基于QSPR方法的活性化合物热稳定性预测研究
2022-10-17万可风张子炎张宏哲
高 月,厉 鹏,万可风,张子炎,苑 媛,张宏哲
(1.中石化安全工程研究院有限公司化学品安全控制国家重点实验室,山东 青岛 266000;2.应急管理部化学品登记中心,山东 青岛 266000)
0 引言
活性化合物易发生剧烈反应使化学能转化为热能或者机械能,是具有潜在危害的不稳定物质。在工业生产及储运过程中,以有机过氧化物和硝基化合物为代表的活性化合物引发许多严重的热失控事故,在全球范围内造成大量人员伤亡[1]。活性化合物的热稳定性是固有属性,评判热稳定性的常见参数包括起始放热温度(To)和分解热(-ΔHd),两者分别反映热危害发生的可能性和严重性[1]。传统获取活性化合物热稳定性参数的方法是实验方法,如采用差示扫描量热法(Differential Scanning Calorimetry,DSC)等,然而由于实验方法具有滞后性、工作量大、费用昂贵且危险的特点,有必要探究1种简便、快速的方法来评估活性化合物的热稳定性。
定量结构-性质相关性(Quantitative Structure-Property Relationship,QSPR)是通过将分子结构参数与目标性质之间的内在定量关系关联,建立构效关系模型,基于分子结构信息预测化合物性质的1种方法[2-3]。QSPR方法可以弥补实验方法的不足,是化学品热稳定性评估的重要理论预测方法,也是当前研究热点[4]。近年来,已有国内外学者针对有机过氧化物和硝基化合物的起始放热温度和分解热建立QSPR预测模型,Prana等[5]基于38种有机过氧化物的热稳定性实验数据,建立四元和三元线性回归(MLR)预测模型,分别预测To和-ΔHd;Zhang等[1]基于63种硝基芳香族化合物和16种有机过氧化物,综合遗传算法和多元线性回归(GA-MLR)分别建立硝基芳香族化合物和有机过氧化物的To预测模型。总体来说,上述研究中模型均取得了较好的预测效果,但是针对活性化合物的热稳定性的QSPR预测研究仍较少,且起始放热温度和分解热的预测仍以线性模型为主,在表征分子结构与热稳定性之间的复杂关系方面存在不足。针对上述问题,本文采用遗传算法优化的BP神经网络,建立QSPR预测模型,对有机过氧化物和硝基化合物分子结构及其起始放热温度、分解热的内在非线性关系进行探讨。
1 数据样本选取
为获得性能良好的QSPR模型,最标准的数据样本应选自同一数据源,且在实验室条件、测试人员和测试方法不变的情况下获得[6]。通过严格筛选,本文的数据样本均来自同一数据源。有机过氧化物起始放热温度和分解热的实验数据来自Prana等[5]研究中测得的38种有机过氧化物的实验数据;硝基化合物起始放热温度和分解热的实验数据来自Ando等[7]开展的DSC实验研究中104种硝基化合物的实验数据。以上数据样本分别用于建立有机过氧化物和硝基化合物热稳定性预测模型,其中硝基化合物热稳定性的数据样本比Zhang等研究[1]的范围更广。采用随机原则,划分数据样本的80%(30种有机过氧化物和83种硝基化合物的起始放热温度和分解热)作为训练集,用来筛选分子描述符和建立模型;划分数据样本的20%(8种有机过氧化物和21种硝基化合物的起始放热温度和分解热)作为测试集,用来验证模型。数据样本信息如表1所示。
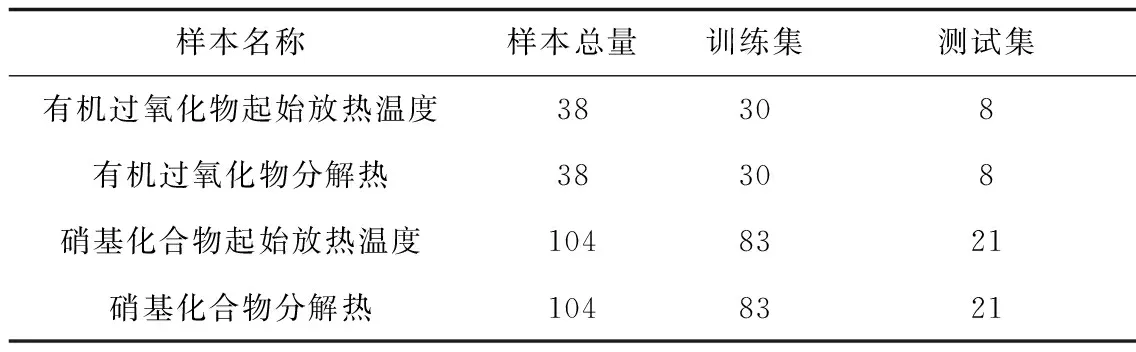
表1 数据样本信息Table 1 Data sample statistics
2 分子描述符计算与筛选
本文在计算分子描述符之前,首先采用HyperChem 8.0软件[8]绘制有机过氧化物和硝基化合物的3D分子结构,并采用VB编程,利用DDE接口操控HyperChem的分子力学(MM+)和量子化学半经验方法(AM1)对绘制的分子结构进行批量优化,获得能量最低的稳定构型,将优化后分子结构导入E-Dragon在线计算工具[9]计算数据样本中各化合物的分子描述符。
经过计算,数据样本中每个化合物均获得1 664个分子描述符。为提取预测模型建模所需的特征变量,需要对大量的分子描述符进行降维、筛选。首先利用MATLAB进行分子描述符初筛,剔除大量冗余的描述符。初筛的原则包括:1)剔除对所有化合物来说数值为常数或近似常数的描述符;2)对于两两相关系数大于0.95的描述符,剔除与热稳定性参数相关性较差的一方;3)剔除与热稳定性参数相关系数小于0.1的描述符。初筛后,有机过氧化物与硝基化合物的起始放热温度数据样本对应的分子结构描述符分别由1 664个减少至477个和396个;分解热数据样本对应的分子结构描述符分别由1 664个减少至480个和479个。
基于初筛的描述符,采用Materials Studio软件的遗传函数算法(GFA),按照以下步骤筛选描述符:1)设置描述符筛选目标数量;2)由GFA算法筛选出与热稳定性参数相关的对应目标数量的分子描述符组合10组,并建立筛选的分子描述符与热稳定性参数的10个回归方程;3)比较10个回归方程的决定系数R2,R2最接近1的方程的变量即为目标数量下最佳的分子描述符组合;4)重复步骤1)~3),获得目标数量为1~10的最佳分子描述符组合;5)分析不同目标数量下最佳分子描述符组合的R2值随描述符目标数量的变化规律,如图1所示,并依据Katritzky等[10]提出的“断点原则”,由“断点”位置确定最佳的分子描述符数量,该数量下的描述符组合即为建模的最优描述符,如表2所示。
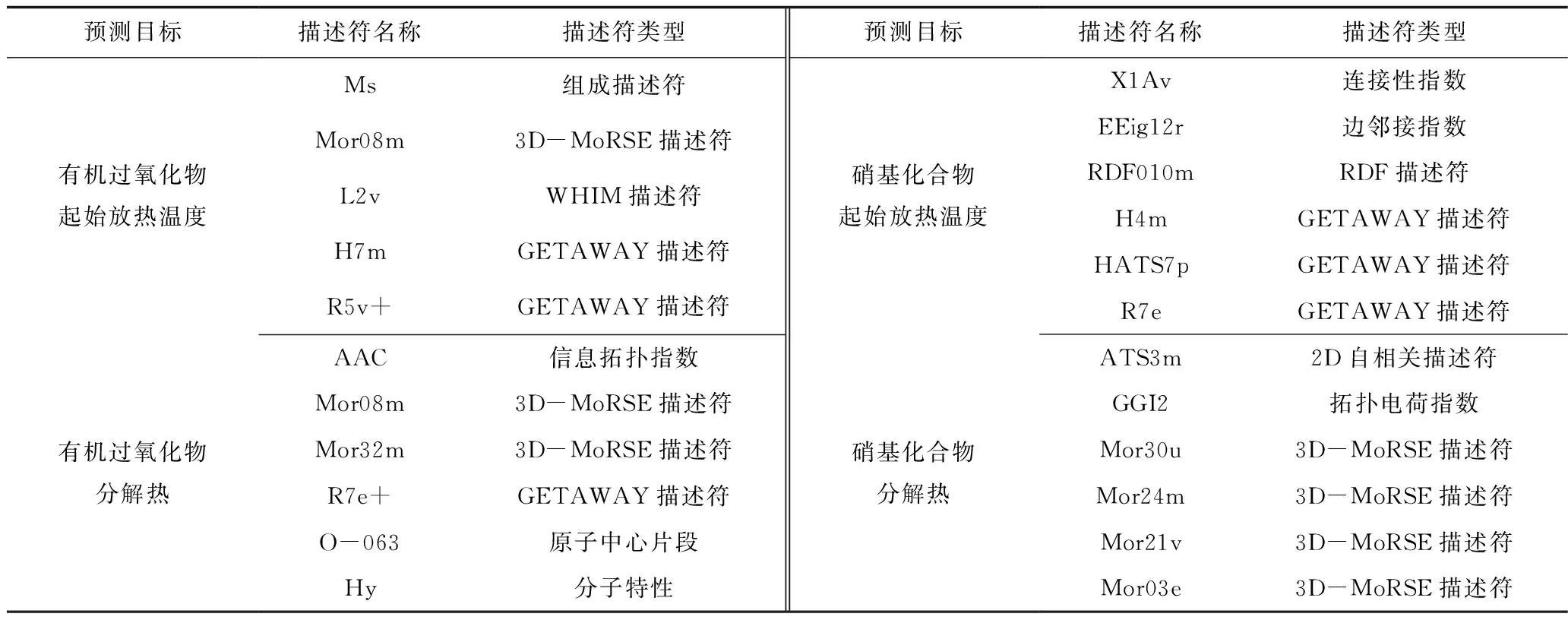
表2 最优分子描述符组合Table 2 Combination of optimal molecular descriptors

图1 描述符组合的R2值随数量的变化规律Fig.1 Change law of R2 value of descriptors combination with number
3 QSPR预测模型的建立
BP神经网络是1种单向传播的具有3层或3层以上的前向神经网络,包括输入层、隐含层和输出层,上下层之间实现全连接。若网络输出与期望输出值不一致,则将其误差信号反向传播,并在传播过程中对加权系数不断修正,使在输出层节点上得到的输出结果尽可能接近期望输出值[6]。为优化BP神经网络的预测效果,采用遗传算法(GA)优化网络的权值和阈值,优化后的BP神经网络能得到更好的预测输出结果。本文基于GFA筛选出的描述符,在MATLAB中实现BP神经网络的训练与测试,同时采用GA算法优化BP网络的权值和阈值,提升BP模型的性能,最终获得有机过氧化物、硝基化合物的起始放热温度、分解热的GA-BP预测模型。同时,为对比模型预测效果,以相同的描述符作为输入参数,采用偏最小二乘法(PLS)建立线性预测模型。GA-BP模型和PLS模型预测结果分别如图2、图3所示,对比2图中GA-BP模型和PLS模型的离散性可知,GA-BP模型预测结果明显优于PLS模型。以有机过氧化物的分解热预测模型为例,列举部分样本的预测结果,见表3。
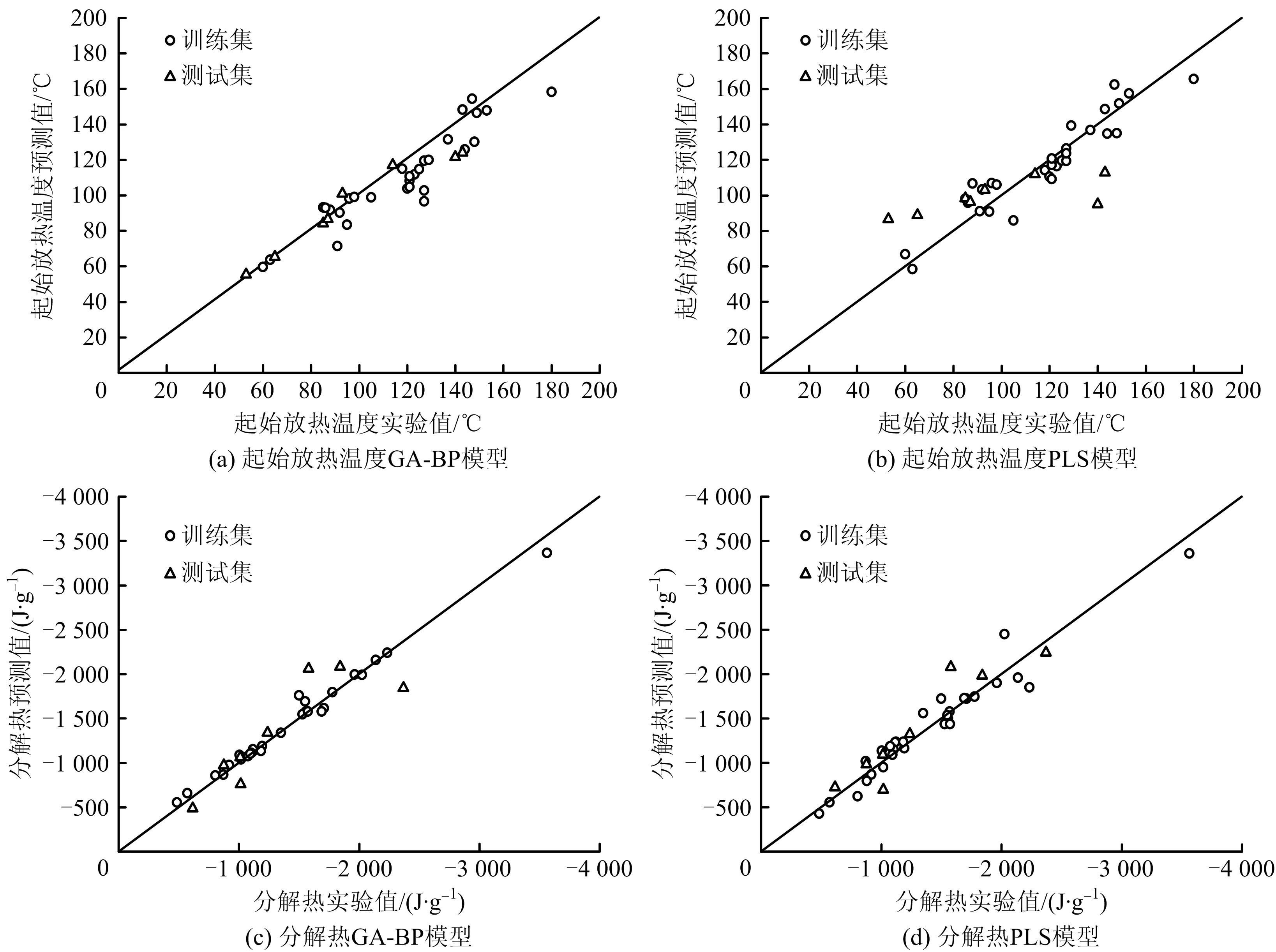
图2 有机过氧化物热稳定性GA-BP预测模型和PLS预测模型预测结果对比Fig.2 Comparison on prediction results of GA-BP prediction model and PLS prediction model for thermal stability of organic peroxides
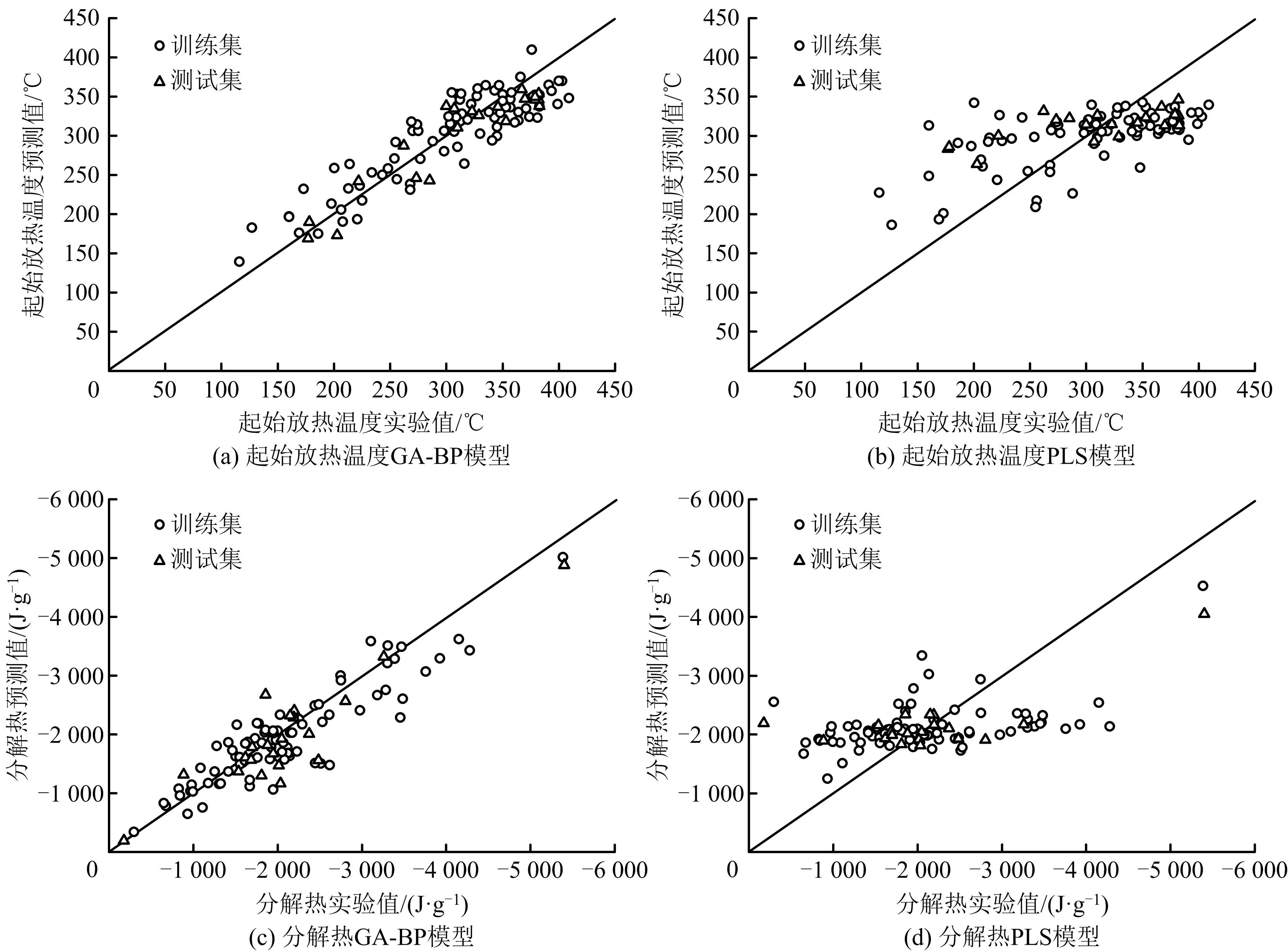
图3 硝基化合物热稳定性GA-BP预测模型和PLS预测模型结果对比Fig.3 Comparison on prediction results of GA-BP prediction model and PLS prediction model for thermal stability of nitro compounds

表3 部分有机过氧化物的分子描述符与分解热数据Table 3 Molecular descriptors and heat of decomposition of some organic peroxides
4 模型验证与讨论
4.1 模型验证与对比

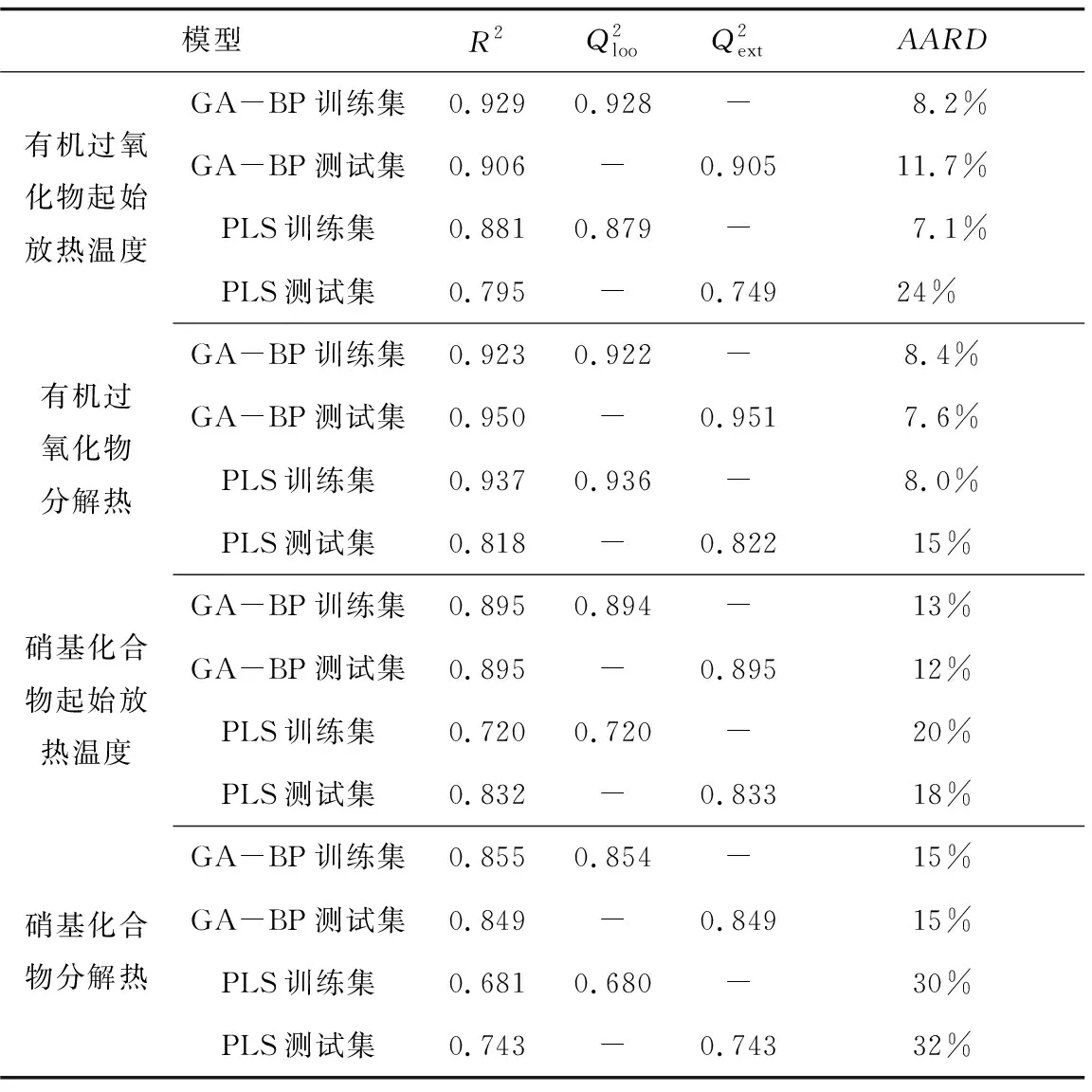
表4 热稳定性预测模型验证结果Table 4 Validation results of thermal stability prediction models
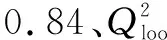
同时,为验证本文建立的热稳定性参数预测的GA-BP模型的应用效果,额外选取数据样本集以外的1种硝基化合物,验证预测方法的合理性。4,4-二硝基二苯二硫醚(CAS:100-32-3)起始放热温度预测值为258.12 ℃,分解热预测值为-2019.23 J/g;起始放热温度实验值为248.00 ℃,分解热实验值为-1955.24 J/g。通过应用效果验证,本文预测方法获得热稳定性参数预测值与实验值较为接近。
4.2 GA-BP模型的应用域评价
模型应用域的评价对于预测模型的应用是非常重要的,只有当所预测的化合物处于模型的应用域范围内,预测模型对性质的预测才是有效的[12]。前文中,模型验证与对比证明了GA-BP模型的优越性,本文采用Williams图进一步验证模型的应用域。
若Williams图中所有数据均在±3倍标准偏差和临界臂比值(h*)构成的范围之内(图4中3条虚线与纵坐标轴围成区域),则说明所有的化合物均在模型的应用域范围之内。从图4中可以看出,4个模型的数据均落在±3倍标准偏差之内;其中图4(b)~图4(d)中少数数据点的臂比值(h)超过了h*,说明对应化合物的某些分子结构对于样本集整体而言比较特殊,预测结果是模型外推得来的。虽然部分臂比值超过了临界值,但是标准化残差值落在±3倍标准偏差范围之内,有助于使模型更加稳定并具有一定的外推能力,因此可以看作是“良性异常点”[13]。综上,通过应用域验证了模型的有效性以及可靠性。
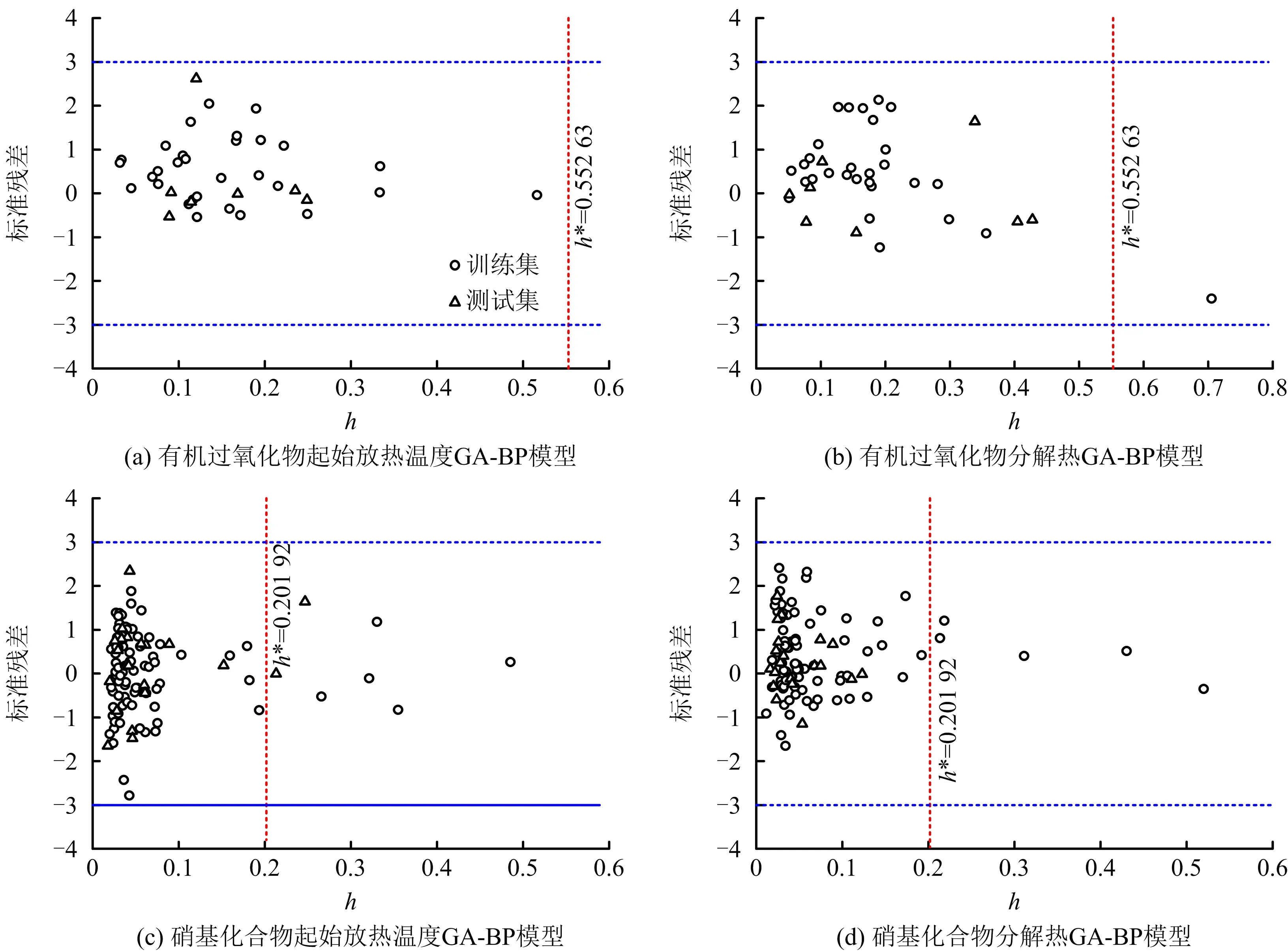
图4 GA-BP模型的Williams图Fig.4 Williams diagrams of GA-BP model
4.3 GA-BP神经网络模型机理浅析
BP神经网络是1种“黑箱”模型,因此难以对GA-BP模型进行机理解释。本文采用描述符重要度衡量方法(MMDI)[14]分析模型描述符对模型的影响程度,浅析影响热稳定性的主要结构因素。MMDI方法的基本原理是,以GA-BP模型的AARD值作为基数AARD值,依次打乱模型中各分子描述符的数值顺序,利用GA-BP模型对新的数据样本进行预测,新预测结果的AARD值与基数AARD值之差作为各描述符对应的AARD差值,比较其大小即可获得各描述符对模型的影响程度。本文中有机过氧化物起始放热温度GA-BP模型的描述符重要度排序为:Ms>H7m>R5v+>L2v>Mor08m,其中Ms和H7m对模型的影响最大,分别是组成描述符和GETAWAY描述符,反映了分子的平均电拓扑状态和中心原子坐标;有机过氧化物分解热GA-BP模型的描述符重要度排序为:R7e+>Hy>O-063>Mor08m>AAC>Mor32m,其中R7e+和Hy对模型的影响最大,分别是GETAWAY描述符和分子特性描述符,反映了分子的中心原子坐标和亲水性能;硝基化合物起始放热温度GA-BP模型的描述符重要度排序为:X1Av>RDF010m>HATS7p>H4m>R7e>EEig12r,其中X1Av和RDF010m对模型的影响最大,分别是连接性指数和RDF描述符,反映了分子图中的原子顶点度和原子间距离;硝基化合物分解热GA-BP模型的描述符重要度排序为:Mor30u>Mor03e>Mor24m>GGI2>ATS3m>Mor21v,其中Mor30u和Mor03e对模型的影响最大,两者均是3D-MoRSE描述符,反映了原子的3D排列。综上,利用MMDI方法明确各模型中影响化合物热稳定性参数的主要结构因素。
5 结论
1)采用遗传算法优化BP神经网络参数,建立预测有机过氧化物和硝基化合物的起始放热温度与分解热的GA-BP模型,其拟合能力、稳定性、预测能力以及应用域得到验证。其中,硝基化合物热稳定性预测模型建立在比前人的研究更广泛的数据样本基础之上,具有更强的代表性和适用性。
2)本文构建的GA-BP模型在热稳定性预测方面更具优势,说明非线性模型更能表征分子结构与热稳定性之间的复杂关系,从一定程度上证明热稳定性参数与分子结构之间存在非线性关系。
3)采用MMDI方法对GA-BP模型的机理进行浅析,得出各模型中影响化合物热稳定性参数的主要结构因素。
