基于多目标优化粒子群优化算法的高校图书推荐模型研究
2022-10-13白晓燕
白晓燕
(榆林学院, 陕西 榆林 719000)
0 引言
目前,高校图书馆大部分只有借书的功能,并没有充分地利用图书借书数据来挖掘潜在的信息.高校图书馆拥有大量的书籍,基本是按照学科来分类,学生寻找图书基本是单一的检索模式.因此,学生有时候很难知道自己需要什么样的书籍,这样一来,就会导致只有很少一部分图书被借阅,而造成大量图书处于空闲状态.
在大数据技术和数据挖掘技术飞速发展的今天,已经可以挖掘出图书与图书、图书和借阅者之间的关系,挖掘出学生的学习兴趣,挖掘出哪些同学之间有相同的借阅图书内容.这样一来,图书馆就不仅是被动地让学生来查找书籍,而是主动地给学生推送一些书籍;还可以建立基于图书借阅信息的学习群体,构建大学生学习生态网络,学生可以知道相同学习圈里其他同学在看什么样的书籍.这种类型的高校图书馆,不仅具有提供借阅书籍的功能,更是可以主动地给大学生推荐其有可能感兴趣的书籍,从而解决了高校图书馆个性化推荐水平不高、图书利用率不均衡等一系列不利的问题.
学习群体[1-2]是协作学习的核心组成部分.本文针对大学生借阅图书事件,构建多目标优化视角下大学生学习群体形成模型;然后,将大学生图书借阅事件问题抽象为粒子群多目标优化问题,分析了大学生借书事件的关联度与亲密度,并采用改进的多目标离散的粒子群优化算法[3-4],对大学生借书事件网络进行优化,从而得到多目标优化[5]视角下的大学生学习群体社区,即可以有效地、有目的地把相关书籍推荐给相应学生的社区.
1 粒子群优化算法
粒子群优化算法[6]是群智能算法的一种,其来源于对群居动物觅食和躲避捕食者的群体智能行为的人工建模与仿真[7].粒子群优化算法具有快速有效性、参数少、精度高、容易实现等优点,在单任务领域得到广泛应用.PSO算法[8]作为一种基于群智能体的优化算法,个体之间的协作[9]能涌现出智能行为.
粒子群算法是微粒群优化算法,通过微粒子在粒子空间中搜索解来优化一个问题,每个微粒子有两个属性:位置和速度,每个粒子通过记得自己最优解和知道整个种群的最优解来调整自己的速度和位置来到达全局最优.
假设一个种群有n个粒子,粒子的搜索空间的维数为d,令Vi={vi1,vi2,…,vid}表示第i个粒子的速度向量,令Xi={xi1,xi2,…,xid}表示第i个粒子的位置向量,则粒子更新自身状态的规则可以表示为:
(1)
(2)
式(1)中:Pi={pi1,pi2,…,pid}和G={g1,g2,…,gd},分别表示第i个粒子在飞行过程中的历史最优解和整个种群的最优解;c1和c2分别为粒子加速系数[10]和社会系数[11];r1和r2是0到1之间的随机数.
粒子群优化算法是一个不断重复的迭代计算算法,每个粒子根据公式(1)和公式(2)来不断地调整本身粒子飞行轨迹,从而得到整个粒子空间中最优的粒子,然后进行不断地逼近.
2 基于粒子群优化的借书网络社区建立
2.1 算法框架
本文提出的离散粒子群优化算法[11]通过重新定义粒子群算法操作算子,计算能量函数的最小值等来更新粒子的位置和速度[12-13].本文所提出算法的工作流程图如图1所示.

图1 本文算法工作流程图
2.2 粒子适应度函数
适应度函数用来评价粒子的优秀程度,对于社交网络的问题而言,适应度函数用来评价粒子的收敛程度是否合理,收敛速度怎么样,文献[14]提出了一种度量网络平衡程度的能量函数H(s),其定义如下:
H(s)=∑i,j(1-aijsisj)/2
(3)
式(3)中:aij∈{±1}是网络邻接矩阵的元素,si和sj分别表示节点i和节点j的符号.若节点i和节点j属于同一个社区,则si·sj=1,若节点i和节点j属于不在同一个社区,si·sj=-1.
该适应度函数[15]是根据网络平衡结果来衡量其对应的能量函数,函数值越小代表网络越接近于平衡.本文利用粒子群优化算法来最小化该函数,从而很快地找到对应的网络社区结构,继而找到对应的图.
2.3 粒子的表示
本文基于字符串的编码和解码[16]对网络进行编解码,编解码是优化问题和优化算法之间的桥梁.本文采用基于字符串的编码,这种编码操作简单可靠,对后期的解码有利,具体采用的粒子编码如图2所示.

图2 粒子的表示示意图
由图2可知,粒子的位置采用整数序列来表示,序列中的每个数字代表粒子的对应位置,其对应的数字代表粒子分类的社区标号,进行解码的时候,具有相同社区类标号的整数节点会被划分到同一个社区里面.从而,采用整数进行编码可以自动地预测网络需要划分为几个社区.
采用整数编码的方法,在解码的时候,如果节点i和节点j在同一个社区,则si·sj=1,如果节点i和节点j不在同一个社区,则si·sj=-1.
2.4 粒子的状态更新规则
本文算法中粒子的位置采用整数来进行编码,因此传统的粒子状态更新方程已经不再适用本文问题的求解.为了更好地得到社区结构,本文重新定义了粒子的状态更新方程:
(4)
(5)
式(4)中:ω是惯性权值常数,符号⊕表示异或操作.
函数ζ(x)是一个二维向量函数,其目的是将变量x变为离散的二进制形式,便于其与位置向量进行公式(4)的操作.函数ζ(x)具体定义如下:

(6)
公式(5)中的⊗操作是粒子状态更新的核心操作,该操作设置的好坏会直接影响算法挖掘社区的性能,还会影响算法的收敛程度.
对于一个图书网络而言,两个节点之间的连接概率采用如下方法,本文定义的⊗操作如下:
(7)
式(7)中:rand(xit)表示的是从xit对应的节点的邻居节点中随机选取一个节点的社区标号.
2.5 算法过程
算法过程如下所示:

步骤1首先初始化种群W,设种群W中粒子数为N;
步骤2计算粒子I在不同任务上的适应值;
步骤3计算粒子的i的最优因子ti,i属于W;
步骤4对当前种群W引入扰动因子φ,产生新的个体形成新的种群W1;
步骤5将W1中的新个体用于求解特定的任务;
步骤6将原始种群W和新的种群合并形成一个新的临时种群W2W2(W2=W∪W1)
步骤7更新W2中的最优因子ti;
步骤8从当前临时种群W2中挑选出适应值最优的N个粒子形成新的种群W3;
步骤9对每个任务的当前值解实行局部搜索,以逼近全局最优.
步骤10循环步骤3~步骤9,直到满足循环条件;
步骤11输出所有的任务的全局最优解.
3 实验测试与分析
3.1 实验设置
为了测试本算法的性能,将采用真实的图书借阅书籍进行实验测试.首先将本文算法命名为PSOSB,本文算法用到的参数做如下设置:惯性系数ω设置为0.718,本算法的加速系数c1和c2设置为1.510,粒子群的种群大小N设置为200,算法的循环迭代次数M设置为200.本文采用的算法对比文献[17]提出算法MemeSB,该算法的交叉概率和变异概率分别设置为0.8和0.2,其种群规模N设为200,算法的迭代次数设置为300.
实验中用到的数据为榆林学院图书馆四组不同的图书借阅事件,该网络由不同的节点组成,分别采用改进的粒子群优化算法进行测试.高校图书馆借阅事件分别用(YLTSG1)、(YLTSG2)、(YLTSG3)、(YLTSG4)来表示.本文通过四组(YLTSG1)、(YLTSG2)、(YLTSG3)、(YLTSG4)图书借阅真实数据进行测试,该四组图书借阅事件网络的属性见表1所示.
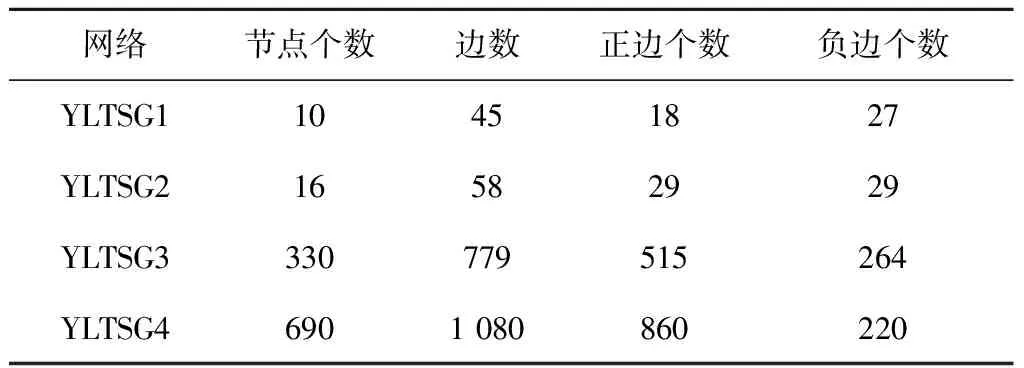
表1 图书借阅事件数据统计表
3.2 模拟数据测试
对本文算法运行30次,实验中发现,在对YLTSG事件1和YLTSG事件2网络进行测试时,可以得到不同的四个图书事件社区.
PSOSB算法和MemeSB算法30次独立运行得到的能量函数H(s)的值均为0,说明两种算法均找到了网络的平衡结构.图3和图4分別展示了YLTSG事件1和YLTSG事件2的网络结构图.从图3和图4可以看出,YLTSG事件1和YLTSG事件2网络都被分成了三个社区,且每个社区内部的节点都是正边连接的,社区之间的节点均为负边连接,可以得到哪些同学在读相似的图书,得到大学生学习群体社区[18].

图3 YLTSG事件1结构图
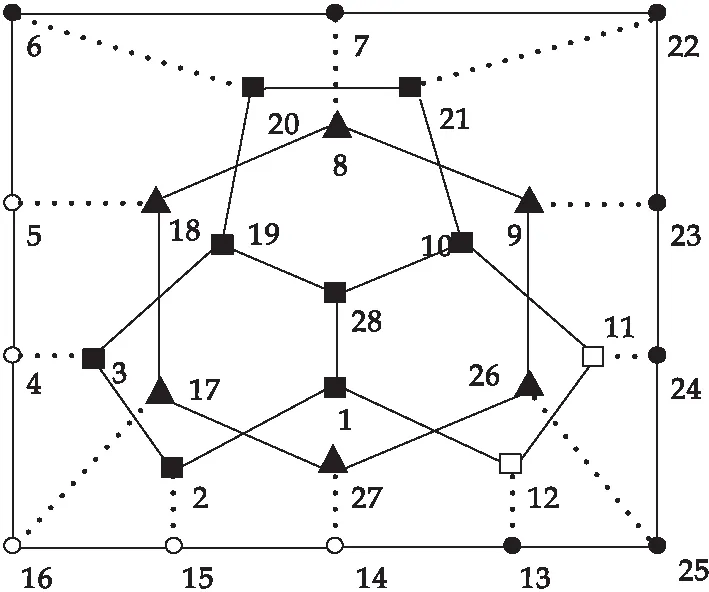
图4 YLTSG事件2结构图
3.3 模拟数据测试(Real data test)
在对真实网络YLTSG3,YLTSG4进行测试时,PSOSB和MemeSB同样独立运行30次.表2记录了实验统计结果.
在网络YLTSG事件3和YLTSG事件4上,两个算法都得到了相同的结果,PSOSB和MemeSB均得到了最小的能量函数值,但PSOSB算法的计算速度要比MemeSB算法快0.8 s.
图5和图6分别展示了图书借阅事件的真实社区结构图以及PSOSB算法得到的具有最小能量函数[19]的网络拓扑结构经过改变非平衡边得到的网络的平衡结构图.通过图5和图6对比可以看出,为了实现网络的结构平衡[20],节点SNS与DS和ZS-ESS之间的负边变成了正边,从而让曾经读过和该书有相似的借阅事件大学生加入该社区.

图5 YLTSG图书借阅事件3的真实社区结构图
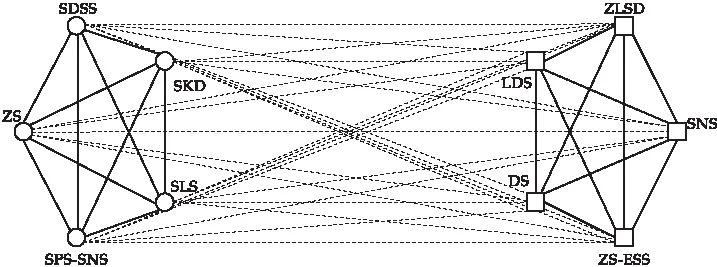
图6 YLTSG图书借阅事件3的真实社区结构变换非平衡边得到的平衡结构图
在YLTSG图书借阅事件1上,从表2可以看出,PSOSB比MemeSB得到了更小的H(s)的值,且PSOSB算法的计算速度仍然要比MemeSB算法快.图7和图8展示了YLTSG3网络的真实社区划分以及网络通过改变非平衡的边所得到的平衡结构.从图7和图8的对比可以看出,YLTSG图书借阅事件3的四条正边被变成了负边,可以把不相关的借阅事件剔除出该社区.

表2 真实网络数据30次独立测试结果统计表
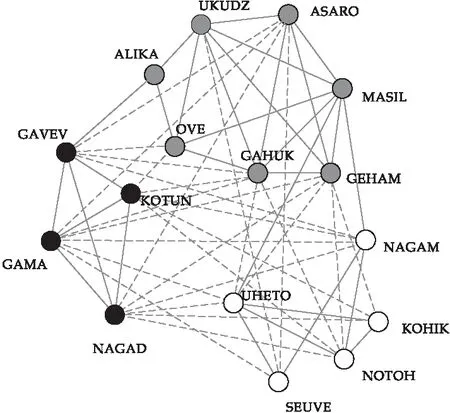
图7 事件4网络真实社区结构
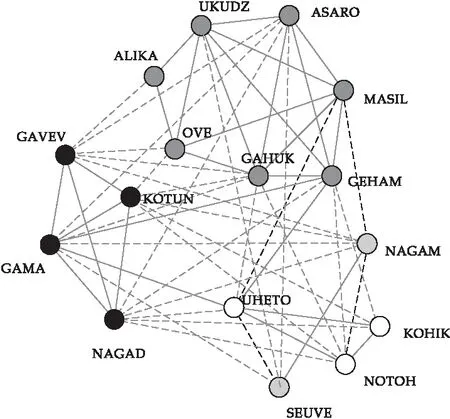
图8 事件4网络变换非平衡边得到的平衡结构图
在YLTSG事件3和YLTSG事件4上,本文提出的算法和对比算法的实验结果一样,这是因为这两个网络的规模太小,两种算法均很容易找到问题的最优解.虽然在YLTSG事件3和YLTSG事件4上,两种算法得到了相同的实验结果,但是本文算法比对比算法具有更快的收敛速度,本文算法的运行时间比对比算法要快两个数量级.从表2所示的统计结果来看,本文提出的PSOSB算法在YLTSG事件3和YLTSG事件4网络上的实验性能要明显优于MemeSB算法,PSOSB不仅能够得到比MemeSB算法更小的能量函数值,而且PSOSB算法的运行收敛时间明显要快于对比算法MemeSB.
实验中还发现,PSOSB算法比MemeSB算法具有更快的收敛速度.图9和图10分别展示了在YLTSG事件3网络和YLTSG事件4网络上两种算法在迭代100次时,算法单次运行得到的收敛曲线.从收敛实验的对比结果可以看出,PSOSB算法基本上在迭代40次的时候就已经收敛,而MemeSB算法需要迭代大约80次才能达到收敛.

图9 算法在YLTSG事件3网络上的收敛情况对比

图10 算法在YLTSG事件4网络上的收敛情况对比
从图9和图10可以看出,本文提出的基于离散的粒子群优化算法可以很快地向最优方向逼近,另外,本文算法在结构设计上充分考虑到图书网络本身的特点,在经典的粒子群算法的基础上,重新设计了粒子的状态更新方程,该方程可以增加粒子的全局寻优速度.对比MemeticSB算法,本文算法增加了扰动粒子,防止算法进入局部最优,而MemeticSB算法采用贪婪算法容易使算法陷入局部最优,而且贪婪算法的计算代价特别高.
由于本文算法和MemeSB算法都是随机搜索算法,算法的运行受到很多实际参数的影响,而且算法在每次运行时结果都不一样,因此探讨算法的稳定性是很有必要的.图11是PSOSB算法和MemeSB算法在YLTSG事件3网络数据、YLTSG事件4网络数据上独立运行200次得到的统计结果的箱图展示.
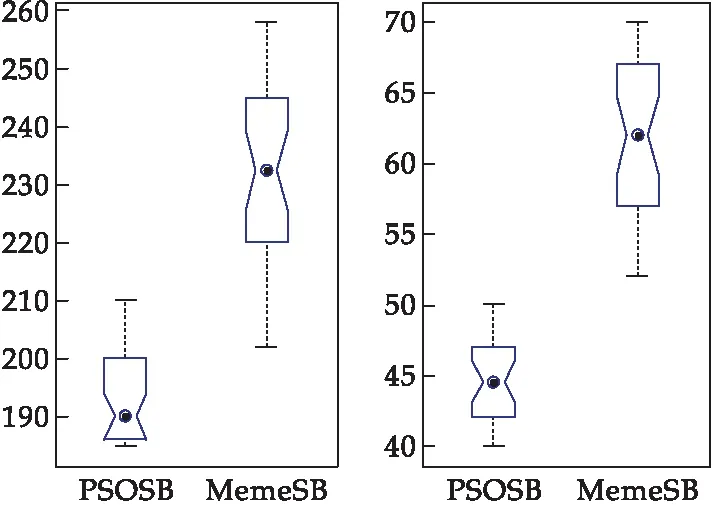
图11 在YLTSG事件3和YLTSG事件4上的算法稳定性对比实验
箱图能够反应算法的稳定性情况,其长短反应的是算法的稳定性.箱图长度越长代表算法不稳定,箱图长度越短代表算法越稳定.从图11可看出,本文算法经过200次的迭代运行,得到的箱图长度比MemeSB的要短,同时说明本文算法相对于MemeSB算法在稳定性方面更优秀.从箱图的数据分布情况可以看出,在不同大学生借阅图书事件上本文算法优化得到的最小的能量函数的函数值要比MemeSB算法的更小,从而证明了本文所提算法的有效性.
4 结论
本文以大学生图书借阅事件为研究对象,建立了大学生图书借阅事件网络结构图.然后,以图论知识为基础,对大学生借阅图书事件网络结构进行了深入研究,提出了一种基于粒子群优化的求解大学生学习群体问题的方法.该方法不仅可以实现大学生学习群体网络结构图,还可以挖掘网络中隐藏的社团结构.
本文把大学生借阅事件看做粒子,粒子通过调整种群中解的表示方法、位置和速度的更新规则以及局部搜索策略,设计出离散粒子群算法,从而得到具有相同大学生借书事件网络社区.最后,将本文算法在真实的大学生借阅图书事件上进行测试,较好地得到了大学生具有相同借阅事件的网络结构图,从而发现大学生学习群体,验证了该算法的有效性,并可以有针对性地把相关书籍推荐给大学生.根据真实实验测试,本文推荐算法的准确率提高了11%,覆盖率提升了13%,这对高校建立大学生学习社团具有很好的指导意义.
