基于时序分析的电网合并单元电平预测
2022-10-13张朝辉林康照秦冠军金岩磊
张朝辉,罗 炜,林康照,秦冠军,金岩磊,丁 笠,周 宇
(1.中国南方电网有限责任公司超高压输电公司广州局,广州 510663;2.南京南瑞继保电气有限公司,南京 211102;3.南京航空航天大学计算机科学与技术学院,南京 211106)
引 言
随着国内经济的迅猛增长,国民用电需求也在快速增长。与之相对应的,中国的超、特高压输变电技术也正式走向了完善和成熟。在高压输电技术日趋成熟的前提下,如何做到精益求精,对超、特高压输变电工程安全性、稳定性和智能化的要求越来越高,成为一个急需面对的严峻问题。目前直流输电正朝着高电压大容量的技术方向发展,直流输电的长距离输电等方面优势明显,但也会出现一些关键设备由于故障造成的直流系统非正常停运,对电力系统造成的影响越来越大[1]。因此,提高对直流关键设备的感知程度,对电网中关键设备存在的潜在故障隐患进行提前预判采取相应的对策,将故障消灭在萌芽阶段,对降低直流系统非正常停运风险并保证供电可靠性具有重要的意义。
合并单元装置为直流控制保护系统提供真实有效的电流或电平信息,是直流关键设备,是直流测量装置的重要组成部件[2]。合并单元装置用于接收直流测量装置的数字采样信号,合并各直流测量装置的采样数据并进行组帧,然后通过光纤介质按照标准通信协议分别传输到直流控制保护等设备。同时,它还要通过供能光纤为直流测量装置的远端模块(Remote terminal unit,RTU)提供激光能量作为其工作电源。在运行时,如果出现激光器驱动电流高、激光器温度高或者接收数据电平低的情况,会导致直流测量出现偏差,造成直流非正常停运[3]。
当前,针对合并单元装置的运行状态存在一些监视措施,但大多是利用已有经验来设置合并单元设置阈值。当合并单元装置中某些数据超过或低于已设阈值时,系统发出告警信号。这种方式仅能区分系统的“健康”和“不健康”状态,对处于中间区域的“亚健康”状态无法识别并及时预警。除此之外,此方式缺少对监视数据进行充分的挖掘和分析,不能及时发现隐藏在电网时序数据中的信息和趋势。鉴于此,考虑到监视数据具有时序性,本文提出利用时序分析方法对监测数据进行时序分析并预测未来值从而达到评估合并单元设备状态的目的。而且,考虑到合并单元激光器电平是合并单元的关键参数之一,着重根据合并单元激光器驱动电平的监视数据进行合并单元设备状态的预测研究,以期创建预测电网时序数据模型,挖掘数据中的隐藏信息和趋势,降低维护成本,提高故障排查效率,分析和掌握设备状态信息,实现合并单元设备及时预警[4]。
1 相关工作
国内外研究学者提出很多基于时序数据的分析方法[5-8]。这些方法经历了从传统的时序模型到基于机器学习的模型,以及从单一模型到组合模型的发展,都对时间序列数据进行分析,根据时间序列体现出的趋势、规律和方向对后续过程进行扩展和总结,进而预测下一段时间内的数据水平。
传统的时间序列分析方法有很多种。1927年数学家Yule提出自回归(Autoregressive,AR)模型,根据之前已经存在的数据来预测未来下一时间点。1931年Walker提出滑动平均(Moving average,MA)模型和自回归滑动平均(Autoregressive moving average,ARMA)模型。MA模型是一种根据时序数据通过计算移项、时间序列的平均值来体现数据长期趋势的方法。相较于AR模型和MA模型,ARMA模型在谱估计和谱分辨率方面表现更为优异,与其相对应的参数估算也较为复杂。上述3种模型的构建均以平稳时间序列为前提,而差分整合移动平均自回归(Autoregressive integrated moving average,ARIMA)模型的优点在于可以对非平稳的时序数据建模进行时序分析预测[9-10]。
时间序列预测研究与机器学习方法中的回归分析关系密切。机器学习方法中包括了常见的支持向量机(Support vector machine,SVM)[11]、贝叶斯网络[12]等,矩阵分解等方法也常用在时间序列数据的分析预测方面,并取得了不错的效果。Kim[13]采用SVM对股票价格指数加以预测取得了很好的效果;Tay和Cao[14]也将SVM应用在金融时间序列数据方面进行预测;Das和Ghosh[15-16]提出将时空信息融合到贝叶斯网络,对气象领域的时间序列数据进行预测;在应对高维度时间序列时,一般的时序分析模型往往难以应对,因此Yu等[17]提出一种时间正则矩阵分解技术,可以很好地解决此问题,而且在包含了噪声数据的时间序列数据方面展现了良好的鲁棒性。
近年来,随着深度学习的不断深入发展以及广泛应用,它在时间序列预测方面也是有效的[18-20],尤其是循环神经网络(Recurrent neural networks,RNN)的使用。RNN可以解决时间上的延续性问题[21]。虽然RNN将整个时间序列信息转换成一个向量,但始终存在一个无法解决的问题,就是时序数据在时序长度不断增加的情况下,RNN的记忆能力与时序长短成反比而不断减弱,最终效果也就不甚明显,由于存在如此缺陷,会导致RNN无法克服自身存在的长期依赖的问题[22]。长短期记忆网络(Long short-term memory,LSTM)由Schmidhuber在1997年提出,其目的就是为了弥补RNN的不足之处。它引入了一个上下文向量,进而在解码过程中可以选取最相关的信息,因此非常适合用于时序数据分析,构建预测模型。
但无论是传统时序分析方法中的ARIMA模型、机器学习方法中的SVM、还是深度学习中的LSTM神经网络,没有一种特定的单一模型能够统一对电网时间序列数据做出最好的预测,因此组合模型应运而生。组合模型可以弥补单个预测的缺点,受益于单个预测之间的相互作用以及各个模型的多样性,在减少单一模型使用风险的同时又能够提升预测精度。在组合预测模型中,如何分配每个单一预测模型的权重系数是提高预测准确性的关键。大多数研究采用相对简单的等权平均组合预测法和均方根误差组合预测法。等权平均组合预测法中的各个模型同等重要,即所有权重都相等,没有给预测更准确的单一模型分配更多的权重,即没有优选的概念,而均方根误差组合预测法存在权值不稳定的问题。考虑到蛙跳算法(Shuffled frog leaping algorithm,SFLA)具有很强的全局收敛性和局部搜索细致等优点[23],因此,选取SFLA求得组合模型中各个模型的较优权重值,在各个单一模型基础上综合优化进而提高预测准确性。
2 合并单元设备状态研究
合并单元设备状态研究与数据息息相关。考虑到合并单元激光器驱动电平是合并单元设备的一个关键参数,本文根据合并单元激光器驱动电平的监视数据进行合并单元设备状态的预测研究。
2.1 数据准备
本工作数据来源于中国南方电网从2017年9月到2019年8月的超高压换流站设备合并单元激光器驱动电平数据记录。
考虑到要分析数据的时序性和趋势性特征,而初始数据是散乱分布于数据库中的,因此需要以下一系列的数据预处理来构建一个干净的数据集。
(1)数据存取高效性保证:为了保证高速、有效地对数据进行划分、筛选和清洗,将所有数据从数据库中导出,并以JSON或者CSV文件格式存储。
(2)数据时序性保证:鉴于合并单元设备数量众多,需要对每台设备的监视数据进行分析,为了分析每台设备随时间变化的运行状态,需要对数据按设备进行划分,并按时间节点对每台设备的监视数据进行排序,确保数据的有效性和时序性。
(3)冗余数据滤除:在所有监视数据中存在冗余数据,即存在因为停电、故障等原因造成的某个时间段内数据值缺失的问题,因此,需要将这些无效数据进行清洗和过滤,进而确保所收集数据的真实性和有效性。
在获得干净的数据集后,可以对监测到的合并单元激光器驱动电平数据进行趋势分析。
2.2 数据趋势分析
为了更好地分析合并单元激光器驱动电平数据随时间变化的趋势性和规律性,分别按天、周对合并单元激光器驱动电平数据进行随机抽样,分析其规律性和趋势变化。
2.2.1 一天内数据分析
对过滤后的数据集进行随机抽样,选取3天的合并单元激光器电平数据进行分析,其采集数据随时间的变化如图1所示,其中3个分图分别描绘了在一天时间内合并单元激光器驱动电平的变化趋势。
从图1可以分析出,合并单元激光器驱动电平在正常工作情况下,其值会趋于保持在一个稳定范围内,会有随机的波动,但值的波动幅度较小,且驱动电平值均在正常值范围之内变化。
2.2.2 一周内数据分析
对过滤后的数据集进行随机抽样,选取了3周的驱动电平数据进行分析,结果如图2所示,其中3个分图分别描绘了在3周时间内合并单元中激光器驱动电平的变化趋势。
从图2可以分析出,激光器驱动电平在正常工作情况下,其值依旧会趋于保持在一个稳定范围内,会有随机的波动,但值的波动幅度不大,且驱动电平值均在正常值范围之内变化。为进一步确定采集到的激光器驱动电平数据是否为一个平稳时间序列,可采用计算均值、标准差等方式。
3 合并单元设备状态分析方法
对处理好的合并单元激光器电平数据,选取、确定一些时序性分析方法,尝试建立预测模型,对合并单元设备状态进行组合模型预测分析。
3.1 组合模型预测优化原理
组合模型的原理是分别对单一时序预测模型预测结果进行再处理,首先采取一定的方法计算后得到适当的权重,然后对各个模型的预测结果加权平均计算,以最终得到的结果作为最终预测结果。组合模型可以在多个单一模型预测结果的基础上综合优化,降低单一模型不适用的风险,提高预测精度。本文选择将传统的预测模型分别和SVM、LSTM神经网络构建两个组合预测模型对电网数据进行实验,分析挖掘数据内在的规律,组合模型的基本原理为

式中:yi(i=1,2,…,n)为真实电量时序数据;ypj(j=1,2,…,k)为第j个模型的预测值;Wj为第j个模型权重的估计值,满足和wj≥0;yp为组合预测值。
本方法进行预测的基本原理是基于误差平方和最小的固定权系数进行组合预测,即

本文采用SFLA算法对式(2)进行优化,即误差平方和取得最小值时,得出相应权重系数,并赋值给式(1),从而获得最优组合预测值。
3.2 组合模型预测优化过程
(1)ARMA模型。ARMA模型进行时序数据分析的首要条件是数据平稳性,它是由AR模型与MA模型两个传统时序模型改进结合两者优点而构成的模型。假设一个随机过程在时间的维度上,通过计算其均值和方差值,如果两者的计算结果都是固定不变的数值,满足这样条件的随机时间序列即为平稳的。ARMA模型可表示为

式中:p、q分别代表了ARMA模型的阶数,简记为ARMA(p,q),即时序预测值Yt是现在和过去的误差或冲击值εt以及在此之前的时间序列Yt-1的线性组合。
(2)ARIMA模型。ARIMA模型是针对不满足平稳性条件的时间序列建模。通过差分将非平稳的时间序列进行平稳化。ARIMA模型本质上可以也能看作AR模型与MA模型的组合,但和ARMA模型有所区别。ARIMA模型可表示为
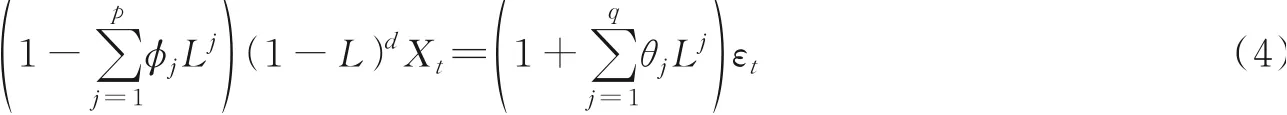
式中:L代表滞后算子;d表示对非平稳时序数据经过d次差分后得到的平稳的时序数据。
(3)SVM模型。SVM模型是以统计学理论为基础的学习方法,在高维数据处理方面有较强优势,而且可以在参数少、样本小的条件下具有很好的泛化能力。从理论上分析只存在唯一的全局最优解,其泛化能力在小样本集合条件下有更好的体现。SVM模型的性能由误差惩罚因子C和核函数中的参数决定。误差惩罚因子的作用在于确定数据子空间时调节置信区间范围。本文选用径向基函数作为核函数,其参数σ为径向基半径。在构建支持向量机模型时,需要综合衡量之后合理地选择支持向量机的参数,提高模型的学习和泛化能力。
(4)LSTM神经网络。LSTM模型具有记忆长短期信息的能力,可以从过去的数据中挖掘有用信息来分析未来变化的规律。LSTM网络可以解决梯度消失不能进行很好反馈的问题。根本原因在于LSTM网络采用记忆块取代传统的RNN的隐含节点,从而能够更好地学习时序数据内在长期依赖关系。LSTM神经网络模型在训练时涉及到许多超参数的设定,设神经元数量为m,时间步长T,批数据大小batch size,迭代次数epoch轮。神经元个数决定了神经网络对时序数据的拟合程度,时间步长和批数据大小决定了模型训练的结果,选择适应性矩估计(Adaptive moment estimation,ADAM)优化器对参数进行优化调整。
(5)SFLA算法。基本原理是:在D维搜索空间内,随机产生一只青蛙种群。Xi=(xi1,xi2,…,xid)表示种群的第i只青蛙个体,并按照适应度进行非递增排序,然后将种群按照一定方法分为s个子群。其方法为第一只青蛙分配到第一个子群,第二只青蛙分配到第二个子群,第s只青蛙分配到第s个子群,值得注意的是第s+1只青蛙会重新分配到第一个子群,以此类推,直到青蛙分配完毕。
在每个子群,适应度最优的青蛙个体设为Xbest,适应度最差的青蛙个体设为Xworst。对整个青蛙群体而言,一定存在适应度最优的青蛙个体,记为Xg。对从第一个子群开始对每个子群进行局部搜索,最终搜到第s个子群,在这个过程中,按照以下更新策略迭代每个子群中最差的个体。
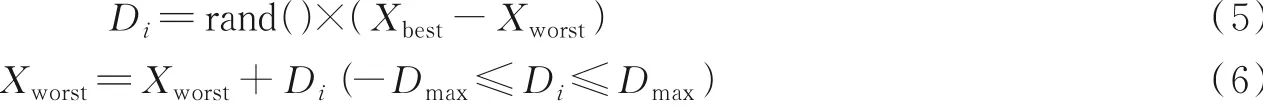
式中:rand()表示范围大于零小于1的随机数,Dmax为青蛙个体可以移动的最大步长。如果经过更新迭代后,计算出的最新的Xworst个体优于原来的Xworst个体,则取代原子种群中最差的青蛙个体,否则就用Xg代替Xbest重新进行更新,如果其适应度仍没有改进,则随机产生一个X'worst取代原有的Xworst。不断执行上述步骤,直到完成所有更新。当子群体全部经过局部搜索后,将青蛙个体进行混合运算,重新划分子群,进行局部搜索,直到迭代次数完成为止。
4 实验评估
4.1 评估度量指标
(1)算术平均值,表示为

(2)方差,表示为

(3)均方根误差,表示为
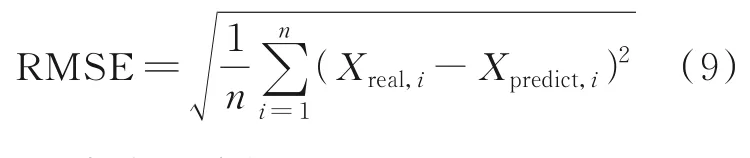
4.2 实验结果分析
随机选取一台合并单元设备从2020年5月1日到5月30日的数据进行实验分析评估,电平数据采样的时间间隔为5 min,数据的趋势变化如图3所示。从图3可以看出,合并单元在正常工作状态下,激光器驱动电平趋于平稳,波动幅度较小,其算术平均值趋近于一个常量,方差值亦趋近于0。此外,运用迪基-福勒检验进行单位根校验[25],计算得到p值小于0.01,说明此时间序列在超过99%的置信水平下是显著的,即数据是时间平稳序列,不需要经过差分运算就可以建模。
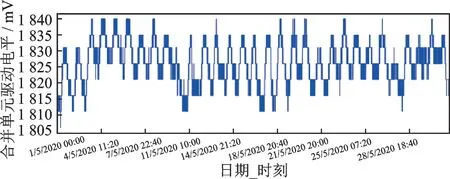
图3 激光器驱动电平一个月内数据变化图Fig.3 Data change diagram of laser drive level within one month
本文方法中的参数设置:基于激光器驱动电平的数据是时间平稳序列,先建立ARIMA(1,0,2)模型,确定模型参数,进行预测。将惩罚因子C设为10,用径向基函数(Radial basis function,RBF)作为进行预测。优化误差惩罚因子C和核函数能够很好提升SVM的性能,LSTM神经网络的神经元数量m=128,批数据大小batch size=32,迭代次数epoch=10。SFLA算法的群体数为150,子群数s=5,子群迭代次数设为50,混合迭代总数1 000。
将提出的基于SFLA算法优化的ARIMA(1,0,2)和SVM组合模型方法与等权组合模型方法、ARIMA及SVM的预测结果进行比较,验证SFLA算法优化后组合模型的有效性。从图4可以看出,采用SFLA算法优化组合模型所预测的曲线与ARIMA(1,0,2)和SVM预测曲线相比,在合并单元驱动电平数据发生变化上更加接近真实电平曲线。
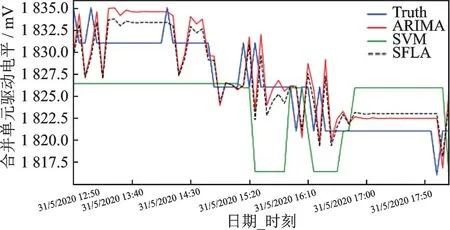
图4 ARIMA、SVM、SFLA预测模型的预测结果Fig.4 Prediction results of ARIMA,SVM and SFLA models
表1通过均方根误差指标评估组合模型质量,SFLA算法优化组合模型的均方根误差为3.12,优于单一的ARIMA模型和SVM模型。说明基于SFLA算法优化组合预测模型比单一模型更加适合应用在电网中电平预测,获得的预测效果更好。
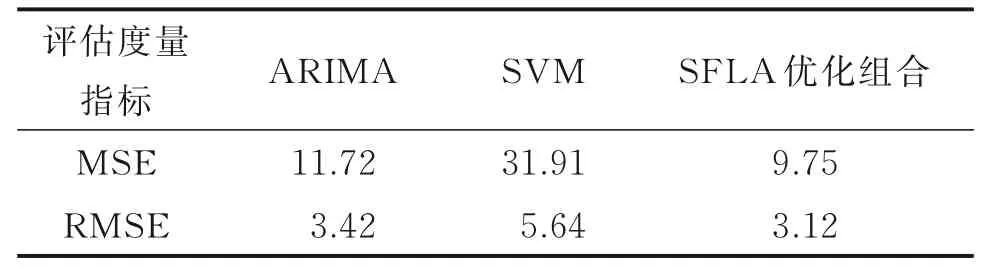
表1 SFLA优化组合模型与ARIMA、SVM模型的性能对比Table 1 Performance comparison among ARIMA,SVM models and the combined model optimized by SFLA
将提出的基于SFLA算法优化的ARIMA(1,0,2)和LSTM神经网络组合模型方法与等权组合模型方法,ARIMA(1,0,2)及LSTM神经网络的预测结果进行比较,验证优化后组合模型的有效性。从图5中可以看出,采用SFLA算法优化组合模型所预测的曲线比ARIMA(1,2)和LSTM预测曲线相比更加接近真实电平曲线。ARMA(1,0,2)可以很好拟合真实电平在运行过程中变化的曲线,但SFLA算法优化组合模型可以在ARIMA(1,0,2)模型的基础上进一步提升拟合精度。
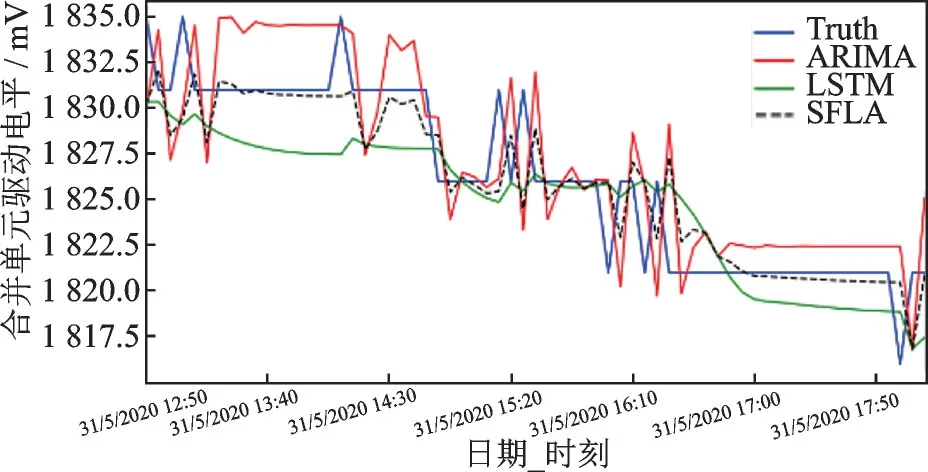
图5 ARIMA、LSTM、SFLA预测模型的预测结果Fig.5 Prediction results of ARIMA,LSTM and SFLA models
表2说明,经过SFLA算法优化的ARIMA-LSTM组合在预测模型的均方误差和均方根误差上均优于单一模型,组合模型可以结合两个模型的优点提高预测精度,在电平数据预测中获得更好的效果。
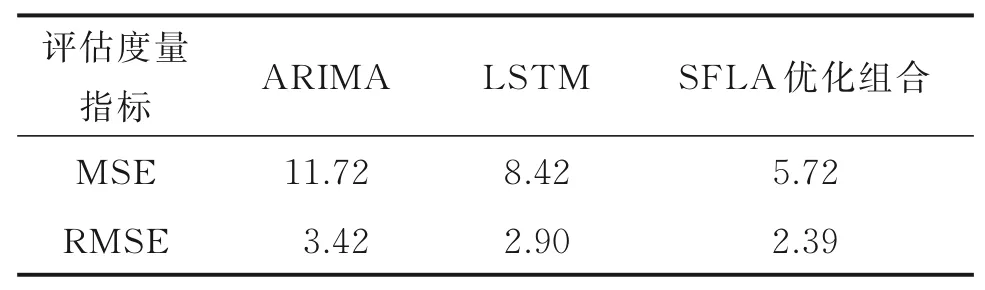
表2 SFLA优化组合模型与ARIMA、LSTM模型的性能对比Table 2 Performance comparison among ARIMA,LSTM models and the combined model optimized by SFLA
为了比较SFLA算法优化后的ARMA-SVM组合模型和SFLA算法优化后的ARMA-LSTM组合模型,确定哪个组合模型更适合电网数据预测,将其进行单独对比,结果如图6所示。从图6可以看出,经过SFLA算法优化的ARIMA-LSTM组合模型明显优于ARIMA-SVM模型。
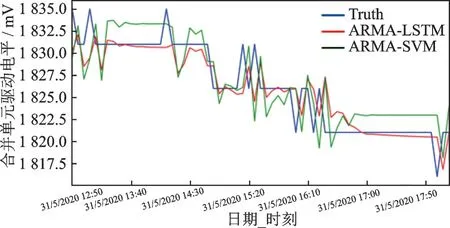
图6 SFLA优化后不同组合预测模型的预测结果Fig.6 Prediction results of different combination prediction models after SFLA algorithm optimization
表3进一步说明ARIMA-LSTM组合模型适合电网中的电量预测,主要原因是LSTM神经网络属于深度学习方法,和浅层机器学习方法算法相比具有更好的非线性能力和泛化能力。SVM在训练集样本学习到拟合效果较好的映射关系,在实际应用中面对新数据,其预测效果并不理想,其原因是浅层机器学习模型的泛化能力较差。而深度学习则通过多层连接和权值共享的网络结构增强了模型的泛化性能。

表3 两种SFLA优化组合模型性能对比Table 3 Performance comparison between two combined models optimized by SFLA
为了进一步比较SFLA算法对组合模型优化的性能,将经过SFLA算法优化后的ARIMA-LSTM组合模型与基于ARIMA和LSTM两个单一模型形成的等权组合模型和方差-协方差组合模型进行对比,结果如图7所示。从图7中可以发现,3组组合模型都能很好拟合电平的变化趋势。采用SFLA算法优化组合模型所预测的曲线与另外两个组合模型形成的曲线比较接近,是因为通过SFLA算法经过一系列计算之后,计算出的权值和另外两个组合模型的权值比较接近。经局部SFLA算法优化后的模型能够更好地反应真实数据。
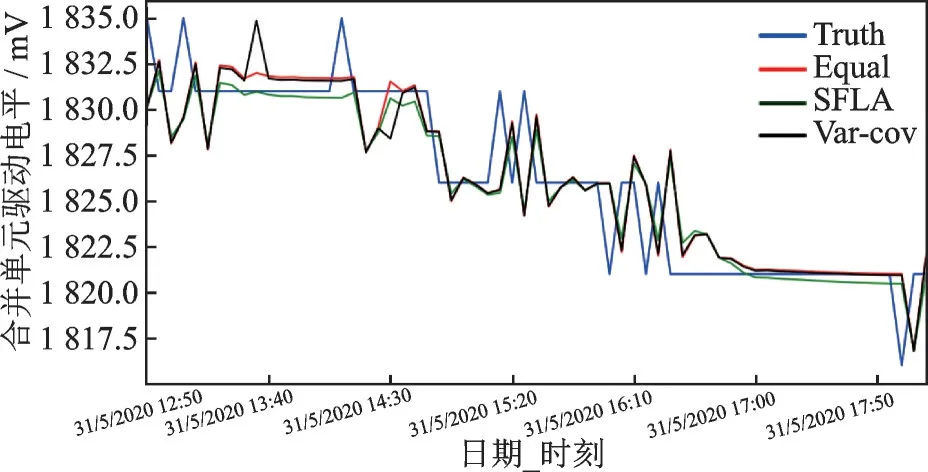
图7 不同组合模型预测结果Fig.7 Prediction results of different prediction models
从表4中计算的均方根误差和均方误差说明,经过SFLA算法优化的ARIMA-LSTM组合预测模型各项指标均优于ARIMA-LSTM等权组合模型和方差-协方差组合模型,SFLA算法对组合模型的优化效果更好。
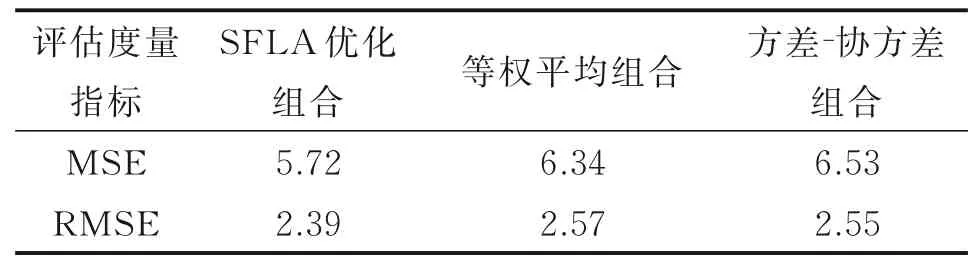
表4 不同优化方法的组合模型性能对比Table 4 Performance comparison among different optimized methods for combined models
5 结束语
采用SFLA算法对组合模型进行优化,综合改进组合模型ARIMA-SVM和ARIMA-LSTM中各自的优点,在单一模型的基础上进一步提升预测精度。更好地处理时序序列数据预测的随机性因素,与单一模型相比,在降低模型选择风险的同时提高预测精度。
SFLA算法具有很强的全局搜索性和局部搜索仔细的特点。采用SFLA算法确定组合预测模型中每个模型的权重系数,相比较等权组合模型中各个模型权重都相等,没有优选的概念,而均方根误差组合预测法存在权值不稳定的问题,能够进一步提高预测精度。
本文对ARMA和SVM组合模型进行优化,将其应用在电网中的电平预测,精度比单一模型和等权组合模型有所提高,为电网中的电平预测提供了一种行之有效的预测方法。
