基于BP神经网络的车牌识别方法研究
2022-10-17李洁李登刚曾文亮
李洁,李登刚,曾文亮
(湖南工业大学轨道交通学院,湖南株洲,412007)
0 引言
随着经济发展及生活水平的进步,大量汽车的出现带来了许多交通问题,如交通拥堵、肇事逃逸等。为解决上述问题,智能交通、车牌识别已成为近年来的发展热点[1-3]。目前在停车场、高速公路,交通路口等领域随处可见车牌识别的应用。我国的普通车牌主要由7个字符的蓝底矩形牌照框构成,根据车牌的特点,设计了一种基于BP神经网络的车牌自动识别算法。该算法由以下几部分构成:车牌图像预处理,车牌区域定位,字符分割,字符识别。可以对国内普通的蓝底7字符车牌进行简单快速有效的识别。
1 车牌识别系统的方案设计
车牌识别算法的流程主要分为四个部分:1)图像预处理,2)车牌定位,3)字符分割,4)字符识别。其中图像预处理、车牌定位和字符分割的目的是为了获取车牌的各个字符,然后将得到的车牌字符送入后续模块中进行字符识别,从而得到车牌号码信息,各步骤如图1所示。

图1 车牌识别系统总体方案
1.1 图像预处理
图像预处理是整个车牌识别算法中的最基础的一步,预处理后的图像结果将关系到后面字符识别部分的准确度。车辆图像预处理[4]的主要作用是突出车牌的主要特征,以及去除图像在成像、传输过程中的噪声等,本文的车辆图像预处理方式如图2所示。
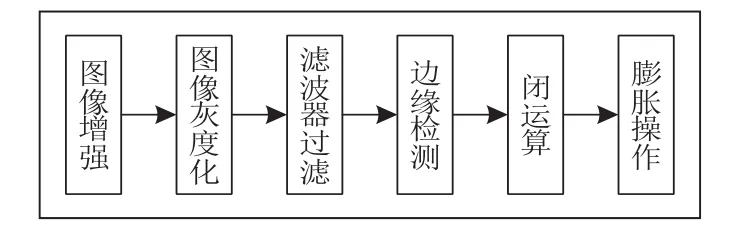
图2 图像预处理
1.2 车牌定位
车牌定位是使用图像处理中的去噪算法和数学形态学方法从给定的图像中找到车牌所在的部分,将其他部分进行区分并成功提取出来。本文设计了车牌区域粗-细两级定位方式,各步骤如图3所示。

图3 车牌定位流程图
1.2.1 粗定位
粗定位就是对车牌区域轮廓进行粗略定位。首先将原始图像进行直方图均衡化处理用于增强图像中的信息,再将图片进行灰度化处理增强图像效果,然后对图像进行滤波操作减少图像中噪声,使用Sobel算子边缘检测[5]提取出结构特征,最后使用闭运算等形态学处理方法得到粗定位图像,粗定位过程如图4所示。

图4 车牌图像粗定位过程
1.2.2 细定位
精细定位主要是为了获得完整、准确的车牌信息。本文使用HSV色彩空间提取车辆牌照区域,主要是为了找出图像中的蓝色像素。在得到HSV色彩空间所提取的车辆牌照区域后,算法将其转换为RGB图像从而定位得到蓝色车牌区域图像,如图5所示。

图5 车牌图像细定位过程(提取蓝色车牌区域)
在得到蓝色车牌区域之后,将图5.c进行灰度化处理,并且将图像进行二值化,然后通过将二值化图(图6.c)与粗定位结果(图4.f)使用形态学方法进行取交集运算,从而得到准确的车牌位置,如图6所示。

图6 定位车牌区域
确定车牌位置之后,对目标区域进行长宽比筛选,从而得到目标车牌图像,再通过Radon算法[6]对获取的车辆牌照进行倾斜校正,从而得到精细定位结果,如图7所示。

图7 精细定位结果
1.3 字符分割
《中国人民共和国机动车号牌》行业标准规则[7],我国现行的车辆牌照号码由7个字符组成。因此需要把定位后的车牌图片中的7个字符,分割开来。在对图7.b进行灰度化处理后,再对其进行二值化操作并去除噪声点,如图8所示。根据每个字符的高度和宽度以及各字符之间的间距等几何规律,采用垂直投影分割法[8]对图8进行字符分割,把车牌分割为7个小区域,并且调整各个区域的大小为32×40的格式,调整后的字符如图9所示。

图8 车牌区域二值图像

图9 车牌字符分割
1.4 字符识别
字符识别是对分割出来的字符图像(包括汉字、数字和字母)进行特征识别,从而得到相对应的车牌信息,也是整个车牌识别流程中最核心部分。本文在总结各方法的基础上,采用了BP(BackPropagation)神经网络技术进行字符识别。
BP神经网络[9-10]的网络结构如图10所示。从图中可以看出,该网络模型分为三部分:输入层、隐藏层、输出层。

图10 BP神经网络结构图
BP神经网络的工作原理是根据各个信号的前向传播以及误差的反向传播,从而调节自身网络的权重和阈值,利用梯度下降法,使整个网络的平方误差的和为最小值。基于BP神经网络的车牌识别算法流程以下:1)构建BP神经网络,2)训练BP神经网络,3)根据字符特征进行车牌的识别和分类。
1.4.1 构建BP神经网络
根据我国普通车牌的主要特点,建立了两个子网去识别不同类型的字符。第一个子网用来识别车牌号码中的第一个汉字字符,第二个子网用来识别车牌号码中的第2-7个字符,这六个字符除第二个为英文字符外,其余五个均为英文和数字的混合。
第一个子网,构建拥有10个输入层、10个隐含层、14个输出层的BP神经网络;而第二个子网,构建44个输入、10个隐含层、34个输出层的BP神经网络。两个子网第一层神经元激活函数都采用logsig,第二层均为sigmode,学习方法均采用trainlm。
1.4.2 训练BP神经网络
将各个字符的特征值输入到两个BP子网进行训练。第一个子网收集了中国大陆31个省份简称的汉字字符,一共3108张字符图片。然后将上述图片进行特征值提取,输入到BP子网进行训练,部分汉字字符的训练样本如图11所示。

图11 部分汉字训练样本
对于第二个BP子网,因为车牌号码中没有字母“I”和字母“O”,所以采集了除“I”和字母“O”之外的其它 24个大写英文字母字符和“0”到“9”这10个数字的字符,共4297张字符图片。然后对这些图片进行特征提取,输入到BP子网进行训练,部分数字和英文字符的训练样本如图12所示。

图12 部分英文数字字符训练样本
1.4.3 BP神经网络分类结果
完成BP神经网络训练之后,把图9中已分割字符的特征值提取出来之后输入到已经训练完成的BP神经网络中进行识别和分类。实验结果显示:输出字符识别结果为“川A7HN79”,与真实的车牌号码一致,如图13所示。

图13 车牌识别结果
实验共收集了停车场出入口、高速公路等不同场景下的30幅车牌图片,共有汉字字符30个,英文字符73个,数字107个。将这些车牌信息输入系统并进行车牌识别,识别的结果如表1所示。从表中可以看出,汉字的识别正确率为96.7%,英文字符的识别正确率为95.9%,数字识别的正确率为95.3%,所有字符的平均识别正确率为95.7%,取得了比较好的识别结果。
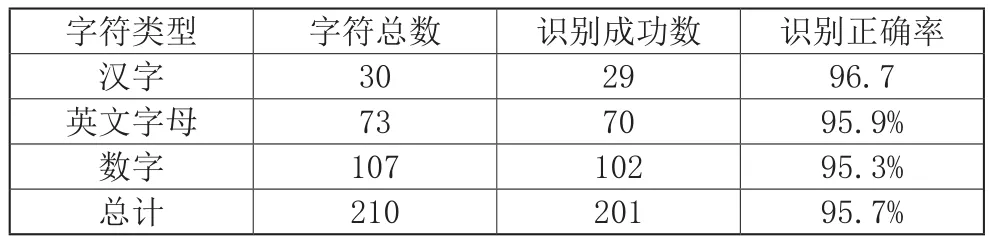
表1 各个字符识别正确率情况
2 结论
本文设计了一种BP神经网络的汽车车牌自动识别算法。该方法首先通过对车牌图像进行预处理,以获得车牌的主要特征。其次通过粗细二级定位的方式对车牌区域进行了精准定位,并对车牌区域可能出现的倾斜进行了校正。然后通过字符分割,分割出了汉字、字母、数字等7个字符,最后通过构造BP神经网络对分割出来的7个字符,进行了逐个识别。实验结果表明,该算法可以准确地识别出车辆的车牌信息。
