基于深度多尺度扩张CNN的多波段光谱锐化
2022-10-17李静,高媛
李 静,高 媛
(1.忻州师范学院 计算机系,山西 忻州 034000;2.中北大学 大数据学院,山西 太原 030051)
0 引 言
多波段光谱图像已广泛应用于数字地图、农业、军事等领域,与单波段或少数波段的普通图像相比,多波段光谱图像通常包含卫星或传感器在不同光谱下捕获的多个波段的目标[1,2]。在多光谱图像融合中,为了充分利用现有的信息,通常采用全色锐化方法同时对两个分量进行融合,生成高分辨率多光谱图像。如何实现高质量的锐化性能,这是许多学者研究的重点。
近些年,提出了一系列新的锐化方法。文献[3]提出一种基于超拉普拉斯惩罚因子(PHLP)的全色锐化方法,使用超拉普拉斯分布来约束误差,这在一定程度上允许了结构保留值的较大偏差。在文献[4]中,该方法在一个统一的框架内实现了卫星图像的配准与融合(SIRF),它不仅利用高通滤波器来实现图像的相似性,而且还融合了不同波段之间的内在相关性。PHLP和SIRF方法实现与传统的分量替代与自适应方法相比,效果更好,但也往往依赖于人工设计的假设,需要对不同的信号进行参数调整。
由于深层卷积神经网络具有强大的映射表示能力,许多研究者利用该技术进行全色锐化。例如,深度神经网络假设多光谱图像块之间的关系与对应的高分辨率/低分辨率图像块之间的关系是相同的,并使用这个假设通过神经网络学习映射关系[5]。卷积神经网络泛化(PNN)改进了先前的超分辨率网络结构,并通过引入非线性辐射指数来增加输入[6]。为了使深度残差网络适合解决全色锐化问题,文献[7]使用深度残差模块代替池化层以减少空间细节信息丢失,并使用可学习参数的转置卷积上采样重建图像尺寸。然而,上面提到的3种基于深度学习的方法只是将锐化处理为一个图像回归问题,虽然获得了较好的结果,但它们没有考虑和解释光谱和空间保存,而是将其视为一个黑箱学习过程。根据文献[7],对于全色锐化问题,在融合过程中,空间特征与光谱信息被证明可以极大地提高分辨准确率,因此在学习函数映射时应该重点关注这一点。
为了解决上述问题,提出了一种基于深度多尺度扩张卷积神经网络的多波段光谱锐化方法,通过实验验证该方法能够有效保存光谱和空间信息。
1 多尺度网络
1.1 深度学习框架
一般来说,超分辨率贝叶斯法和高光谱图像(hyperspectral image,HSI)锐化的目标是利用高分辨率(high-resolution,HR)分量来锐化包含更多频带和光谱信息的高分辨率(low-resolution,LR)分量。因此,这两个任务可以统一到一个观察模型中。将所需图像表示为X包含C×R大小的B波段。输入图像的成像模型可以写为
P=XHp+Np
(1)
M=HmX+Nm
(2)
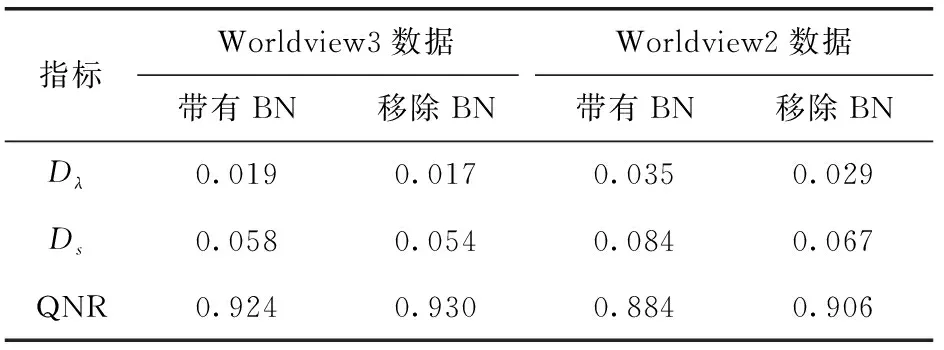
式中:X∈RCR×B时期望输出,Np和Nm分别是P和M所包含的噪声。Hp∈RB×B1是光谱传感器的响应,Hm∈Rcr×CR由一个下采样算子组成。因此,P∈RCR×B1是包含B1(B1 图1显示了本文提出的深度学习的框架,该框架具有从多尺度扩张卷积到全色图像锐化的深度学习。可以发现,这涉及在LR多光谱图像和输出之间的跳跃连接,以加强光谱相似性,并采用本文提及的多尺度扩展模块在高通域中训练网络参数,从而对空间内容建模,↑代表上采样操作。 本文搭建的网络使用带有残差网络模块的卷积神经网络作为网络主干。深度卷积神经网络能够捕获相关的图像特征,并为回归任务构建复杂的非线性函数。此外,卷积滤波器还可以探索不同多光谱图像带之间的高相关性。因此,为了利用深层神经结构强大的非线性能力,本文采用ResNet作为基本网络模块[7]。总体架构如式(3)所示 Yl=σ(Wl⊗concat(PG,UP(MG))+vl)Y2l=σ(W2l⊗Y2l-1+v2l)Y2l+1=σ(W2l+1⊗Y2l+v2l+1)+Y2l-1 (3) (4) 式中:UP(M) 代表上采样的LR多光谱图像。 本文测试了3个基本网络结构,其结构图如图2所示。第三个网络,即PanNet[8],性能最佳。第一种结构是将仅包含ResNet的结构直接应用于图像融合问题。基于此网络结构,本文提出了用于锐化以保留光谱和空间信息的新模型。 (1)频谱保存:对于频谱保存,对M进行上采样,并运用到深层网络的跳跃连接 (5) 受变分方法的启发,它强迫X共享M的光谱含量。但是,与利用平滑核对X进行卷积的变分方法不同,本文方法允许深度网络自动校正HR差异。图2中的第二个网络对应于式(5),将此网络称为“ResNet +光谱映射”[9]。 (2)网络结构保存:为了加强结构的一致性,大多数变分方法都利用PAN图像中包含的高通信息。基于此目的,使用PAN图像和上采样LR多光谱图像的高通量作为网络输入。修改后的模型如式(6)所示 (6) 为了获得高通信息,通过对原始图像的平均滤波,从原始图像中剔除低通像素值。在获得高通信息之后,将上采样提高到LR多光谱图像的PAN大小。另外,由于UP(M) 是低通部分,因此 (UP(M)-X) 包含X的高通分量。这增强了深层网络的学习能力,将PAN中包含的高通空间信息融合为X的映射函数。为了使网络专注于处理高通信息,本设计将UP(M) 的高通部分即UP(MG) 输入网络 (7) 式中:bui是基线预测因子。 本节定性地分析了本文提及的基于相关专业知识如何简化学习过程的网络设计。如图3所示,在添加光谱映射并使用高通输入之后,映射过程实际上是在3个稀疏分量之间,即图3(d)~图3(f)。即大多数像素等于或接近0,如图3(h)的直方图所示。这表明未知量显著减少,这大大简化了学习过程。 稀疏性也被广泛地应用于现有的超分辨率贝叶斯方法中。因此,引入了光谱映射和高通输入来训练网络参数。 与高层次视觉问题不同,超分辨率贝叶斯法是一个图像融合问题,需要精确的密集像素预测。因此,引入广泛用于获取抽象特征的池操作会导致空间信息不可挽回的丢失。然而,不添加池操作会减慢感受野的增长速度。另一方面,许多多尺度网络,例如U-Nets[10]和RNDN[11],在这些网络中,较低尺度的特征使用巧妙设计的跳跃连接来重新利用高尺度特征的计算。然而,这些方法以分层方式提取多尺度特征。在更细粒度的规模中,多尺度的能力有限。由于本文使用高通信息作为输入,所以只有细节和边缘被输入到网络中。因此,为了平衡空间高通信息保存和感受野放大,本文提出了一种多尺度分组扩张模块在细粒度水平上提取多尺度表示。 通过膨胀因子的步长,对像素进行加权,膨胀卷积可以有效地增加感受野,而不会丢失空间信息,且不会增加参数的负担。在不同的膨胀因子下,一个固定的卷积核可以获得不同的感受野,因此设计一个多尺度的膨胀模块,以充分利用不同尺度上的空间信息。然而,直接增加膨胀因子需要更多的计算预算。因此,本设计将特征图分成不同的组别,分别对每组进行不同的膨胀卷积。 ResNet模块中的卷积运算可以看作是膨胀因子等于1的膨胀卷积。分组的多尺度膨胀模块由两个多尺度膨胀运算和一个大小为1×1的卷积核组成。每个模块包含4个具有不同膨胀因子的平行膨胀卷积。这4个膨胀因子由一个大小为1×1的卷积层连接融合,产生的计算复杂度可忽略,以生成输出特征图。其中,这4个因子是单独处理的并且没有完全连接,这节省了计算和存储的负担。本文设计的分组模块的多尺度表示能力与现有方法有些不同之处,后者在不同的网络层中使用具有不同分辨率的特征,而本文模型的多尺度是指单个网络层上的多个感受野。本文模型的整个网络包含4个组别的多尺度膨胀块和两个大小为3×3的卷积层。第一个3×3卷积层用于提取基本图像特征,而最后一个用于重建残差图像。 作为减轻内部协变量偏移的最有效方法之一,批量归一化(BN)在深度学习的每一层非线性网络被广泛采用。BN的操作包含两个部分:首先,通过式(8)对小批量中的特征图x进行归一化 (8) (9) 式中:y是输出特征映射,γ和β是经网络学习需要更新的参数,用于提高模型能力。 数据经批量归一化后,网络的训练速度可以变得更快、初始化灵敏度低等。然而,在本文实验中,发现在测试其它卫星数据时,运用BN,网络并不总是表现良好。这是因为BN假设训练和测试数据的分布是相同的。在实验阶段,根据训练数据计算并保存式(8)中使用的平均值μx和标准差σx。 然而,对于遥感领域,不同的卫星有自己的数据类型。在一颗卫星上获得的μx和σx并不总是与其它卫星的参数一致。因此,在测试新的卫星数据时,从不同卫星获取的参数值可能会有些波动,影响后续的计算。注意,如PanNet所述,由于图像中的主要能量,即低通分量已经被去除,使用高通分量训练网络可以在一定程度上减少分布差异。但是,连续使用式(8)和式(9)会使波动累积,从而再次增大分布差异。因此,结合高通分量训练网络,去除BN可以进一步提高深度网络对不同卫星的泛化能力。这在新卫星和传感器无法提供足够的训练数据的情况下具有实用价值。 此外,如前文所述,引入光谱映射和高通分量可以有效地简化学习过程,因此不需要BN来加速训练。此外,移除BN可以充分减少内存使用量,因为BN层与前面的卷积层需要消耗的内存相同。基于上述观测和分析,从本文的网络中移除了BN层,从而提高了模型对新卫星的泛化能力,减少了参数数目和计算资源。 进一步给出提出的深度多尺度扩张CNN的多波段光谱锐化算法: 算法1:深度多尺度扩张CNN的多波段光谱锐化 输入:原始图像数据集 输出:HR多波段图像 (1)参数初始化:标准偏差,下采样因子,上采样因子,权重衰减,动量,初始学习率,批量大小,低通滤波器的半径,训练迭代次数,非线性函数; (2)将图像按照式(1)、式(2)得到PAN图像以及LR多波段图像; (3)通过高通滤波器式(6)对PAN图像以及LR多波段图像进行处理,LR多波段图像进行上采样; (4)将原始的LR多波段图像进行新一轮的上采样; (5)将高通滤波器处理的PAN图像与LR多波段图像作为深度多尺度扩张CNN输入; (6)将包含64个特征的输入分为4组,每组分别包含16个特征; (7)将4个组分别输入3×3的卷积层进行映射,用于提取基本图像特征; (8)每组的输出经过ReLU整流,然后再次进入3×3的卷积层映射,重建残差图像; (9)对所有的4组特征映射输出进行特征融合; (10)然后经过ReLU整流,再次经过一个1×1的卷积层进行映射; (11)将残差图像输出与多波段图像进行对比融合,输出HR多波段图像。 本文使用Worldview3卫星图像进行实验。由于HR多光谱图像在数据集中不能用,在所有实验中都遵循Wald协议。Wald协议对LR多光谱和PAN图像都进行了降采样,使得原始的LR多光谱图像可以用作地面真实图像。在降采样之前,应用低通滤波器以减少像素混叠。本实验使用标准偏差为0.1,大小为7×7的高斯核对所有原始图像进行卷积,然后采用因子4进行下采样。将几种基于非深度学习的超分辨率贝叶斯方法进行了比较:ATWT-M3[12]、AWLP[13]、BDSD[15]、PRACS[16]、Indusion[17]、PHLP和SIRF。将3种基于深度学习的方法进行了比较:一种相对浅层网络PNN和两种多尺度网络U-Net和RNDN。还将与图2的3个网络结构进行比较,即ResNet,ResNet+光谱映射和PanNet。 为了训练本文构建的网络,总共提取了18 K个PAN/LR多光谱/HR多光谱图像块对,每个图像块大小设置为64×64。在训练过程中,70%的配对用于学习网络,其余用于测试。使用Caffe来训练本文模型,并选择ReLU作为非线性σ(·)。 所有网络层的卷积核数量都设置为16。使用SGD算法,其中权重衰减和动量设置为10-7和0.9,用来最小化目标函数式(6)。将初始学习率设为0.001,经过105次迭代和2×105次迭代后除以10。训练网络的迭代次数设为2.5×105次,小批量大小设为16,低通滤波器的半径设为5。 首先使用上节描述的实验框架,在采集自Worldview3卫星的225幅图像上测试本文模型,这些图像包含8个光谱带。其中只有3个色带用于可视化,而所有光谱带都用于执行定量评估。用5种广泛使用的量化指标来评估性能,即相对无量纲综合误差(ERGAS)、光谱角映射器(SAM)、频带平均的通用图像质量指数(QAVE)、Q8的X波段扩展和空间相关系数(SCC)[18]。 量化指标得分的平均值和标准差见表1,排名第一和第二的结果分别用粗体和下划线标出。可以看出,如果不考虑图2的网络和本文的多尺度网络,PNN方法的效果最好。而PanNet则比PNN的实验结果明显可观。这是由于光谱映射和高频输入的额外设计。此外,本文的多尺度网络在所有其它方法中取得了最好的效果,这表明由于更多的上下文信息被用于后续模型重建,使用多尺度方式可以进一步提高模型的重建精度。 表1 采集自Worldview3卫星的225幅图像的不同方法的测量指标 图4列举了缩小比例的例子,如小矩形所示,其它比较方法在其结果中会出现明显的模糊和伪影,以及一些光谱失真,显示为颜色失真。在图5中,描绘了这些图像的残差,用来突出不同之处。可以看出,本文的多尺度网络的残留图像的颜色趋于灰色,这说明本文模型可以很好地保留光谱。同时,本文模型生成的残差图像显示的细节和纹理也比其它方法少,这意味着本文模型可以实现最佳的空间信息保存,LRMS表示低分辨质谱方法。 表2给出了基于深度学习的方法的可训练参数数量的比较。可以看出,本文网络的参数量虽然比PanNet的参数量略多,但是比其它方法少得多,且图像融合效果最好,对比结果见表1。 表2 基于深度学习方法的参数数量的比较 本文还评估了不同方法在Worldview3卫星原始分辨率下对200张图像的测试结果。结果示例如图6所示。由于缺乏地面真实的HR多光谱图像,向上采样的LR多光谱图像的残差如图7所示。由于输出和上采样的LR多光谱图像应该具有近似的光谱信息,平滑区域应该接近于零,并且只显示与LR多光谱图像缺少的信息相对应的边缘或结构。 本实验还采用了文献[12]中使用的方法来进行定量评估,即对输出的HR多光谱图像进行下采样,并将其与LR多光谱进行比较作为基本参考。另外还使用由光谱畸变指数Dλ和空间畸变指数Ds组成的QNR作为无参考度量。结果见表3,排名第一和第二的结果分别用粗体和下划线标出,可以再次发现本文模型具有的良好性能。 本文多尺度网络对卫星间的差异更具有鲁棒性,为了验证这一点,在Worldview2和Worldview3卫星数据集上将本文模型与PNN进行了比较。具体来说,测试了两个PNN训练的模型:一个称为PNN-WV2,它根据worldwiew2数据进行训练;另一个称为PNN-WV3的模型是在与多尺度网络相同的worldwiew3数据集上训练的。 表3 将Worldview3卫星图像采用不同方法进行度量 图8中展示了一个视觉结果。可以看到,PNN不能很好地推广到新的卫星上,而多尺度网络可以很好地推广到Worldview2,并接受Worldview3训练。在图8(d)和图8(e)中,PNN分别产生明显的频谱失真,而本文网络模型对新类型的数据具有鲁棒性。这验证了本文模型能够将光谱信息的建模工作留给光谱映射过程,并使得网络专注于结构信息。另一方面,PNN要求其网络同时对空间和光谱信息进行建模。 本文还考虑了本文的模型和PNN如何推广到IKONOS卫星数据。由于IKONOS数据包含R、G、B和红外4个波段,因此选择Worldview3数据中的波段来训练本文模型。PNN-IK和PNN-WV3分别表示PNN根据IKONOS数据和Worldwiew3数据训练的两个模型。如图9所示,PNN-WV3以光谱失真为代价获得了清晰的结构。虽然PNN-IK是直接在IKONOS上进行训练,但是本文方法仍然有更清晰的结果。如图9的第二行即残余图像中可以看到,本文方法能够同时实现光谱和空间的保留。具体地说,与PNN相比,本文模型的结果在平滑区域的色差更小,边界区域周围的结构更清晰。实验过程中发现使用高频部件来训练本文网络可以消除不同卫星数据的不一致性。 进一步分析本文模型每个部分的影响: (1)分组膨胀模块效应:由于分组多尺度膨胀模块是本文模型的核心模块,首先通过与只包含正态卷积的基本网络的比较来测试不同膨胀模块的效果。具体地说,通过将扩张因子从2增加到5来测试5个不同分组的膨胀模块。为了公平比较,调整了不同的膨胀模块,使其具有相近的参数数量。 定量分析结果见表4,增加扩张因子可以产生更好的结果。扩张因子可以产生更大的感受野,这比普通卷积有更大的优势。然而,增加扩张因子最终会增加模型记忆功能负担,模型改善有限。因此,为了平衡性能和速度,选择最大扩展因子设为4,作为默认设置。 表4 在不同膨胀因子下的定量比较 实验人员还测试ResNet模块和分组膨胀模块的计算效率,即两个网络架构,如图10所示。众所周知,在卷积神经网络框架下,卷积运算占据了主要的运行时间。由于卷积核的尺寸增大,直接加入膨胀因子通常会增加运算时间。然而,由于将特征映射分成4个平行的组,卷积核的数目和相邻特征之间的连接数都减少到原始数目的1/4。这使分组膨胀模块具有更强大的多尺度表示能力,同时保持与ResNet相似的计算效率。如图10所示,由于分组操作,本文模型的参数个数减少,而经GPU加速后,每个模块的计算运行时间(以ms为单位)差不多。 为了查看这些模块已经学习了哪些表示,在图11中展示了来自不同展开卷积运算的一些特征图。显然,随着膨胀因子的增加,对应的特征图包含更大比例的结构和内容,这与捕捉多尺度空间模式的目的是一致的。因此,与现有的以分层方式进行多尺度表示的方法不同,本文的分组膨胀模块可以在细粒度级别上提取多尺度特征,并增加单个网络层内的感受野,这使得在锐化性能方面有显著的改进。 (2)移除BN的效果:为了验证移除BN的有效性,如前文所述,通过将BN加入本文的深层模型进行实验。当每个卷积运算之后再进行BN运算。在Worldview3数据上使用BN训练深度模型,并在原始比例下对Worldview3和Worldview2数据进行测试。定量结果见表5,从Worldview3的测试数据可以看出,两种模型的整体性能非常接近。这是因为训练数据和测试数据都是从同一颗卫星上采集的,这符合BN的假设。而在Worldview2的测试数据上,使用BN的模型性能明显下降。这是因为两颗卫星收集到的数据分布形式不同。BN所掌握的一类卫星的分布形式,即式(8)中的平均值和标准差,不能直接用于另一类卫星。 表5 移除BN的定量结果 为了验证这一观点,图12描绘了第一层特征图的统计直方图分布的示例。式(8)和式(9)中的参数是从Worldview3数据中学习的。很明显,在图12(a)中,如果训练数据和测试数据具有相同的分布形式,即来自Worldview3,则BN操作之后生成的特征图的波动范围较小。相反,使用从Worldview3学习到的参数来处理Worldview2数据会有明显的变化。如图12(b)所示,可能导致后续计算结果不稳定,从而降低性能。此外,增加BN操作会消耗更多的计算和存储资源。因此,一致认为BN并不适合这个特定的遥感群体。为了提高泛化能力,节省计算和存储预算,从模型中移除了BN操作。 (3)超参数的影响:此次实验还测试了卷积核数量和分组膨涨模块数量的影响。具体地说,首先测试核数K∈{16,32,48,64}, 同时将分组膨胀模块数固定为4。然后,在核数固定为64的情况下,检验了群膨胀模块数L∈{1,2,4,6}。 定量测试结果见表6。显然增加内核和模块数量可以表现出更高的性能。添加分组模块可以获得更大的建模容量以及可以进行更多的非线性操作,这比增加核数有更大的优势。然而,增加K和L的数量带来的改善是有限的,且损耗了存储以及使计算速度减慢。还调整了PanNet,使其参数数目接近本文的多尺度模型。定量分析结果见表7。很明显,在不同数量级下,本文方法始终优于PanNet,这进一步验证了本文模型的有效性。为了平衡性能和速度,将K=64和L=4作为默认设置。 表6 不同核数(K)和块数(L)下的定量分析比较 表7 不同参数数量下与PanNet的定量比较 图13中展示了训练和测试数据集的收敛性作为SGD迭代的函数。对比4种不同的网络结构:ResNet、ResNet+光谱映射、PanNet和本文的多尺度网络。如图13所示,与其它网络结构相比,本文构建的网络具有显著更低的训练和测试误差。这说明多尺度网络结构和高通训练策略适用于特定的超分辨率贝叶斯问题。 进一步测试了有关HSI锐化的模型,该模型在遥感任务中受到了越来越多的关注,例如目标分类和变化检测。本课题旨在将LR HSI与HR多光谱图像融合,用来获得HR-HSI。本文采用文献[19]中的融合框架来评估本文模型。将本文网络与4种最先进的方法进行了比较,即通过基于子空间的HYSURE、耦合光谱解混(CSU)、非负结构性稀疏表示(NSSR)和深高光谱图像锐化(DHSIS)[20]实现高光谱图像超分辨率。表8记录了两个公共数据集的定量结果,即CAVE数据集和Havard数据集。可以看出,本文模型在4个指标上的总体性能最好。这是因为此模型采用专业领域知识来分别保存光谱和空间信息,这也是HSI锐化的关键。这说明多尺度网络是通用模型,可以解决不同任务。 表8 CAVE和Havard数据集的定量结果 图14描述了每个数据集的锐化结果,用于视觉比较。如输出的矩形所示,HR-HSIs、HYSURE、CSU和NSSR方法具有明显的光谱伪影,而DHSIS具有明显的边缘失真。相反,本文模型可以同时实现光谱和空间的保护。本文还用伪彩色显示了相应的残差图像,以反映预测的HR-HSI与地面真实的差异。如残差图像所示,其它比较方法包含各种退化处理,例如模糊细节和振铃效应,尤其是在标记区域。本文提出的深度多尺度细节网络在细节重建和伪影减少方面的性能最好。同时,本文模型产生的残差图像在整个平滑区域以深色显示,也就是说,所有的差值都接近于0。而其它的残差图像或多或少包含了较显眼的区域,表明误差相对较大。 为了解决全色锐化过程中频谱和空间信息保存问题,提出了一种基于深度多尺度扩张卷积神经网络的多波段光谱锐化方法。通过多个数据集的实验对比验证可得出如下结论:①由于更多的上下文信息被用于后续模型重建,使用多尺度方式可以进一步提高模型的重建精度。另外分组膨胀模块可以在细粒度级别上提取多尺度特征,并增加单个网络层内的感受野,这使得在锐化性能方面有显著的改进;②提出方法的多尺度网络的残留图像颜色趋于灰色,这说明本文模型可以很好地保留光谱;③提出模型生成的残差图像显示的细节和纹理也比其它方法少,这意味着本文模型可以实现最佳的空间信息保存;④提出方法由于删除了BN过程,使得结果在平滑区域的色差更小,边界区域周围的结构更清晰,并且可以消除不同卫星数据的不一致性,提升方法的泛化性能。1.2 基本网络结构



1.3 网络学习过程
1.4 多尺度分组网络结构
1.5 移除批量归一化

2 算法流程
3 实验与结果
3.1 数据集和实验方法
3.2 实验结果


3.3 按原始图像进行模型评估
3.4 将本文模型推广到新卫星

3.5 分块研究



3.6 收敛性能
3.7 高光谱图像锐化

4 结束语
