基于逻辑回归方法的日出气象预报模式研究
——以霞浦县花竹村为例
2022-10-14陈文佳余至成
陈文佳 余至成 王 婧
(1.福建省霞浦县气象局,福建 宁德 355100;2.福建省大气探测技术保障中心,福建 福州 350008;3.福建省气象信息中心,福建 福州 350001)
0 引言
随着经济发展及社会进步,人民群众可支配收入增长,旅游产业地位不断攀升。而气象条件对旅游质量和旅游安全保障等多方面均有影响,随着旅客对旅游气象服务的要求不断提升,传统、定时、单一的预报服务模式不能完全满足旅客的需求,精细化、定制化的旅游气象服务模式将逐渐成为主流趋势[1-2]。近年来,旅游气象服务研究工作实属热门,各地气象部门均对该业务开展了各类研究。赖辉煌等[3]对2020年九仙山的日出日落时间、气象条件等进行了统计分析,结果发现,九仙山可观赏率最高的月份为1月,最有利观日气象条件是前一日风向为偏西风向,为九仙山观日旅游服务提供指导。杨春华等[4]利用茶卡盐湖景区临近气象站观测数据,对景区气象要素开展了统计分析,并对摄影的影响因子云量、能见度、风速和降水进行分级,确定了天空之镜摄影气象指数和摄影气象条件优劣标准。丁国香等[5]针对安徽省山岳型景区的需求,开展了气象景观预报,在计算各类气象条件分级指标后,通过叠加方式确立云海出现的概率情况,以此方法达到定制化服务,而特色景观更多依赖于预报员的经验预报。
作为旅游大县,霞浦县的海岸线达505km,近岸还有“中国最美丽的滩涂”,配合其西高东低的复杂地势,享有丰富的山海资源。正是由于霞浦依山傍海的天然地理环境,使其成为国内外摄影爱好者的宠儿,而滩涂摄影、日出日落摄影等产业的蓬勃发展又进一步促进了霞浦旅游业的发展,到霞浦游玩的旅客数量日益增多,提供精准、及时的旅游气象服务势在必行。
根据前期实地调研和线上意见征集的结果,来霞旅客认为常规气象服务形势单一、内容枯燥、缺乏针对性,对此,他们提出了许多意见。霞浦县气象局听取反馈意见,于2020年开展了一系列精细化旅游气象服务工作。在诸多服务中,广受好评及热议的是2020年10月上线的花竹日出预报服务。花竹村位于霞浦三沙镇,素有“中国观日地标”的美誉[6],其自然资源禀赋优越,具有以“山、海、滩、石、岛、日出”为代表的自然山水景观[7]。作为热门网红打卡点,霞浦县气象局提供了花竹破晓时间、日出时间以及日出指数和气象条件。综合各类研究结论,其他旅游气象类研究对实况数据进行统计分析,并依据分析结果建立分级指数,将分级值叠加或加权后得到各类旅游指数,这种方法缺少预报结论与实况的检验评估。本文就2021年霞浦县气象局花竹日出预报服务进行检验评估,并通过机器学习的方法建立新日出预报服务模式,为后期开展多点服务提供参考。
1 资料和分析方法
利用2021年5月1日至12月31日三沙国家一般气象站和花竹自动气象观测站的逐小时观测数据及实景观测结果,对福建省霞浦县气象局该时段内提供的花竹日出气象预报数据进行检验,并利用Python的开源库Sklearn中的逻辑回归(Logistic Regression,LR)算法,将清洗过的实况数据代入算法进行模型训练,再根据模型预测明日日出情况(实现二分类,即有无日出)。
逻辑回归算法是将某事件发生结果作为因变量,将影响其结果的要素作为自变量建立的回归模型,其因变量应具有二分特性,即结果可以用是或否(有或无)等类似判定词描述,其取值有且仅有两种,在计算机内可以用0或1来表示[8]。目前被较多应用于流行性疾病判识等方面,也被尝试引入电商环境[9],鉴于此,可以将该模式引入旅游气象服务业务工作。以经典糖尿病数据集为例,LR算法模型将人的BMI、年龄、血压等作为自变量,判识该个体是否有糖尿病。通过学习这种预测模式,可以将前期收集到的花竹日出过程中的天气情况、云量、能见度、风速、雨量、相对湿度、气温等数据集和实景观测有无日出的数据集作为训练数据集对模型进行训练,通过计算不同训练集的准确率、召回率等,选取最佳训练集。也就是通过这种方式确定日出的主导影响要素。
逻辑回归曲线计算公式[10]如下:
(1)
f(x)=α0+α1x1+α2x2+α3x3+...
(2)
当变量值通过0值时(如图1所示),可确定函数值为0.5,这里规定当函数值大于等于0.5为正向,小于0.5为负向,从而将函数值二分类。在本研究中,x1、x2、x3……即对应气温、相对湿度、降水量、风速、能见度等要素,α0、α1、α2、α3等为回归系数,L(x)对应有无日出的结果。
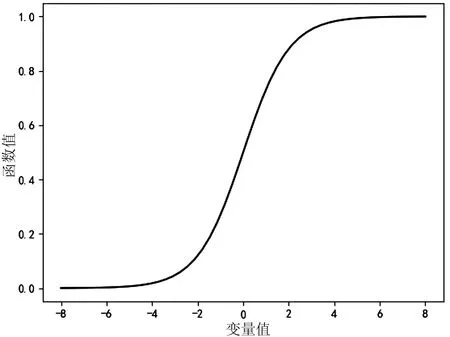
图1 逻辑回归曲线示意图
当确定主导要素后,以该模型开始预测,并再次检验预测效果。
2 多要素回归模拟结果分析
本文使用的观测数据所含要素为气温、相对湿度、降水量、瞬时风速、能见度,对数据进行清洗,筛除缺测和错误数据后,将上述数据引入随机种子random_state=0的参数设置进行拆分,拆分为训练集和测试集,代入编写好的Python程序中进行模拟实验。这里使用的是Python的Sklearn开源库中包含的LR算法。将要素类目分为两组,一组是包含气温、相对湿度、降水量、瞬时风速、能见度、海平面气压、24小时最高气温、24小时最低气温、露点温度、水汽压、人工观测云量(以下称试验1),另一组包含气温、相对湿度、降水量、24小时最高气温、24小时最低气温、云量(以下称试验2)。通过对2组要素进行试验,试验结果如表1、表2所示。

表1 试验1要素的模拟试验结果
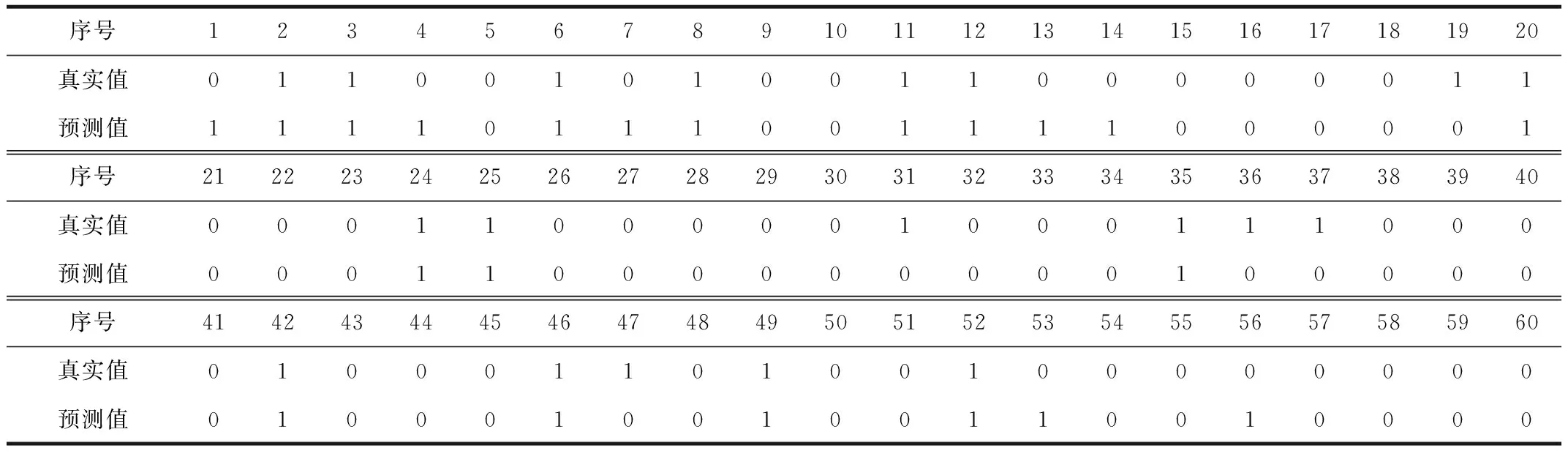
表2 试验2要素的模拟试验结果
将实验模拟结果统计整理成混淆矩阵,如表3所示。表4为2组试验结果的准确率、错误率、召回率、特异度等[11],通过对比这些数值来评估2组模拟方法拟合效果的区别。

表3 LR算法模拟试验结果的混淆矩阵

表4 两组试验拟合效果统计值
比对2组数据的模拟效果检验指标可以得知,相对于试验1,试验2采用了更少的要素场参与拟合,从4项指标值而言,召回率和特异度较试验1相比更优。试验2使用较少的气象要素进行试验时,虽然特异度和召回率有一定程度提升,但提升效果并不明显,且准确率有所降低,更容易出现空报现象。通过试验1、2结果各项的系数对比,发现降水量、24小时最高气温、24小时最低气温影响系数较大,起主导作用,而在模拟中,其他气象要素的影响系数比以上3个要素偏小或小1个量级。
3 随机数种子模拟结果分析
根据上一组试验结果,选取最优相关要素组代入,对使用的随机种子randomseed进行改动,并进行检验,结果表明,当使用随机数种子不同时,模拟效果也不同。通过比对各类检验指标发现,当随机种子设置小于200时,准确率和错误率整体浮动比较小。召回率在选择40~200区间内呈先增加后减少的态势。当随机种子选取大于200时,准确率、召回率骤然降低,特异度略有提升。因此,在预测中将随机数种子适当设置在40~200的区间内,尤其在100左右为最佳。
召回率是指预测日出样本数占实际日出的比重。特异度是指预测无日出占实际无日出样本数的比重。从实际角度而言,这两个值更能反映预报精准度质量。从特异度角度分析可以发现,当随机种子数介于0~200,大部分模拟效果预报无日出的情况都可以达到80%以上的概率,在实际服务中,可以有效规避不利天气对赏日出行规划的影响。
在实际业务服务日出预报中,更注重召回率,即精准预测日出的情况,对于过拟合的情况,其实是对日出概率的悲观考虑,使用随机种子在0~200区间可以提升预报准确率,使用随机种子在100左右效果尤佳,而且能够从很大程度上提高日出预报中有效日出预报占比,从而提升游客对服务效果的信任度。
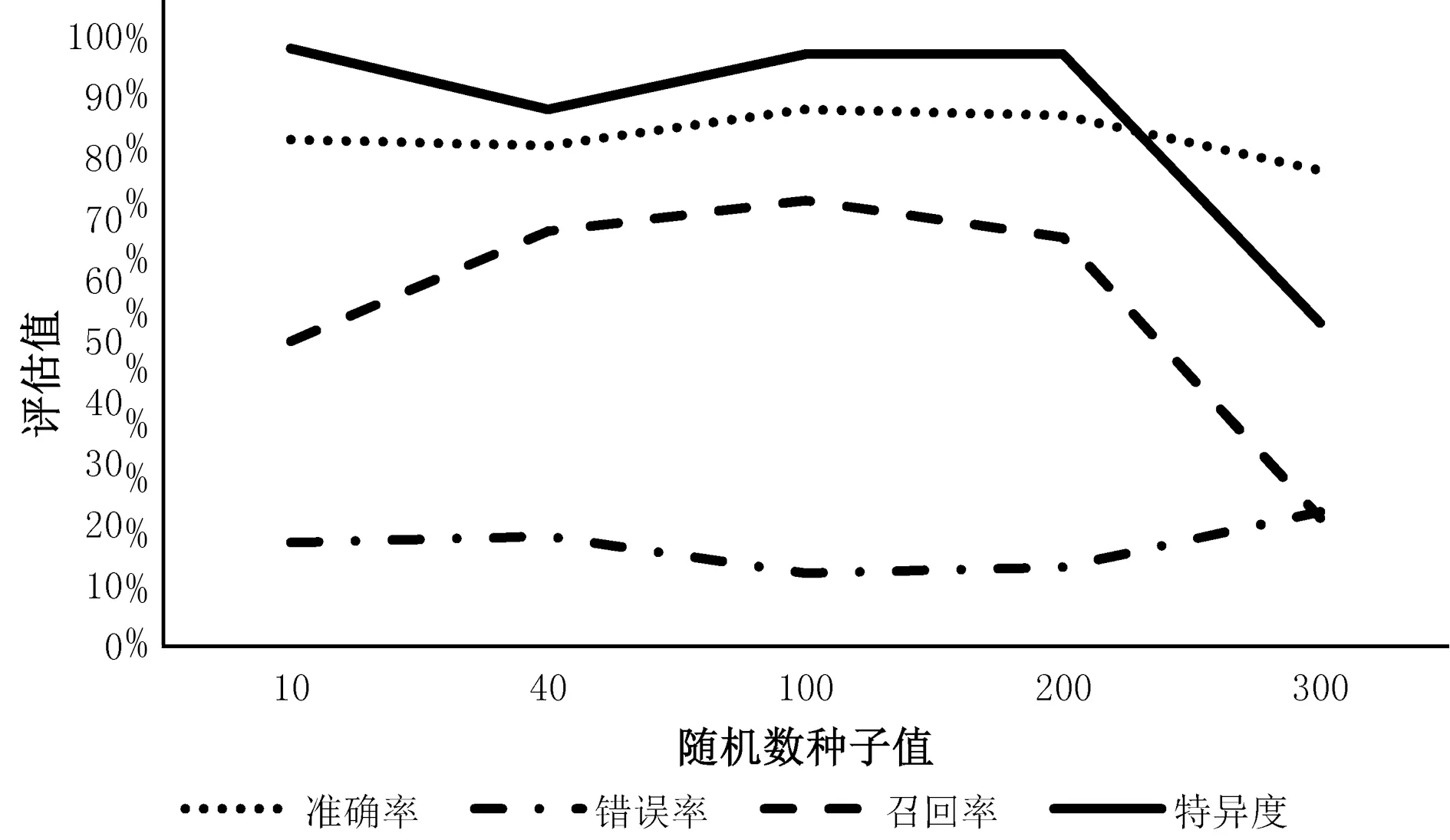
图2 不同随机数种子值模拟检验结果
综合上述指标,将随机种子值定为100,进行模拟运算,获得式(3)、式(4)预报模型。
其中,x1是逐时平均气温,x2是逐时相对湿度,x3是逐时降水量,x4是24小时最高气温,x5是24小时最低气温,x6是日出时刻人工观测云量,x7是逐时极大风速,x8是逐时能见度,x9是逐时海平面气压,x10是逐时露点温度,x11是逐时水汽压(数据时间选择的是05—06时这一小时)。
确定随机数种子最优值后计算各要素回归系数,其系数值分别为-0.01417,-0.03609,-0.02613,-0.04751,0.04295,-0.06742,0.06934,-0.0001083,0.006641,0.04475,0.03082。
(3)
f(x)=-0.01417x1-0.03609x2-0.02613x3-0.04751x4+0.04295x5-0.06742x6+0.06934x7-0.0001083x8+0.006641x9+0.04475x10+0.03082x11-0.0001704
(4)
4 结论与讨论
利用Python的Sklearn库中的LR算法,对日出预报服务进行改进,将机器学习的方式引入当前业务工作中。利用自动站获取的2021年5月1日至12月31日逐时要素数据,进行机器学习算法,获得逻辑回归算法模型。
通过模拟试验,可以得出以下结论:
①选取不同要素进行模拟试验的结果表明,选取较少的气象要素个数虽然会提升召回率但会造成准确率降低,以及空报的概率增加。选取过多的要素会造成结果过于悲观,召回率低,故应结合实际选取要素。
②将不同随机数种子值代入试验结果表明,当随机值在0~200的区间内时,特异度和准确率均可达到80%以上,可以较好地模拟日出情况。当随机种子处于40~200区间内,召回率呈先增加后减少的态势,当处于100左右时达到最优。
③选取最优因子和最优随机种子值进行模拟,计算得到的回归模型可以将模式输出的平均气温、降水量、相对湿度等气象要素代入运算,获得预测值。预测值大于0.5,表示可见日出;预测值小于0.5,表示无日出。
本文引入机器学习中常用的LR算法对日出预报进行模拟试验,该方法既将实况数据纳入了预报中,还可满足预报检验的需求,同时利用机器学习的特点,实现动态模型的预报模式。但这种方法还存在几点问题:
①LR算法更多针对的是二分类数据,但在实际服务中,除了有无日出,日出还有多种多样的形态,这种算法适用范围有限。
②选取的2个站点缺乏云量自动观测数据,从第二大点的随机值试验的系数值中可以发现,在最优随机值时,系数较大的其中一项气象要素为云量,文中使用的云量为人工观测,后期可以借助卫星遥感的数据对云量数据进行改进,实现自动预报的学习模式。
