基于机器学习的私人汽车保有量影响因素分析及预测
——以新疆为例
2022-10-17周亚林叶琴郭杰王雪成
周亚林,叶琴,郭杰,王雪成
(1.交通运输部科学研究院,北京 100029;2.新疆交通科学研究院有限责任公司,新疆 乌鲁木齐 830011;3.干旱荒漠区公路工程技术交通运输行业重点实验室,新疆 乌鲁木齐 830011)
0 引言
随着经济的发展,我国私人汽车保有量在不断增加。从2000 年到2021 年,我国私人汽车保有量从625 万辆增加到2.6 亿辆,增长了41倍[1-2]。私人汽车保有量的高速增长带来了城市交通拥堵、空气污染等一系列问题。对私人汽车保有量的影响因素进行分析进而科学地预测私人汽车保有量,对于测算私人汽车的二氧化碳排放量、评估私人汽车对能源和环境的影响、科学规划城市道路、制定交通拥堵缓解措施等非常重要。
目前,已有不少文献对汽车保有量的影响因素及预测进行了研究。孙璐等[3]基于主成分分析法,Cao等[4]、Yang等[5]基于固定效应和随机效应模型、林耿堃等[6]基于多元线性回归模型分析了汽车保有量的影响因素。Ha等[7]进一步拓展了研究方法,基于柬埔寨金边市数据,运用多元Logit模型以及机器学习中的神经网络和随机森林方法,分析家庭汽车保有量影响因素,发现家庭收入是最重要的影响变量,其次是16岁以上家庭成员的数量和工作出行次数。以上研究发现私人汽车保有量会受到多类因素的影响,包括宏观经济因素、公共交通服务水平、汽油价格、交通管理政策等,而经济增长是汽车保有量增长的一个重要驱动因素。在分析汽车保有量影响因素的基础上,很多学者对未来汽车保有量进行了预测,其中最常用的是计量经济学法。如李瑞敏等[8]、刘恺[9]、万芳[10]基于计量经济学模型,蒋艳梅等[11]基于新产品扩散Logistic 模型及两种参数估计方法,谌小丽等[12]基于指数平滑模型对我国汽车保有量进行了预测。也有部分学者探索了其他汽车保有量预测方法,如Huo等[13]构建了燃料经济性和环境影响(FEEI)模型,Hao等[14]建立了包含3个子模型的混合模型对我国私家车保有量进行了预 测;Wu等[15],Lu等[16]基于Gompertz曲线,Hsieh等[17]基于蒙特卡洛模拟,Feng等[18]基于Cui-Lawson 模型预测了未来我国的汽车保有量。另外,还有部分学者采用神经网络方法对汽车保有量进行了预测。例如,夏钰等[19]基于神经网络BP算法对出租汽车保有量进行预测,结果表明神经网络预测模型在交通预测方面具有较高的计算精度;吴文青等[20]基于Simpson 改进的灰色神经网络预测了汽车保有量,证明基于Simpson 公式的灰色神经网络预测精度高于灰色神经网络模型和单一预测模型。
整体而言,目前汽车保有量的影响因素分析和预测研究主要是基于传统的统计学、计量经济学和宏观经济学模型,较少采用机器学习方法,相应缺少强大的模式识别能力,难以很好地拟合变量之间的复杂关系。而少数基于机器学习的汽车保有量影响因素分析或预测研究,或是以家庭为研究对象开展影响因素分析[7],或是直接基于机器学习模型进行预测而忽略了对汽车保有量影响因素的分析[19-20]。基于此,本研究将构建基于机器学习的私人汽车保有量影响因素分析及预测模型,通过极度梯度提升树(Extreme Gradient Boosting,XGBoost)提取私人汽车保有量最重要的影响因素,并在比较不同机器学习方法预测精度的基础上,筛选出预测效果最好的方法对私人汽车保有量进行预测,从而为测算私人汽车碳排放量、制定私人汽车管理政策提供依据。
1 模型方法介绍
随着人工智能的发展,机器学习被广泛应用于各领域的因素识别和预测。机器学习研究如何利用学习经验改善模型自身的性能,其主要从输入的数据中产生模型的算法,挖掘输入数据之间的关系,即“学习算法”[21]。机器学习的具体方法有很多,包括XGBoost、随机森林、神经网络、支持向量机等。在交通运输领域,已有大量研究采用了机器学习方法,如基于随机森林方法对交通出行方式选择进行预测[22],基于k 邻近算法和支持向量回归模型对交通流进行预测[23],基于神经网络方法对公路货运量[24]、铁路货运量[25]、铁路客流发送量[26]、货车交通流量需求[27]以及城市轨道交通客流[28]等进行预测,均具有良好的预测效果。
为更准确地识别私人汽车保有量的影响因素并预测未来的私人汽车保有量,本研究将构建基于机器学习的私人汽车保有量影响因素及预测模型。该模型首先基于历史数据,采用XGBoost 方法识别出影响私人汽车保有量的主要影响因素。然后通过比较预测精度筛选出机器学习中预测效果最好的方法,并将识别出的主要影响因素纳入预测模型,从而对未来的私人汽车保有量进行预测。模型具体结构如图1所示。
1.1 XGBoost方法
本研究拟采用机器学习中的Boosting 方法分析私人汽车影响因素。Boosting 是机器学习中一种常用的集成学习方法,其主要思想是通过多个弱学习器的组合来得到一个强学习器,从而提升性能。XGBoost 方法[29]是一种典型的Boosting 算法,在学习器模型选择、算法运行效率优化、算法鲁棒性等方面,均比以往方法有较大提升,因此被广泛应用于各种分类或回归任务中。XGBoost中常用的底层学习器为决策树,假设集成模型中共有K个决策树,其中第k个决策树的输出结果为fk(xi),则XGBoost方法的最终输出为:
式(1)中:xi为第i个输入样本;yi为对该样本的预测值。
XGBoost模型的优化目标L为:
式(2)中:为真实输出值;l(yi,)为损失函数,用于计算预测值和真实值之间的误差;γ和α为加权系数;T为叶子节点个数;w为决策树对应的权重;M为样本数量。
在优化过程中,通过不断构建决策树来得到最终的XGBoost模型。具体而言,在第t次迭代优化过程中,需寻找对预测误差降低最多的决策树ft加入到集成模型中,第t次迭代的优化目标L(t)如式(3)所示。
通过迭代优化以上损失函数,即可让XGBoost训练得到较好的预测模型。
模型的解释性是XGBoost 方法的一项重要优势。由于XGBoost 的底层是由决策树实现的,因此对于最终训练得到的模型,可进行决策过程解释,有助于深入了解模型做出预测的逻辑。同时,XGBoost 方法可得到不同输入特征的重要性度量,因此可有效筛选出重要的影响因素。
1.2 神经网络方法
神经网络是一种模仿生物神经网络系统的机器学习模型,可有效拟合不同的函数。神经网络可创建自主学习系统,相比其他机器学习算法,其学习能力更强且具有较强的数据处理能力,因此被广泛应用于预测领域。
神经网络由多个层叠加组成,主要包括一层输入节点、一层输出节点、一个或多个中间层。在每一层中,由多个神经元的共同作用得到输出结果[30]:
式(4)中:fi为该层第i个神经元的输入;wi为该神经元的权重,通过训练得到;b为偏置量;o为该层的输出。
神经网络的训练主要依赖反向传播算法,通过寻找使输出损失函数最快下降的方向,来调整神经网络的权重。对于多层神经网络,需利用链式法则计算得到每一层中权重参数的求导结果。一旦训练完成,神经网络的形式就固定下来,通过对神经网络的前向推导,可得到最终的输出结果。
2 私人汽车保有量影响因素分析——以新疆为例
2000 年以来,新疆私人汽车保有量不断提升,年均增长率超过18%(见图2)。本文将运用前文介绍的模型对新疆私人汽车保有量进行影响因素分析及预测。基于新疆2000—2020年的统计数据,首先识别影响私人汽车保有量的影响因素,然后在此基础上预测到2030年新疆私人汽车保有量。
2.1 影响因素筛选
根据不同学者的研究(见表1),私人汽车保有量的影响因素主要分为4 类:(1)宏观经济因素,包括人均GDP、产业结构、城镇化率、居民人均可支配收入等;宏观经济因素是影响私人汽车保有量的主要因素,GDP 的增长和生活水平的提高会提升人民对出行质量的需求;在发展中国家,随着人均GDP、人均收入等的增加,私人汽车保有量一般会相应增长;(2)公共交通因素,主要指标为城市人均公共交通运营数或客运量,包括人均公共汽电车数量或公共汽车载客量、出租车数量等,完善的公共交通设施可使公共交通出行更具吸引力,从而对私人汽车出行形成一定替代;(3)道路条件因素,包括人均道路面积、人均公路里程等,一般而言,良好的行车条件会使居民倾向于私人汽车出行;(4)汽油价格因素,燃油价格的增长会提高私人汽车使用成本,从而会影响消费者对私人汽车的购买意愿。
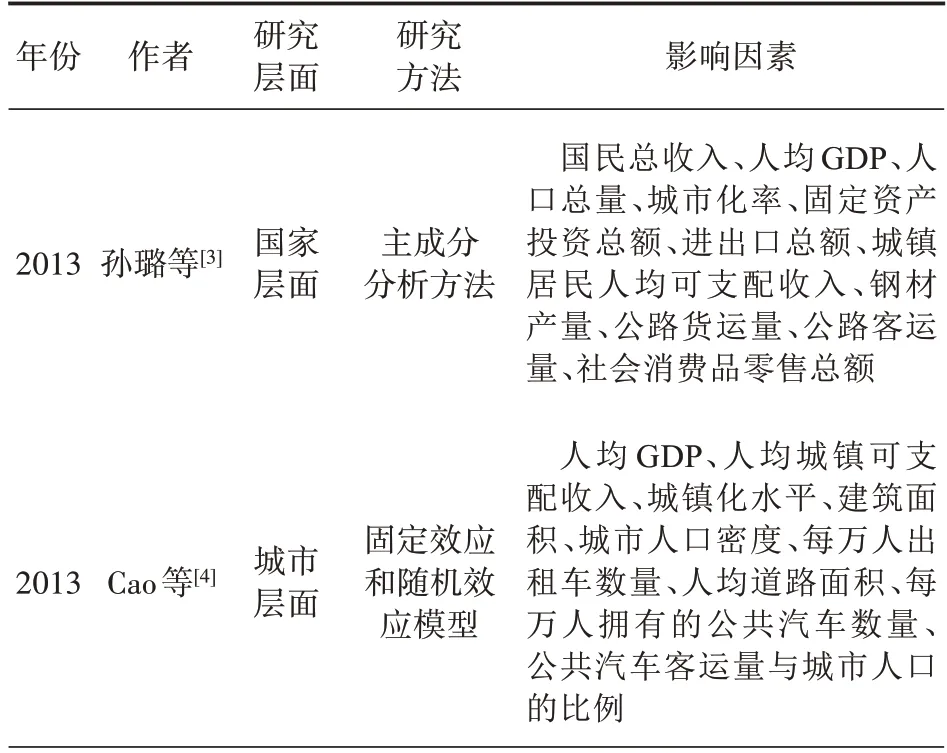
表1 私人汽车保有量影响因素相关研究
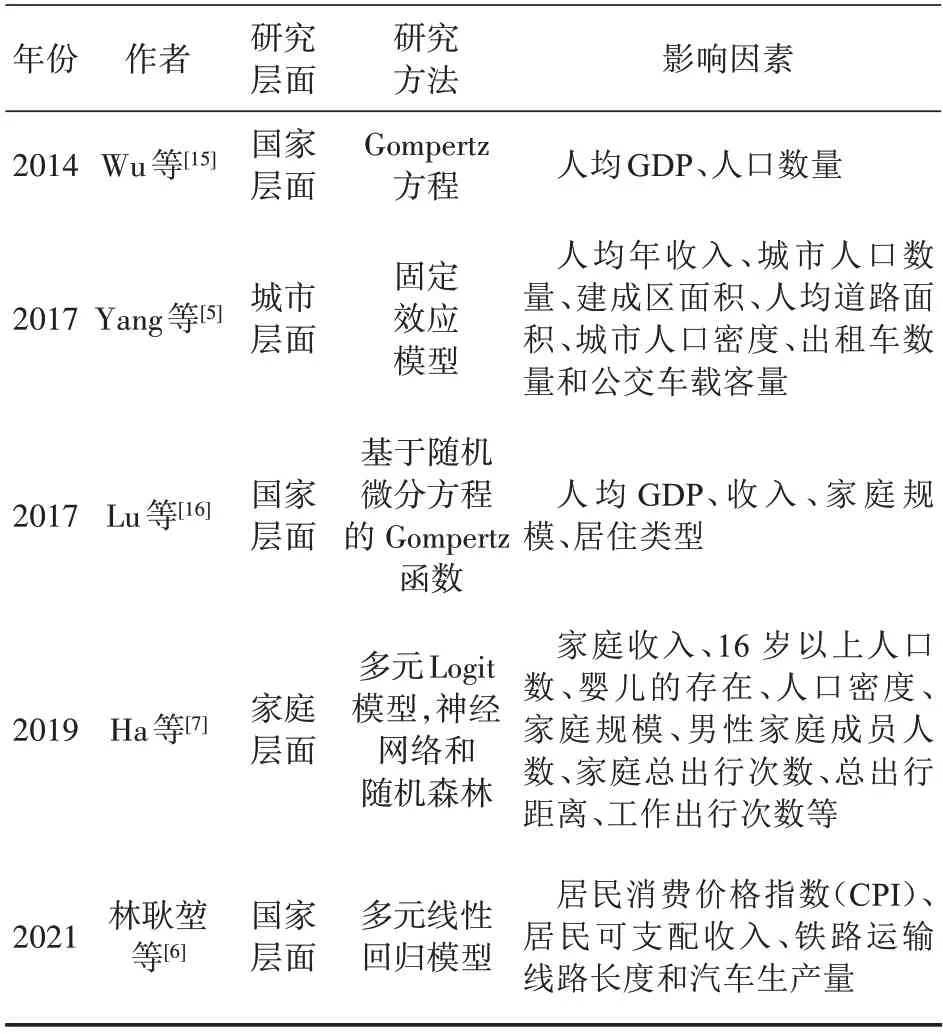
表1 (续)
在相关文献研究成果的基础上,考虑数据的可得性,本研究选取了9 个可能影响私人汽车拥有量的因素,包括人均GDP、城镇化率、第三产业占比、城镇居民人均可支配收入、人均道路面积、每万人公路里程、每万人公共汽电车数量、每万人出租汽车数量以及汽油价格。人均GDP、城镇化率、第三产业占比、城镇居民人均可支配收入、人均道路面积、每万人公路里程、每万人公共汽电车数量、每万人出租汽车数量等指标所需原始数据均来源于国家统计局,汽油价格选取了乌鲁木齐92号清洁汽油年均价格数据,来源于CEIC数据库。
由于输入的因素较多,且不同因素对最终预测的影响不同,某些因素可能与最终预测结果相关性很低,因此在对私人汽车保有量进行预测时,首先需要对影响私人汽车保有量的因素进行筛选和分析,从而提高最终预测的准确性。本研究基于2003—2020年新疆私人汽车保有量及其影响因素相关数据,将样本划分为训练集和测试集,其中训练集为2003—2016年的数据,测试集为2017—2020 年的数据。本研究采用XGBoost 模型在训练集中学习,从而得到新疆私人汽车保有量影响因素的分析结果。
2.2 影响因素分析结果
在应用XGBoost 模型过程中,通过逐次剔除每个输入特征后观察其对最终结果的影响,可以得到每个特征的重要性分值。图3 所示为基于XGBoost 模型学习到的不同输入变量(新疆私人汽车保有量影响因素)的重要性程度的可视化。从图中可看出,人均GDP 及城镇化率两个因素对于新疆私人汽车保有量具有最重要的影响。
为更清晰地理解XGboost 模型的工作过程,本研究对XGBoost 模型进行更多的可视化,展示XGBoost模型中的两个决策树推理过程,如图4所示。对于输入的变量,在每个节点中,根据条件来判断选择左右子节点,直至到达最终的叶子节点,则得到该决策树的输出。通过综合多个决策树的输出结果,即可得到模型最终的预测值。由图4 可看出,XGBoost 模型会首先根据人均GDP来决定预测模型的走向,这也验证了人均GDP 这一因素对于私人汽车保有量的影响尤为重要。
3 私人汽车保有量预测——以新疆为例
基于XGBoost 方法计算结果,本研究筛选出重要的影响因素,构建预测模型,对未来新疆的私人汽车保有量进行预测。
3.1 预测方法比较
在机器学习方法中,XGBoost 方法、随机森林方法、神经网络方法等均可应用于预测。本研究基于已有数据,首先对以上3 种方法的预测效果进行对比。图5 展示了不同方法在训练集中的拟合效果。由图5可看出,XGBoost、神经网络和随机森林模型均能很好地在训练集中对输入变量进行学习和拟合,得到的预测值和真实值基本一致。
本研究进一步在测试集中评估了模型的效果,如图6 所示。神经网络方法在测试集中的表现达到了较好的水平,预测值和真实值最接近。同时,XGBoost 方法和随机森林方法虽然在训练集的拟合中取得了良好效果,但在测试集中的表现劣于神经网络方法。另外,在2020 年,基于3种方法的预测结果和真实值均有较大差异。2020年,受新冠肺炎疫情影响,新疆人均GDP 相比2019年有所下降,基于模型预测得到的2020年新疆私人汽车保有量也有所下降。但实际上2020年新疆私人汽车保有量相比2019 年仍保持了7.7%的增长,这可能是由于公共交通服务受限激发了居民对私人汽车的需求。
本研究进一步对3 种方法的预测效果进行定量评估。均方根误差(Root Mean Square Error,RMSE)常被用于评价预测的精度,其计算公式为:
式(5)中:yi为对该样本的预测值;为真实值。
RMSE 越小表示模型预测精度越高。表2 展示了XGBoost、神经网络以及随机森林3种方法的RMSE 值。可以看出,神经网络方法的RMSE 指标数据小于其他两种方法,显示神经网络模型具有更好的预测精度。

表2 不同方法的RMSE值
3.2 预测模型参数设置
基于上文的分析结果,本研究将以新疆私人汽车保有量最重要的两个影响因素,即人均GDP和城镇化率作为预测模型的输入,运用预测效果更好的神经网络方法来对未来新疆私人汽车保有量进行预测。本研究对未来宏观经济发展设置了低、中、高3 种情景。根据《新疆维吾尔自治区国民经济和社会发展第十四个五年规划和2035年远景目标纲要》[31],到2025 年新疆常住人口城镇化率将不低于60%;根据《新疆城镇体系规划(2012—2030)》,到2030 年新疆城镇化率将达66%~68%[32],因此,本研究设定在低、中、高3个发展情景下,到2025 年新疆城镇化率分别为60%,61%和63%,到2030 年新疆城镇化率分别为66%,67%和68%。不同情景下2022—2030 年新疆人均GDP 增长率则分别参考不同机构或学者对于未来我国人均GDP 增长率的预测数据进行设定[33-35],详见表3。

表3 新疆未来不同发展情景相关参数设定
3.3 预测结果
基于神经网络的新疆私人汽车保有量预测结果如图7、表4 所示。根据预测结果,随着未来新疆人均GDP 及城镇化率的提升,新疆的私人汽车保有量将继续保持不断增长态势。在低发展情景下,未来新疆私人汽车保有量年均增长率为5%,到2025 年,新疆私人汽车保有量将达到516.5万辆,到2030年将达到650.2万辆;在中发展情景下,新疆私人汽车保有量年均增长率为5.6%,到2025 年和2030 年保有量将分别达到525 万辆和687.7 万辆;在高发展情景下,新疆私人汽车保有量年均增长率将达到6.4%,到2025年和2030 年保有量预计将分别达到541.2 万辆和734.3万辆。

表4 不同情景下2021—2030年新疆私人汽车保有量预测结果
4 结语
本研究基于机器学习方法构建了私人汽车保有量影响因素分析及预测模型。以新疆2003—2020 年数据为基础,采用机器学习中的XGBoost方法分析了影响私人汽车保有量的因素,结果显示人均GDP 和城镇化率是对私人汽车保有量影响最大的因素。在此基础上,通过对比XGboost、随机森林以及神经网络3 种方法的预测效果,采用预测效果最好的神经网络方法建立新疆私人汽车保有量预测模型,对2021—2030年新疆私人汽车保有量进行了预测。在本研究中,因样本数据量有限,在少量数据上训练得到的神经网络的泛化能力略差,即虽然在已知的数据集(训练集)上拟合效果较好,但在对训练数据之外的私人汽车保有量进行预测时,精度可能会下降,故未来的研究中需进一步丰富样本数据量。另外,基于2003—2016 年的数据分析显示,人均GDP 和城镇化率是对私人汽车保有量影响最大的两个因素,但在一些特殊年份(如2020 年),其他因素如公共交通服务水平等相比而言对私人汽车保有量可能有更大的影响。因此,本研究的预测方法仍有一定的局限性,未来在对机动车保有量进行长期预测时,可考虑将基于历史数据的定量分析与政策等定性分析结合,或根据不同的增长阶段提出更详细的模型,从而更好地捕捉影响私人汽车保有量的因素,实现更科学准确的预测。
