部分城市已经实现监控全覆盖,所产生的大量监控视频是重要的社会治安资源,却也造成了查阅的负担,因此对监控视频进行分类,可以在解决视频数据冗余以及查阅困难等问题的同时,大大提高公安部门的办案效率,做到对重大事件的事前预防、事中响应和事后追查[2],从而保障城市的安全运行与发展。
早在2006年美国麻省理工学院召开的场景理解研讨会上,图像场景分类技术第一次被明确定义为分类的一个关键课题,这表明场景分类技术在计算机视觉领域的重要地位[3]。目前,从分类过程中涉及的特征来看,针对视频及图像的场景分类方法可大致分为两种:第一种是基于传统手工设计特征的分类算法,第二种是基于深度学习的分类算法。
基于传统手工设计特征的分类算法主要是提取视频及图像的颜色、纹理、整体、局部、显著区域等特征,然后再进行场景分类。2001年Oliva等[4]率先对场景快速识别与分类展开研究,提出使用傅里叶变换对分割后的图像区域进行特征提取,再用PCA/ICA技术对特征进行降维,最后通过神经网络进行分类,文中在提出分类方法的同时还阐述了场景快速识别与分类的流程。Itti等[5]提出先使用Gabor滤波法对提前划分好的图像在颜色、方向和密度三个通道上提取特征,然后使用PCA/ICA技术对特征进行降维,最后通过神经网络进行分类。Theriault等[6]提出利用无监督学习对视频进行分类。刘扬等[7]针对球场颜色的非均一问题提出自适应高斯混合模型(GMM)对球场进行检测,首先从视频中随机抽取图像,找到图像中主颜色的大致分布,然后利用GMM拟合主要颜色的分布,不断更新模型参数来提高模型的适应能力,最后,利用球场区域在图像中的分布,对足球赛场景进行分类。刘林等[8]提出利用多颜色空间和累计直方图对场景进行分类。彭太乐等[9]提出利用关键帧之间的时序关系结合词袋模型,对视频进行分类。贾澎涛等[10]提出多特征的视频场景分类,首先提取视频的平均关键帧,再将关键帧划分成感兴趣区域与不感兴趣区域,之后再分别提取场景特征,最后将特征进行融合并利用特征阈值对场景进行分类。
基于深度学习的分类算法主要是通过构建深度学习模型,利用端到端的训练方法,提取图像或视频的高级语义特征,以此对图像或视频进行分类。Li等[11]提出利用预先训练好的卷积神经网络提取不同层的深度特征,再利用多尺度的改进Fisher核编码对中层特征进行编码,最后,用主成分分析或者谱回归判别分析方法将提取的各层特征融合进行分类。Zhu等[12]提出了FASTER视频分类框架,先利用深层神经网络提取动作细节特征,再利用浅层神经网络提取背景特征,以此来避免冗余,再使用论文中新设计的FAST-GRU来聚合来自不同剪辑模型的表示问题,最后对视频进行分类。Bird等[13]提出将图像特征和音频特征进行融合对视频进行分类,首先利用微调的VGG16提取图像特征,再利用优化过的深度神经网络提取音频特征,然后再将提取的特征进行融合,最后得出视频分类结果。程萍等[14]提出利用帧间差分法和徽标检测法对分割镜头进行监测,然后提取分割镜头的语义特征,最后通过C3D对视频进行分类。
目前,大多数分类算法都是针对自然场景、城市场景以及室内场景设计的,很少有对事件场景进行分类的。本文针对城市安全问题,提出一种基于深度学习的犯罪事件分类方法,旨在更快更高效地对监控视频进行分类,以协助平安城市安防系统的建成。该方法有效结合了C3D和CBAM-ConvLSTM,通过提取监控视频的时间和空间特征,实现了对监控视频犯罪事件的有效分类。
1 相关理论
1.1 3维卷积神经网络
3维卷积神经网络(3D convolutional neural network,C3D)是2015年由Tran等[15]提出的,主要是为了解决2D卷积缺乏运动建模问题。C3D可以理解为三个通道上的卷积,比2D卷积多了时间通道。3D与2D卷积核对比如图1所示。
2D卷积核其大小为C×h×w,其中C表示卷积核的通道数,h和w表示卷积核的高和宽。3D卷积核的大小为t×C×h×w,其中t表示3D卷积核的时间长度,其他与2D卷积核相同。由2D卷积核的形状可知其仅对图片的宽和高进行操作,所以不管输入一张图片还是多张图片,最后提取的也只是图片的空间特征。而3D卷积不仅会对图片的宽和高进行操作,还会对时间轴操作,能同时提取空间和时间特征。正因为3D卷积能同时提取空间和时间特征,故论文使用预训练的C3D模型作为特征提取网络,在使用时只使用特征提取部分。C3D模型如图2所示。
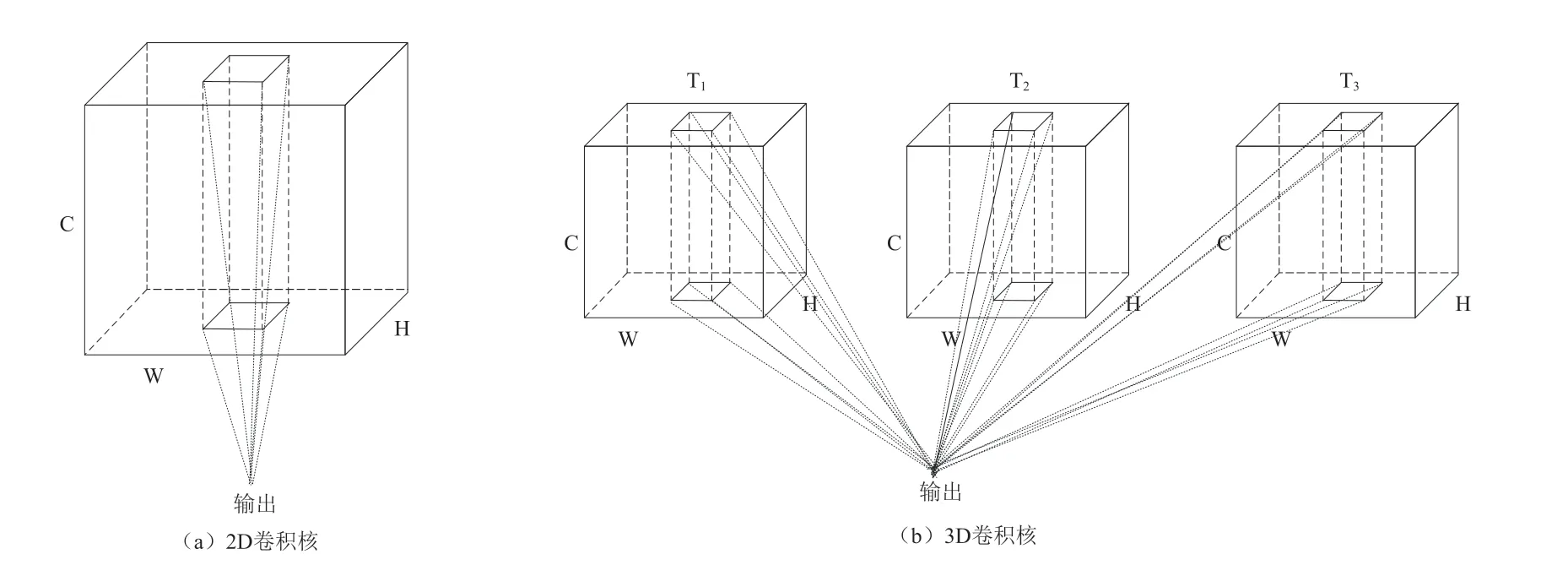
图1 2D(a)与3D(b)卷积核对比Fig. 1 Comparison of 2D (a) and 3D (b) convolution kernels

图2 C3D模型图[15]Fig. 2 C3D model [15]
1.2 注意力机制
注意力机制作为一种资源分配方案,将有限的计算资源用来处理更重要的信息,是解决信息超载问题的主要手段。卷积注意力模块 (convolutional block attention module,CBAM)是2018年由Woo等[16]提出的一种轻量级通用的注意力模块,可以在通道和空间两个维度上关注重要信息。
CBAM的结构如图3所示,CBAM包含两个独立的子块,通道注意力模块(channel attention module)和 空 间 注 意 力 模 块(spatial attention module),两个模块分别凸出通道维度和空间维度上的重要特征。
1.3 ConvLSTM
ConvLSTM网 络 是2015年 由Shi等[17]提 出,用于解决降水预报问题。ConvLSTM网络是将原LSTM网络的全连接权重改为了卷积权重,这种改进使LSTM网络能够同时掌握时间和空间信息,克服了只能建模序列的问题。为了更好地了解输入和状态,可以把它们想象成站在空间网格上的向量,ConvLSTM通过输入和其他本地邻居过去状态来确定网格中某个网格的未来状态。这可以很容易地通过在状态到状态和输入到状态的转换中使用卷积运算符来实现,其实现状态如图4所示。
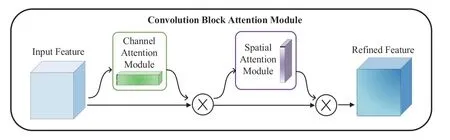
图3 CBAM结构图[16]Fig. 3 CBAM structure [16]
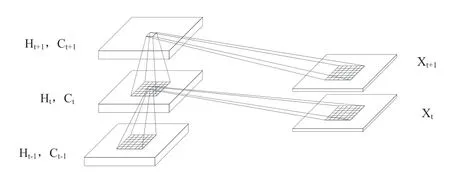
图4 ConvLSTM内部结构[17]Fig. 4 Inner structure of ConvLSTM[17]
2 模型构建
2.1 模型介绍
本文设计了一种基于C3D和CBAM-ConvLSTM的犯罪事件视频场景分类模型,旨在准确高效地对监控视频中的犯罪事件进行分类。基于C3D和CBAM- ConvLSTM的犯罪事件视频场景分类主要包括两部分:视频特征提取部分和视频事件分类部分。
视频特征提取部分由C3D网络提取局部时空特征,然后结合3维时空注意力和3维通道注意力,凸出比较重要的局部时空特征;视频事件分类部分由CBAM-ConvLSTM提取视频的全局时空特征,然后由全连接层映射出最终结果。论文提出的模型架构如图5所示。
模型的特征提取部分(图5中红线的上半部分),先用预训练的C3D网络提取监控视频的局部时空特征,然后将提取的视频特征序列放入3维时空注意力和3维通道注意力模块中,用于凸显分类相关特征或削弱无关特征。模型的视频分类部分(图5中红线的下半部分)把上半部分提取的局部特征序列作为输入,利用CBAM-ConvLSTM网络提取局部特征序列的全局时序特征和全局空间特征。
因为本文提出的CBAM-ConvLSTM是ConvLSTM 与注意力结合,使得网络在提取时序特征的同时也加强了对空间特征的提取。最后使用全连接层对全局特征进行分类。
在模型的特征提取部分,文中对其空间注意力机制和通道注意力机制作出改进,将本为2维的注意力机制中加入时间维度,转变为3维注意力机制,使得模型不仅能在空间维度和通道维度上凸显出重要特征,也能在时间维度上凸显出重要特征,改进后的注意力机制将在本文2.2节中详细介绍。
在模型的视频事件分类部分,文中对ConvLSTM 网络作出改进,旨在提取更有利于提高分类准确性的全局特征。改进后的网络将在本文2.3节中详细介绍。
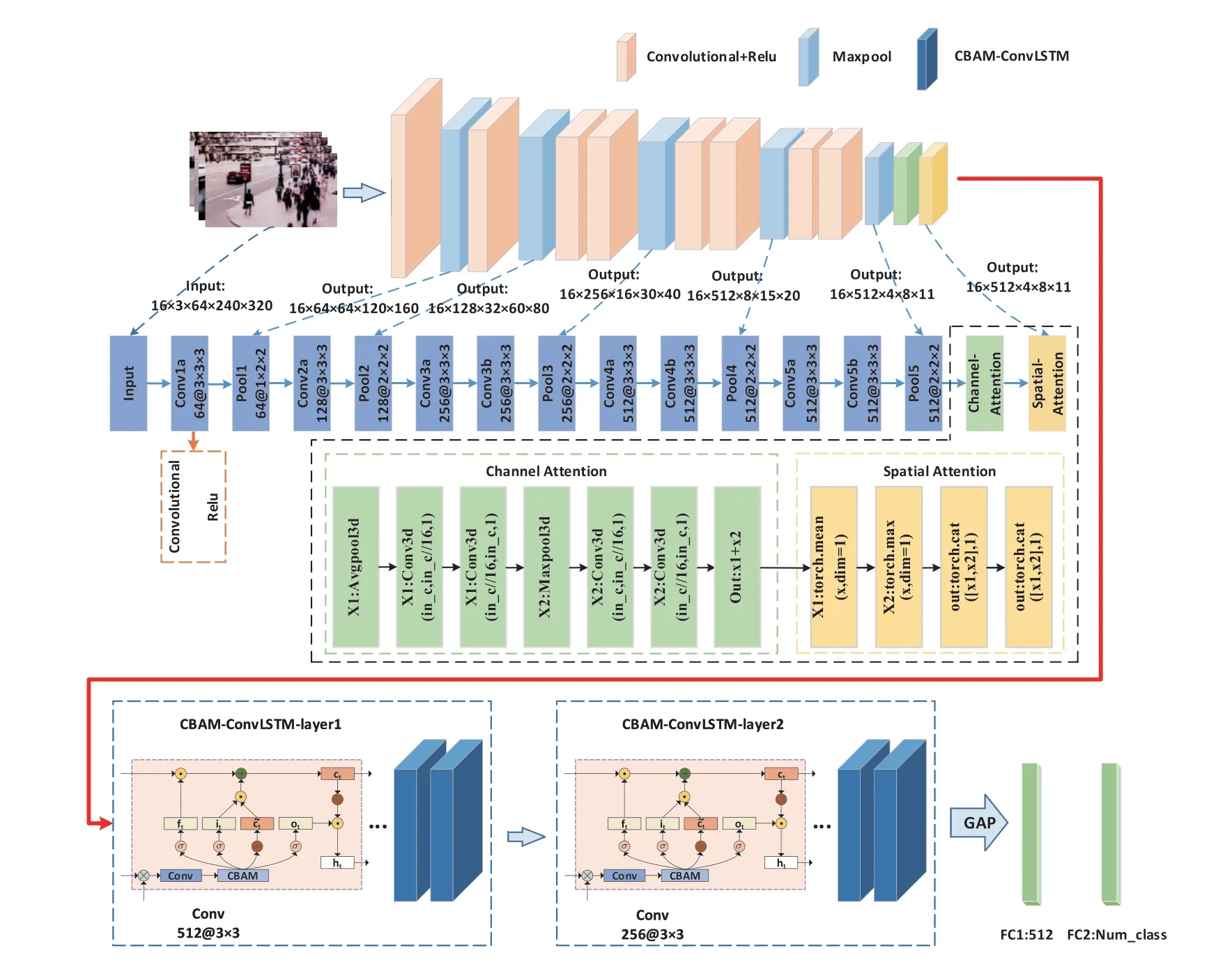
图5 模型架构图Fig. 5 Model architecture adopted with this paper
2.2 3维注意力机制
2.2.1 3维通道注意力模块
在卷积中,一个卷积核代表了一个通道,不同的卷积核对特征的影响也不同,使用通道注意力的目的是在不同的时间上将注意力集中在对最终结果影响较大的通道上。通道注意力模块由两个池化层、多层感知机、激活函数组成。3维通道注意力的网络模型架构如图6所示。
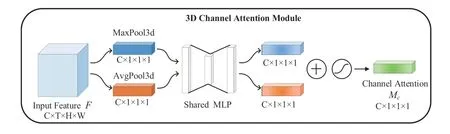
图6 3维通道注意力模型图[16]Fig. 6 3D channel attention model [16]
其中表示按位相加,表示sigmoid的激活函数。具体实现过程为:首先分别利用3维平均值池化和3维最大值池化来聚合输入特征的空间信息,生成两种不同的时空上下文描述符;再将两个时空上下文描述符分别送入一个共享权重的多层感知机中,得到两个特征图;最后将得到的两个特征图进行逐元素求和并用sigmoid函数激活得到最后的通道注意力权重。通道注意力的计算公式为:
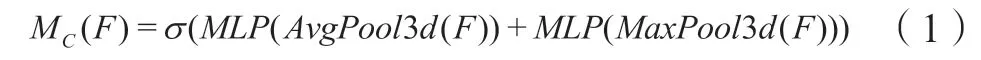
其中MLP代表两层神经网络,σ代表sigmoid激活函数。由于本文输入的是视频序列,包含时序信息,所以将通道注意力模块中的平均池化、最大池化由2维扩展为3维,即输入由(batchsize, channel, height, width)改为(batchsize, channel, time_sequential, height, width)。
2.2.2 3维时空注意力模块
3维时空注意力主要是为了集中注意力在对分类有利的时间和空间特征区域上,是对3维通道注意力的补充。时空注意力模块由两个池化层、一个卷积层、一个激活函数组成。时空注意力模块的具体模型架构如图7所示:
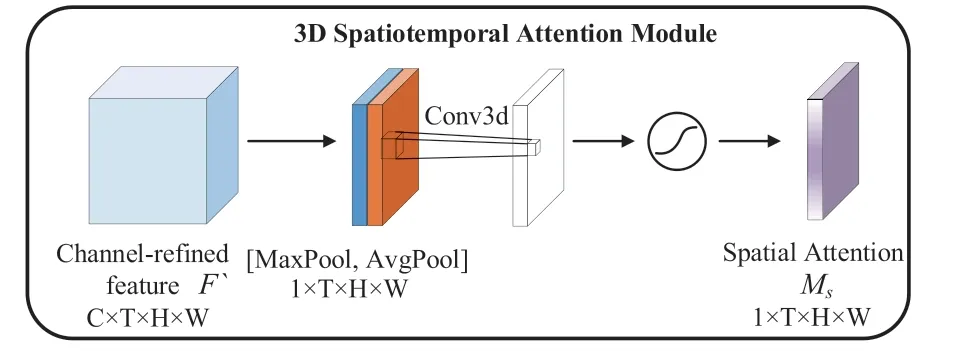
图7 3维时空注意力模型图[16]Fig. 7 3D spatio-temporal attention model [16]
时空注意力的具体过程为:首先分别利用平均池化和最大池化来聚合输入特征的通道信息,生成两种不同的通道上下文描述符;再将两个通道上下文描述符拼接在一起,并经过一个卷积核为7×7×7的卷积层进行信息的聚合;最后用sigmoid函数激活得到时空注意力权重。时空注意力的计算公式为:
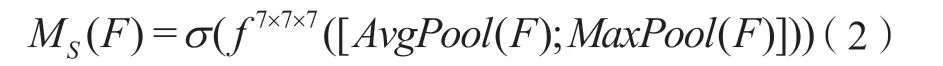
其中ƒ7×7×7代表卷积核为7×7×7的卷积运算,σ代表sigmoid激活函数。与通道注意力相似,本文对空间注意力机制也做出了修改,不但将空间注意力中的平均池化、最大池化由2维扩展为3维,还将2维卷积换成了3维卷积,改进之后的空间注意力机制变为时空注意力机制,因为改进后的注意力机制不仅可以聚焦重要的局部空间信息,还能聚焦重要的局部时间信息,能够在时间和空间两个维度上突出重要特征。
2.3 CBAM-ConvLSTM
为了使模型能够提取出更具代表性的全局时空特征,文中对ConvLSTM网络作出了改进。ConvLSTM网络由多个cell组成,文中在每个cell中加入注意力机制,增强了网络提取全局时空特征的能力,同时能更准确地提取出代表性特征。文中将改进后的ConvLSTM简记为CBAM-ConvLSTM,结构图如图8所示。
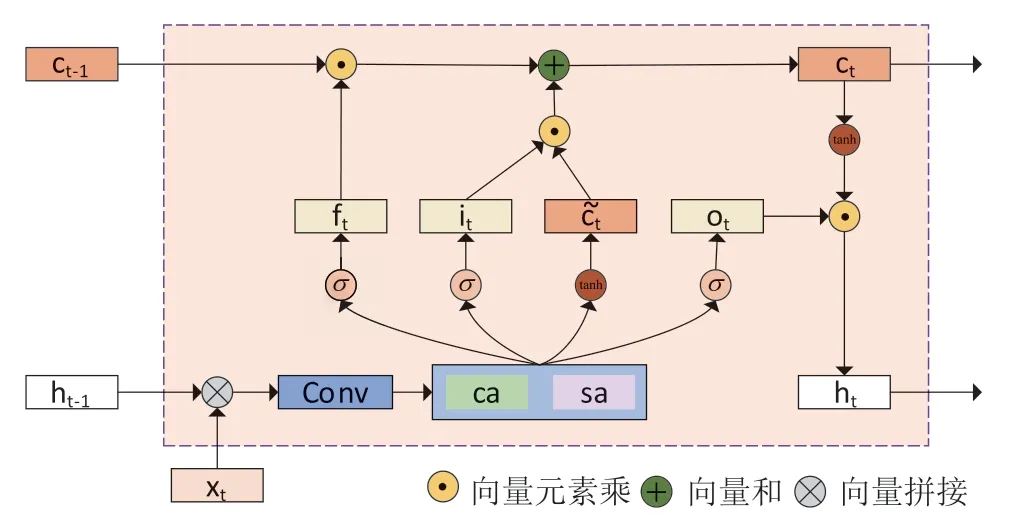
图8 CBAM-ConvLSTM结构图Fig. 8 CBAM-ConvLSTM structure
由上图可知,CBAM-ConvLSTM网络的计算过程可分为三个步骤:首先将上一时刻的外部状态ht-1和当前时刻的输入xt按通道维度拼接在一起,并进行卷积,再将卷积提取的特征作为CBAM的输入,最后通过对CBAM的输出进行切分操作得到遗忘门ƒt、输入门it、输出门ot和当前时刻的内部状态ct。遗忘门ƒt决定上一时刻的内部状态ct-1需要遗忘多少信息,当ƒt=0时表示完全忘记,当ƒt=1时表示完全保留;输入门it决定当前时刻的内部状态需要保留多少信息,当it=0时表示所有的信息都不保留,当it=1时表示保留全部的信息;输出门ot决定当前时刻的内部状态ct有多少信息需要输出,当ot=0时表示不输出,当ot=1时表示全部输出。遗忘门、输入门、输出门和当前时刻的内部状态的计算 公式为:

其中Wxf、Wxi、Wxo和Wxc分别为遗忘门、输入门、输出门和当前时刻的内部状态的状态-输出权重矩阵;Uhf、Uhi、Uho和Uhc分别为遗忘门、输入门、输出门和当前时刻的内部状态的状态-状态权重矩阵;bf、bi、bo和bc分别为遗忘门、输入门、输出门和当前时刻的内部状态的偏置向量;*表示卷积操作;C表示CBAM操作;σ表示sigmoid的激活函数;tanh表示tanh激活函数。
然后,由上一时刻的状态、输入门、遗忘门和当前时刻的内部状态计算出当前时刻的状态,当前时刻的内部状态的计算公式为:

其中⊙为矩阵的Hadamard乘积。
最后,用输出门和当前状态相乘得到当前时刻的外部状态,当前时刻的外部状态的计算公式为:

2.4 模型的详细参数
本文模型较为复杂,其中特征提取部分的C3D网络由8层3维卷积和5层池化组成,卷积核大小均为3×3×3;事件分类部分由2层CBAMConvLSTM网络和2层全连接层组成,CBAMConvLSTM中的卷积核大小3×3,全连接层的神经元个数分别为512、3。由于特征提取部分的C3D网络不但层数较多,而且参数量庞大,所以利用迁移学习的方法,使用Sports-1M体育视频数据集对C3D网络进行预训练。
在训练模型时,为了使模型快速收敛,得到局部最优解,使用交叉熵计算模型的损失,并使用Adam优化器更新模型的参数。
3 实验结果与分析
3.1 数据集
UCF-Crimes数据集是Sultani等[18]在2018年提出的监控视频下的异常检测数据集。该数据集分为14类,共有1 900段监控视频。虽然UCF-Crimes数据集种类多,数量大,但是数据集中存在一些严重的问题,比如,监控视频的画质差;部分监控视频中存在镜头切换、重复、尺寸不一;类别界定不清晰(比如,纵火和爆炸、虐待和斗殴等)。
所以本文通过对UCF-Crimes数据集进行裁剪、去重、归整等一系列操作,自建了一个包含打架斗殴、交通事故以及故意破坏3类监控视频的数据集Crimes-mini。打架斗殴类包含两人互殴和多人群架,这类视频共包含74个;交通事故类包含汽车之间、汽车与行人之间、汽车与自行车之间发生的碰撞,这类视频共包含87个;故意破坏类包含故意破坏或损坏公共或私人财产的行为,这类视频共包含90个。数据集中的部分视频如图9所示。
本文在使用Crimes-mini数据集时,采用定长抽帧的方法在视频中抽取64帧,由于视频长度不同,所以抽帧的间隔帧数也不同。最后将每帧图像的大小统一调整为240×320。
Hockey数据集为常用的暴恐检测数据集,曲棍球比赛中的打斗视频,一共有1 000个视频片段,其中500个为曲棍球比赛中的暴力视频片段,另外500个为正常曲棍球比赛视频。每个视频片段的分辨率为360×288,数据集中部分样本如图10所示。

图9 Crimes-mini数据集样本图像(a:打架斗殴;b:交通事故;c:故意破坏)Fig. 9 Sampling images with Crimes-mini dataset (a: fighting; b: road accident; c: vandalism)

图10 Hockey数据集样本图像(a:暴力视频;b:正常比赛)Fig. 10 Sampling images with Hockey dataset (a: violence in video; b: normal match)
3.2 实验过程
3.2.1 卷积核的设置
本文选用CBAM-ConvLSTM网络作为监控视频犯罪事件场景分类的全局特征提取网络,CBAM- ConvLSTM网络由LSTM、卷积层和注意力机制组成,其中卷积层用于提取全局空间特征,LSTM用于提取全局时序特征,注意力机制用于凸显对分类贡献最大的时空区域。由于卷积层提取的全局空间特征是注意力机制和LSTM的输入,因此卷积层提取全局空间特征的能力至关重要。而卷积层提取全局特征的能力由卷积核决定,所以本节将CBAMConvLSTM网络中卷积核分别设置成1×1、3×3、5×5、7×7,在Crimes-mini数据集上通过实验分析不同卷积核提取全局特征的能力,及模型对犯罪事件视频场景分类结果的影响。不同卷积核的实验结果如图11所示。
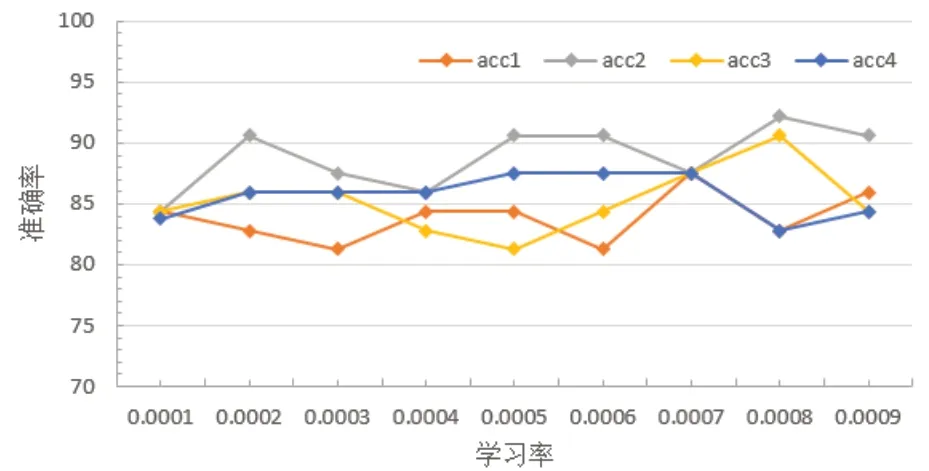
图11 不同卷积核对准确率的影响Fig. 11 Effect of different convolution kernels on accuracy
图11中的acc1、acc2、acc3、acc4分别表示卷积核为1×1、3×3、5×5、7×7时准确率的变化曲线。当卷积核为1×1时,感受野为1,无法获取和聚集当前区域与邻域之间的联系,相当于不同通道间的信息做线性变换,不能达到提取全局特征的效果。随着卷积核的增大,感受野也会增大,但是因为CBAM-ConvLSTM网络每个时间步输入和输出的特征图大小相同,所以在卷积时需要根据卷积核的大小对输入进行填充,因为填充的数值是0,相当于在输入中加入了噪声,这对特征提取会造成很大的影响,且这种影响会随着时间步的叠加不断累积。当卷积核为5×5、7×7时,填充后的特征中一半以上的数值为0,不利于全局特征的提取。只有当卷积核为3×3时,既能同时弥补以上缺陷,又能提取出最有利于分类的全局特征,所以本文选用3×3的卷积核。
3.2.2 学习率的设置
学习率是神经网络优化时的重要超参数,在梯度下降法中,学习率的取值非常关键,如果过大就会不收敛,如果过小则收敛太慢,在不同的学习率下F1值变化如图12所示。
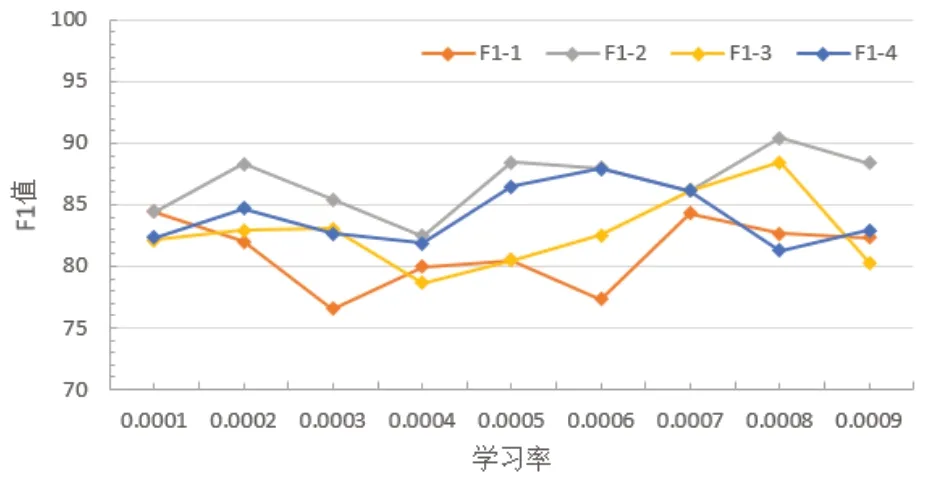
图12 不同学习率对F1值的影响Fig. 12 Effect of different learning rates on F1 value
图12中的F1-1、F1-2、F1-3、F1-4分别表示卷积核为1×1、3×3、5×5、7×7时F1值的变化曲线,由图可知,当卷积核为3×3时,F1值普遍大于其他三种情况,再一次验证了上一节的说法。由图11、12可知,当卷积核为3×3,学习率为0.000 8时准确率和F1值达到最大。
3.3 实验结果分析
本文设计的基于深度学习的监控视频犯罪事件分类算法,在自建的监控视频Crimes-mini数据集和公开的暴力行为Hockey数据集上进行实验。在实验过程中,数据集的80%作为训练集,20%作为测试集。使用训练集进行模型训练,通过迭代更新参数,以获得局部最优解;用测试集评价模型,并用准确率及F1值作为评价指标。
由于目前学界对监控视频犯罪事件的研究较少,且本文是在自建的Crimes-mini数据集上进行实验,所以利用消融实验的方法,验证所提模型的有效性。实验结果如表1所示。
对比模型1和3,可知LSTM提取全局时序特征的能力比C3D更好;对比模型2和3,可知先使用C3D聚合局部时空特征比直接使用ResNet2d网络提取空间特征对分类更有益;对比模型3和4,可知加入注意力机制后更能凸显有利于分类的时空特征;对比模型4和5,可知ConvLSTM比LSTM提取出的全局时空特征更好;对比模型5和7,可知在ConvLSTM中加入CBAM之后,模型提取全局时空特征的能力更强,分类效果更好;对比模型6和7,可知在加入3维通道注意力和3维时空注意力后,模型局部特征提取能力更强,更能体现出视频中对分类有益的局部特征。
综上所述,本文提出的模型7能更好地对监控视频犯罪事件进行分类。为了进一步验证本文模型的有效性,本文在公开暴恐数据集Hockey数据集上进行消融实验,表2展示了消融实验结果。为了综合评估本文所提模型的性能,将本文所提模型与其他几种先进算法进行比较,对比数据如表3所示。
表3中ViF+OViF是利用光流信息提取出视频的ViF特征(描述观测到的运动幅度的变化)和OViF特征(描述了运动幅度和运动方向的信息),再将两种特征结合在一起,最后使用AdaBoost+Linear-SVM进行暴力视频的检测[19];3D-CNN将2维卷积扩展为3维卷积,可以同时提取时间和空间上的特征,最后再对提取的特征进行暴力检测[20];Three streams+ LSTM提出将双流网络扩展为三流网络,每个分支分别使用2D-CNN和LSTM提取特征,三条分支分别为空间特征提取分支、时间特征提取分支和动态信息特征提取分支,最后采用分数级融合策略进行检测,这种方法是针对人-人暴力检测提出的[21]; MoSIFT+ KDE+Sparse Coding首先采用MoSIFT算法提取查询视频的低层描述,为了消除特征噪声,利用基于核密度估计(KDE)的特征选择方法对MoSIFT描述子进行特征选择,选择最具代表性的特征,然后采用稀疏编码(sparse coding)将简化的低级描述符转换为紧凑的中层特征,最后使用SVM分类器进行分类,得出结果是否为暴力视频[22];C3D+SVM使用3D-CNN网络提取视频的时空特征,再使用SVM分类器进行分类[23];MoIWLD先使用高斯滤波器提取MoIWLD描述符,然后使用核密度估计(KDE)特征选择方法,从所提描述中去除冗余和无关特征,然后再使用文中提出的稀疏模型(SRC)得到最后的分类结果[24];FightNet将视频帧特征、光流特征和图像加速度特征作为网络的输入,得到检测分数,最后将三种分数进行融合得到最后检测结果[25];ConvLSTM使用两帧之差作为输入,使用预训练的AlexNet网络提取视频帧的空间特征,再使用ConvLSTM网络提取时序特征,最后再对视频进行分类[26];3DCNN+ConvLSTM使用3D-CNN网络提取视频的短时特征,然后使用ConvLSTM网络提取视频的高层时序特征,最后,利用sigmoid函数进行分类[27]。

表1 Crimes-mini数据集消融实验结果对比Table 1 Comparison of ablation tests into the Crimes-mini dataset

表2 Hockey数据集消融实验结果对比Table 2 Comparison of ablation experiments into the Hockey dataset
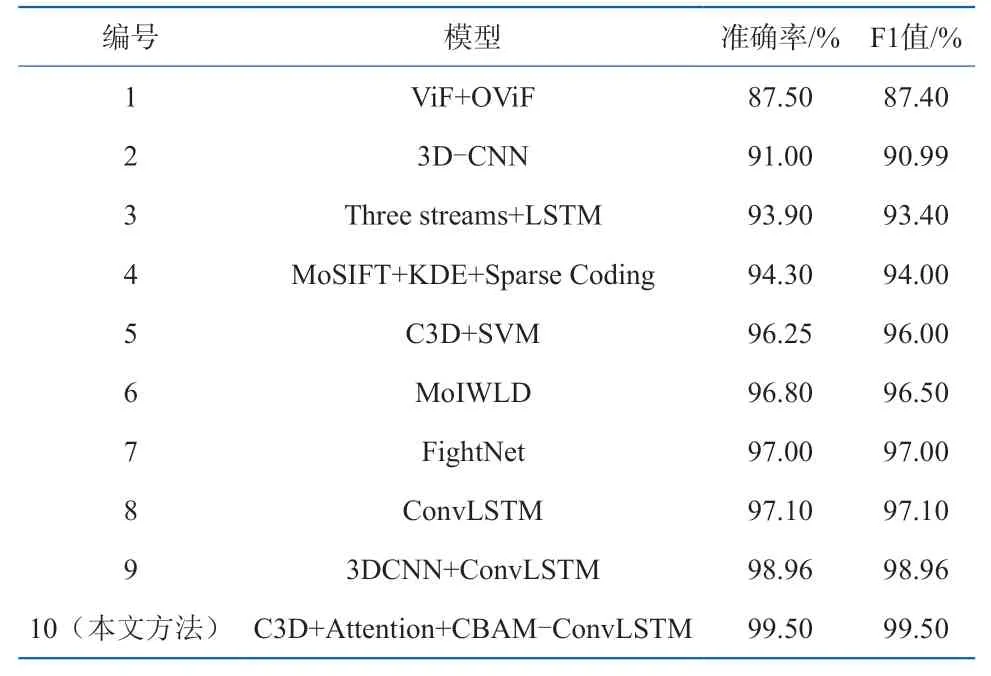
表3 Hockey数据集上与其他暴力行为检测算法比较Table 3 Comparison among the violent behavior detection algorithms with the Hockey dataset
本文所提模型在Hockey数据集上的识别精度达到了99.50%,优于大多数的暴力检测算法。与传统的暴力检测算法MoIWLD相比识别精度提高了2.70个百分点,目前大多数的传统方法会使用光流信息,计算光流信息会大大增加模型的计算量,无法做到端到端的训练和识别。与深度学习的算法相比,比目前识别精度最高的3DCNN+ConvLSTM网络识别精度提升了0.54个百分点。
本文方法具有先进的识别精度,有两方面原因:1)模型采用3DCNN网络和注意力机制提取视频的局部时空特征,加入注意力机制使得网络在提取局部特征时能够更加准确地定位到视频中行为动作和场景,是一种高效的视频描述符。2)利用CBAMConvLSTM网络对局部时空特征进行建模,提取视频的全局时空特征,进一步挖掘出视频的前后联系和视频中的空间信息。
4 结语
本文针对监控视频提出了一种基于深度学习的犯罪事件场景分类模型。通过C3D网络和注意力机制提取监控视频的局部空间特征和局部时序特征,再利用CBAM-ConvLSTM网络进一步提取监控视频的全局空间特征和全局时序特征,以提高事件分类的准确率。但是由于视频数量有限,视频的质量参差不齐,且视频类别界定不清晰,导致网络准确率不高。以后工作将从以下方面做出改进,以达到更高的准确率:1)对UCF-Crimes数据集做进一步的修改,提高数据集质量;2)用自监督的方式进行模型的训练,以达到更高的准确率。
