自然光条件下文本识别系统的设计与实现
2022-10-14冯志昕杨景皓李鑫龙周翔王震
冯志昕,杨景皓,李鑫龙,周翔,王震
(中国矿业大学(北京),北京 100083)
0 引 言
随着科技的迅速发展,人们对电子文档的使用不断增加。如何从文档图像中准确地提取出文本信息成为一个亟待解决的问题。近几十年来,国内外科研工作者不断探索、不断开发,从最早的光学字符识别器,到如今利用手机便可提取图像中的文字,文档图像识别技术已日益成熟。在文字识别的过程中,图像本身因素和外界因素,如反光、局部遮挡、图像污损、倾斜拍摄等,都会对文字识别的精确度带来很大的误差。因此,在文档识别之前,对图像进行预处理和倾斜校正便显得十分重要。
1 预处理图片
灰度化处理、二值化处理、去噪处理和倾斜校正是图像预处理操作当中一些基本的步骤。本文通过对现有的几种常用的预处理算法进行对比实验,得到了一套完整的图像预处理方法。
1.1 图像灰度化处理
目前绝大多数拍摄的图像采用的颜色模式都是RGB模式,考虑到文本识别的特性,冗余颜色信息的去除一定程度上可以增加识别准确率和运算速度,为此对图像进行灰度化,并进行后续的二值处理。常见的灰度化处理方法包括伽玛矫正法、平均值法和加权均值法。
(1)伽玛校正法。伽玛校正是为了使输出图像的灰度值与输入图像的灰度值呈指数性关系,对输入图像计算出的灰度值进行非线性操作。伽玛校正由以下幂律表达式定义:

其中:表示一个常量,通常取值为1,一般[0,1]为输入输出范围;为非负实数值;当<1时光照强度变强,当>1时光照强度变弱。
(2)计算最大值法。彩色图像中RGB三部分中的最大的值作为我们所求的灰度图像中像素点对应的灰度值,我们这样做的目的是为了能够让图像变得更加突出,从而更容易观察。它的数学表达式为:
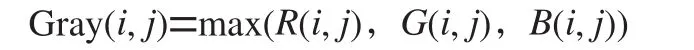
(3)加权均值法。按一定权值灰度化后,对、、的值进行加权平均。即:
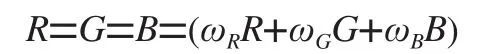
出现在上式中的分别是、、的权值。因为人的眼睛对绿色的敏感度最高,其次是红色,对蓝色的敏感度最低,基于此对三种颜色分量赋予不同的权重。通常情况下,ω=0.21、ω=0.72、ω=0.07。其数学表达式如下:
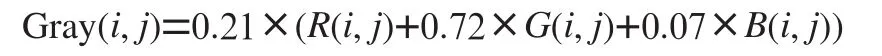
1.2 二值化处理图像
对图像进行二值化处理是将图像中灰度值处在某一特定值以下的像素点的灰度值设置为0,阈值以上的像素点的灰度值设置为1,其中“0”表示纯黑,“1”表示纯白。二值化处理的关键在于阈值的选取,可以分为动态阈值计算法、局部阈值计算法和全局阈值计算法三种。常见方法包括全局阈值计算法中的Otus(大津算法)和局部阈值计算法中的Sauvola算法。
(1)大津算法。大津算法(Otsu),又称为最大类间方差法。它假定输入进去的图像根据其设定的某一特殊值可将图像分成目标和背景两个组成部分,然后再通过计算让这两个部分的类间方差变得最大,同时要让它们之间的错分概率最小,最后将类间方差中最大的值来作为目标最佳的阈值。
(2)Sauvola算法。Sauvola算法是针对文档二值化处理的,其原理是以当前的像素点为中心,然后动态地计算出这一像素点的阈值,根据当前像素点的邻域计算出的灰度均值与标准方差。
1.3 去除噪声
我们在日常生活拍摄的图像中可能会存在各种妨碍人们获取想要信息的因素,我们把这些可能妨碍我们获取信息的因素统称为图像噪声。图像中一般存在的噪声主要有椒盐噪声和高斯噪声两种。本小节将主要介绍这两种噪声以及去除这两种噪声是我们可能会用到的处理手段。
1.3.1 噪声的主要类别
(1)椒盐噪声。所谓椒盐噪声,椒为黑,盐为白,是一种白色或黑色的像素点,可能是在明亮的区域内有黑色的像素点或是在黑暗的区域内有白色的像素点。椒盐噪声往往是由图像切割引起的。椒盐噪声的概率密度函数可以表示为:
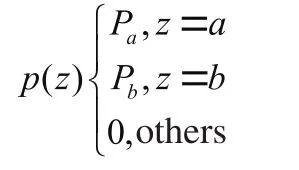
(2)高斯噪声。高斯噪声在图像噪声当中较为常见,主要是以麻点的形式存在于图像当中。高斯噪声的概率密度函数服从正态分布,可以表示为:

其中,表示灰度值,表示均值或期望,表示的标准差。
1.3.2 降噪方法研究
(1)中值滤波。针对椒盐噪声的问题,比较好的滤除脉冲噪声的方法是应用中值滤波,中值滤波是非线性滤波器技术的一种。通常使用一个含有奇数个像素点的滑动窗口实现这个功能,用滑动窗中数据的中值来代替中心点的灰度值,从而消除孤立的噪声点。常用的中值滤波窗口形状有线形、矩形、圆形以及十字形。
(2)高斯滤波。高斯滤波能够平滑图像并抑制高斯噪声。其方法是用一个奇数位的滑动窗口扫描目标像素点并对窗口中的像素点进行加权平均,最后用这个加权平均值来代替目标像素点的灰度值
1.4 倾斜校正
在经过灰度化、二值化、去噪处理之后的图像,还需要对其进行倾斜校正,统一文字的方向。准确的找出文档图像的倾斜角是图像倾斜校正的关键所在。角度检测算法可以分为以下四类,分别是:投影法、霍夫变换法、傅里叶变换法、近邻法。本小节将介绍倾斜校正中比较常用的两种方法,投影法和霍夫变换法及相关的研究工作。
1.4.1 投影法
以投影为基础的校正方法,主要是利用图像水平和垂直方向的投影特征来进行倾斜判断。主要用到投影一些常见的统计特性。在图像投影时,对于一条直线,最短是沿着他的水平方向投影,最长是沿着他的垂直方向投影,如图1所示,我们将此称为Radon变换。
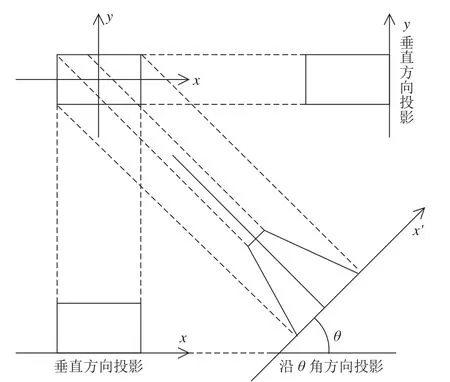
图1 矩形函数在水平垂直方向和沿θ角方向的投影
投影角度可以是任意的,通常情况下(,)的Radon变换是(,)平行于轴的线积分,格式如下:
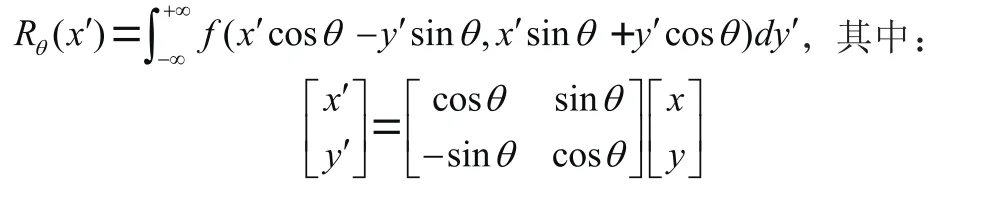
1.4.2 霍夫变换法
霍夫变换法主要是通过坐标空间变换,将直角坐标系中图像各个像素点的位置转换到对应的极坐标系中去,通过分析极坐标系中点位置的特点来检测出原图像的倾斜角度。
具体的霍夫变换原理介绍如下所示:假设图像空间内有一条直线为=+。其中,表示直线的斜率,表示直线的截距。同样,此直线也可以用极坐标如下表示:

上式中,表示原点到直线的垂直距离,表示垂线与轴所成的夹角。该式可以进一步改写为:
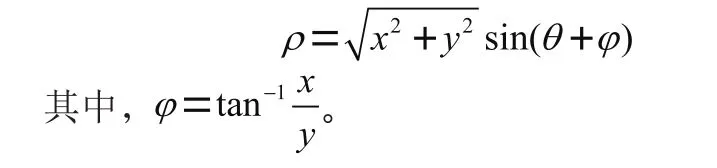
图2中,当左图空间坐标系中直线上的多个点映射到右图的极坐标系中时,会在极坐标系中形成多个曲线,这些曲线会有一个共同的交点,该交点处的和值便是笛卡尔坐标系中直线的和的数值。在进行霍夫变换过程中,同一直线上的不同点映射到极坐标系时,极坐标系中(,)点处上的直线个数会不断累加,该点就会形成一个峰值。在极坐标系中寻找此类峰值便可以推导出图像空间中直线的存在,而峰值对应的点的纵坐标便是直线的倾斜角度,可以用此倾角来表示图像的倾斜情况。
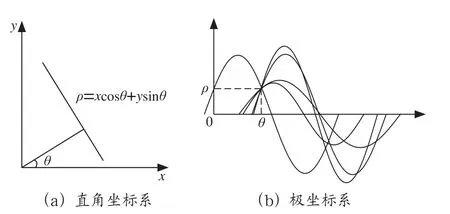
图2 霍夫变换表示方法
2 系统设计与测试实验
对于系统设计,图像预处理和文字识别两种操作通常是字符识别系统的主要功能。设计的可视化系统从这些常用的操作出发,隐藏了算法实现的细节。主要功能如图3所示。
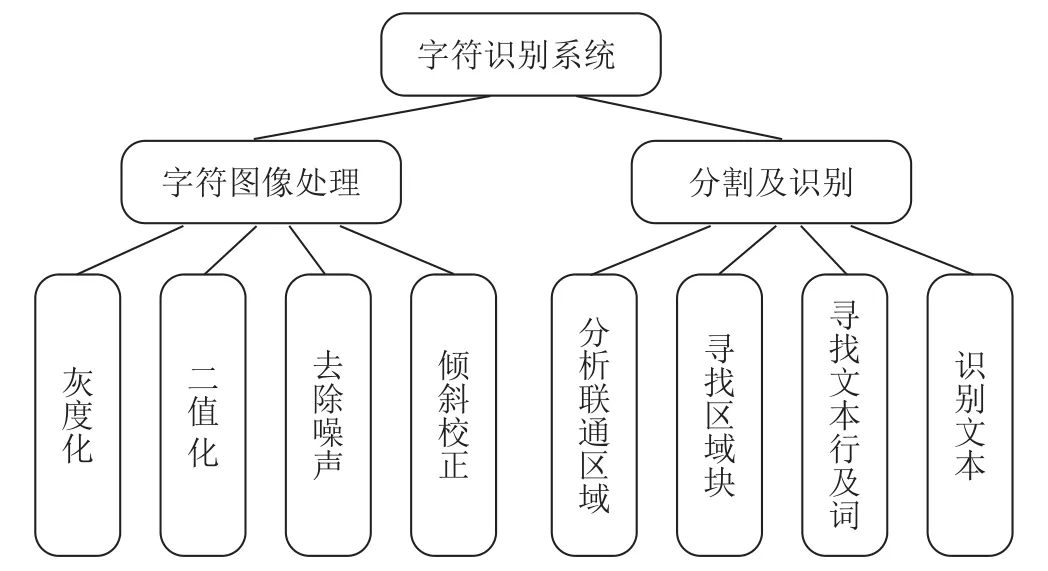
图3 可视化系统主要功能
2.1 算法选择
(1)灰度化:综合本次研究对象的具体情况,最终择加权均值法作为系统灰度化处理的方法,这样更符合人类眼睛审美,也便于后续的图像分割和图像识别;
(2)二值化:尽管大津算法更好的适用于双峰图像,但是对于多峰图形,只需对大津算法稍加扩展也可以完成,基于此,本系统选择Otsu对图像进行二值化处理操作;
(3)除噪:高斯白噪声作为图像中最常见的噪声,高斯滤波器也会被广泛应用。它的一个优点是,高斯函数经过傅里叶变换之后仍旧为高斯函数的形式,本系统基于高斯函数本身具有的优点,采用高斯函数对图像做滤波处理;
(4)倾斜校正:综合考虑准确率、运行时间、平均误差等参数,系统选择投影方法作为文档图像倾斜校正的方法。
2.2 测试实验
GUI识别界面及识别结果如图4所示。

图4 GUI识别界面及识别结果
3 结 论
本文基于百度文字识别API,利用Qt Designer开发出了一个文字识别系统的工具,主要的研究工作是对文档图像预处理阶段各个步骤不同算法之间的比较。通过实验得出,在识别图像较亮的情况下,本系统采用加权灰度化的方法,使用大津算法进行二值化,针对图片中比较常见的高斯噪声,采用高斯滤波进行去噪,最后采用投影法进行倾斜校正,调用百度API进行文字识别。
面对现实生活中拍摄图片的随机性,比如污点、光照不均匀等,本系统在预处理和识别方面还需要进一步的改进。除此之外,随着研究的进一步深入,可以在纯文字图像识别的基础上,进行公式识别,实现更加复杂的功能。
