基于YOLO算法的集装箱扭锁目标检测方法*
2022-10-15闵冠宇
张 氢 闵冠宇 覃 昶
同济大学 机械与能源工程学院 上海 201804
0 引言
随着全球化贸易的发展,建设自动化、信息化和智能化的码头已经成为现代化港口发展的必然趋势。不同于大多数工厂常见流水线中固定工序的重复操作,码头的工作环境复杂多变,对自动化设备需要极高的灵活性和适应性。其中,集装箱的扭锁装拆问题是制约目前码头自动化发展的重要瓶颈。集装箱在堆叠时必须使用特殊的锁具进行固定,而集装箱扭锁的作用便是用于集装箱堆叠时上下2层箱体之间的固定连接,如图1所示。在集装箱装卸的过程中,扭锁也需要进行相应的装卸操作。

图1 集装箱扭锁
集装箱扭锁常用的类型为手动扭锁和半自动扭锁,目前国际上并没有统一的标准,需要人工拆装的种类就至少有6大类近百余种。由于国际上各个国家和地区的不同型号扭锁装卸方式有较大的区别,且普通抓取及操作工具适应性差,再加上港口复杂的户外环境,导致扭锁装卸过程很难实现完全的自动化,成为全自动化码头的最后一公里难题之一。目前,大多数自动化港口的集装箱扭锁装卸工作仍由人工辅助机器或完全人工完成,这对于港口安全生产带来较大的负面影响。若要高效地实现该目标,不仅需要灵活的拆装操作装置,同时还需要配套智能识别系统,能够快速准确地识别出复杂码头环境下的不同扭锁目标(见图2),完成检测-识别-分类的过程。

图2 各型号的集装箱扭锁
对于集装箱自动化领域的识别研究,国内外研究学者最常用的方式便是基于相机影像的视觉识别,其研究的识别内容包括集装箱主体、锁孔和编号等。对于集装箱装卸过程,均可采用锁孔识别的方式进行操作,故许多研究人员将研究重心放置在集装箱锁孔的识别和定位上[1,2]。采用锁孔识别的方式对于装锁过程较为合理,但拆锁过程却存在问题。装锁时,识别锁孔位置后再通过装置进行扭锁安装,该思路完全可以保证扭锁安装的精度;在拆锁时,如果同样采用锁孔识别的方式间接计算扭锁的位置,会由于锁孔的安装间隙及扭锁的安装位置影响最终的识别精度;同时,由于缺乏对扭锁状态的识别,使得拆锁过程存在安全隐患。因此,在拆锁时更应该考虑直接识别并定位扭锁的方式,但其识别难度应高于形状规则的锁孔。
在实现视觉定位之前,首先必须让机器知道图像中是否存在目标对象,且知道目标对象所处的图像位置,即本文视觉识别研究最核心的内容——目标检测。在集装箱中,箱体、锁孔和编号等对象的特征明显且单一,但扭锁不同于此类规则的对象,其复杂的类别和形态对视觉识别提出了更高的要求。马爽[3]曾基于Kinect提出了具有自主发育能力的增量PCA扭锁在线识别方法,这种方法考虑到了扭锁种类繁多的问题,实现了简单场景下扭锁对象的在线学习和位姿估计,但该研究不涉及实际装卸应用中还有更重要的目标检测和定位问题。Liang C等[4]曾为扭锁建立过3D模型库,并通过图像比对的方式实现了扭锁对象的识别,该方法虽然对库内对象能实现较好地识别,但缺乏多种环境和多种类型下的泛化能力。高精度的算法通常伴随着深层次的网络和高维度的特征,过程的复杂无疑会影响速度。YOLO算法找到了速度和精度较好的平衡点[3]。
1 模型相关工作
1.1 YOLO检测网络结构
YOLO(You Only Look Once)算法体现出了单一步骤的检测特点。YOLO算法最早由Redmon J等[5-9]于2016年提出,并陆续发布了三代版本的官方模型。在2020年,由Alexey Bochkovskiy归纳提出了精度更高的第四代模型,随后由Glen Jocher提出了第五代模型,截至目前总计已发布了5个版本。大多数基于深度学习的目标检测算法都是采用候选区域+分类器的方式,先在图像上上产生候选区域,再在候选区域上进行分类和回归。YOLO算法则创新地将目标检测问题转换为单一的回归问题,在整张图片输入后,直接通过单一的网络管道实现端到端的目标检测效果。由于YOLO算法优良的检测速度和精度,使其成为一步法(One-Stage)的代表之一。
在第三代YOLO模型中,检测过程仍然沿用了第二代的锚框方式,但数量上有所增加;第二代YOLO中的锚框预设尺寸有5个种类,而到了第三代YOLO中则达到了9个种类。此外,这些锚框被分为3组用于得到3组不同尺度的输出结果,以达到提高模型精度的目的。第三代YOLO中还引入了逻辑回归方法,忽略掉了多余的非最大IOU预测框。为了提高目标检测的分类及定位精度,选择了更深层次的网络结构,将原本的Darknet-19改进为了Darknet-53,卷积层数增加到了53个。由于网络深度的大幅增加,引入了深度残差网络来解决梯度弥散或梯度爆炸问题。虽然第三代YOLO网络结构变得更加庞大,但是每个网络层的训练设置相同,减少了浮点运算,使其仍然保持着很快的检测速度。目前,第三代YOLO仍是稳定性好、成熟化的高性能检测方法之一。
第四代YOLO模型是Alexey Bochkovskiy归纳提出的一种细节更加优化的目标检测模型。可以使用一些通用的单GPU来训练。在检测器训练阶段,验证了一些最先进的Bag-of-Freebies和Bag-of-Specials方法的效果,并且改进了损失函数,采用了马赛克数据增强方法,使其平均精度更高。第五代YOLO模型是由Glen Jocher于第四代模型发布后2个月便提出来的新模型,直到目前为止并没有发表总结性的论文。鉴于目前第四代和第五代属于技术整合阶段,且一直在快速更新内容,本文采用第三代模型进行检测实验。
1.2 VOC数据集建立和训练
YOLO算法属于有监督的深度学习算法,网络模型训练时需要提供带标签的数据集作为训练样本。本文所使用的VOC数据集源自PASCAL Visual Object Classes Challenge[10],2007版本的VOC数据集结构如图3所示,每个数据集节点中包含5个节点。

图3 VOC2007数据集结构
数据集中的图片样本主要来自网络和实物拍摄,其内容包含了多场景下不同角度、数量和距离的扭锁照片,扭锁类型主要为纯手动型及半自动型,样本数量为 913张。而本次模型训练中主要标记了3类对象,如图4所示,包括Twistlock、Switch1、Switch2,全部通过人工借助LabelImg脚本软件进行手动标记。其中,Twistlock表示扭锁主体,对于扭锁的开关,纯手动扭锁是拉杆形式,而半自动扭锁时拉锁形式,故将其区分开来分别标记为Switch1和Switch2。每张样本图片都对应一个.xml解释文件,该文件中记录了同名图片信息以及用于模型训练及学习的标签信息。
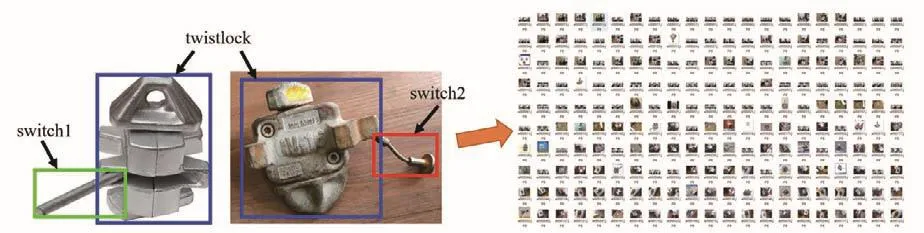
图4 样本集标签类型
从数据集的图片样本中随机抽取10%的样本作为验证集,剩余的90%样本作为训练集。对于训练集样本和验证集样本,需要分别计算其损失,并称之为训练损失(Train Loss)和测试损失(Test Loss)。训练损失使用训练集样本进行计算,主要反映训练模型的拟合效果;测试损失使用验证集样本进行计算,主要反映训练模型的泛化能力。在训练集的样本参与模型的训练过程,用于网络参数的学习优化;验证集的样本不参与模型的训练过程,仅在每次训练之后用于测试模型的检测及泛化能力。
对于大多数现有的YOLO训练模型,集装箱扭锁并没有包含在其中,故需要从零开始训练模型网络的所有层参数。训练过程中每次迭代都采用自适应矩估计(Adam)方法进行参数优化,该方法基于梯度变化,采用一阶及二阶矩估计来动态调整模型参数的学习率。图5为全参数训练过程的损失曲线,其中迭代次数为300次,只显示0~100的损失范围。

图5 全参数训练的损失曲线
从损失曲线可以看出,在前100次迭代过程中,训练损失能较好地降低收敛,但测试损失的收敛并不稳定,甚至在某几次迭代时会出现猛增的情况;在后100次迭代过程中,测试损失依然出现了多次极不稳定的猛增情况,甚至训练损失也同样出现了多次大幅增多的情况。其原因主要在于数据集规模与网络规模不匹配,模型训练时采用的扭锁数据集样本数量不足千张,使用如此小规模的数据集训练庞大的YOLO模型网络,很容易出现梯度爆炸或者梯度消失的情况,导致训练过程中网络收敛不稳定或者过拟合。
1.3 基于迁移学习思想的训练改进策略
迁移学习是一种常用的深度学习处理方法[11],其主要思路是将预训练的模型作为新模型的起点,则能将原本消耗了巨大时间和计算资源的网络模型再次得到利用。基于此,虽然扭锁场景没有出现YOLO官方的训练样本中,但有大量的训练场景所包含的语义与扭锁场景相似。
按照图6所示的训练流程。假设官方模型A训练了N层网络参数,对于要训练的新扭锁模型B,在预加载模型A的参数之后,可以冻结前N-M层参数,仅留训练后M层参数。这样使模型的训练更快收敛的同时保留原模型A的识别能力,适应新的扭锁识别场景。

图6 迁移学习的训练流程
第三代YOLO采用的是Darknet-53网络结构,根据Keras提供的API可以了解到该框架下训练网络的层数为252层,这其中有2个重要的节点:一个是第185层,这是Darknet-53网络的最后一个残差单元;另一个是倒数3层,网络底部3层是3个1h1的卷积层,主要是用于最终的预测输出。
首先,采用冻结185层的方案进行训练,得到如图7a所示的损失曲线,可以看到训练初期的参数收敛较为顺利,但在第90次迭代时仍发生了梯度爆炸的问题。图7b下为模型预加载官方参数后,冻结前249层后的训练结果,其中迭代次数为100次,只显示0~200的损失范围。从图中可以看出,在前70次迭代过程中,训练损失和测试损失都出现了稳定的降低;在70次迭代之后,训练损失和测试损失逐渐稳定在25左右,训练达到了瓶颈。
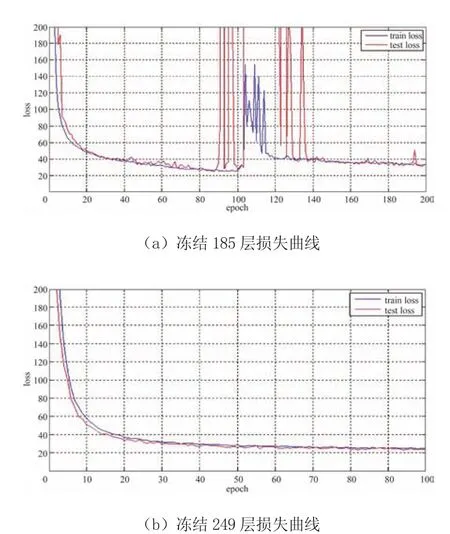
图7 冻结185层和冻结249层的损失曲线对比
迁移学习的训练方法冻结了网络的大量层参数,让模型保留原有能力的基础上快速适应了新的场景,虽然提高了训练收敛的稳定性,但同时也会使得网络的可塑性降低,且冻结层数越多可塑性越低,会更快地遇到学习瓶颈,限制其发展能力。为此,在迁移学习迭代100次后释放冻结的网络层又再次迭代了50次,得到如图8所示的损失曲线。从图中可以看出,释放所有网络层参数后,损失值突破原有瓶颈再次降低,最终训练损失降至15.532 5,测试损失降至15.486 4。

图8 释放冻结网络层后的损失曲线
从训练结果可以看出,在使用迁移学习思想的整个训练过程中,损失值的变化趋势都是稳定的,即使之后再次释放所有层参数,其变化也仍然保持稳定。
不同于从零开始训练全参数模型,迁移学习的方式能在梯度变化较大的初期稳定训练的发展趋势,让网络参数尽快适应新的场景。在网络参数适应并稳定后,再释放其原有塑性,可让整个网络更加契合新的场景。
2 实验结果与优化改进
2.1 扭锁目标检测实验与分析
目标检测的输入是包含RGB信息的图像矩阵,通过网络计算得到目标的识别和定位,识别是将目标分类为所属的目标类型,定位是得出目标在图像中的位置。图9和图10为首次模型检测效果,2张测试照片分别为纯手动扭锁对象和半自动扭锁对象,且该照片均未在数据集样本中出现过。从图中可以看出,模型对扭锁目标的检测效果较好,预测框都较为准确地定位了目标所在区域,3个种类的对象都能被很好地检测,且置信得分和IOU(即交并比,产生的候选框与原标记框的交叠率)都在0.9以上。

图9 全手动扭锁检测效果

图10 半自动扭锁检测效果
图11为复杂背景下的扭锁检测效果,从图中可以看出,即使扭锁处于背景比较复杂的环境下,模型仍然有较高的识别鲁棒性。图12为不同角度的扭锁检测效果,从图中可以看出,模型对于从不同角度的扭锁对象仍然具备良好的识别能力,但由于其中的拉锁被部分遮挡,所以识别的置信得分较低。不过即使目标对象有一定的遮挡,模型仍表现出较好的检测能力。

图11 复杂背景下检测效果

图12 不同角度检测效果
图13和图14分别为扭锁被遮挡30%和被遮挡70%下的检测效果,2种情况下扭锁仍然能被模型检测到,置信分数分别为0.89和0.37。该实验证明了训练模型对于目标物体被部分遮挡后仍然具备检测能力,但是由于遮挡的缘故,检测结果的置信分数较低,且遮挡范围越大,置信分数越低。

图13 遮挡30%的检测效果

图14 遮挡70%的检测效果
图15和图16分别为扭锁在集装箱角件中正面和侧面的检测效果。在拆卸场景下,扭锁安装在角件中通常会被部分遮挡,但训练模型仍然能保持良好的检测效果。

图15 扭锁在角件中正面检测效果

图16 扭锁在角件中侧面检测效果
图17为多扭锁场景下的检测效果,从图中可以看出该模型对于多扭锁场景仍然具备较好的检测能力。图中右上角的扭锁拉杆并未被检测出来,是由于多对象堆叠后造成置信分数较低,从而导致该预测框被阈值筛选去掉。图18为多种扭锁检测效果,可以看出训练模型对于多种类型的扭锁具备一定的泛化能力。

图17 多扭锁场景下的检测效果

图18 多种扭锁检测效果
图19为视频中的目标检测效果,在相应配置下,该模型对720p画质的视频进行目标检测的最高帧率为12 FPS。网络模型的输入图像是包含RGB信息的矩阵,其检测速度主要与矩阵大小,即图像分辨率有关,与图像背景复杂度影响不大。

图19 视频检测效果
2.2 扭锁错误识别优化
在反复的目标检测实验过程中,可以发现一些频繁出现的识别错误类型。图20为模型错误将安全单锥识别成了扭锁主体,从图中可以看出安全单锥的特征确实和扭锁类似,但功能上并不是同一类物品。在模型训练时,数据集中并未放入安全单锥作为样本,但在模型检测时仍检测了该对象,从另一个角度也证明模型具备不错的泛化能力。图21为模型错误将螺栓识别成了扭锁的操作杆,因为2种的外观特征上确实很相似,并且操作杆的特征也比较单一。

图20 错误识别安全单锥

图21 错误识别螺栓
对于基于深度学习的目标检测算法,在遇到复杂识别情况时,通常方法仍然是将类似的物品作为负样本放入模型中进行训练,从而改善网络参数拟合的效果,让模型学会这类物体不是真正的目标,从而减少识别的错误率。
对于图像的深度学习过程,网络只会不断提取图像中所能表现的特征[12],例如形状、颜色分布和灰度梯度等,同时也存在一些不具备物理意义的特征参数,但当图像内容特征提取殆尽后,训练将达到瓶颈。对于特定的现实场景,例如针对扭锁的目标检测任务,存在一些图像属性以外的逻辑特征,这部分逻辑特征无法直接通过训练图像获取,将这部分逻辑特征的判断加入到目标检测的过程中,将会大幅减少错误识别的发生。如图22所示的逻辑判断流程所示,插入后可以有效减少错误识别率。

图22 扭锁目标检测后处理流程图
逻辑特征的本质是判断特定场景下的合理性,在扭锁检测中核心的原则是扭锁(Twistlock)数量和开关(Switch)数量必须对等,且两者有一定的位置关系,不满足相应的关系则可以进行逻辑排除。图23为加入逻辑特征后的目标检测效果,从图中可以看出模型原有的错误识别有了明显改善。其中,图23a中包含了安全单锥对象,但该对象不含有Switch特征,加之Twistlock的置信度低于0.95,则判断其不是Twistlock对象;图23b中包含了螺栓对象,但Twistlock对象只有一个,因此仅保留按照中心点在主体1.2倍范围内的一个Switch,其他的排除。

图23 识别优化后的检测效果
2.3 扭锁目标检测结果二次处理改进
目标检测的结果通常是图像级的,其预测框内除了目标物体的主体外,还包含着一部分背景图像。这部分背景图像对于目标物体后续信息的提取会造成干扰,因此最佳的办法是消除这部分背景区域,只保留目标的主体区域。由于目标检测已经获取了目标对象所在区域的图像级信息,因此只需提取局部图像进行二次处理,达到分清主次的目的。如图24所示,对于图中2个目标对象,分别提取了扭锁主体的局部图和拉索的局部图。

图24 局部图提取
对于图像的已知局部区域,常用阈值法提取对象区域。阈值法通常使用灰度值作为阈值,通过该阈值将图像划分为黑白2部分,分别表示目标与背景区域。单阈值的分割方式过于笼统、缺少细节,故采用双阈值的方式进行二值化分割,输出图像灰度值为
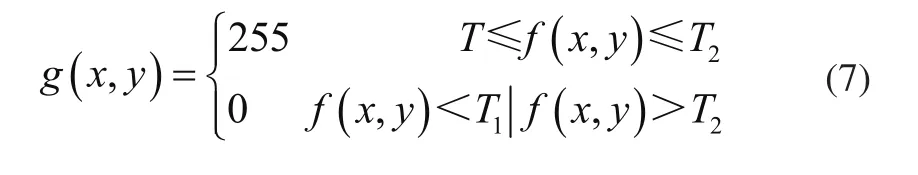
式中:f(x,y)为输入图像灰度值,T1、T2分别表示2个阈值。
对于阈值的选取参考OTSU方法[13],在灰度直方图中,2个阈值将灰度分布划分为了阈值间和阈值外2部分,遍历所有阈值,当2部分组间方差最大且组内方差最小时,可认为此时阈值为最佳阈值。
在得到双阈值二值化结果后,遍历图像中所有像素点,取所有相邻点存在梯度变化的点作为边缘点,并将这些点依据是否相邻归为不同组,每一组代表一个点集,将点集内部点去掉后,每一组点集代表一个轮廓,取点集规模最大的轮廓作为主体轮廓。局部图像的整个处理流程如图25所示,最终结果表示为包含目标物体外轮廓信息的点集。
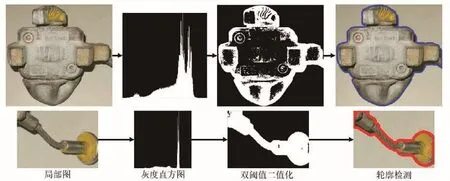
图25 局部图像的处理流程
当局部图像获取了目标物体外轮廓信息后,只需将点集围成的区域填充便可获得目标物体所在区域信息。在原图中将多个局部图提取的区域信息整合,得到最终处理结果,如图26所示,处理后的图像中每一像素坐标所属的对象类型都得到了明确的定义。具体的局部区域可以进一步减少后续处理受到背景的影响,使得特征提取等操作能集中于目标主体本身。该处理过程均采用传统的图像处理方式,不涉及大量网络参数的计算,整个目标检测的速率仍依赖于YOLO模型计算的速度[14]。

图26 二次处理结果
3 结束语
本文研究了码头环境下扭锁视觉识别中的目标检测内容,目标检测作为机器认知扭锁的第一步,解决了机器什么物品是扭锁的问题,为后续进一步的视觉定位奠定了基础。
1)依据目标检测评价指标对YOLO的检测原理和网络结构进行了分析,YOLO算法在多目标及部分遮挡的情况下都具有较好的检测效果;
2)根据扭锁场景建立了包含扭锁主体、推杆和拉锁3种类型对象的VOC数据集,并采用损失函数作为评价标准对该数据集训练了相关的模型网络,基于迁移学习思想改进了全参数训练的方法,提高了模型网络的收敛稳定性和预测准确性,并在训练之后验证了模型在多种情况下的目标检测能力;
3)提出了扭锁场景下目标检测的改进方法,针对模型较强的泛化能力导致的识别错误,通过添加逻辑特征减少了识别的错误率,然后基于图像分割方法实现了检测结果的二次处理。
本文还需要相关的视觉定位方法作为目标检测的辅助。最终构建智能系统的目的,旨在使用本文所述的软件算法部分进行进一步扩展,再结合相应的配套执行硬件——抓取装置,提高码头自动化领域特别是集装箱扭锁场景下的自动化程度,有助于推动其行业的技术进步。
